Sáu (rưỡi) trực giác về sự phân kỳ của KL
Six (and a half) intuitions for KL divergence
Bài viết này tổng hợp nhiều khung lý thuyết khác nhau để làm sáng tỏ KL divergence – một chỉ số quen thuộc trong machine learning nhưng thường gây nhầm lẫn do tính chất không đối xứng và giá trị không bị chặn. Thông qua các góc nhìn như "expected surprise" (độ bất ngờ kỳ vọng), "suboptimal coding" (mã hóa chưa tối ưu) và "maximum likelihood estimation" (ước lượng hợp lý cực đại), tác giả chỉ ra rằng KL divergence thực chất đo lường "chi phí thông tin" hoặc "hình phạt hiệu năng" khi mô hình ($Q$) của bạn chệch khỏi phân phối dữ liệu gốc ($P$). Đối với các lập trình viên, đây là bộ công cụ thực tế giúp bạn hiểu rõ tình trạng lệch mô hình (model mismatch), từ đó nắm bắt được tại sao việc tối thiểu hóa KL divergence về mặt toán học lại tương đương với việc tối ưu hóa cho likelihood.
Phân kỳ KL là một chủ đề xuất hiện ở rất nhiều nơi khác nhau trong lý thuyết thông tin và học máy, vì vậy điều quan trọng là phải hiểu rõ. Thật không may, nó có một số đặc tính dường như...
Phân kỳ KL là một chủ đề xuất hiện ở rất nhiều nơi khác nhau trong lý thuyết thông tin và học máy, vì vậy điều quan trọng là phải hiểu rõ. Thật không may, nó có một số thuộc tính có vẻ khó hiểu ở lần vượt qua đầu tiên (ví dụ: nó không đối xứng như chúng ta mong đợi từ hầu hết các phép đo khoảng cách và nó có thể không bị giới hạn khi chúng ta đưa giới hạn xác suất về 0). Có rất nhiều cách khác nhau để bạn có thể phát triển trực giác tốt về nó mà tôi đã từng gặp trước đây. Bài đăng này là nỗ lực của tôi nhằm đối chiếu tất cả những trực giác này và cố gắng xác định những điểm tương đồng cơ bản giữa chúng. Tôi hy vọng rằng đối với tất cả những người đọc bài viết này, sẽ có ít nhất một bài viết mà bạn chưa từng gặp trước đây và điều đó giúp cải thiện hiểu biết tổng thể của bạn!
Một lưu ý khác - có một số điểm trùng lặp giữa mỗi bài viết này (một số bài trong số đó có thể được mô tả gần như chỉ là cách diễn đạt lại của những bài khác), vì vậy bạn có thể chỉ muốn duyệt qua những bài mà bạn thấy thú vị. Ngoài ra, tôi mong đợi một phần lớn giá trị của bài đăng này (có thể >50%) đến từ phần tóm tắt, vì vậy bạn có thể chỉ muốn đọc phần đó và bỏ qua phần còn lại!
Tóm tắt
1. Dự kiến sẽ có bất ngờ
bạn mong đợi sẽ ngạc nhiên hơn bao nhiêu khi quan sát dữ liệu có phân phối , nếu bạn lầm tưởng rằng phân phối là so với nếu bạn biết sự thật phân phối
2. Kiểm tra giả thuyết
lượng bằng chứng chúng tôi mong đợi nhận được cho trên trong kiểm tra giả thuyết, nếu là đúng.
3. MLE
Nếu là phân phối dữ liệu theo kinh nghiệm, được thu nhỏ (trên ) khi là công cụ ước tính khả năng xảy ra tối đa cho .
4. Mã hóa dưới mức tối ưu
số bit chúng ta đang lãng phí nếu chúng ta cố gắng nén nguồn dữ liệu có phân phối sử dụng mã thực sự được tối ưu hóa cho (tức là mã có độ dài tin nhắn dự kiến tối thiểu nếu là nguồn dữ liệu thực sự phân phối).
