
Sự trả thù của nhà khoa học dữ liệu
The revenge of the data scientist
test
Thời hoàng kim của nhà khoa học dữ liệu đã qua? Tạp chí Harvard Business Review từng gọi nó là “Công việc quyến rũ nhất thế kỷ 21”.1 Trong lĩnh vực công nghệ, vai trò nhà khoa học dữ liệu thường nằm trong số những công việc được trả lương cao nhất.2 Công việc này cũng...
Thời hoàng kim của nhà khoa học dữ liệu đã qua chưa? Tạp chí Harvard Business Review từng gọi đây là “Công việc quyến rũ nhất thế kỷ 21”.1 Trong công nghệ, vai trò nhà khoa học dữ liệu thường nằm trong số những vị trí được trả lương cao nhất.2 Công việc này cũng đòi hỏi sự kết hợp các kỹ năng khác thường:
Nhà khoa học dữ liệu (n.): Người giỏi thống kê hơn bất kỳ kỹ sư phần mềm nào và giỏi công nghệ phần mềm hơn bất kỳ nhà thống kê nào.
— JosH100 (@josh_wills) Ngày 3 tháng 5 năm 2012Ngoài việc tạo ra rào cản gia nhập cao, những kỹ năng này còn cho phép các nhà khoa học dữ liệu xây dựng các mô hình dự đoán, đo lường mức độ thương vong và tìm ra các mẫu trong dữ liệu. Trong số này, mô hình dự đoán được trả lương cao nhất. Sau đó, các công ty đã tách công việc đó thành một chức danh mới: Kỹ sư máy học (“MLE”).3
Trong nhiều năm, việc vận chuyển AI có nghĩa là giữ các nhà khoa học dữ liệu và MLE đi đúng hướng. Với LLM, điều này không còn là mặc định nữa. API mô hình nền tảng hiện cho phép các nhóm tích hợp AI một cách độc lập.
Việc bị loại khỏi vòng lặp khiến các nhà khoa học dữ liệu và MLE lo lắng mà tôi biết. Nếu công ty không còn cần bạn vận chuyển AI nữa, thật công bằng khi tự hỏi liệu công việc này có còn ưu điểm tương tự hay không. Câu chuyện khắc nghiệt hơn mà mọi người tự nhủ: trừ khi bạn đang được đào tạo trước tại phòng thí nghiệm mô hình nền tảng, nếu không bạn sẽ không ở nơi hành động.
Tôi đọc nó theo cách khác. Các mô hình đào tạo chưa bao giờ là công việc quan trọng nhất. Phần lớn công việc là thiết lập các thử nghiệm để kiểm tra xem AI khái quát hóa dữ liệu chưa nhìn thấy tốt như thế nào, gỡ lỗi các hệ thống ngẫu nhiên và thiết kế các số liệu tốt. Việc gọi LLM qua API không làm mất đi công việc này.
Gần đây tôi đã có một buổi nói chuyện có tiêu đề “Sự trả thù của nhà khoa học dữ liệu” tại PyAI Conf để chứng minh trường hợp đó bằng các ví dụ thay vì chỉ khẳng định. Dưới đây là phiên bản có chú thích của bài thuyết trình đó.

Khai thác là khoa học dữ liệu
OpenAI đã xuất bản một bài đăng trên blog về kỹ thuật khai thác mà tôi khuyên bạn nên đọc. Họ mô tả cách Codex làm việc trên một dự án phần mềm trong nhiều tháng một cách tự chủ, với các nhân viên phát triển mã được bao bọc bởi nhiều thử nghiệm và thông số kỹ thuật.

