Chưng cất tìm kiếm cây cho các mô hình ngôn ngữ sử dụng PPO
Tree Search Distillation for Language Models Using PPO
Bài viết này bàn về cách áp dụng **Monte Carlo Tree Search (MCTS)** vào kỹ thuật **distillation** cho các mô hình ngôn ngữ (LLM), gợi nhớ đến các kỹ thuật AI trong game như **AlphaZero**. Tác giả đã thử nghiệm thành công MCTS để tìm kiếm các chuỗi suy luận mạnh mẽ hơn trên một LLM nhỏ, chơi trò Countdown (một trò chơi tính toán số). Kết quả cho thấy sự cải thiện đáng kể (8.2 điểm phần trăm) so với các phương pháp **Reinforcement Learning (RL)** tiêu chuẩn sau quá trình distillation. Điều này hé mở tiềm năng của các phương pháp dựa trên tìm kiếm (search-based methods) trong việc nâng cao khả năng suy luận của LLM, đặc biệt hiệu quả với các tác vụ mang tính tổ hợp (combinatorial tasks). Các lập trình viên muốn cải thiện khả năng suy luận của LLM nên cân nhắc tìm hiểu MCTS và các thuật toán tìm kiếm cây khác. Để áp dụng chúng cho việc sinh ngôn ngữ, chúng ta cần định nghĩa rõ ràng không gian hành động (action spaces) và cách biểu diễn trạng thái (state representations), có thể kết hợp các kỹ thuật như **Tree-of-Thoughts**.
Các mạng thần kinh chơi trò chơi như AlphaZero đạt được hiệu suất siêu phàm trong các trò chơi trên bàn cờ bằng cách tăng cường chính sách thô bằng khai thác tìm kiếm trong thời gian thử nghiệm và chắt lọc...
Các mạng thần kinh chơi trò chơi như AlphaZero đạt được hiệu suất siêu phàm trong các trò chơi cờ bàn bằng cách tăng cường chính sách thô bằng khai thác tìm kiếm trong thời gian thử nghiệm và chắt lọc chính sách tăng cường, mạnh mẽ hơn trở lại mạng. Tại sao ngày nay các kỹ thuật tương tự không được sử dụng trong mô hình hóa ngôn ngữ? Các tác giả DeepSeek-R1 cho biết họ nhận thấy thành công hạn chế với MCTS; Finbarr Timbers có bài đăng tuyệt vời về lý do tại sao họ có thể gặp phải vấn đề này, cụ thể là họ chọn UCT thay vì pUCT.
Mục đích của bài đăng này là khám phá hai câu hỏi:
- Có thể việc chắt lọc tìm kiếm thực sự cải thiện lý luận về mô hình ngôn ngữ không?
- Nó hoạt động như thế nào so với các phương pháp RL ngôn ngữ tiêu chuẩn, ví dụ: GRPO?
Để khám phá điều này, tôi đã áp dụng MCTS qua các bước suy luận cho Qwen-2.5-1.5B-Instruct, để tìm kiếm các quỹ đạo mạnh hơn và chắt lọc những quỹ đạo này trở lại mô hình thông qua vòng lặp PPO trực tuyến. Khi thực hiện Đếm ngược, một trò chơi số học tổ hợp, mô hình chắt lọc (được đánh giá mà không cần khai thác tìm kiếm) đạt được điểm eval@16 tiệm cận là 11,3%, so với 8,4% của CISPO và 7,7% của best-of-N. So với mô hình hướng dẫn trước RL (3,1%), đây là mức cải thiện 8,2 điểm phần trăm.
Điểm tuyệt đối thấp phản ánh thực tế rằng đây là những thử nghiệm quy mô nhỏ trên mô hình 1,5B. Tôi muốn sử dụng bài đăng này làm bài đăng đầu tiên trong loạt bài và hy vọng sẽ thấy những điểm số này tăng lên trong các bài đăng blog tiếp theo khi tôi sử dụng các mô hình lớn hơn và tính toán ngân sách.
Đếm ngược
Ban đầu, tôi đã thử sử dụng GSM8K làm môi trường để thử nghiệm phương pháp này nhưng nhận thấy sự khác biệt tối thiểu giữa GRPO và MCTS để đưa ra khẳng định chắc chắn. Thay vào đó, tôi quyết định chọn trò chơi Countdown làm môi trường của chúng tôi. Tiền đề rất đơn giản: cho một tập hợp N số nguyên dương, sử dụng các phép toán chuẩn (+, -, /, *) để tính một mục tiêu cụ thể. Tại sao đếm ngược? Giả thuyết là các vấn đề tổ hợp được hưởng lợi nhiều hơn từ loại tìm kiếm cây lý luận thích ứng song song cho phép, trái ngược với GSM8K trong đó lý luận tuần tự cũng dẫn đến kết quả hiệu quả. Chúng tôi đào tạo trên tập dữ liệu gồm 20.000 mẫu và đánh giá trên bộ thử nghiệm gồm 820 mẫu. Mỗi mẫu bao gồm bốn số nguyên đầu vào, từ 1 đến 13.
Tôi nhận thấy rằng việc sử dụng phần thưởng thưa thớt (0/1 cho tính chính xác) trong quá trình huấn luyện sẽ khiến quá trình huấn luyện không ổn định. Chuyển sang chức năng thưởng dày đặc:
$1,0 - 2 \cdot \min\left(\frac{|t - p|}{t}, 1.0\right)$ nếu định dạng đúng, nếu không thì $-1,0$
Ở đây, $t$ là mục tiêu thực sự và $p$ là mục tiêu được dự đoán.
Tuy nhiên, việc đánh giá vẫn sử dụng chức năng khen thưởng thưa thớt vì chúng tôi muốn có thể hiểu được điểm số (ví dụ: % tỷ lệ đậu).
