
ZJIT loại bỏ tải và lưu trữ đối tượng dư thừa
ZJIT removes redundant object loads and stores
ZJIT vừa bổ sung một "load-store optimization" mới ở giai đoạn High-level Intermediate Representation (HIR). Tối ưu hóa này tập trung vào việc loại bỏ các thao tác load và store object dư thừa, thường xuất hiện trong các ứng dụng Ruby do tính chất hướng đối tượng. Kết quả đáng chú ý là qua benchmark `setivar`, ZJIT giờ đây vượt trội YJIT một cách rõ rệt, khẳng định lợi thế hiệu năng ngày càng tăng của ZJIT. Các nhà phát triển Ruby nên lưu ý rằng các JIT compiler luôn được cải tiến liên tục. Việc tìm hiểu về các "optimization passes" của compiler có thể giúp bạn hiểu rõ hơn về các điểm nghẽn hiệu năng và những khu vực tiềm năng để tối ưu hóa ứng dụng Ruby của mình.
Kể từ khi đăng bài vào cuối năm ngoái, ZJIT đã phát triển và thay đổi theo một số cách thú vị. Đây là câu chuyện về cách một thẻ tối ưu hóa mới, khép kín khiến hiệu suất của ZJIT vượt qua YJIT trên...
Giới thiệu
Kể từ bài đăng vào cuối năm ngoái, ZJIT đã phát triển và đã thay đổi theo một số cách thú vị. Đây là câu chuyện về một thế hệ mới, khép kín quá trình tối ưu hóa khiến hiệu suất của ZJIT vượt qua YJIT một cách thú vị microbenchmark. Đã 10 tháng kể từ khi ZJIT được sáp nhập vào Ruby và hiện chúng tôi bắt đầu thấy sự khác biệt về thiết kế giữa YJIT và ZJIT thể hiện ở sự khác biệt về hiệu suất. Trong bài đăng này, chúng tôi sẽ khám phá chi tiết về một tối ưu hóa mới trong ZJIT có tên là Load-store tối ưu hóa. Việc triển khai này là một phần của trình tối ưu hóa ZJIT trong HIR. thu hồi rằng cấu trúc của ZJIT trông gần giống như sau.
sơ đồ LR
A(["Ruby"])
A --> B(["YARV"])
B --> C(["HIR"])
C --> D(["LIR"])
D --> E(["Hội"])
Bài đăng này sẽ tập trung vào các bước tối ưu hóa trong HIR hoặc Trung cấp “Cấp cao” Đại diện. Ở cấp độ HIR, chúng tôi có hai khả năng khác biệt từ các giai đoạn biên soạn khác. Những tối ưu hóa của chúng tôi trong HIR thường sử dụng lợi ích từ việc đại diện cho SSA của chúng tôi ngoài HIR hệ thống hiệu ứng hướng dẫn.
Đây là các bước phân tích hiện tại trong ZJIT mà không cần tối ưu hóa kho lưu trữ, cũng như thứ tự thực hiện các lượt chuyển.
run_pass!(type_specialize);
run_pass!(nội tuyến);
run_pass!(optimize_getivar);
run_pass!(optimize_c_calls);
run_pass!(fold_constants);
run_pass!(clean_cfg);
run_pass!( Remove_redundant_patch_points);
run_pass!(eliminate_dead_code);
Đây là nơi tối ưu hóa cửa hàng tải được thêm vào.
run_pass!(type_specialize);
run_pass!(nội tuyến);
run_pass!(optimize_getivar);
run_pass!(optimize_c_calls);
+ run_pass!(optimize_load_store);
run_pass!(fold_constants);
run_pass!(clean_cfg);
run_pass!(remove_redundant_patch_points);
run_pass!(loại bỏ_dead_code);
Tổng quan
Ruby là ngôn ngữ lập trình hướng đối tượng nên CRuby cần có một số khái niệm về tải đối tượng, sửa đổi và lưu trữ. Thực chất đây là một chủ đề đã được đề cập trong một Rails quy mô khác bài đăng trên blog. Hình dạng hệ thống cung cấp các cải tiến về hiệu suất trong CRuby (cả trình thông dịch và JIT), nhưng vẫn còn nhiều cơ hội để cải thiện hiệu suất JIT. Đôi khi tối ưu hóa từng mã trình thông dịch một lần để lại các lần tải hoặc lưu trữ lặp đi lặp lại có thể được làm sạch bằng thẻ tối ưu hóa phân tích chương trình. Trước khi nhận được Hãy bàn về hiệu suất.