5A. Trò chơi cờ bạc - đánh nhà cái
số tiền (trong không gian đăng nhập) chúng ta có thể thắng từ một trò chơi sòng bạc, nếu chúng tôi biết cách phân phối trò chơi thực sự là nhưng ngôi nhà tin nhầm rằng đó là .
5B. Trò chơi cờ bạc - chơi xổ số
số tiền (trong không gian nhật ký) chúng ta có thể thắng xổ số nếu chúng ta biết xác suất giành được vé trúng thưởng và phân phối lượt mua vé .
6. Phân kỳ Bregman
theo một nghĩa nào đó là một cách tự nhiên để đo khoảng cách đến từ nếu chúng tôi đang sử dụng entropy của phân phối để nắm bắt khoảng cách từ 0 đến bao nhiêu (tương tự như cách là thước đo tự nhiên về khoảng cách giữa các vectơ và , nếu chúng tôi đang sử dụng để nắm bắt khoảng cách của vectơ đến từ không).
Chủ đề chung cho hầu hết trong số này:
thước đo mô hình của chúng tôi khác với phân bố thực sự . Nói cách khác, chúng tôi quan tâm đến mức độ và khác nhau trong thế giới nơi P là đúng, điều này giải thích tại sao KL-div không đối xứng.
1. Bất ngờ được mong đợi
Đối với biến ngẫu nhiên với phân bổ xác suất , bất ngờ (hoặc ngạc nhiên ) được định nghĩa là . Điều này được thúc đẩy bởi một số ràng buộc trực quan đơn giản mà chúng tôi muốn có đối với bất kỳ khái niệm "bất ngờ" nào:
- Một sự kiện có xác suất không có gì bất ngờ
- Các sự kiện có xác suất thấp hơn thực sự đáng ngạc nhiên hơn
- Hai sự kiện độc lập cũng đáng ngạc nhiên như tổng mức độ bất ngờ của các sự kiện đó khi được đo độc lập
Trên thực tế, có thể chứng minh rằng ba yếu tố cân nhắc này đưa định nghĩa về mức độ bất ngờ lên đến bội số không đổi.
Từ điều này, chúng ta có một cách khác để xác định entropy - là điều bất ngờ được mong đợi về một sự kiện:
Bây giờ, giả sử chúng ta (nhầm) tin vào sự thật phân phối của là , thay vì . Sau đó, điều bất ngờ dự kiến về mô hình của chúng tôi (có tính đến phân phối thực sự là ) là:
và giờ đây chúng tôi tìm thấy rằng:
Nói cách khác, độ phân kỳ KL là sự khác biệt giữa mức độ bất ngờ dự kiến của mô hình của bạn và mức độ bất ngờ dự kiến của mô hình chính xác (tức là mô hình mà bạn biết phân bố thực sự ). Khoảng cách xa hơn là từ , mô hình càng tệ dành cho , tức là. thực tế thì càng ngạc nhiên hơn.
Hơn nữa, điều này giải thích tại sao không đối xứng, ví dụ: tại sao nó nổ khi nhưng không nổ khi . Trong trường hợp trước, mô hình của bạn đang gán xác suất rất thấp cho một sự kiện có thể xảy ra khá thường xuyên, do đó mô hình của bạn rất ngạc nhiên về điều này. Trường hợp thứ hai không có đặc tính này và không có câu chuyện tương đương nào bạn có thể kể về việc mô hình của bạn thường xuyên rất ngạc nhiên như thế nào. [1]
2. Kiểm tra giả thuyết
Giả sử bạn có hai giả thuyết: một giả thuyết không cho biết rằng và một giả thuyết thay thế cho biết rằng . Giả sử null thực sự đúng. Kiểm tra giả thuyết tự nhiên là kiểm tra tỷ lệ khả năng xảy ra, tức là. bạn từ chối nếu quan sát nằm trong vùng tới hạn:
đối với một số hằng số xác định quy mô của bài kiểm tra. Một cách viết khác là:
Chúng ta có thể hiểu giá trị là (bội số vô hướng của [2] ) bit bằng chứng chúng tôi thu thập được cho kết thúc . Nói cách khác, nếu xảy ra thường xuyên gấp đôi khi được phân phối so với phân phối , thì quan sát là một chút bằng chứng cho qua .