Tìm kiếm cây Monte Carlo
Thuật toán MCTS đã được những người khác trình bày chuyên sâu, vì vậy tôi sẽ bỏ qua phần mô tả chi tiết: vì mục đích của bài đăng này, tôi muốn tập trung vào sự khác biệt giữa MCTS cổ điển và phương pháp tôi đã thử. Nói ngắn gọn, MCTS xây dựng cây tìm kiếm theo cách lặp đi lặp lại để khám phá không gian hành động một cách thông minh, được hướng dẫn bởi hàm giá trị.
Trò chơi cờ bàn có không gian hành động tương đối có ý nghĩa, tức là mỗi nước cờ trong cờ vua có xu hướng ảnh hưởng đáng kể đến việc người chơi có thắng hay không. Ngược lại với mô hình hóa ngôn ngữ, trong đó nhiều mã thông báo trong dấu vết lý luận đóng vai trò là chất độn hoặc đường cú pháp và việc phân nhánh từ nhật ký top-k (hoặc điều chỉnh theo ngưỡng entropy) không phải lúc nào cũng dẫn đến tính đa dạng tìm kiếm. Hãy tưởng tượng một trạng thái trong đó các mã thông báo có thể xảy ra tiếp theo là “nhưng”, “tuy nhiên”, “chưa” v.v; cuối cùng chúng tôi sẽ phải tiêu tốn tài nguyên tính toán để xây dựng các cây tìm kiếm cực kỳ lớn với lợi ích cận biên trên cơ sở mỗi mã thông báo.
Tôi thích cách tiếp cận do Tree-of-Thoughts (Yao et al., 2023) giới thiệu hơn để tìm kiếm các bước lập luận khả thi tiếp theo. Trong công thức này, mỗi trạng thái nút là một chuỗi các mã thông báo liền kề:
- Nút gốc tương ứng với dấu nhắc đầu vào
- Các nút trung gian tương ứng với các bước suy luận:
... - Nút đầu cuối tương ứng với câu trả lời:
...
Với tinh thần nghiên cứu nhiều “núm” mở rộng quy mô hơn, việc triển khai của tôi sử dụng MCTS song song, trong đó N tác nhân chia sẻ cùng một cây tìm kiếm trên mỗi mẫu và sử dụng các tổn thất ảo để khuyến khích sự đa dạng trong tìm kiếm.
Bắt đầu từ mỗi nút lá, chúng tôi tạo ra K lần hoàn thành cho đến khi gặp thẻ dừng . Các chuỗi K này tạo thành không gian hành động của chúng tôi cho nút cụ thể đó.
Vì pUCT yêu cầu các ưu tiên cấp hành động nên chúng tôi tính toán các logprob tổng hợp ở cấp độ trình tự và áp dụng hàm softmax để có được các ưu tiên tương đối. Những điều này chơi tốt vì xác suất chuỗi tích lũy thô trở nên cực kỳ nhỏ và không ổn định về mặt số lượng.
MCTS thường sử dụng đầu giá trị $V(s_t)$ để cải thiện quá trình đào tạo và giúp hướng dẫn quá trình tìm kiếm theo quỹ đạo tốt hơn. Điều này được triển khai dưới dạng MLP, sau đó là hàm tanh được áp dụng cho trạng thái ẩn cuối cùng của máy biến áp.
Phương pháp này có điểm tương đồng với TS-LLM (Feng et al., 2023), phương pháp này cũng kết hợp tìm kiếm cây kiểu AlphaZero với hàm giá trị đã học qua các hành động ở cấp độ câu.
Sự khác biệt chính là:
- Sử dụng RL trực tuyến (CISPO/PPO) thay vì SFT để chưng cất
- MCTS song song với tổn thất ảo là trục chia tỷ lệ bổ sung
Lựa chọn quỹ đạo
Thông thường với trò chơi board MCTS, tín hiệu huấn luyện đến từ việc giảm thiểu sự khác biệt KL giữa chính sách tìm kiếm ở nút gốc và chính sách thô mà mô hình dự đoán. Tuy nhiên, vì có sự không khớp về độ chi tiết của không gian hành động của chúng ta so với không gian hành động của mô hình thô (các bước suy luận so với mã thông báo), nên chúng ta cần phải làm điều gì đó khác. Cách tiếp cận mà tôi sử dụng là sau khi tất cả công nhân hoàn thành M lần lặp của thuật toán cho một mẫu cụ thể, họ sẽ thực hiện quy trình lựa chọn tham lam:
- Bắt đầu từ gốc, chọn quỹ đạo theo số lượt truy cập tối đa
- Gửi quỹ đạo này tới vùng đệm chung để sử dụng cho việc đào tạo PPO
Đào tạo
Công nhân được chỉ định là "người huấn luyện" lấy mẫu không đồng bộ từ bộ đệm dùng chung. Họ sử dụng trình tối ưu hóa AdamW và thực hiện một bước bên trong PPO duy nhất cho từng lô mẫu B, với CISPO là loại tổn thất của chúng tôi.
Mục tiêu đào tạo là giảm thiểu tổng tổn thất $L_{total}$:
$L_{total} = c_{ppo} L_{ppo} + c_{value} L_{value} + c_{KL}\, \mathbb{D__{KL}(\pi_\theta \mid\mid \pi_{ref})$
$L_{cispo} = -\mathbb{E}\left[sg(\min(\frac{\pi_\theta(a_t \mid s_t)}{\pi_{old}(a_t \mid s_t)}), \epsilon) \cdot A_t \cdot \log \pi_\theta(a_t \mid s_t) \right]$
trong đó $A_t = r_{terminal} - sg\!\left(V_{old}(s_t)\right)$ là lợi thế cấp độ mã thông báo (chúng tôi chỉ định phần thưởng thiết bị đầu cuối giống nhau cho mỗi mã thông báo). Tôi đã không sử dụng GAE vì dấu vết lý luận có thể mở rộng tới hàng nghìn mã thông báo và với phần thưởng cuối cùng, các mã thông báo sớm sẽ được giảm giá theo cấp số nhân xuống các giá trị nhỏ không đáng kể.