Một chi tiết trong bài viết blog đó rất dễ bị bỏ sót. Khai thác bao gồm một ngăn xếp khả năng quan sát: nhật ký, số liệu và dấu vết được hiển thị cho tác nhân để tác nhân có thể biết khi nào nó đi chệch hướng. Ngoài các bài kiểm tra và thông số kỹ thuật, còn có các số liệu. Đó là thành phần then chốt của hệ thống.
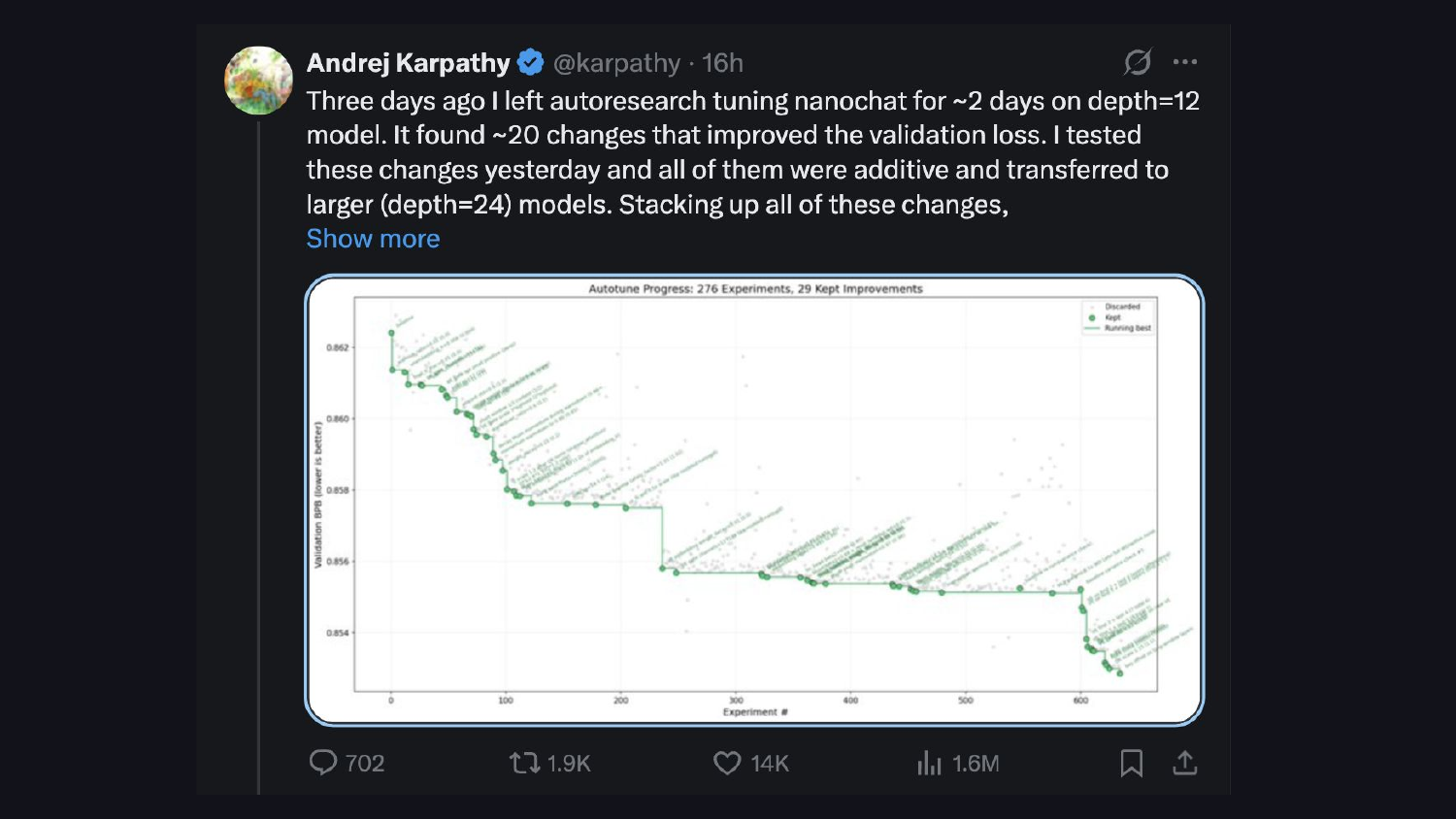
dự án nghiên cứu tự động của Andrej Karpathy cho thấy cùng một mô hình: các mô hình tối ưu hóa lặp lại theo chỉ số tổn thất xác thực. Cùng một ý tưởng, khác nhau về dây nịt.

Điều tôi muốn thuyết phục bạn là phần lớn khai thác là khoa học dữ liệu.
Hãy lùi lại một bước và xem xét vị trí của chúng ta.

Nhiều năm trước, những người thực hành đã dành hàng giờ để kiểm tra dữ liệu, kiểm tra sự liên kết của nhãn và thiết kế các số liệu. Ngày nay, chúng tôi xây dựng dựa trên “sự rung cảm”, hỏi mô hình xem nó có hoạt động tốt không và lấy các thư viện số liệu có sẵn mà không cần xem dữ liệu.