là (bội số vô hướng của) các bằng chứng dự kiến mà chúng tôi thu được cho over , trong đó kỳ vọng vượt quá giả thuyết không . Càng gần và càng gần là vậy, chúng ta càng cho rằng sẽ khó phân biệt được giữa chúng - tức là. khi là đúng thì chúng ta không nên kỳ vọng thực tế sẽ cung cấp nhiều bằng chứng cho thay vì đang đúng.
3. MLE
Cái này hơi nặng về toán hơn những cái khác, vậy nên ymmv cho biết nó thú vị như thế nào!
Giả sử là phân bố theo kinh nghiệm của dữ liệu , mỗi iid có phân phối và là mô hình thống kê được tham số hóa bởi . Hàm khả năng của chúng tôi là:
Theo luật số lớn, gần như chắc chắn. Đây là entropy chéo của và . Cũng lưu ý rằng nếu chúng ta trừ đi giá trị này khỏi entropy của thì chúng ta sẽ nhận được . Vì vậy, việc giảm thiểu entropy chéo trên tương đương với việc tối đa hóa .
Công cụ ước tính khả năng tối đa của chúng tôi là tham số tối đa hóa và chúng ta có thể sử dụng một số lý thuyết học thống kê cộng với rất nhiều cách vẫy tay để lập luận rằng (tức là chúng tôi đã hoán đổi xung quanh các toán tử giới hạn và argmin). Nói cách khác, ước tính khả năng tối đa tương đương với việc giảm thiểu phân kỳ KL. Nếu lớn thì điều này cho thấy rằng sẽ không phải là mô hình tốt cho dữ liệu được tạo từ phân phối [[TAG_892]%.
4. Mã hóa dưới mức tối ưu
Mã hóa nguồn là một nhánh lớn của lý thuyết thông tin và tôi sẽ không đề cập đến tất cả những điều đó trong bài đăng này. Có một số tài nguyên trực tuyến có thể giải thích tốt điều đó. Để tóm tắt lại ý tưởng quan trọng sẽ quan trọng ở đây:
Nếu bạn đang cố gắng truyền dữ liệu từ một số phân phối qua kênh nhị phân, bạn có thể chỉ định kết quả cụ thể cho chuỗi chữ số nhị phân theo cách giảm thiểu số chữ số dự kiến mà bạn phải gửi. Ví dụ: nếu bạn có ba sự kiện có thể xảy ra với xác suất (0,8, 0,1, 0,1) thì bạn nên sử dụng mã như (0, 10, 11) cho chuỗi này vì bạn sẽ thấy mình gửi các mã ngắn hơn với xác suất cao hơn.
Trong giới hạn cho số lượng lớn các giá trị có thể có cho (với điều kiện là một số thuộc tính khác được giữ nguyên), mã tối ưu [3] sẽ đại diện cho kết quả với chuỗi nhị phân có độ dài .
Từ điều này, trực giác về sự phân kỳ của KL hiện rõ ràng. Giả sử bạn đã nhầm tưởng rằng và bạn đã thiết kế một mã hóa tối ưu trong trường hợp này. Số bit dự kiến bạn sẽ phải gửi cho mỗi tin nhắn là:
và chúng ta có thể thấy ngay rằng phân kỳ KL là (theo hệ số tỷ lệ) sự khác biệt về số bit dự kiến cho mỗi sự kiện mà bạn sẽ phải gửi với mã dưới mức tối ưu này so với số lượng bạn muốn gửi nếu bạn biết phân bố thực sự và có thể xây dựng mã tối ưu. Càng xa nhau và nghĩa là, trung bình bạn càng lãng phí nhiều bit hơn do không gửi mã tối ưu. Đặc biệt, nếu chúng tôi gặp trường hợp như thì điều này có nghĩa là mã của chúng tôi (được tối ưu hóa cho ) sẽ gán một từ mã rất dài cho kết quả vì chúng tôi không mong đợi điều đó sẽ xảy ra thường xuyên và vì vậy chúng ta sẽ lãng phí rất nhiều dung lượng tin nhắn khi thường xuyên phải sử dụng từ mã này.
