Chúng tôi đã thay thế RAG bằng hệ thống tệp ảo cho trợ lý tài liệu AI của mình
We replaced RAG with a virtual filesystem for our AI documentation assistant
RAG rất tuyệt cho đến khi nó không như vậy. Trợ lý của chúng tôi chỉ có thể truy xuất những đoạn văn bản khớp với truy vấn. Nếu câu trả lời tồn tại trên nhiều trang hoặc người dùng cần cú pháp chính xác nhưng không nằm trong top-K...
RAG rất tuyệt cho đến khi nó không như vậy.
Trợ lý của chúng tôi chỉ có thể truy xuất những đoạn văn bản khớp với truy vấn. Nếu câu trả lời tồn tại trên nhiều trang hoặc người dùng cần cú pháp chính xác nhưng không đạt được kết quả top-K thì nó sẽ bị kẹt. Chúng tôi muốn nó khám phá tài liệu theo cách bạn khám phá cơ sở mã.
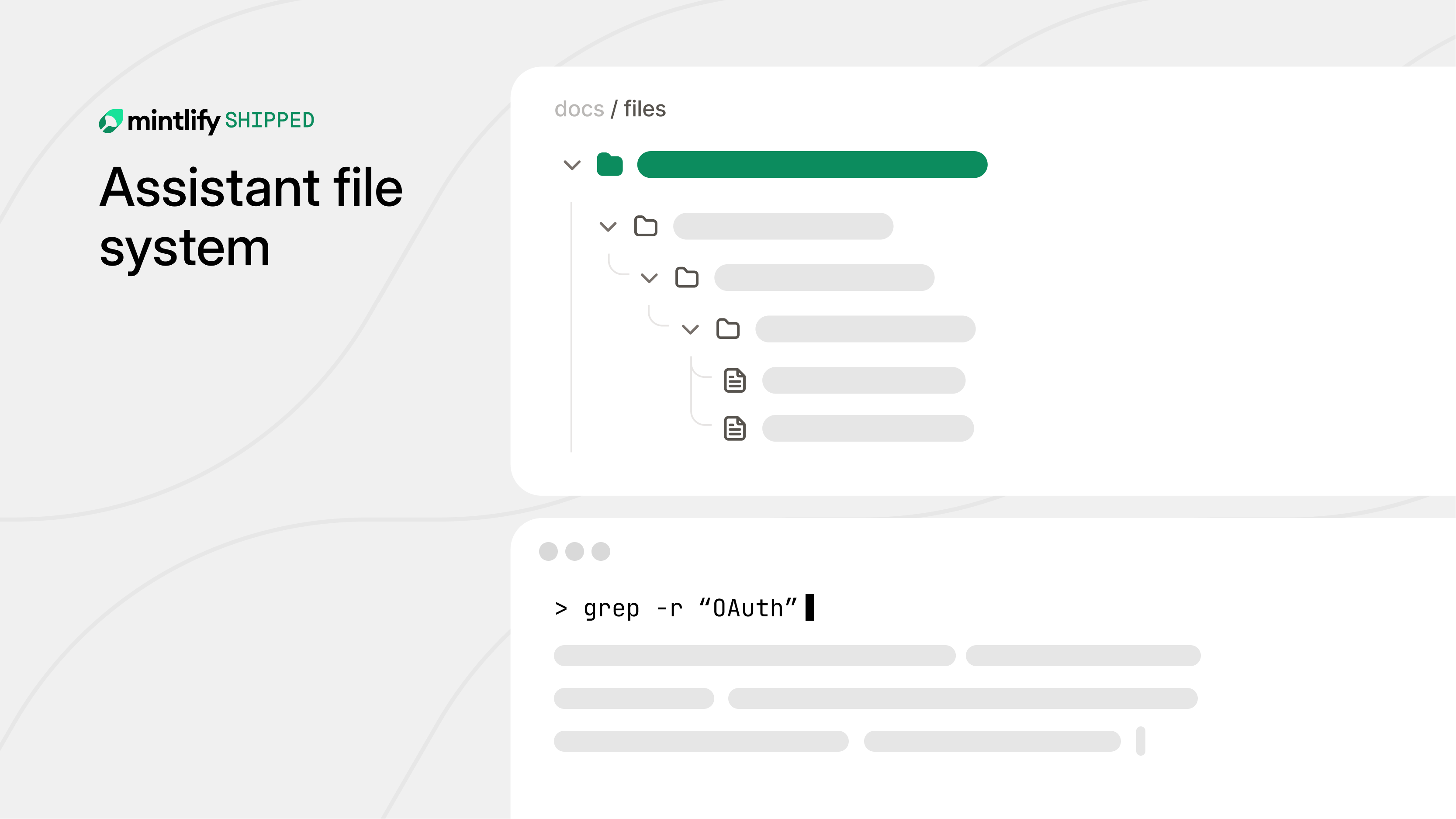
Nhân viên hội tụ trên các hệ thống tệp làm giao diện chính vì grep, cat, ls và find đều là những gì nhân viên cần. Nếu mỗi trang tài liệu là một tệp và mỗi phần là một thư mục thì tác nhân có thể tìm kiếm các chuỗi chính xác, đọc toàn bộ trang và duyệt qua cấu trúc của chính nó. Chúng tôi chỉ cần một hệ thống tệp phản chiếu trang tài liệu trực tiếp.