Điều này xuất hiện nhiều nhất trong quá trình truy xuất và đánh giá. Không có nền tảng dữ liệu, các kỹ sư lo sợ những gì họ không hiểu. Họ tuyên bố “RAG đã chết” hoặc “evals đã chết”, nhưng vẫn xây dựng các hệ thống phụ thuộc vào những khái niệm đó.
Phần còn lại của bài đăng này sẽ đề cập đến 5 cạm bẫy đánh giá mà tôi gặp nhiều lần và cách mà một nhà khoa học dữ liệu sẽ làm khác nhau trong mỗi trường hợp.
Chỉ số chung
Cạm bẫy đầu tiên là các chỉ số chung chung.

Việc tìm kiếm một khung đánh giá và sử dụng các số liệu sẵn có của nó là điều rất hấp dẫn. Vấn đề: bạn không biết cái gì thực sự bị hỏng. Hầu hết các đội đều đưa ra một bảng thông tin với điểm hữu ích, điểm mạch lạc, điểm ảo giác. Những điều này nghe có vẻ hợp lý. Chúng cũng đủ chung chung nên vô dụng trong việc chẩn đoán lỗi ứng dụng của bạn.
Một nhà khoa học dữ liệu sẽ không áp dụng các số liệu sẵn có. Họ sẽ khám phá dữ liệu, khám phá dấu vết, hỏi “điều gì thực sự đang xảy ra ở đây?” và tìm ra thứ có giá trị cao nhất để bắt đầu đo lường. Có vô số thứ để đo lường. Bạn phải hình thành các giả thuyết và lặp lại.
Phương thuốc tốt nhất cho cạm bẫy này là xem xét dữ liệu.
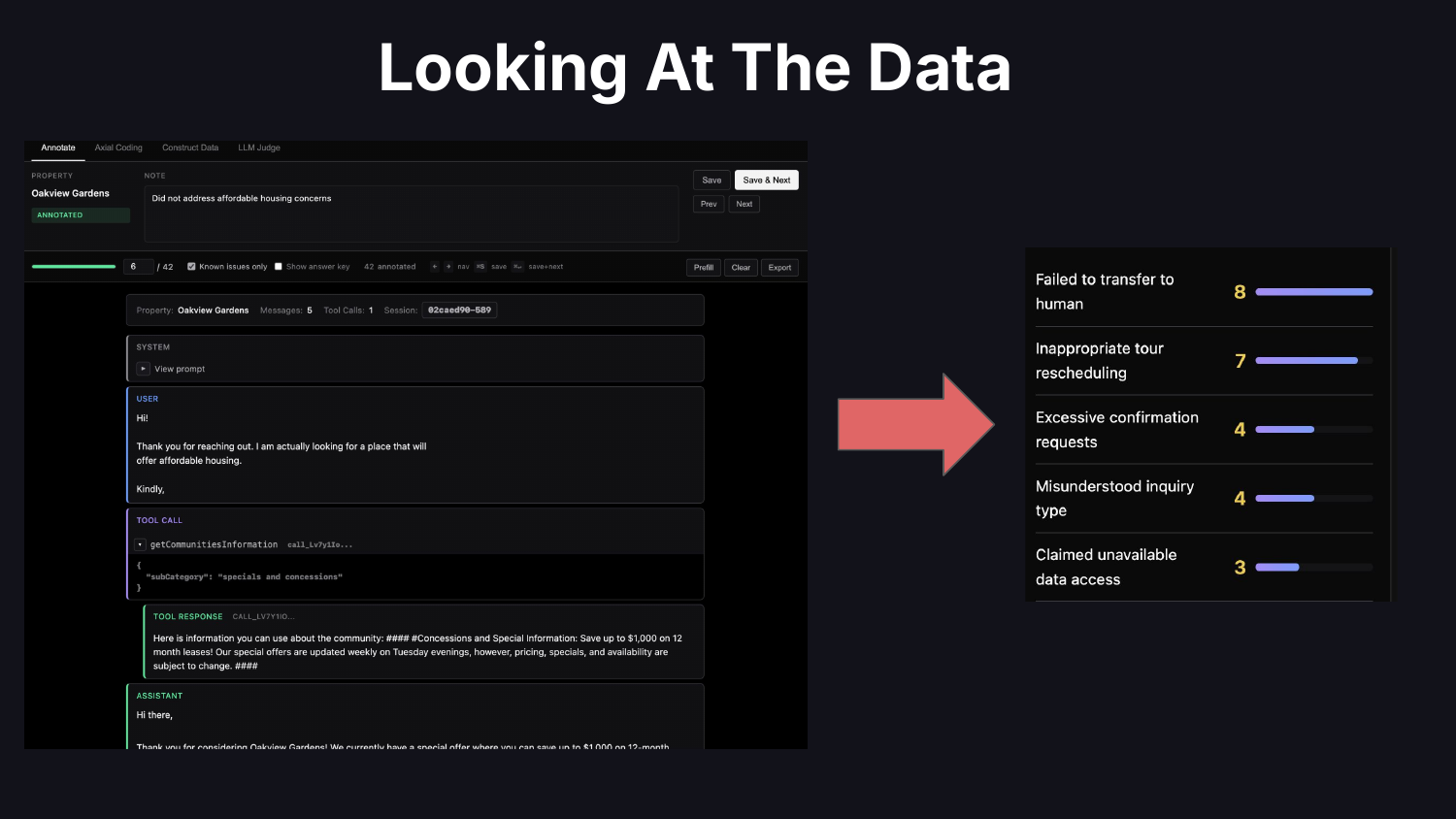
Trong thực tế, việc “xem xét dữ liệu” có ý nghĩa gì? Nó có nghĩa là đọc dấu vết. Viết mã trình xem dấu vết tùy chỉnh của riêng bạn để bạn có thể loại bỏ khó khăn và tùy chỉnh hiển thị cho các đặc điểm riêng của miền của mình. Ghi chú về các vấn đề bạn tìm thấy. Thực hiện phân tích lỗi: phân loại lỗi, tìm ra những việc cần ưu tiên, quyết định những việc cần làm.
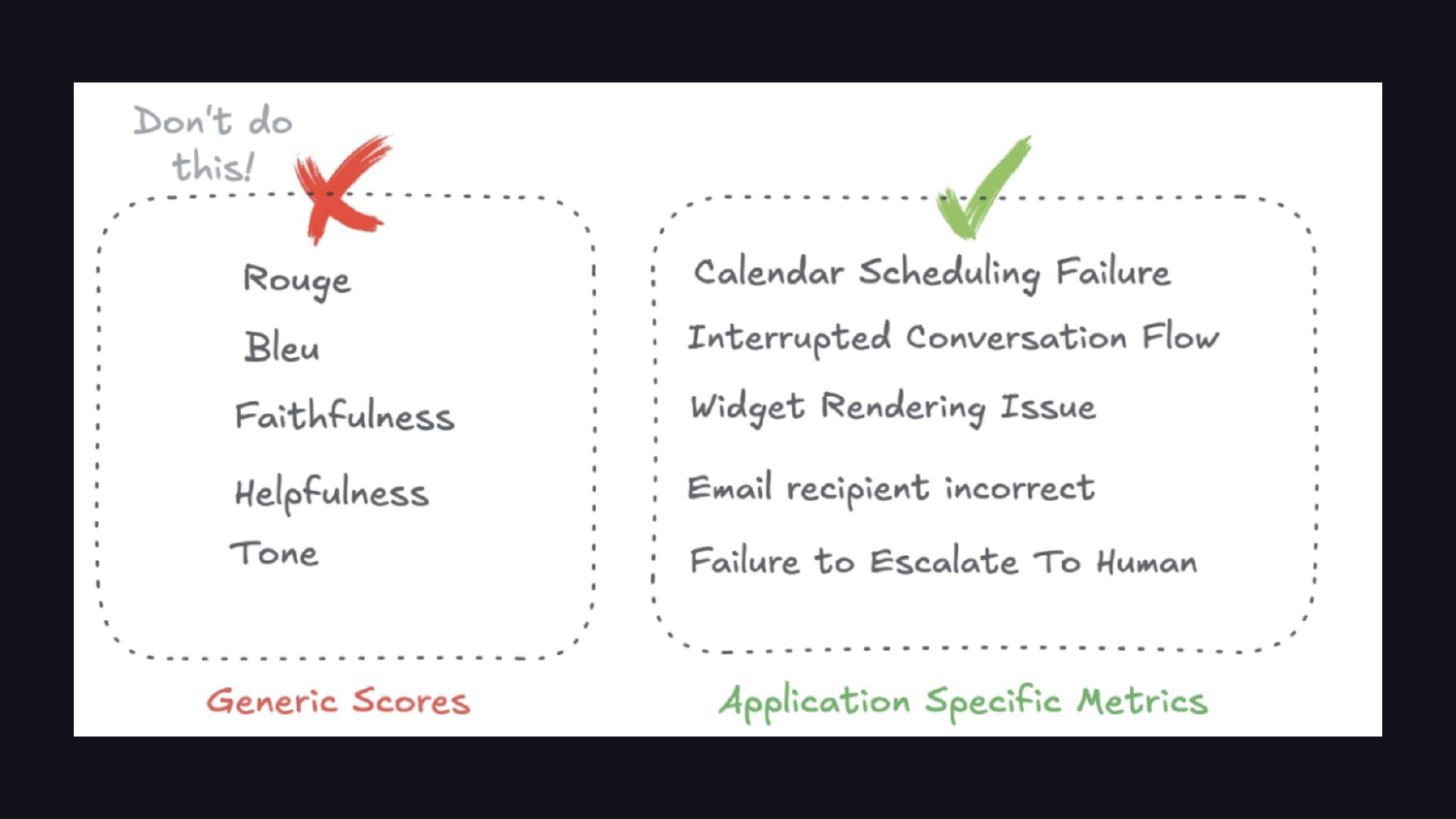
Khi xem xét dữ liệu của mình, bạn sẽ hướng tới các chỉ số dành riêng cho ứng dụng. Các số liệu tương tự có sẵn như ROUGE hoặc BLEU hiếm khi phù hợp với đầu ra LLM. Các chỉ số quan trọng giống như “Lỗi lập kế hoạch lịch” hoặc “Không thể chuyển sang con người”.