5A. Trò chơi cờ bạc - Đập nhà cái
Giả sử bạn có thể đặt cược vào kết quả của một số trò chơi sòng bạc, ví dụ: một phiên bản của bánh xe roulette với xác suất không đều. Trước tiên, hãy tưởng tượng nhà cái công bằng và trả cho bạn lần số tiền đặt cược ban đầu của bạn nếu bạn đặt cược vào kết quả (theo cách này, mọi đặt cược đều có giá trị mong đợi bằng 0: vì đặt cược bật kết quả nghĩa là bạn mong đợi nhận được đã trả lại cho bạn). Vì nhà cái biết chính xác tất cả các xác suất nên không có cách nào để bạn thắng tiền trong kỳ vọng.
Bây giờ hãy tưởng tượng nhà cái thực sự không biết xác suất thực sự , nhưng bạn thì có. Niềm tin sai lầm của nhà cái là nên họ trả tiền cho mọi người cho sự kiện mặc dù điều này thực sự có xác suất xảy ra . Vì bạn biết nhiều hơn họ nên bạn sẽ có thể thu được lợi ích từ tình trạng này. Nhưng bạn có thể kiếm được bao nhiêu?
Giả sử bạn có $1 để đặt cược. Bạn đặt cược vào kết quả , vậy . Hãy để là số tiền thắng dự kiến của bạn. Sẽ tự nhiên hơn khi nói về tiền thắng log, bởi vì điều này mô tả mức độ giàu có của bạn tăng lên theo thời gian. Số tiền thắng nhật ký dự kiến của bạn là:
Hóa ra là khi bạn thực hiện một chút tối ưu hóa đơn giản bằng cách sử dụng Lagrangian:
thì bạn sẽ thấy chiến lược đặt cược tối ưu là (đây là bài tập dành cho người đọc!). Số tiền thắng dự kiến tương ứng của bạn là:
nói cách khác, phân kỳ KL thể hiện số tiền bạn có thể giành được từ sòng bạc bằng cách khai thác sự khác biệt giữa các xác suất thực và những niềm tin sai lầm của ngôi nhà . Càng gần và càng khó kiếm lợi từ kiến thức bổ sung của bạn.
Một lần nữa, cách sắp xếp này minh họa sự thiếu đối xứng trong phân kỳ KL. Nếu , điều này có nghĩa là nhà cái sẽ trả quá nhiều tiền cho bạn khi sự kiện xảy ra, vì vậy chiến lược rõ ràng để khai thác điều này là đặt cược nhiều tiền vào (và tương ứng sẽ rất lớn). Nếu thì không có cách tương ứng nào để khai thác điều này (ngoại trừ trong phạm vi điều này cho thấy chúng tôi có thể có cho một số kết quả khác nhau ).
5B. Trò chơi cờ bạc - Chơi xổ số
Điều này về cơ bản giống với (5A), nhưng nó cung cấp một góc nhìn hơi khác. Giả sử tồn tại một cuộc xổ số mà mọi người có thể mua vé và tổng số tiền mọi người chi cho vé được chia đều cho những người đã mua vé có số trúng thưởng (thực tế, ban tổ chức xổ số sẽ chênh lệch một chút, nhưng chúng tôi cho rằng số tiền này rất nhỏ). Nếu mỗi vé được mua số lần như nhau thì không có cách nào kiếm được tiền như mong đợi. Nhưng giả sử mọi người có một thành kiến có thể đoán trước được (ví dụ: mua số tròn hoặc số có chữ số lặp lại) - khi đó bạn có thể kiếm tiền bằng cách mua những vé được mua ít thường xuyên hơn, vì khi giành chiến thắng, bạn thường sẽ không có nhiều người như vậy nên bạn sẽ phải chia tiền thưởng với.