Cách rõ ràng để thực hiện việc này là chỉ cung cấp cho tác nhân một hệ thống tệp thực sự. Hầu hết các bộ khai thác đều giải quyết vấn đề này bằng cách tạo một hộp cát biệt lập và sao chép kho lưu trữ. Chúng tôi đã sử dụng hộp cát cho các tác nhân nền không đồng bộ trong đó độ trễ là điều cần cân nhắc, nhưng đối với trợ lý giao diện người dùng nơi người dùng đang nhìn chằm chằm vào một vòng quay tải, cách tiếp cận này sẽ thất bại. Thời gian tạo phiên p90 của chúng tôi (bao gồm bản sao GitHub và thiết lập khác) là ~46 giây.
Ngoài độ trễ, các máy ảo siêu nhỏ chuyên dụng để đọc tài liệu tĩnh đã đưa ra một dự luật nghiêm túc về cơ sở hạ tầng:
$0$50k$100k$150k$200k0357101215Thời lượng phiên trung bình (phút)Tính toán bổ sung hàng năm chi phí
SandboxChromaFs
Với 850.000 cuộc hội thoại mỗi tháng, ngay cả thiết lập tối thiểu (1 vCPU, 2 GiB RAM, thời lượng phiên 5 phút) cũng sẽ giúp chúng tôi kiếm được 70.000 USD một năm dựa trên Giá hộp cát mỗi giây của Daytona ($0,0504/giờ mỗi vCPU, 0,0162 USD/giờ mỗi GiB RAM). Thời gian phiên dài hơn gấp đôi. (Điều này dựa trên một cách tiếp cận hoàn toàn đơn giản, một quy trình sản xuất thực sự có thể sẽ có các nhóm ấm và chia sẻ vùng chứa, nhưng quan điểm vẫn giữ nguyên)
Chúng tôi cần quy trình làm việc của hệ thống tệp nhanh chóng và tiết kiệm, điều này có nghĩa là phải xem xét lại chính hệ thống tệp.
Tác nhân không cần hệ thống tệp real; nó chỉ cần ảo ảnh của một. Tài liệu của chúng tôi đã được lập chỉ mục, phân nhóm và lưu trữ trong cơ sở dữ liệu Chroma để hỗ trợ tìm kiếm, vì vậy chúng tôi đã xây dựng ChromaFs: một hệ thống tệp ảo chặn các lệnh UNIX và chuyển chúng thành các truy vấn trên cùng cơ sở dữ liệu đó. Quá trình tạo phiên giảm từ ~46 giây xuống ~100 mili giây và do ChromaF sử dụng lại cơ sở hạ tầng mà chúng tôi đã thanh toán nên chi phí tính toán biên cho mỗi cuộc trò chuyện bằng 0.

| Chỉ số | Hộp cát | [[TA G_64]]ChromaFs|||
|---|---|---|---|---|
| P90 Khởi động Thời gian | ~46 giây | ~100 ms Chi phí | ~$0,0137 mỗi cuộc hội thoại | ~$0 (sử dụng lại DB hiện có) |
| Tìm kiếm Cơ chế | Quét đĩa tuyến tính (Syscalls) | Siêu dữ liệu DB Truy vấn | ||
| Cơ sở hạ tầng | Daytona hoặc các nhà cung cấp tương tự | Được cung cấp DB |
ChromaFs được Vercel Labs xây dựng trên just-bash (shouout Malte!), một bản tái hiện TypeScript của bash hỗ trợ grep, mèo, ls, tìm và cd. just-bash hiển thị giao diện IFileSystem có thể cắm, do đó, nó xử lý tất cả logic phân tích cú pháp, đường dẫn và cờ trong khi ChromaFs chuyển mọi lệnh gọi hệ thống tệp cơ bản thành truy vấn Chroma.
Cách hoạt động
Khởi động thư mục Cây
ChromaFs cần biết những tệp nào tồn tại trước khi tác nhân chạy một lệnh duy nhất. Chúng tôi lưu trữ toàn bộ cây tệp dưới dạng tài liệu JSON được nén bằng gzipped (__path_tree__) bên trong bộ sưu tập Chroma:
{
"auth/oauth": { "isPublic": true, "nhóm": [] },
"auth/api-keys": { "isPublic": true, "nhóm": [] },
"nội bộ/thanh toán": { "isPublic": false, "nhóm": ["admin", "thanh toán"] },
"api-reference/endpoint/users": { "isPublic": true, "nhóm": []
Khi bắt đầu, máy chủ tìm nạp và giải nén tài liệu này thành hai cấu trúc trong bộ nhớ: một Set<string> của đường dẫn tệp và một chuỗi Map<, string[]> ánh xạ thư mục tới trẻ em.