$L_{value} = \mathbb{E} \left[(V(s_t) - r)^2\right]$
$\mathbb{D__{KL}(\pi_\theta \mid\mid \pi_{ref}) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{ref}(a_t \mid s_t)} - \log \frac{\pi_\theta(a_t \mid s_t)}{\pi _{ref}(a_t \mid s_t)} - 1$ (từ bài báo DeepSeek-R1)
Chúng tôi thực hiện quá trình đào tạo cho đến khi điểm đánh giá ổn định.
Cơ sở hạ tầng
Tất cả các thử nghiệm được thực hiện trên nút 8xH100 từ Andromeda. Đối với MCTS, sáu GPU được chỉ định làm máy phát điện, trong khi hai GPU là máy huấn luyện. Một nhân viên Rust lấy mẫu các câu hỏi từ tập dữ liệu và gửi yêu cầu suy luận đến nhóm trình tạo được hiển thị thông qua gRPC. Họ ghi các quỹ đạo đã chọn vào luồng Redis; giảng viên liên tục lấy mẫu từ đây. Trọng số được đồng bộ hóa giữa trình tạo và trình huấn luyện sau mỗi 8 bước chuyển màu bằng Redis pub/sub.
Đường cơ sở
Tôi đã chạy đường cơ sở CISPO với quy mô lô toàn cầu là 128 mẫu và quy mô nhóm là 16, dẫn đến kích thước lô hiệu quả là 2048. Nhật ký được tính toán trong float32 theo ScalRL. Một lần nữa, quá trình đào tạo diễn ra cho đến khi điểm đánh giá ổn định. Tất cả tám GPU đều được sử dụng để huấn luyện CISPO và không có sự phân chia giữa trình huấn luyện/trình tạo.
Để tách biệt giá trị gia tăng của cấu trúc cây, tôi đã chạy thử nghiệm trong đó quỹ đạo gửi đến vùng đệm huấn luyện của chúng tôi được chọn thông qua “best-of-N” (N=64) thay vì tìm kiếm trong cây.
Kết quả
Chúng tôi sử dụng Mean@16 để đánh giá mô hình. Điều này có nghĩa là chạy 16 thế hệ cho mỗi lời nhắc đánh giá, chấm điểm chúng với phần thưởng 0/1 thưa thớt và tính trung bình các kết quả. Trong quá trình đánh giá, chính sách được chắt lọc MCTS không có khai thác tìm kiếm đạt được điểm trung bình tiệm cận@16 là 11,3%, trong khi mô hình CISPO tiệm cận ở mức 8,4% và Best-of-N hoạt động kém nhất, ổn định ở mức 7,7%.
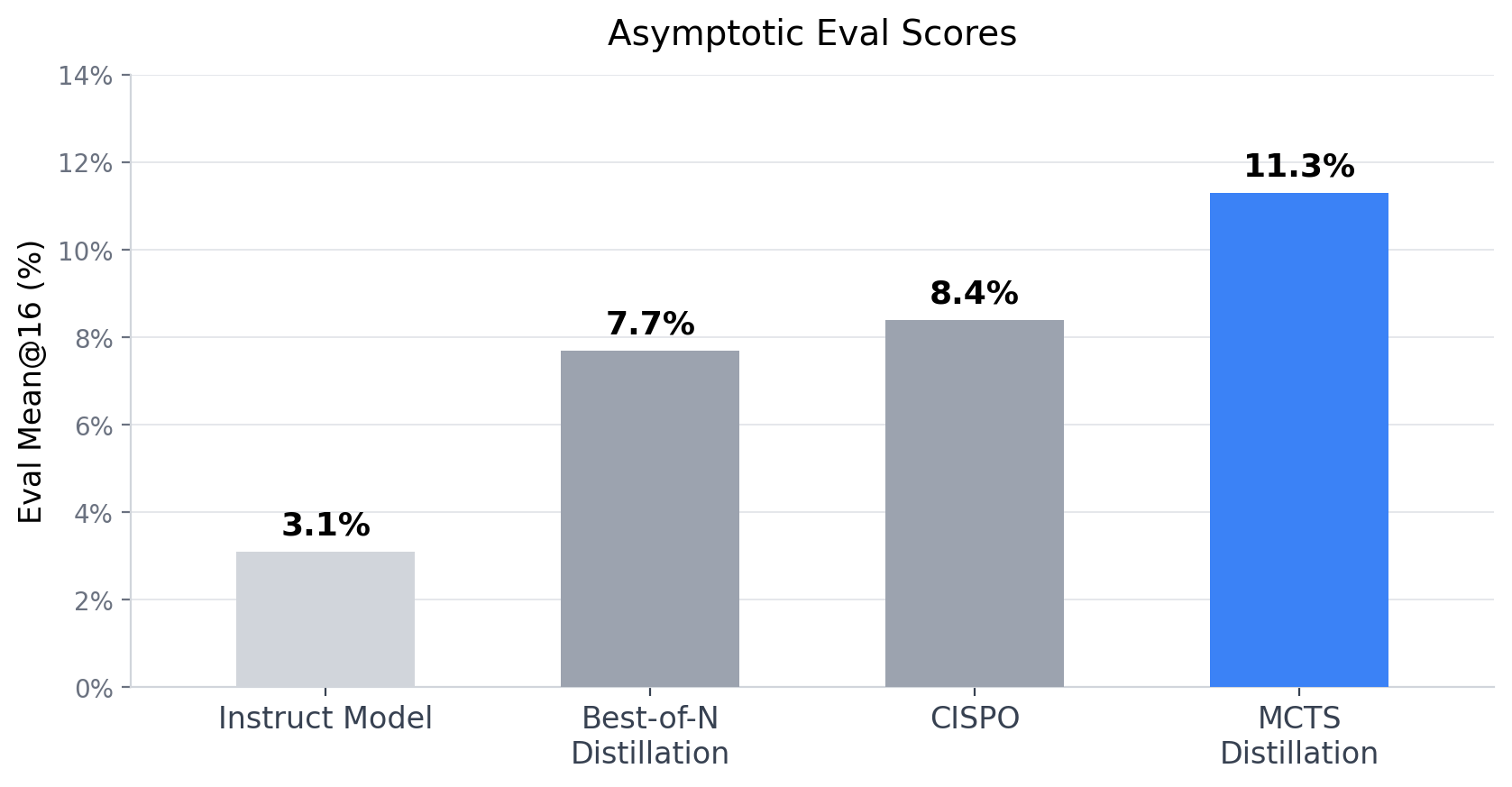
Đáng ngạc nhiên là tôi cũng nhận thấy rằng mặc dù phần thưởng đào tạo cao hơn đáng kể, nhưng quá trình chưng cất “best-of-N” lại hoạt động kém hơn cả CISPO và MCTS trên bộ đánh giá. Mặc dù không hoàn toàn rõ ràng lý do tại sao, nhưng chúng tôi có thể đưa ra giả thuyết: nếu mô hình của chúng tôi có 98% khả năng mắc ít nhất một lỗi suy luận trong quá trình suy nghĩ, thì vẫn có $1 - 0,98^{64} \approx 72,6 \%$ cơ hội chọn ít nhất một quỹ đạo đúng. Nhưng nếu không có