Nếu có một điều cần rút ra từ bài đăng này: hãy nhìn vào dữ liệu. Làm thế nào để nhìn vào nó là một câu hỏi riêng biệt và cần phải thực hành. Đây là hoạt động ROI cao nhất mà bạn có thể tham gia và thường bị bỏ qua.
Thẩm phán chưa được xác minh
Cạm bẫy thứ hai là các thẩm phán chưa được xác minh. Rất nhiều nhóm sử dụng LLM làm giám khảo để tìm hiểu xem AI của họ có hoạt động hay không. Trong hầu hết mọi trường hợp, không ai có câu trả lời thỏa đáng cho câu hỏi “làm thế nào để bạn tin tưởng thẩm phán?”

Mặc định: yêu cầu LLM xếp hạng kết quả đầu ra theo thang điểm và sử dụng các con số. Một nhà khoa học dữ liệu sẽ coi thẩm phán như một người phân loại. Bạn có một hộp đen đưa ra dự đoán cho bạn. Làm thế nào để bạn tin tưởng nó? Nhận nhãn của con người, phân chia dữ liệu thành huấn luyện/nhà phát triển/kiểm tra và đo lường xem trình phân loại có đáng tin cậy hay không.
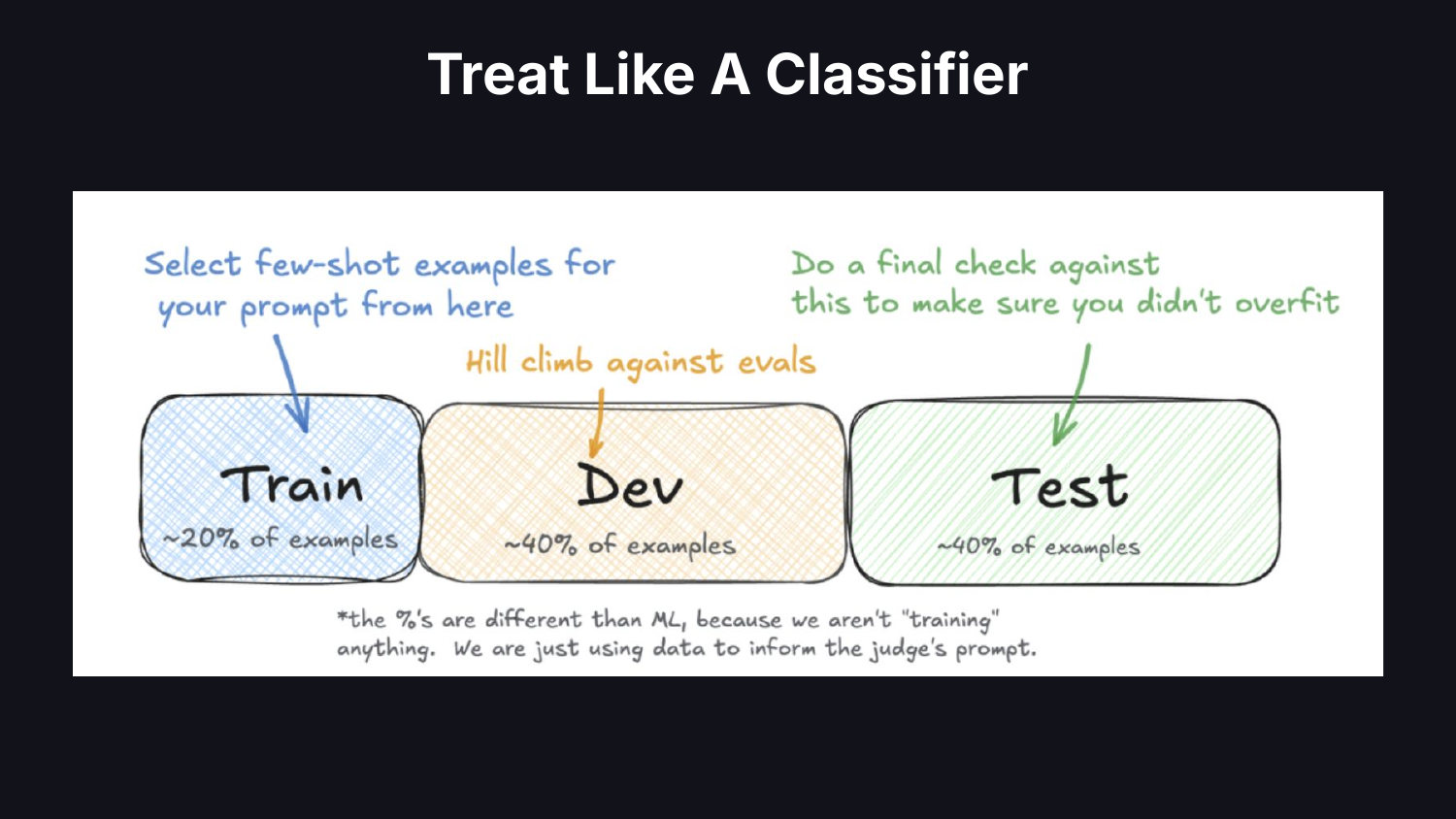
Lấy các ví dụ về một vài cảnh quay từ tập huấn luyện của bạn. Leo dốc theo lời nhắc của giám khảo đối với nhóm nhà phát triển. Hãy để một bài kiểm tra sang một bên để xác nhận rằng bạn không tập luyện quá sức. Nếu bạn đã từng học máy trước đây thì điều này thật nhàm chán. Nhưng mọi người không làm điều đó. Việc xác minh các bộ phân loại đã trở thành một nghệ thuật đã bị lãng quên trong AI hiện đại.

