Chạy Gemma 4 cục bộ với CLI không đầu và Claude Code mới của LM Studio
Running Gemma 4 locally with LM Studio's new headless CLI and Claude Code
LM Studio vừa ra mắt CLI (Command Line Interface) dạng headless, cho phép các bạn chạy Google Gemma 4 models ngay trên máy tính cá nhân. Đây là một lựa chọn "miễn phí" và "bảo mật" thay thế cho các API trên cloud, cực kỳ hữu ích cho các tác vụ như code review hay test prompt. Kiến trúc Mixture-of-Experts (MoE) của Gemma 4, đặc biệt là bản 26B, giúp nó hoạt động hiệu quả ngay cả trên phần cứng thông thường. Lý do là bởi mỗi token chỉ kích hoạt một phần nhỏ các tham số của mô hình. Điều này cho phép developer tích hợp LLM vào quy trình làm việc của mình mà không tốn chi phí API hay lo lắng về vấn đề riêng tư dữ liệu. Tuy nhiên, hiệu năng có thể thay đổi khi tích hợp với các công cụ khác như Claude Code.
API AI đám mây rất tuyệt vời cho đến khi chúng không tuyệt vời. Giới hạn mức giá, chi phí sử dụng, mối lo ngại về quyền riêng tư và độ trễ của mạng đều tăng lên. Để thực hiện các tác vụ nhanh như xem lại mã, soạn thảo hoặc nhắc nhở thử nghiệm, một mô hình cục bộ chạy...
Các API Cloud AI rất tuyệt vời cho đến khi chúng không còn hữu ích nữa. Giới hạn tốc độ, chi phí sử dụng, lo ngại về quyền riêng tư và độ trễ mạng cộng lại đều có tác động. Đối với các tác vụ nhanh như đánh giá mã, soạn thảo hoặc kiểm thử prompt, một mô hình cục bộ chạy hoàn toàn trên phần cứng của bạn có những ưu điểm thực sự: không tốn chi phí API, không có dữ liệu rời khỏi máy của bạn và tính khả dụng nhất quán.
Google Gemma 4 rất thú vị để sử dụng cục bộ vì kiến trúc mixture-of-experts của nó. Mô hình 26B tham số chỉ kích hoạt 4B tham số cho mỗi forward pass, có nghĩa là nó hoạt động tốt trên phần cứng không thể xử lý được mô hình 26B dày đặc. Trên MacBook Pro M4 Pro 14 inch của tôi với 48 GB bộ nhớ hợp nhất, nó hoạt động thoải mái và tạo ra 51 token mỗi giây. Tuy nhiên, theo kinh nghiệm của tôi, nó có hiện tượng chậm đáng kể khi sử dụng trong Claude Code.

Google đã phát hành Gemma 4 dưới dạng một họ gồm bốn mô hình, không chỉ một. Dòng sản phẩm này bao gồm nhiều mục tiêu phần cứng khác nhau:

Các mô hình “E” (E2B, E4B) sử dụng Per-Layer Embeddings để tối ưu hóa việc triển khai trên thiết bị và là các biến thể duy nhất hỗ trợ đầu vào âm thanh (nhận dạng giọng nói và dịch thuật). Mô hình dày đặc 31B là mạnh mẽ nhất, đạt điểm 85,2% trên MMLU Pro và 89,2% trên AIME 2026.
Tại sao tôi chọn 26B-A4B. Kiến trúc mixture-of-experts là yếu tố then chốt. Nó có 128 chuyên gia cộng với 1 chuyên gia chia sẻ, nhưng chỉ kích hoạt 8 chuyên gia (3,8B tham số) cho mỗi token. Một quy tắc kinh nghiệm phổ biến ước tính chất lượng tương đương với mô hình dày đặc MoE bằng khoảng căn bậc hai của (tổng x tham số kích hoạt), đưa mô hình này vào khoảng 10B hiệu quả. Trên thực tế, nó mang lại chi phí suy luận tương đương với mô hình dày đặc 4B với chất lượng vượt trội so với hạng cân của nó. Trên các benchmark, nó đạt điểm 82,6% trên MMLU Pro và 88,3% trên AIME 2026, gần với mô hình dày đặc 31B (85,2% và 89,2%) trong khi chạy nhanh hơn đáng kể.
Biểu đồ dưới đây cho thấy điều đó. Nó vẽ điểm Elo so với kích thước mô hình tổng thể trên thang đo log cho các mô hình open-weight gần đây có kích hoạt tư duy. Vùng được làm nổi bật màu xanh lam ở trên cùng bên trái là nơi bạn muốn đạt được: hiệu suất cao, dấu chân nhỏ.