Nếu bạn diễn giải là sự phân bổ số người mua mỗi vé (tức là bạn đã biết) và là phân phối cơ bản thực sự của vé nào được thanh toán (cũng đã biết), sau đó ví dụ này sẽ rút gọn về ví dụ trước - bạn có thể sử dụng tính năng tối ưu hóa để tìm ra cách tốt nhất để mua vé tỷ lệ với và phân kỳ KL bằng với số tiền thắng trong nhật ký dự kiến của bạn.
Để hiểu sâu hơn về cách sắp xếp này, hãy xem xét các tình huống trong đó Bạn không biết trên cơ sở mỗi số nhưng bạn biết phân bổ tổng thể về quy mô nhóm cho mỗi số vé. Ví dụ: trong giới hạn số lượng người chơi và số lượng lớn, bạn có thể ước tính quy mô nhóm dưới dạng phân phối Poisson. Nếu mỗi vé có xác suất thanh toán như nhau thì bạn có thể kiếm được lợi nhuận kỳ vọng bằng cách mua một trong mỗi vé (trong đó là phân phối đồng đều và là phân phối Poisson). Điều thú vị là, về mặt lý thuyết, chiến lược "mua pot" này có thể thực hiện được đối với một số loại xổ số nhất định, chẳng hạn như trong xổ số 6/49 của Canada (xem bài viết phân tích lỗ hổng này tại đây ). Tuy nhiên, có một số lý do khiến điều này có xu hướng không hiệu quả trong đời thực, chẳng hạn như:
- Xổ số thường có tỷ lệ cắt giảm đáng kể
- Có các hạn chế về xổ số (ví dụ: giới hạn vé)
- Mua hồ bơi cực kỳ tốn kém (rất khó để tổ chức và tài trợ cho một tập đoàn để khai thác hiệu ứng này!)
6. Phân kỳ Bregman
Bản thân sự phân kỳ Bregman khá phức tạp và tôi không hy vọng phần này sẽ làm sáng tỏ cho nhiều người (nó vẫn chưa làm sáng tỏ hoàn toàn đối với tôi!). Tuy nhiên, tôi nghĩ tôi vẫn nên để nó lại vì nó mang lại một góc nhìn thú vị.
Nếu bạn muốn định lượng mức độ phân kỳ của hai phân bố xác suất, điều đầu tiên bạn có thể nghĩ đến là sử dụng một chuẩn mực (ví dụ: ) về sự khác biệt giữa chúng. Điều này có một số đặc tính tốt, nhưng nó cũng không đạt yêu cầu vì nhiều lý do. Ví dụ: về mặt trực quan, nó có vẻ giống như khoảng cách giữa các phân bố Bernoulli với và phải lớn hơn giá trị đó trong khoảng và . [4]
Hóa ra là có một cách tự nhiên để liên kết bất kỳ hàm lồi nào với mức độ phân kỳ. Vì các tiếp tuyến của hàm lồi luôn nằm bên dưới chúng nên chúng ta có thể định nghĩa Phân kỳ Bregman là số tiền mà lớn hơn ước tính mà bạn sẽ nhận được bằng cách khớp một tiếp tuyến dòng tới at và sử dụng nó để ngoại suy tuyến tính thành .