Hãy đối xử với người đánh giá như người phân loại trong cách bạn báo cáo kết quả. Đi đến đâu tôi cũng thấy báo cáo chính xác. Nếu chế độ lỗi xảy ra trong 5% thời gian, độ chính xác sẽ che giấu hiệu suất thực sự của hệ thống. Sử dụng độ chính xác và thu hồi.
Thiết kế thử nghiệm tồi
Cạm bẫy thứ ba là thiết kế thử nghiệm. Có nhiều chiều hướng cho điều này. Đây là hai cái xuất hiện nhiều nhất.

Đầu tiên là xây dựng bộ thử nghiệm. Hầu hết các nhóm tạo dữ liệu tổng hợp bằng cách nhắc LLM: “Hãy cho tôi 50 truy vấn kiểm tra”. Họ nhận được dữ liệu chung chung, không mang tính đại diện. Trước tiên, nhà khoa học dữ liệu sẽ xem xét dữ liệu sản xuất thực tế, sử dụng các giả thuyết để xác định những thứ nguyên nào quan trọng, sau đó tạo ra các ví dụ tổng hợp theo các thứ nguyên đó.

Dữ liệu tổng hợp cơ bản ở dạng nhật ký hoặc dấu vết thực. Chỉ ra những kích thước cần thay đổi. Tiêm trường hợp cạnh. Dựa trên dữ liệu tổng hợp dựa trên dữ liệu thực.
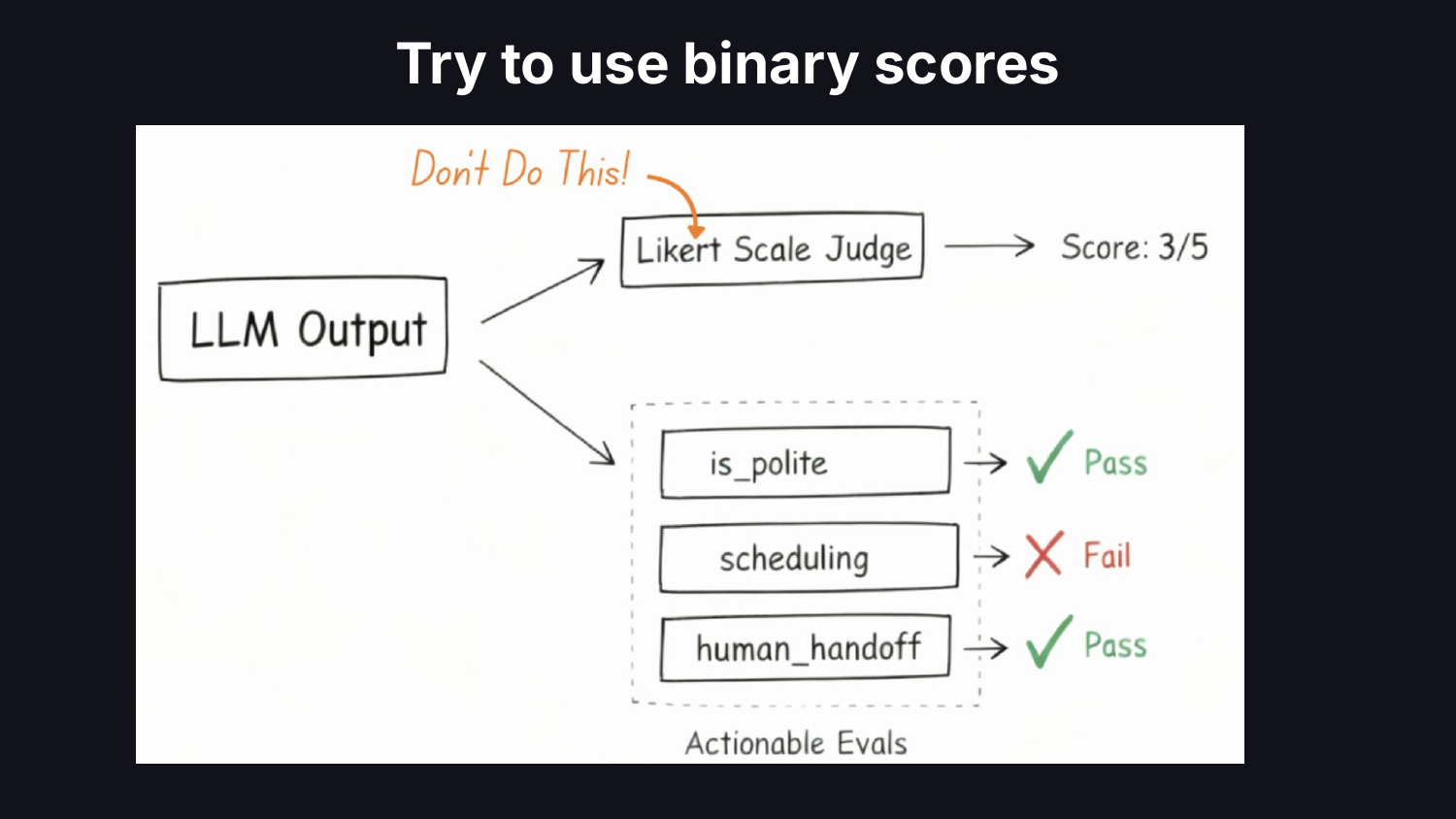
Thứ hai là thiết kế số liệu. Các nhóm gói toàn bộ phiếu tự đánh giá vào một cuộc gọi LLM duy nhất và mặc định ở thang đo Likert 1-5. Một nhà khoa học dữ liệu sẽ giảm bớt độ phức tạp, làm cho từng số liệu có thể áp dụng được và gắn nó với kết quả kinh doanh. Thay thế thang đo chủ quan bằng thang đo đạt/không đạt nhị phân trên các tiêu chí trong phạm vi. Thang đo Likert che giấu sự mơ hồ và loại bỏ những quyết định khó khăn về hiệu suất hệ thống.
Dữ liệu và nhãn xấu
Cạm bẫy thứ tư là dữ liệu và nhãn xấu. Các nhà khoa học dữ liệu không tin tưởng vào dữ liệu. Họ không tin tưởng vào nhãn hiệu. Họ không tin tưởng bất cứ điều gì. Họ hoài nghi về việc đào tạo. Các kỹ sư AI nói chung vẫn chưa xây dựng được cơ chế này.