Gemma 4 26B-A4B (Elo ~1441) nằm chắc chắn trong vùng đó, vượt xa trọng lượng 25,2B tham số của nó. Biến thể dày đặc 31B đạt điểm cao hơn một chút (~1451) nhưng vẫn rất nhỏ gọn. Để tham khảo, các mô hình như Qwen 3.5 397B-A17B (~1450 Elo) và GLM-5 (~1457 Elo) cần 100-600B tham số tổng để đạt được điểm số tương tự. Kimi-K2.5 (~1457 Elo) yêu cầu hơn 1.000B. Mô hình 26B-A4B đạt Elo cạnh tranh với một phần nhỏ các tham số, điều này trực tiếp chuyển thành yêu cầu bộ nhớ thấp hơn và suy luận cục bộ nhanh hơn.
Đây là những gì làm cho các mô hình MoE trở nên mang tính cách mạng cho việc sử dụng cục bộ. Bạn không cần một cụm máy tính hoặc dàn GPU cao cấp để chạy một mô hình cạnh tranh với các "gã khổng lồ" có hơn 400B tham số. Một chiếc máy tính xách tay với 48 GB bộ nhớ hợp nhất là đủ.
Đối với suy luận cục bộ trên Mac có 48 GB, đây là điểm ngọt. Mô hình dày đặc 31B sẽ tiêu tốn nhiều bộ nhớ hơn và tạo token chậm hơn vì mọi tham số đều tham gia vào mọi forward pass. Mô hình E4B nhẹ hơn nhưng rõ ràng là kém mạnh mẽ hơn. Mô hình 26B-A4B cung cấp cho bạn tối đa 256K ngữ cảnh, hỗ trợ thị giác (hữu ích để phân tích ảnh chụp màn hình và sơ đồ), gọi hàm/công cụ gốc và lý luận với các chế độ suy nghĩ có thể cấu hình, tất cả đều với tốc độ 51 token/giây trên phần cứng của tôi.

LM Studio đã là một ứng dụng máy tính phổ biến để chạy các mô hình cục bộ trong một thời gian. Phiên bản 0.4.0 đã thay đổi kiến trúc một cách cơ bản bằng cách giới thiệu llmster, công cụ suy luận cốt lõi được trích xuất từ ứng dụng máy tính và đóng gói dưới dạng một máy chủ độc lập.
Kết quả thực tế: bạn giờ đây có thể chạy LM Studio hoàn toàn từ dòng lệnh bằng cách sử dụng tiện ích lms CLI. Không cần GUI. Điều này làm cho nó có thể sử dụng trên các máy chủ không có màn hình, trong các quy trình CI/CD, các phiên SSH, hoặc chỉ đơn giản là cho các nhà phát triển ưa thích làm việc trong terminal.
Các bổ sung chính trong phiên bản 0.4.0:
Dịch vụ nền llmster: một dịch vụ chạy ngầm quản lý việc tải và suy luận mô hình mà không cần ứng dụng máy tính
CLI
lms: giao diện dòng lệnh đầy đủ để tải xuống, tải, trò chuyện và phục vụ các mô hìnhXử lý yêu cầu song song: batching liên tục thay vì xếp hàng tuần tự, vì vậy nhiều yêu cầu đến cùng một mô hình chạy đồng thời
API REST có trạng thái: một điểm cuối
/v1/chatmới duy trì lịch sử hội thoại qua các yêu cầuTích hợp MCP: hỗ trợ giao thức Ngữ cảnh Mô hình cục bộ với cơ chế cấp quyền bằng khóa
Cài đặt lms CLI bằng một lệnh duy nhất:
# Linux/Mac
curl -fsSL https://lmstudio.ai/install.sh | bash
# Windows
irm https://lmstudio.ai/install.ps1 | iexSau đó khởi động dịch vụ nền không cần màn hình:
lms daemon upTrên macOS, cập nhật cả hai trình chạy suy luận:
lms runtime update llama.cpp
lms runtime update mlxVới dịch vụ nền đang chạy, tải xuống mô hình Gemma 4 26B của Google:
lms get google/gemma-4-26b-a4bCLI sẽ hiển thị biến thể mà nó sẽ tải xuống (lượng tử hóa Q4_K_M theo mặc định, 17.99 GB) và yêu cầu xác nhận:
↓ To download: model google/gemma-4-26b-a4b - 64.75 KB
└─ ↓ To download: Gemma 4 26B A4B Instruct Q4_K_M [GGUF] - 17.99 GB
About to download 17.99 GB.