Kết quả
setivar điểm chuẩn cho ZJIT thay đổi đáng kể trên
2026-03-06. Đây là lúc tính năng tối ưu hóa kho lưu trữ được đưa vào ZJIT. Vào thời điểm
trong bài viết này, ZJIT mất trung bình 2 mili giây cho mỗi lần lặp trên điểm chuẩn này,
trong khi YJIT mất trung bình 5 mili giây.
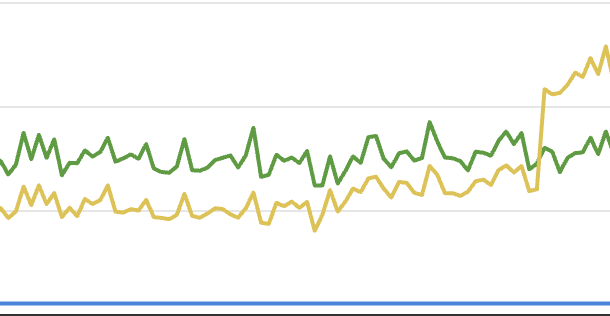
Đây là lần thứ hai ZJIT vượt qua YJIT một cách rõ ràng. Ví dụ đầu tiên ở đây.
Ở mức cao, điều này có nghĩa là ZJIT nhanh hơn gấp đôi YJIT khi lặp lại phép gán biến đối tượng và nhanh hơn 25 lần so với thông dịch viên!
Một sự phát triển đáng lo ngại
Tuy nhiên, có một câu hỏi quan trọng mà chúng ta phải giải quyết - tại sao một
thẻ tối ưu hóa cho tải đối tượng và cửa hàng có liên quan gì đến ví dụ
phép gán biến? Hóa ra Đại diện trung cấp cao của ZJIT
(HIR) sử dụng các lệnh LoadField và StoreField cho cả hai đối tượng
các biến thể hiện và cho các hình dạng đối tượng. Chúng ta sẽ phải đào sâu hơn
thành các hình CRuby và phần bên trong ZJIT HIR để hiểu điều này.
Nền
Cho đến nay, chúng ta đã biết rằng HIR có các hướng dẫn LoadField và StoreField.
Chúng tôi đã tuyên bố rằng chúng đa mục đích và hiệu suất sẽ đến
từ việc tối ưu hóa hình dạng đối tượng mà còn có thể áp dụng cho thể hiện đối tượng
các biến. Vì thuật toán hoạt động tốt cho cả hai tình huống nên
phần còn lại của bài đăng này sẽ tập trung vào các biến đối tượng. Điều này cho phép chúng tôi
thể hiện các khái niệm bằng Ruby thuần túy để làm cho mọi thứ dễ tiếp cận hơn.
Ví dụ
Hãy bắt đầu với một ví dụ đơn giản mà tất cả chúng ta đều có thể đồng ý. Rõ ràng mã này
đoạn mã có một cửa hàng kép và chúng tôi có thể xóa một trong các @a = value một cách an toàn
cuộc gọi.
lớp C
def khởi tạo
giá trị = 1
@a = giá trị
@a = giá trị
kết thúc
kết thúc
Đây là đoạn mã tương tự với ví dụ về lệnh gọi mà chúng tôi xóa. Ở đây, chúng tôi
đã bỏ qua lệnh StoreField dư thừa.
lớp C
chắc chắn khởi tạo
giá trị = 1
@a = giá trị
- @a = giá trị
kết thúc
kết thúc
Khi nào chúng ta nên xóa hướng dẫn LoadField và StoreField? Mã HIR
đoạn trích sẽ đến sau. Hiện tại, chúng ta chỉ cần biết ánh xạ giữa Ruby
và HIR chẳng hạn như tải và lưu trữ có thể thay đổi.