Sau khi được tạo, ls, cd và find sẽ phân giải trong bộ nhớ cục bộ mà không cần gọi mạng. Cây được lưu vào bộ nhớ đệm nên các phiên tiếp theo cho cùng một trang web sẽ bỏ qua hoàn toàn quá trình tìm nạp Chroma.
Kiểm soát quyền truy cập
Chú ý các trường isPublic và groups trong cây đường dẫn. Trước khi xây dựng cây tệp, ChromaFs sẽ cắt bớt các phần mở rộng bằng cách sử dụng mã thông báo phiên của người dùng hiện tại và áp dụng bộ lọc phù hợp cho tất cả các truy vấn Chroma tiếp theo. Nếu người dùng thiếu quyền truy cập vào một tệp thì tệp đó sẽ bị loại trừ hoàn toàn khỏi cây, do đó, tác nhân không thể truy cập hoặc thậm chí tham chiếu đến đường dẫn đã bị cắt bớt.
Trong hộp cát thực, cấp độ kiểm soát truy cập cho mỗi người dùng này sẽ yêu cầu quản lý các nhóm người dùng Linux, quyền chmod hoặc duy trì hình ảnh vùng chứa riêng biệt cho mỗi cấp khách hàng. Trong ChromaFs, cần lọc một vài dòng trước khi buildFileTree chạy.
Nhóm:
không có
| Đường dẫn[[TAG _277]] | Truy cập | Hiển thị | |
|---|---|---|---|
| công khai | ✓ | [[TAG_29 4]]||
| /auth/api-keys.mdx | public | ✓[[TAG_30 2] thích thanh toán | ✗ |
| admin | [[TAG_32 1]]✗ | ||
| /api-reference/users.mdx[[TAG _327]] | công khai | ✓ | [[TAG_334] ]|
| /api-reference/ Payments.mdx | billing | [[TAG _340]]✗
Tập hợp lại các trang từ các phần
Các trang trong Chroma được chia thành các phần để nhúng, do đó, khi tác nhân chạy cat /auth/oauth.mdx, ChromaFs sẽ tìm nạp tất cả các phần phù hợp sên trang, sắp xếp theo chunk_index và nối chúng vào trang đầy đủ. Kết quả được lưu vào bộ nhớ đệm để các lần đọc lặp lại trong quy trình làm việc grep không bao giờ truy cập vào cơ sở dữ liệu hai lần.
Không phải mọi tệp đều cần tồn tại trong Chroma. Chúng tôi đăng ký các con trỏ tệp lười để giải quyết quyền truy cập đối với các thông số OpenAPI lớn được lưu trữ trong bộ chứa S3 của khách hàng. Tác nhân thấy v2.json trong ls /api-specs/ nhưng nội dung chỉ tìm nạp khi chạy cat.
Mọi thao tác ghi đều gây ra lỗi EROFS (Hệ thống tệp chỉ đọc). Tác nhân tự do khám phá nhưng không bao giờ có thể thay đổi tài liệu, điều này khiến hệ thống không có trạng thái, không cần dọn dẹp phiên và không có nguy cơ một tác nhân làm hỏng chế độ xem của người khác.
cat và ls dễ ảo hóa nhưng grep -r sẽ quá chậm nếu nó quét mọi tệp qua mạng một cách đơn giản. Chúng tôi chặn just-bash grep, phân tích các cờ bằng yargs-parser và chuyển chúng thành truy vấn Chroma ($contains cho các chuỗi cố định, $regex cho các mẫu).
Chroma hoạt động như một bộ lọc thô xác định tệp nào có thể chứa nội dung lần truy cập và chúng tôi bulkPrefetch những đoạn phù hợp đó vào bộ đệm Redis. Từ đó, chúng tôi viết lại lệnh grep để chỉ nhắm mục tiêu các tệp phù hợp và gửi lại cho just-bash để thực thi fine filter trong bộ nhớ, nghĩa là các truy vấn đệ quy lớn hoàn thành trong một phần nghìn giây.
ChromaFs hỗ trợ trợ lý tài liệu cho hàng trăm nghìn người dùng trên 30.000+ cuộc trò chuyện một ngày. Bằng cách thay thế hộp cát bằng hệ thống tệp ảo trên cơ sở dữ liệu Chroma hiện có của chúng tôi, chúng tôi đã tạo phiên ngay lập tức, chi phí điện toán biên bằng 0 và RBAC tích hợp mà không cần bất kỳ cơ sở hạ tầng mới nào.
Hãy dùng thử trên bất kỳ trang web tài liệu Mintlify nào hoặc tại mintlify.com/docs.
Tác giả: denssumesh