? Start download?
❯ Yes
No
Change variant selectionNếu bạn đã có mô hình, CLI sẽ thông báo và hiển thị lệnh tải:
✔ Start download? yes
Model already downloaded. To use, run: lms load google/gemma-4-26b-a4bLiệt kê tất cả các mô hình đã tải xuống:
lms lsYou have 10 models, taking up 118.17 GB of disk space.
LLM PARAMS ARCH SIZE DEVICE
gemma-3-270m-it-mlx 270m gemma3_text 497.80 MB Local
google/gemma-4-26b-a4b (1 variant) 26B-A4B gemma4 17.99 GB Local
gpt-oss-20b-mlx 20B gpt_oss 22.26 GB Local
llama-3.2-1b-instruct 1B Llama 712.58 MB Local
nvidia/nemotron-3-nano (1 variant) 30B nemotron_h 17.79 GB Local
openai/gpt-oss-20b (1 variant) 20B gpt-oss 12.11 GB Local
qwen/qwen3.5-35b-a3b (1 variant) 35B-A3B qwen35moe 22.07 GB Local
qwen2.5-0.5b-instruct-mlx 0.5B Qwen2 293.99 MB Local
zai-org/glm-4.7-flash (1 variant) 30B glm4_moe_lite 24.36 GB Local
EMBEDDING PARAMS ARCH SIZE DEVICE
text-embedding-nomic-embed-text-v1.5 Nomic BERT 84.11 MB LocalĐáng chú ý: nhiều mô hình trong số này sử dụng kiến trúc hỗn hợp các chuyên gia (Gemma 4, Qwen 3.5, GLM 4.7 Flash). Các mô hình MoE vượt trội hơn về hiệu suất suy luận cục bộ vì chỉ một phần nhỏ tham số được kích hoạt trên mỗi token.
Bắt đầu một phiên trò chuyện với tùy chọn hiển thị thống kê để xem các số liệu hiệu suất:
lms chat google/gemma-4-26b-a4b --stats ╭─────────────────────────────────────────────────╮
│ 👾 lms chat │
│ Type exit or Ctrl+C to quit │
│ │
│ Chatting with google/gemma-4-26b-a4b │
│ │
│ Try one of the following commands: │
│ /model - Load a model (type /model to see list) │
│ /download - Download a model │
│ /clear - Clear the chat history │
│ /help - Show help information │
╰─────────────────────────────────────────────────╯Với tùy chọn --stats, bạn sẽ nhận được các chỉ số dự đoán sau mỗi phản hồi:
Prediction Stats:
Stop Reason: eosFound
Tokens/Second: 51.35
Time to First Token: 1.551s
Prompt Tokens: 39
Predicted Tokens: 176
Total Tokens: 21551 token/giây trên MacBook Pro M4 Pro (48 GB) màn hình 14 inch với mô hình 26B là khá tốt. Thời gian đến token đầu tiên là 1.5 giây đủ nhanh cho việc sử dụng tương tác.
Xem mô hình nào hiện đang được tải:
lms psIDENTIFIER MODEL STATUS SIZE CONTEXT PARALLEL DEVICE TTL
google/gemma-4-26b-a4b google/gemma-4-26b-a4b IDLE 17.99 GB 48000 2 Local 60m / 1hMô hình chiếm 17.99 GB bộ nhớ với cửa sổ ngữ cảnh 48K và hỗ trợ 2 yêu cầu song song. TTL (thời gian chờ) sẽ tự động dỡ tải mô hình sau 1 giờ không hoạt động, giải phóng bộ nhớ mà không cần can thiệp thủ công.