@var = giá trịStoreField var, @obj@offset, value@varLoadField var, @obj@offsetLưu ý: Trong phương thức khởi tạo của một lớp, các phép toán biến thể hiện là
có thể gây ra các hướng dẫn LoadField và StoreField do hình dạng
chuyển tiếp. Ngoài phương thức khởi tạo, tải và lưu trữ nhiều hơn
có khả năng liên quan đến chính các biến thể hiện. Chúng tôi đã quyết định rằng
các đoạn mã Ruby phức tạp hơn sẽ làm rõ loại LoadField hoặc
StoreField nhưng các đoạn mã trong bài đăng này quá lộn xộn.
Các trường hợp
Hãy xem xét mọi trường hợp đặc biệt cho thuật toán của chúng ta thông qua các đoạn mã Ruby ngắn
để minh họa các tình huống mà chúng ta có thể và không thể bỏ qua LoadField hoặc
StoreField Hướng dẫn HIR.
Lưu ý: Các ví dụ sau có thể thay thế biến value bằng biến
hằng số 1, nhưng trong ZJIT điều này có thể gây ra các tối ưu hóa khác như
gấp liên tục để cản trở việc trình diễn cửa hàng tải của chúng tôi. Chúng tôi sẽ sử dụng
những đoạn mã phức tạp hơn này trong trường hợp người đọc muốn theo dõi
trình khám phá trình biên dịch.
Cửa hàng dự phòng
lớp C
def khởi tạo
giá trị = 1
@a = giá trị
# Cửa hàng này thừa nên bỏ vào HIR
@a = giá trị
kết thúc
kết thúc
Tải dự phòng
lớp C
def khởi tạo
giá trị = 1
@a = giá trị
# Chúng tôi đã biết rằng tải này là `value` và cần được thay thế
@a
kết thúc
kết thúc
Cửa hàng dự phòng có bí danh
lớp C
attr_accessor :a
def khởi tạo(giá trị)
@a = giá trị
kết thúc
kết thúc
lớp D
attr_accessor :a
def khởi tạo(giá trị)
@a = giá trị
kết thúc
kết thúc
def multi_object_test
x = C.mới( 1)
y = D.mới(1)
new_x_val = 2
new_y_val = 3
x.a = new_x_val
y.a = new_y_val
# Chúng tôi muốn giải thích điều này (nhưng hiện tại thì không)
x.a = new_x_val
kết thúc
Với các biến trỏ đến các đối tượng riêng biệt, chúng ta có thể tách cửa hàng thứ hai thành
đối tượng x. Điều này hiện chưa được thực hiện, nhưng có thể là một cải tiến
bằng kỹ thuật có tên phân tích bí danh dựa trên loại.
Cửa hàng bắt buộc có bí danh
lớp C
attr_accessor :a
def khởi tạo(giá trị) @a = giá trị
kết thúc
kết thúc
def multi_object_test
x = C.mới(1)
y = x
new_x_val = 2
new_y_val = 3
x. một = new_x_val
y.a = new_y_val
# Chúng ta không nên bỏ qua phép gán `x.a` thứ hai vì phép gán `y.a` sửa đổi `x`
# Cửa hàng `x.a` sau bình luận này không còn dư thừa
x.a = new_x_val
kết thúc
Với nhiều biến bí danh cho cùng một đối tượng, chúng ta không thể tách biệt
cửa hàng thứ hai vào x. Mặc dù về mặt kỹ thuật, chúng tôi có thể bỏ qua y.a = new_y_val và
phép gán y = x ban đầu, những cải tiến này nằm ngoài phạm vi của việc này
bài viết. Điểm mấu chốt ở đây là việc đặt bí danh cần được xem xét. Nếu chúng ta giả sử
y và x tham chiếu các đối tượng khác nhau và bỏ qua đối tượng thứ hai
x.a = new_x_val, chúng tôi thay đổi hành vi của chương trình.