động lực để đưa ra lý luận chắc chắn mọi lúc, thì mô hình khó có thể học cách phát triển các chiến lược để cải thiện điểm số từng lần. Ở trường cấp hai, tôi đã sử dụng một số kỹ thuật để theo dõi các bước trung gian khi giải toán. Điều này làm giảm đáng kể khả năng mắc những “sai lầm ngớ ngẩn” trong kỳ thi. Nếu tôi được lựa chọn làm bài thi nhiều lần thì tôi sẽ không bao giờ áp dụng những kỹ thuật đó!
Mã
Tất cả mã đều là mã nguồn mở và có thể tìm thấy tại đây.
Định hướng tương lai
Vậy điều này có nghĩa là gì? Phần khiến tôi phấn khích ở đây là các nút lý luận bổ sung mà chúng tôi có thể điều chỉnh, chẳng hạn như số lượng công nhân song song trên mỗi cây hoặc số lần lặp MCTS. Tôi chưa điều chỉnh những giá trị này một cách chính xác, nhưng những thử nghiệm ban đầu cho thấy việc tăng cả hai giá trị này sẽ dẫn đến hiệu suất tăng đáng kể. Vì vậy tôi muốn khám phá thêm hướng này! Có rất nhiều việc phải làm để nhân rộng phương pháp này và lập biểu đồ các xu hướng thực nghiệm để đánh giá tiềm năng của nó đối với các mô hình lớn hơn và tính toán ngân sách. Hãy liên hệ nếu bạn muốn cộng tác!
Bây giờ cần lưu ý: có thể đây là một "hiện tượng mô hình nhỏ" và phương pháp này không có quy mô lớn như GRPO đối với các mô hình lớn hơn, v.v. Có thể điều chỉnh đường cơ sở GRPO (CISPO) để phù hợp với MCTS không? Có lẽ vậy, nhưng ScalRL nhận thấy rằng hầu hết các siêu tham số cho GRPO đều điều chỉnh hiệu quả tính toán chứ không phải mức trần phần thưởng cuối cùng.
Người ta có thể lưu ý rằng MCTS sử dụng nhiều tính toán suy luận trên cơ sở từng mẫu hơn GRPO: tất nhiên là nó hoạt động tốt hơn! Tuy nhiên, mục tiêu ở đây không phải là so sánh tính toán giữa táo với táo; có, MCTS sử dụng nhiều tính toán theo thời gian suy luận hơn, nhưng nó cũng cung cấp cho chúng tôi các đòn bẩy bổ sung để áp dụng/mở rộng quy mô tính toán đó và tăng trần phần thưởng. Trong khi đó, tôi không thấy rõ rằng việc ném thêm máy tính gấp 100 lần vào GRPO sẽ biến cao nguyên thành một cây gậy khúc côn cầu.
Lời cảm ơn
Tôi muốn cảm ơn nhóm Andromeda và Molly Mielke McCarthy vì đã tài trợ cho máy tính cho dự án này, cũng như Tom McCarthy và Joe Melkonian vì đã đọc qua những bản nháp đầu tiên của bài đăng này và đưa ra những phản hồi có giá trị. Tôi cũng muốn cảm ơn Finbarr Timbers vì bài đăng trên blog đã đóng vai trò là động lực cho công việc này.