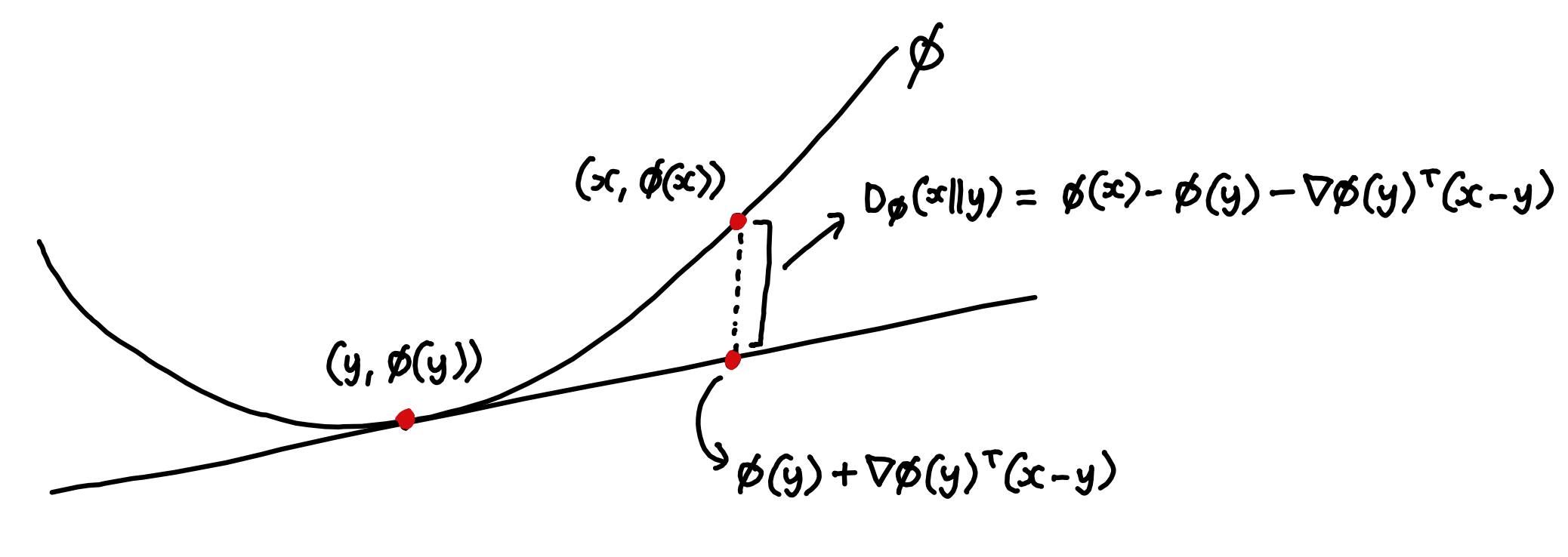
Để thực hiện một số kiểm tra nhanh chóng về sự phân kỳ Bregman - nếu hàm lồi của bạn là bình phương định mức, thì thước đo phân kỳ mà bạn nhận được chỉ là bình phương chuẩn của vectơ giữa điểm:
Về cơ bản đây là những gì bạn mong đợi - nó cho bạn thấy rằng khi quy chuẩn là điều đương nhiên cách để đo khoảng cách của một vật nào đó so với số 0 (tức là nó lớn bao nhiêu), thì định mức của vectơ giữa hai điểm là cách tự nhiên để đo khoảng cách từ một điểm đến khác.
Bây giờ, hãy quay lại trường hợp phân bố xác suất. Có hàm lồi nào đo lường, theo một nghĩa nào đó, cách phân bố xác suất cách 0 bao xa không? Chà, một điều có vẻ tự nhiên là nói rằng "số 0" là bất kỳ phân bố xác suất nào trong đó kết quả là chắc chắn - nói cách khác là entropy bằng 0. Và hóa ra entropy là lõm, nên nếu chúng ta chỉ lấy giá trị âm của entropy thì chúng ta sẽ có một hàm lồi. Đưa nó vào công thức phân kỳ Bregman và chúng ta nhận được:
Không có khoảnh khắc chiếu sáng tia chớp nào từ khung hình này. Nhưng nó vẫn thú vị, vì nó cho thấy những cách khác nhau để đo sự khác biệt giữa hai điểm có thể tự nhiên hơn những cách khác, tùy thuộc vào không gian mà chúng ta đang làm việc và nó thể hiện điều gì. Khoảng cách Euclide giữa hai điểm là tự nhiên trong không gian xác suất, khi số 0 chỉ là một điểm khác trong không gian đó. Nhưng khi làm việc trên xác suất đơn giản, với entropy là cách chúng tôi chọn để đo "sự khác biệt so với 0" của phân bố xác suất, chúng tôi nhận thấy rằng theo một nghĩa nào đó là điều tự nhiên nhất lựa chọn.