Cửa hàng bắt buộc có hiệu ứng
def scary_method(obj)
obj.a = "Chúng tôi đã sửa đổi đối tượng. Cửa hàng thứ hai không còn dư thừa"
kết thúc
lớp C
attr_accessor :a
def khởi tạo(giá trị)
@a = giá trị
kết thúc
kết thúc
def effectful_Operation_between_stores_test
x = C .mới(1)
x.a = 5
scary_method(x)
# Chúng tôi muốn giải thích điều này nhưng `scary_method` có thể sửa đổi `x`
x.a = 5
kết thúc
Trong trường hợp này, cửa hàng thứ hai có vẻ dư thừa nhưng có thể không phải vậy. Một
Phương thức Ruby tùy ý (hoặc lệnh gọi C hoặc một số hướng dẫn HIR) có thể sửa đổi x
đối tượng và phá vỡ các giả định mà chúng ta có thể đưa ra về trạng thái của đối tượng x.
Trong những trường hợp như vậy, chúng tôi không thể thực hiện tối ưu hóa cửa hàng tải.
Thuật toán
Ý tưởng chính
Với những trường hợp này, chúng tôi đã đề cập đến mọi thứ cần thiết để triển khai cửa hàng tải của mình thuật toán tối ưu hóa. Thuật toán nhẹ nhàng diễn giải trừu tượng về các đối tượng. Cách tiếp cận này cho phép chúng ta giảm thiểu tính toán cần thiết để thực hiện quá trình tối ưu hóa của chúng tôi trong khi đảm bảo tính lành mạnh. Theo thuật ngữ của người bình thường, điều này có nghĩa là mỗi tải chúng ta thay thế và mọi cửa hàng chúng tôi loại bỏ sẽ không thay đổi hành vi của chương trình, nhưng chúng tôi sẽ có khả năng bỏ lỡ một số lượt tải hoặc cửa hàng có thể bị loại bỏ.
Chi tiết phức tạp
Khối cơ bản
Quá trình tối ưu hóa cửa hàng tải của chúng tôi quét qua các khối cơ bản, tìm kiếm
tải và lưu trữ dư thừa, đồng thời cập nhật hướng dẫn HIR tương ứng.
Các thao tác StoreField không cần thiết sẽ bị loại bỏ và LoadField không cần thiết sẽ bị loại bỏ
các hoạt động được thay thế bằng lệnh đã giữ giá trị. Trong khi
một lợi ích chính của ZJIT là nó có thể tối ưu hóa toàn bộ phương thức, tải-lưu trữ
tối ưu hóa (hiện tại) chỉ là khối cục bộ.
Sự khác biệt giữa LoadField và StoreField
Cho đến nay, chúng ta đã thảo luận về việc loại bỏ lệnh bỏ chọn và hướng dẫn. Chúng ta có thể thoát khỏi
xóa hướng dẫn StoreField vì không có hướng dẫn nào khác trỏ đến
hướng dẫn StoreField. Ngược lại, các hướng dẫn LoadField có có
phụ thuộc và được tham chiếu bởi các hướng dẫn khác. Những tài liệu tham khảo này cần
được cố định lại. Mỗi tham chiếu đến LoadField được thay thế bằng giá trị được lưu trong bộ nhớ đệm
đó là mục tiêu của tải.
Lệnh WriteBarrier
ZJIT có WriteBarrier hướng dẫn để hỗ trợ thu gom rác. Những điều này cũng
có thể sửa đổi các đối tượng và hoạt động tương tự như các cửa hàng. Chúng ta cần xử lý trường hợp này trong
thuật toán của chúng tôi.