Bảng giá trị
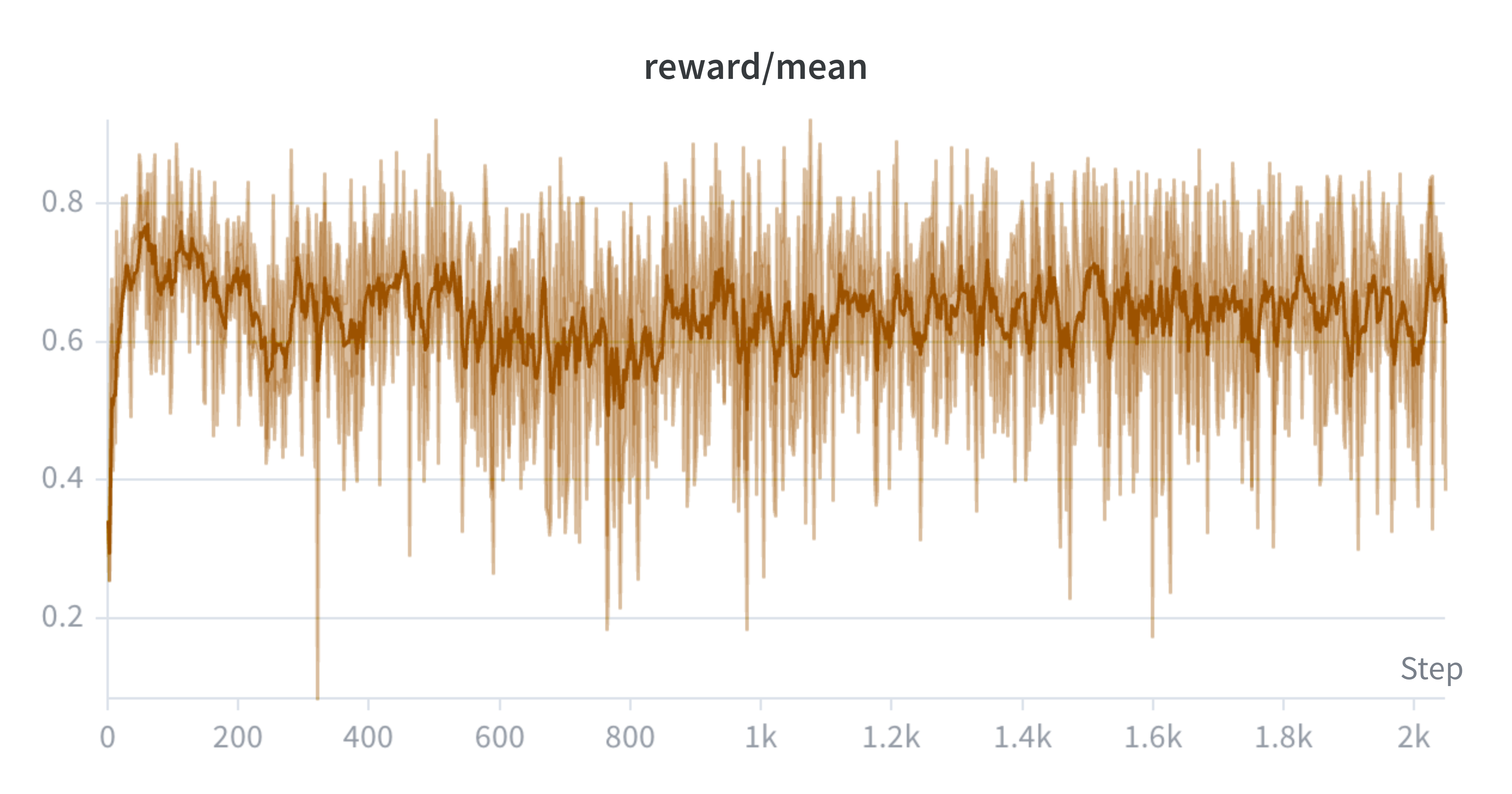
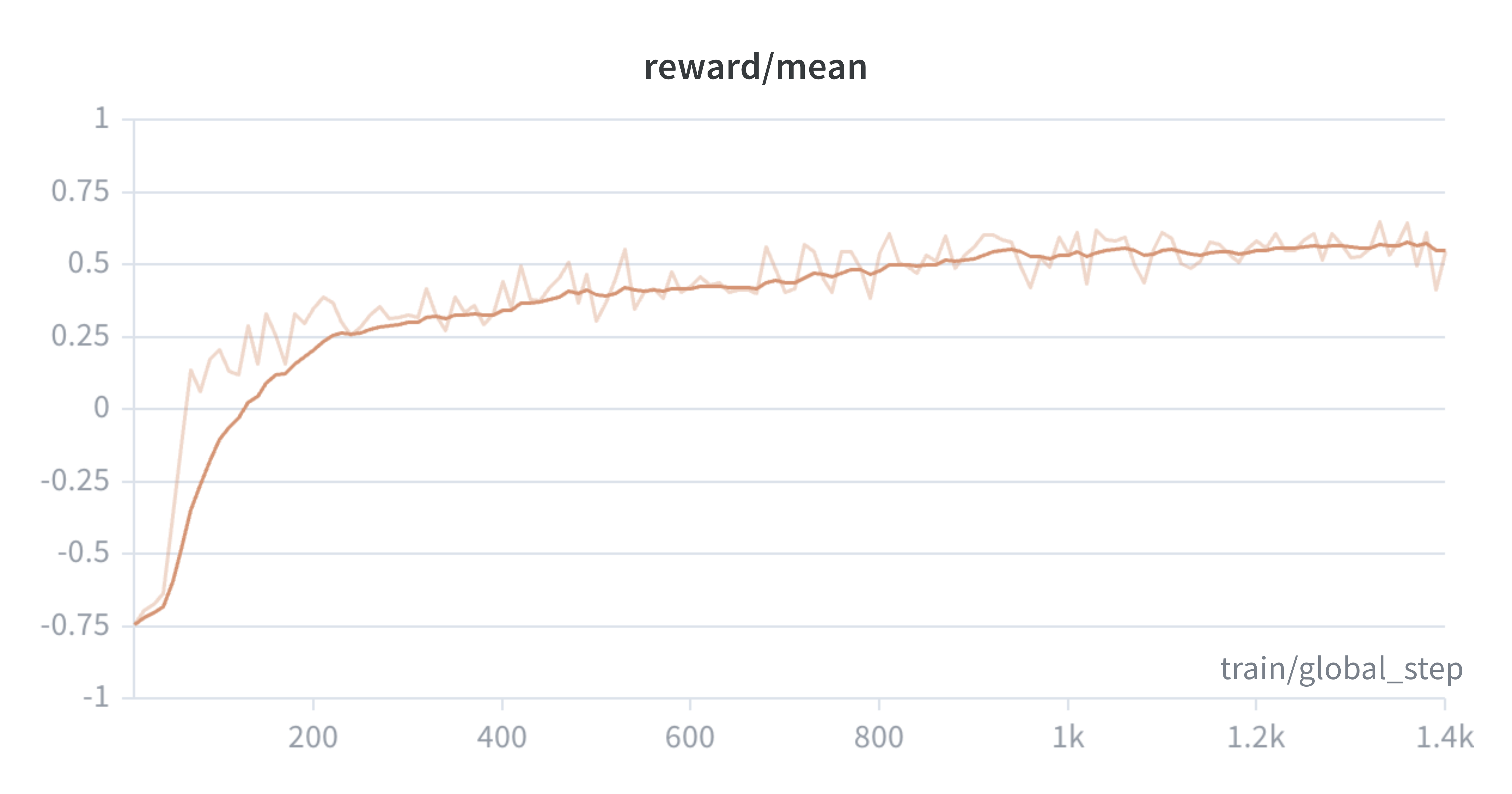
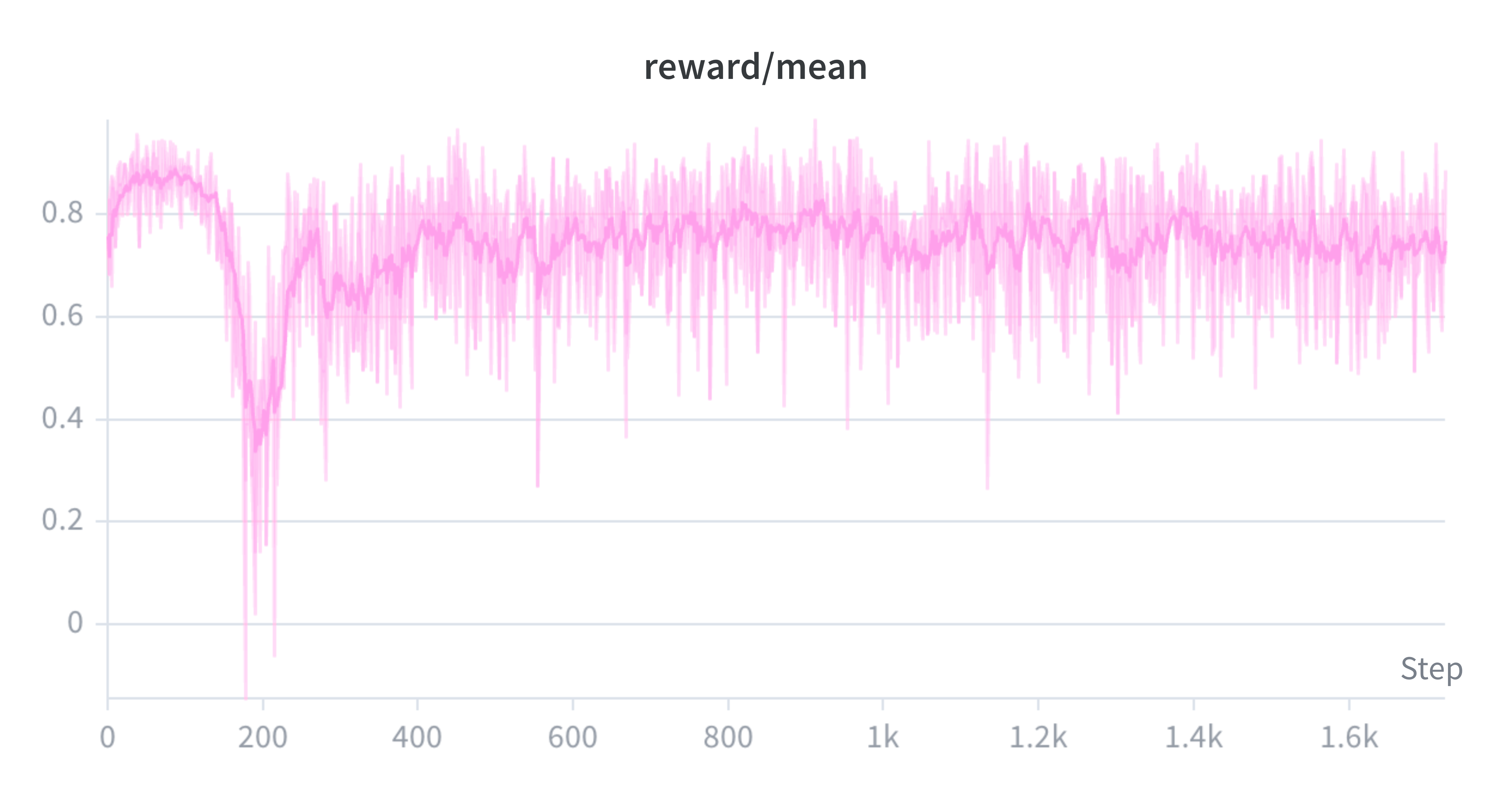