Khi nói đến việc dán nhãn, hầu hết các nhóm đều coi đó là vấn đề của người khác. Việc gắn nhãn có vẻ không mấy hấp dẫn nên nó được giao cho nhóm phát triển hoặc thuê ngoài. Một nhà khoa học dữ liệu sẽ yêu cầu các chuyên gia về miền gắn nhãn cho dữ liệu, luôn hoài nghi về các nhãn đó và xem xét dữ liệu.

Nhưng việc ghi nhãn quan trọng vì một lý do sâu xa hơn là chất lượng của nhãn. Không thể biết bạn muốn gì trừ khi bạn nhìn vào dữ liệu. Có một khái niệm gọi là “sự trôi dạt tiêu chí”, được xác thực trong bài báo của Shreya Shankar và các đồng nghiệp: người dùng cần tiêu chí để chấm điểm kết quả đầu ra, nhưng việc chấm điểm kết quả đầu ra giúp người dùng xác định tiêu chí của họ. Mọi người không biết họ muốn gì cho đến khi họ nhìn thấy kết quả đầu ra của LLM. Bản thân quá trình ghi nhãn sẽ thể hiện những vấn đề quan trọng.

Các nhà khoa học dữ liệu ủng hộ điều này: thu hút các chuyên gia trong lĩnh vực và người quản lý sản phẩm trước dữ liệu thô chứ không phải điểm tóm tắt.
Tự động hóa quá nhiều
Cạm bẫy thứ năm là tự động hóa quá nhiều. Tất cả điều này là công việc của con người. Sự cám dỗ là tự động hóa nó đi.


LLM có thể giúp kết nối mọi thứ, viết hệ thống ống nước, tạo bản mẫu để đánh giá. Họ không thể xem dữ liệu giúp bạn, vì lý do chính xác mà chúng ta vừa thảo luận: bạn không biết mình muốn gì cho đến khi nhìn thấy kết quả đầu ra.
Những cạm bẫy khác
Chúng tôi không có thời gian để giải quyết mọi cạm bẫy. Đây là tốc độ chạy qua phần còn lại.

Lạm dụng điểm tương đồng. Hỏi thẩm phán những câu hỏi mơ hồ như “nó có hữu ích không?” Làm cho chú thích đọc JSON thô. Báo cáo điểm số chưa được hiệu chỉnh mà không có khoảng tin cậy. Dữ liệu trôi dạt, trang bị quá mức, lấy mẫu không chính xác, trang tổng quan vô nghĩa.
Bản đồ
Nếu bạn thu nhỏ thì mọi cạm bẫy ở trên đều có cùng một nguyên nhân sâu xa: thiếu kiến thức cơ bản về khoa học dữ liệu.

Đọc dấu vết và phân loại lỗi là Phân tích dữ liệu thăm dò. Xác thực thẩm phán LLM dựa trên nhãn con người là Đánh giá mô hình. Xây dựng bộ thử nghiệm đại diện từ dữ liệu sản xuất là Thiết kế thử nghiệm. Yêu cầu các chuyên gia trong miền gắn nhãn kết quả đầu ra là Thu thập dữ liệu. Giám sát xem sản phẩm của bạn có hoạt động trong sản xuất hay không là ML sản xuất. Không có điều này là mới. Tên đã thay đổi, tác phẩm thì không.
Đây là hội nghị về Python, vì vậy: Python vẫn là bộ công cụ tốt nhất để xem dữ liệu của bạn và xử lý dữ liệu.

Tôi đã xây dựng một plugin nguồn mở đi sâu hơn. Hãy trỏ nó vào quy trình đánh giá của bạn và nó sẽ cho bạn biết bạn đang làm gì sai hoặc cố gắng hết sức để làm điều đó.

Luôn xem xét dữ liệu.
Nếu bạn thích các meme trong buổi nói chuyện này thì có nhiều hơn nữa trên trang web của tôi.
Nếu bạn muốn tìm hiểu sâu hơn về bất kỳ chủ đề nào trong số này, hãy xem các trang trình bày và video ở bên dưới.
Xin cảm ơn Shreya Shankar và Bryan Bischof cho nhiều cuộc trò chuyện đã định hình nên cuộc nói chuyện này.
Video & Trang trình bày
Liên kết tới các trang trình bày
Chú thích cuối trang
https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century↩︎
https://www.forbes.com/sites/louiscolumbus/2018/01/29/data-scientist-is-the-best-job-in-america-according-glassdoors-2018-rankings/↩︎
https://www.mckinsey.com/about-us/new-at-mckinsey-blog/ai-reinvents-tech-talent-opportunities↩︎
Tác giả: hamelsmu