Sự phức tạp của con trỏ
Mã giả mà chúng tôi sắp giới thiệu sử dụng thuật ngữ “offset” để biểu thị số byte từ địa chỉ cơ sở của đối tượng trong bộ nhớ. Chúng tôi sử dụng điều này để phát hiện các tải và lưu trữ dư thừa, cũng như xóa bộ nhớ đệm khỏi các dữ liệu hiệu quả hướng dẫn và viết các rào cản. Tuy nhiên, không rõ ràng ngay rằng chỉ cần kiểm tra offset là đủ. Làm sao chúng ta có thể chắc chắn rằng ký ức các khu vực chúng tôi đang theo dõi vẫn không bị ảnh hưởng bởi một số hướng dẫn khác? May mắn thay, Hướng dẫn HIR luôn trỏ đến phần đế của một đối tượng và sử dụng các offset nằm trong giới hạn của đối tượng. Nếu chúng ta có hai offset không bằng nhau thì chúng không thể tham chiếu cùng một vùng bộ nhớ. Nếu độ lệch bằng nhau thì bí danh đối tượng phải được xem xét.
Phác thảo thuật toán
Đây là mã giả cho một khối cơ bản nhất định.
Đối với mỗi lệnh HIR trong khối cơ bản
khởi tạo bộ đệm trống dưới dạng hashmap
nếu lệnh là `LoadField`
kiểm tra xem đối tượng, offset và giá trị gấp ba có trong bộ đệm không
nếu vậy, hãy xóa lệnh và thay thế các tham chiếu đến nó bằng giá trị được tải
mặt khác, lưu trữ giá trị đã tải với đối tượng, cặp offset làm khóa
nếu lệnh là `StoreField`
kiểm tra xem đối tượng, offset và giá trị gấp ba có nằm trong bộ nhớ đệm
nếu vậy hãy xóa hướng dẫn
mặt khác, hãy xóa từng mục bộ đệm có cùng độ lệch (trường cờ) để tránh các vấn đề về bí danh
nếu lệnh là `WriteBarrier`
# Lệnh này cần thiết cho bộ thu gom rác và rất phức tạp
# Nó hoạt động tương tự như `StoreField` trong thực tế
# Hướng dẫn này không bao giờ bị xóa nhưng vẫn cần phải dọn dẹp bộ đệm
xóa từng mục bộ đệm giống nhau bù đắp để tránh các vấn đề bí danh
nếu hướng dẫn có thể sửa đổi các đối tượng
xóa bộ nhớ đệm
khác
tiếp tục
trả lại hướng dẫn HIR đã được cắt bớt
Mã nguồn
Bạn có thể tìm thấy nguồn tại thời điểm viết bài này tại đây.
Cải tiến HIR
Sau khi tối ưu hóa, đây là ví dụ về cách HIR thay đổi.
Đây là HIR mới cho ví dụ về tải dự phòng đầu tiên của chúng tôi.
fn khởi tạo@../scripts/double_load.rb:3:
bb1():
Trình thông dịch EntryPoint
v1:BasicObject = LoadSelf
v2:NilClass = Giá trị cố định(nil)
Nhảy bb3(v1, v2)
bb2():
Điểm đầu vào JIT(0)
v5:BasicObject = LoadArg :self@0
v6:NilClass = Giá trị cố định(nil)
Nhảy bb3(v5, v6)
bb3(v8:BasicObject, v9:NilClass):
v13:Fixnum[1] = Giá trị cố định(1)
Chế độ PatchPoint SingleRactor
v30:HeapBasicObject = GuardType v8, HeapBasicObject v31:CShape = LoadField v30, :_shape_id@0x4
v32:CShape[0x80000] = GuardBitEquals v31, CShape(0x80000)
StoreField v30, :@a@0x10, v13
WriteBarrier v30, v13
v35:CShape[0x80008] = Const CShape(0x80008)
StoreField v30, :_shape_id@0x4, v35
- v20:HeapBasicObject = RefineType v8, HeapBasicObject
PatchPoint SingleRactorMode
- v38:CShape = LoadField v20, :_shape_id@0x4
- v39:CShape[0x80008] = GuardBitEquals v38, CShape(0x80008)
- v40:BasicObject = LoadField v20, :@a@0x10
Kiểm tra các ngắt
- Trả về v40
+ Trả về v13
Đây là HIR mới cho ví dụ về cửa hàng dự phòng đầu tiên của chúng tôi.