Phụ lục: Đường cong thực nghiệm
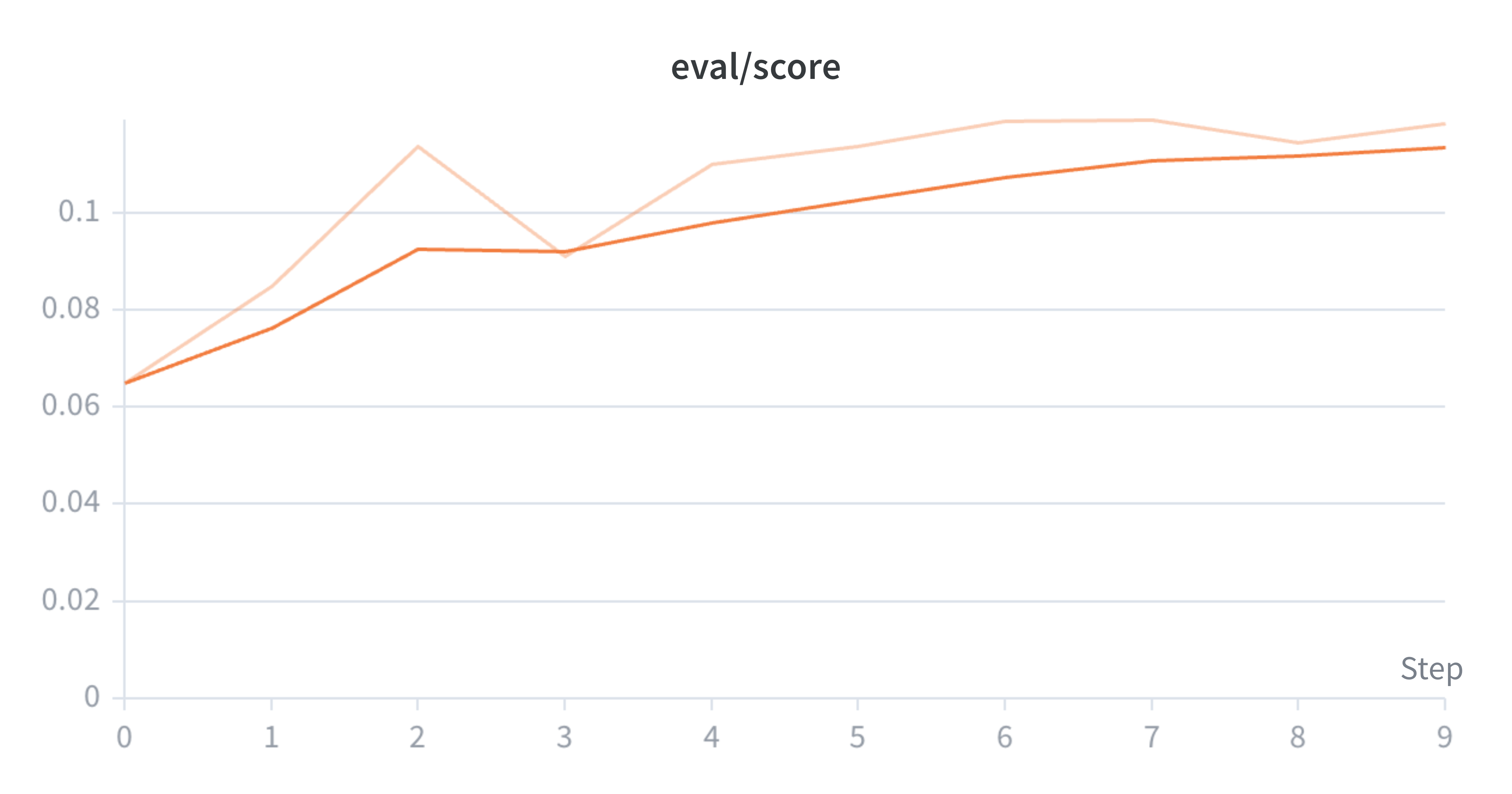
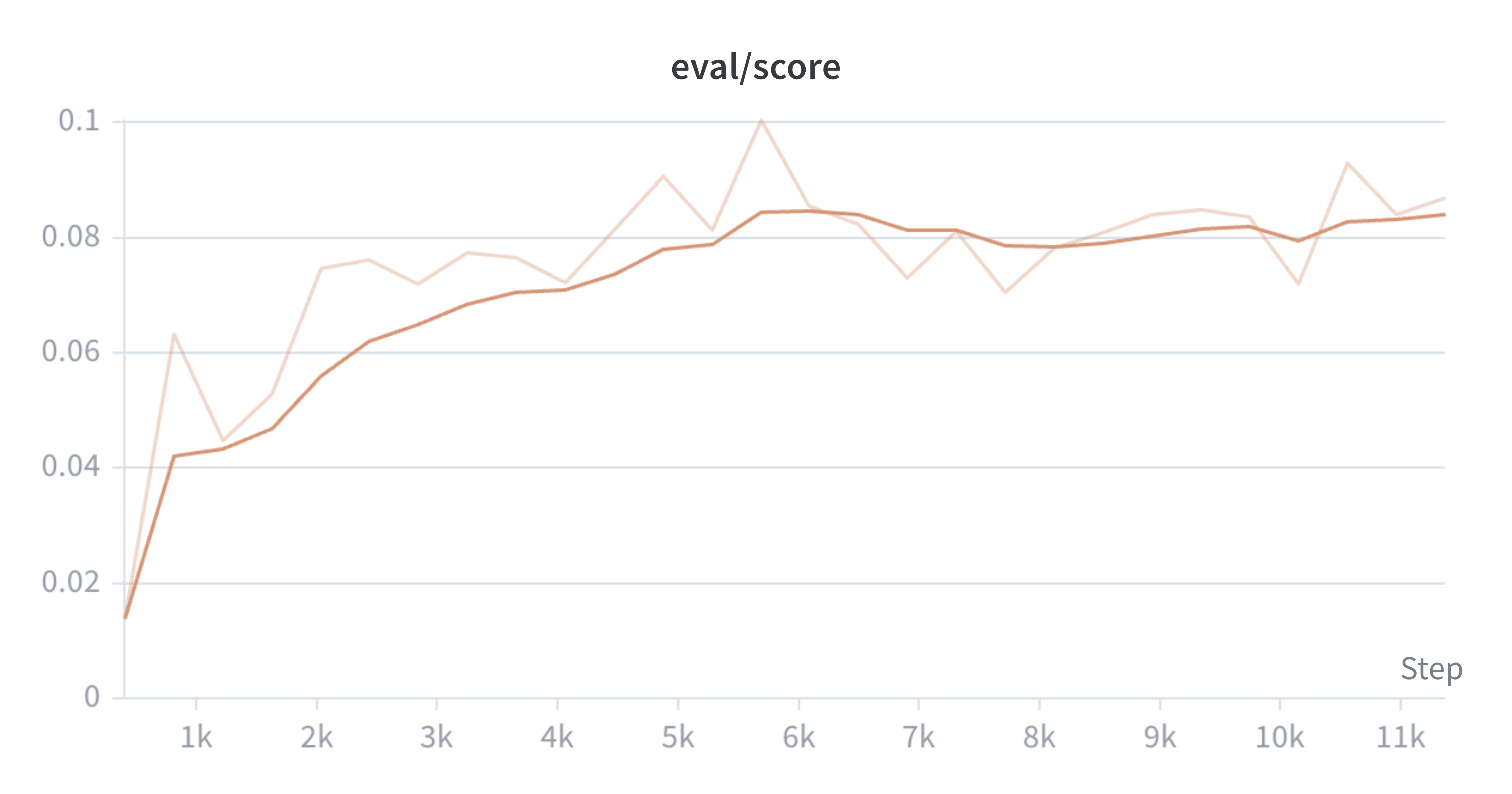