suy nghĩ cuối cùng
Tóm tắt lại những điều này, chúng tôi thấy rằng có kích thước lớn cho biết:
- Mô hình của bạn sẽ rất ngạc nhiên trước thực tế
- Bạn mong đợi nhận được nhiều bằng chứng ủng hộ giả thuyết trên , nếu is true
- is a poor model for observed data
- Bạn sẽ lãng phí rất nhiều nội dung thư nếu cố mã hóa một cách tối ưu trong khi nhầm tưởng rằng phân phối là
- Bạn có thể kiếm nhiều tiền trong các trò chơi cá cược mà người khác có niềm tin sai lầm , nhưng bạn biết xác suất thực sự
- (cái này không có một câu đơn giản như vậy tóm tắt!)
Mặc dù (4) có thể là cách tao nhã nhất về mặt toán học, nhưng tôi nghĩ (1) gần giống nhất với trực giác thực sự cho .
Để tóm tắt điểm chung của tất cả các khung này:
thước đo mức độ mô hình của chúng tôi khác với phân bố thực sự . Nói cách khác, chúng tôi quan tâm đến mức độ và khác nhau trong thế giới nơi P là đúng, điều này giải thích tại sao KL-div lại không đối xứng.
Nói cách khác, "không quan tâm" khi (giả sử cả hai xác suất đều nhỏ), bởi vì mặc dù mô hình của chúng tôi sai nhưng thực tế không thường xuyên cho chúng tôi thấy các tình huống trong đó mô hình của chúng tôi không phù hợp với thực tế. Nhưng nếu thì kết quả sẽ xảy ra thường xuyên hơn chúng tôi mong đợi, liên tục gây ngạc nhiên cho mô hình của chúng tôi và từ đó chứng tỏ tính không thỏa đáng của mô hình.
- ^ Lưu ý rằng trường hợp sau có thể ám chỉ trường hợp trước, ví dụ: nếu thì thực ra chúng ta cũng ở trong trường hợp trước, vì . Nhưng điều này không phải lúc nào cũng xảy ra; có thể có sự bất đối xứng ở đây. Ví dụ: nếu P = (0,1, 0,9) và Q = (0,01, 0,99), thì chúng ta đang ở trong trường hợp trước chứ không phải trường hợp sau. Nếu là đúng thì 10% mô hình thời gian vô cùng ngạc nhiên vì một sự kiện xảy ra có xác suất là 1% - đó là lý do tại sao rất lớn. Nhưng nếu là đúng thì thực tế sẽ đưa ra mô hình không có bất ngờ nào lớn như thế này - do đó không lớn bằng.
- ^ Phần bội số vô hướng là do chúng tôi đang làm việc với log tự nhiên chứ không phải cơ sở 2.
- ^ Cụ thể, mã có thể giải mã tối ưu - nói cách khác, bộ từ mã của bạn cần phải có đặc tính mà bạn có thể xâu chuỗi bất kỳ sự kết hợp nào của chúng lại với nhau và có thể giải mã những từ mã nào bạn đã sử dụng. Ví dụ:
(0, 10, 11)có thuộc tính này, nhưng(0, 10, 01)thì không, vì chuỗi010có thể được tạo từ0 + 10hoặc01 + 0. - ^ Một cách bạn có thể lập luận rằng thước đo khoảng cách nên có đặc tính này là quan sát thấy rằng hai phân bố trước có phương sai thấp hơn nhiều so với phân bố hai cái sau. Vì vậy, nếu bạn quan sát thấy mức phân phối là hoặc , bạn sẽ mất ít thời gian hơn nhiều để biết mình đang xem xét bản phân phối nào so với khi bạn đang cố gắng phân biệt giữa và [[TAG_1814]%.
Tác giả: jxmorris12