bb1():
Trình thông dịch EntryPoint
v1:BasicObject = LoadSelf
v2:NilClass = Giá trị cố định(nil)
Nhảy bb3(v1, v2)
bb2():
Điểm đầu vào JIT(0)
v5:BasicObject = LoadArg :self@0
v6:NilClass = Giá trị cố định(nil)
Nhảy bb3(v5, v6)
bb3(v8:BasicObject, v9:NilClass):
v13:Fixnum[1] = Giá trị cố định(1)
Chế độ PatchPoint SingleRactor
v35:HeapBasicObject = GuardType v8, HeapBasicObject
v36:CShape = LoadField v35, :_shape_id@0x4
v37:CShape[0x80000] = GuardBitEquals v36, CShape(0x80000)
StoreField v35, :@a@0x10, v13
WriteBarrier v35, v13
v40:CShape[0x80008] = Const CShape(0x80008)
StoreField v35, :_shape_id@0x4, v40
v20:HeapBasicObject = RefineType v8, HeapBasicObject
PatchPoint NoEPEscape(khởi tạo)
Chế độ PatchPoint SingleRactor
- v43:CShape = LoadField v20, :_shape_id@0x4
- v44:CShape[0x80008] = GuardBitEquals v43, CShape(0x80008)
- StoreField v20, :@a@0x10, v13
WriteBarrier v20, v13
Kiểm tra ngắt
Trả lại v13
Và đó là tối ưu hóa kho tải!
Thảo luận về thiết kế
Bạn có thể nhận thấy rằng tính năng tối ưu hóa của chúng tôi đang cắt bớt biểu đồ lượt tải và cửa hàng trên một vật thể. Chúng tôi đang giải quyết một vấn đề rất giống với biểu mẫu SSA được đưa vào HIR. Mặc dù sẽ rất tuyệt nếu có thêm “SSA” ở cấp độ đối tượng, nhưng điều này phải trả giá. Tính toán SSA ở cấp độ này có thể cần đến cấu trúc những thay đổi đối với HIR và làm cho mọi thứ trở nên ít thuận tiện hơn hoặc khó hiểu hơn ở các khu vực cơ sở mã bên ngoài việc tối ưu hóa cửa hàng tải. Trên thực tế, câu hỏi “thêm SSA” là một quyết định thiết kế phức tạp và là chủ đề gây tranh cãi với giàu lịch sử trong các trình biên dịch như V8 hoặc Jikes RVM. Cho đến nay, chúng tôi đã quyết định sử dụng biểu diễn SSA nhẹ trong ZJIT để khiến chúng tôi phải làm việc chăm chỉ hơn một chút để đạt được một số bước tối ưu hóa nhất định, mang lại kết quả tinh tế đơn giản hóa thiết kế trên phần còn lại của HIR.
Công việc trong tương lai
Vẫn còn nhiều việc thú vị phải làm và có những cải tiến đối với được thực hiện trước khi chúng ta đạt được lợi nhuận giảm dần. Việc loại bỏ cửa hàng chết sử dụng nhiều có cùng ý tưởng và có thể giúp cải thiện hiệu suất khởi tạo đối tượng. Chúng tôi có thể triển khai phân tích bí danh dựa trên loại, mặc dù điều này cần phải cẩn thận vì lỗi nhầm lẫn về loại khá phổ biến nguy hiểm trong trình biên dịch JIT. Xem phần 4.1 trong bài viết phrack để biết thêm chi tiết.
Kết luận
Cảm ơn bạn đã đọc bài viết đầu tiên về trình tối ưu hóa của ZJIT. Chúng tôi có nhiều hơn nữa để hãy theo dõi nhé.
Tác giả: tekknolagi