Để xem siêu dữ liệu chi tiết của mô hình, hãy chuyển hướng đầu ra sang jq:
lms ps --json | jqCác trường chính từ đầu ra JSON:
"architecture": "gemma4"với"quantization": {"name": "Q4_K_M", "bits": 4}"vision": truevà"trainedForToolUse": true- Gemma 4 hỗ trợ cả đầu vào hình ảnh và gọi công cụ"maxContextLength": 262144- mô hình hỗ trợ ngữ cảnh lên tới 256K, mặc dù tải mặc định là 48K-
"parallel": 2- hai yêu cầu suy luận đồng thời thông qua batching liên tục
Trước khi tải mô hình, bạn có thể ước tính yêu cầu bộ nhớ ở các độ dài ngữ cảnh khác nhau bằng --estimate-only. Tôi đã viết một đoạn script nhỏ để kiểm tra trên toàn bộ phạm vi:
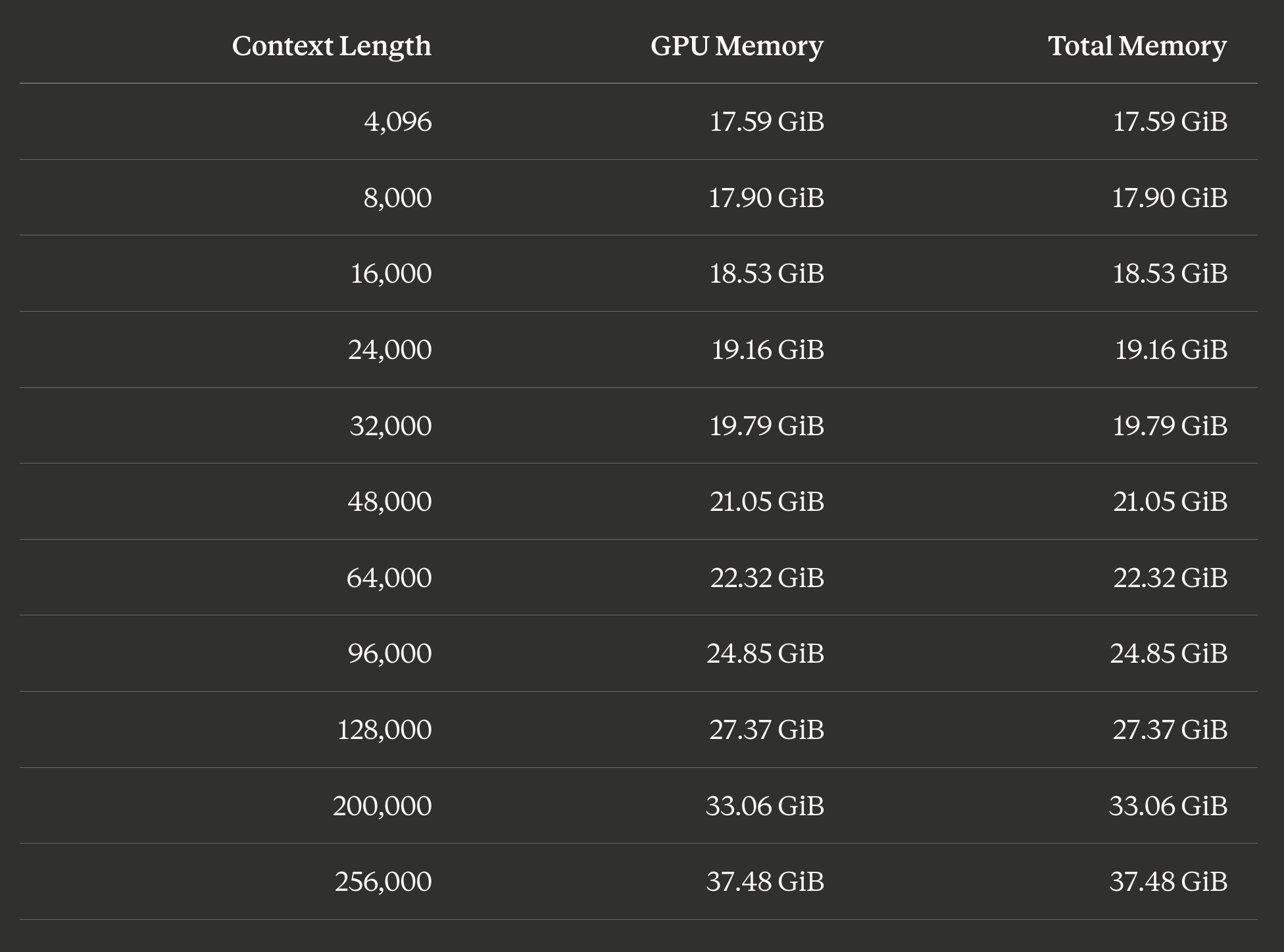
Mô hình cơ sở tốn khoảng 17.6 GiB bất kể ngữ cảnh. Mỗi lần tăng gấp đôi độ dài ngữ cảnh sẽ thêm khoảng 3-4 GiB. Ở ngữ cảnh mặc định 48K, bạn cần khoảng 21 GiB. Trên MacBook Pro 48 GB của tôi, tôi có thể đẩy lên tối đa 256K ngữ cảnh với 37.48 GiB và vẫn còn khoảng 10 GB trống cho hệ điều hành và các ứng dụng khác. Một máy Mac 36 GB có thể chạy thoải mái 200K ngữ cảnh với khoảng trống.