Lưu ý rằng chúng tôi sử dụng nhịp ghi nhật ký khác nhau cho mỗi lần chạy, đó là một phần lý do khiến giới hạn trục x khác nhau. Chúng tôi đào tạo người mẫu cho đến khi điểm đánh giá ổn định.
Đánh giá
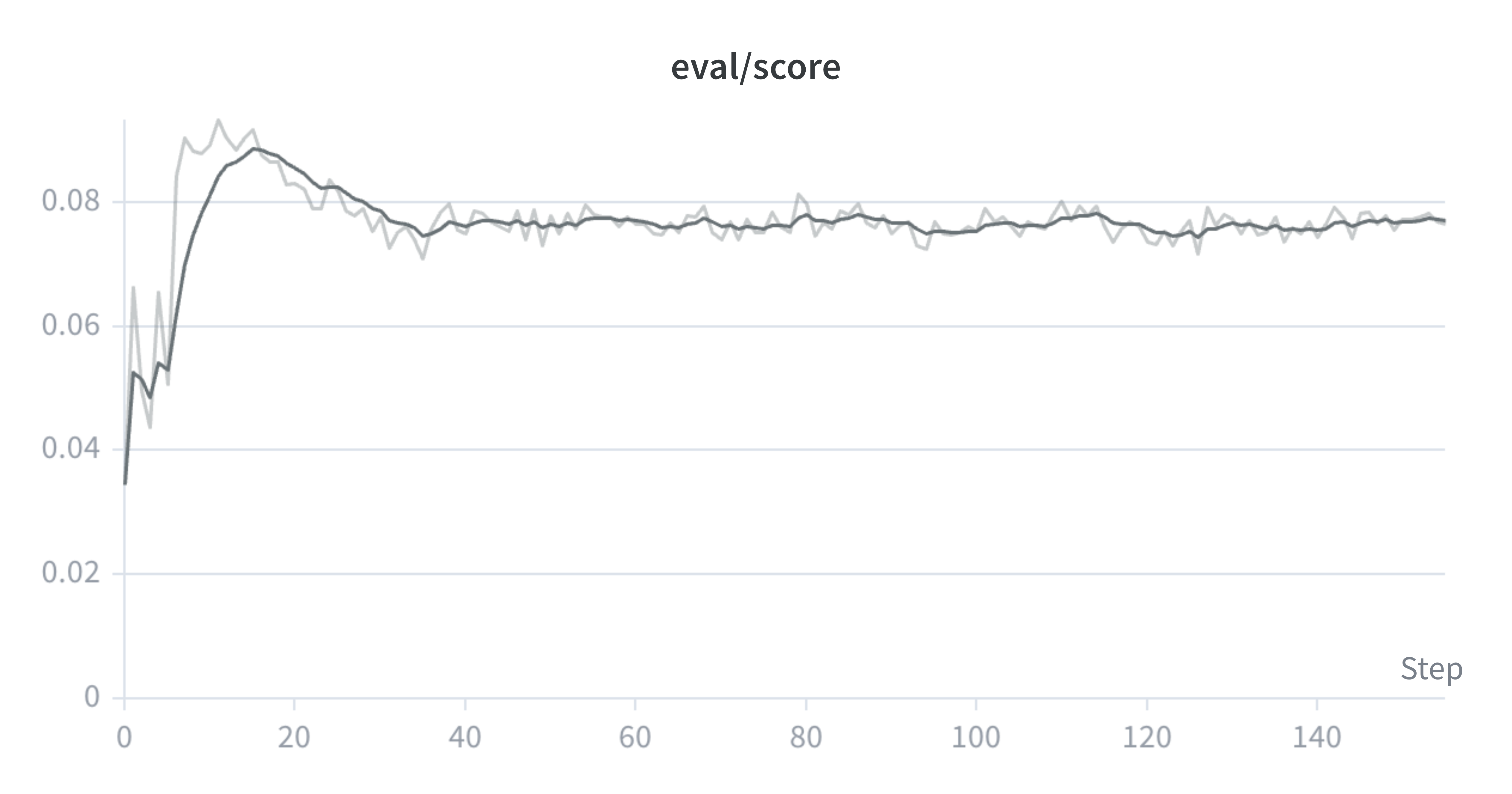
Đào tạo
Tác giả: at2005