Lệnh ước tính rất đơn giản:
lms load google/gemma-4-26b-a4b --estimate-only --context-length 48000
Model: google/gemma-4-26b-a4b
Context Length: 48,000
Estimated GPU Memory: 21.05 GiB
Estimated Total Memory: 21.05 GiB
Estimate: This model may be loaded based on your resource guardrails settings.
Điều này hữu ích cho việc lập kế hoạch năng lực. Nếu bạn muốn chạy Gemma 4 cùng với các ứng dụng khác, hãy kiểm tra ước tính ở độ dài ngữ cảnh mục tiêu của bạn trước.
Đây là toàn bộ script tôi đã sử dụng để tạo bảng trên. Bạn có thể thay thế bằng bất kỳ tên mô hình và danh sách độ dài ngữ cảnh nào để kiểm tra một mô hình khác:
#!/usr/bin/env bash
model="google/gemma-4-26b-a4b"
contexts=(4096 8000 16000 24000 32000 48000 64000 96000 128000 200000 256000)
table_contexts=()
table_gpu=()
table_total=()
for ctx in "${contexts[@]}"; do
output="$(lms load "$model" --estimate-only --context-length "$ctx" 2>&1)"
parsed_context="$(printf '%s\n' "$output" | awk -F': ' '/^Context Length:/ {print $2; exit}')"
parsed_gpu="$(printf '%s\n' "$output" | awk -F': +' '/^Estimated GPU Memory:/ {print $2; exit}')"
parsed_total="$(printf '%s\n' "$output" | awk -F': +' '/^Estimated Total Memory:/ {print $2; exit}')"
table_contexts+=("${parsed_context:-$ctx}")
table_gpu+=("${parsed_gpu:-N/A}")
table_total+=("${parsed_total:-N/A}")
done
printf '| Model | Context Length | GPU Memory | Total Memory |\n'
printf '|---|---:|---:|---:|\n'
for i in "${!table_contexts[@]}"; do
printf '| %s | %s | %s | %s |\n' \
"$model" "${table_contexts[$i]}" "${table_gpu[$i]}" "${table_total[$i]}"
done
Các lệnh lms load hoặc lms chat mặc định chọn các giá trị hợp lý, nhưng bạn có thể điều chỉnh nhiều tham số để phù hợp với phần cứng và trường hợp sử dụng cụ thể của mình. Dưới đây là một khuôn khổ quyết định thực tế.
Bảng bộ nhớ trên là điểm khởi đầu của bạn. Trừ đi chi phí hệ điều hành (macOS thường sử dụng 4-6 GB) khỏi tổng bộ nhớ của bạn, sau đó tìm độ dài ngữ cảnh lớn nhất phù hợp.
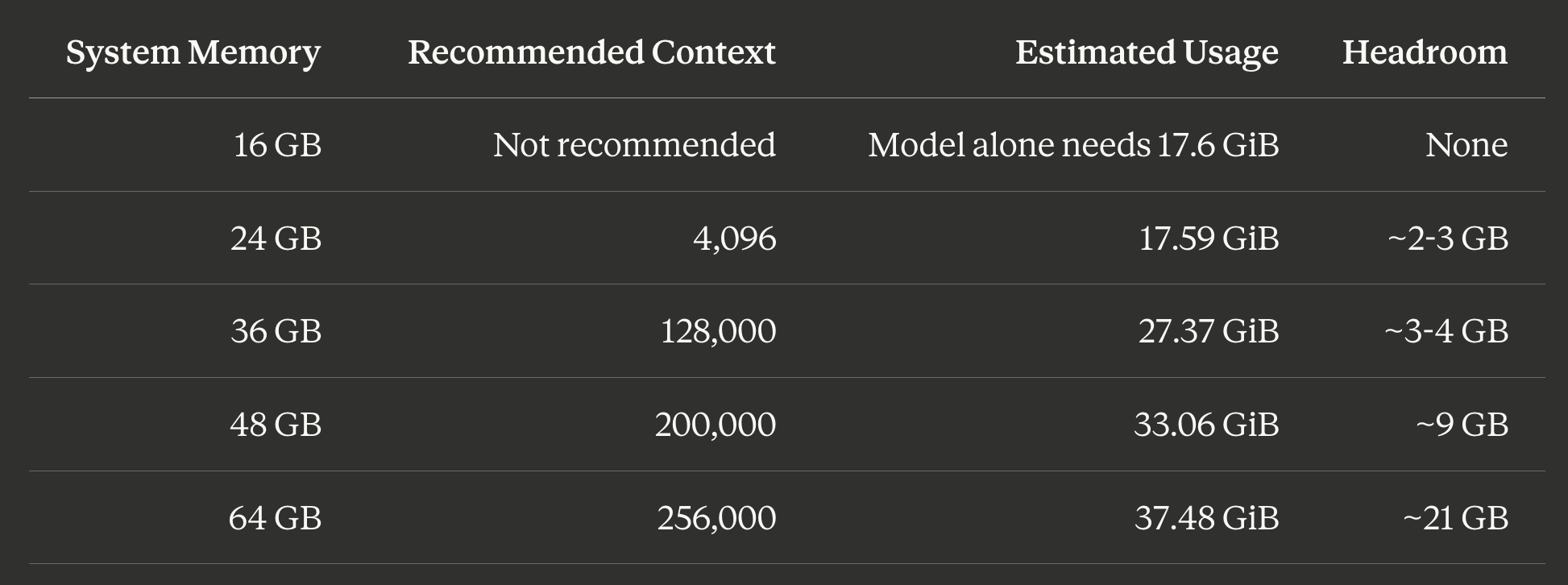
Tải với độ dài ngữ cảnh cụ thể:
lms load google/gemma-4-26b-a4b --context-length 128000Nếu bạn không chắc chắn, hãy luôn chạy --estimate-only trước. Nó tính đến sự vượt trội của flash attention và mô hình vision trong phép tính của nó.
Trên Apple Silicon, kiến trúc bộ nhớ hợp nhất có nghĩa là CPU và GPU chia sẻ cùng một nhóm bộ nhớ, vì vậy --gpu chủ yếu kiểm soát lượng tính toán chạy trên lõi GPU so với CPU. Cài đặt auto mặc định hoạt động tốt, nhưng bạn có thể buộc offload toàn bộ GPU:
lms load google/gemma-4-26b-a4b --gpu=1.0Sử dụng --gpu=max để offload mọi thứ có thể. Trên các hệ thống GPU rời (Linux/Windows với card NVIDIA), điều này trở nên quan trọng hơn vì VRAM GPU và RAM hệ thống là riêng biệt. Nếu mô hình của bạn không hoàn toàn vừa với VRAM, offload một phần (--gpu=0.5) sẽ chia các lớp giữa GPU và CPU, đánh đổi một phần tốc độ để có khả năng chạy các mô hình lớn hơn.
LM Studio hỗ trợ suy luận đồng thời thông qua batching liên tục, nơi nhiều yêu cầu được kết hợp động thành một lô tính toán duy nhất. Điều này hữu ích khi phục vụ mô hình cho nhiều máy khách hoặc chạy các lệnh gọi công cụ song song. Tính năng này yêu cầu runtime llama.cpp (v2.0.0+) và chưa có sẵn cho backend MLX.
Cấu hình nó thông qua GUI: mở trình tải mô hình, chuyển Manually choose model load parameters, chọn một mô hình, sau đó chuyển Show advanced settings để đặt Max Concurrent Predictions (mặc định là 4). Không có cờ dòng lệnh cho cài đặt này; nó được cấu hình thông qua ứng dụng desktop hoặc các mặc định cho từng mô hình.
Mỗi khe song song tiêu thụ thêm bộ nhớ tương ứng với độ dài ngữ cảnh, vì vậy trên các hệ thống bị hạn chế bộ nhớ, hãy giảm số lượng khe song song hoặc giảm độ dài ngữ cảnh để bù đắp. Với Gemma 4 trên 48 GB, 2 khe song song ở độ dài ngữ cảnh 48K là một sự cân bằng tốt.

Cài đặt thời gian tồn tại (time-to-live) tự động gỡ bỏ các mô hình sau một khoảng thời gian không hoạt động, giải phóng bộ nhớ:
lms load google/gemma-4-26b-a4b --ttl 1800Thao tác này đặt thời gian chờ không hoạt động là 30 phút (giá trị tính bằng giây). Mặc định là 3600 giây (1 giờ). Đối với các thiết lập máy chủ dùng chung nơi có thể cần nhiều mô hình, TTL ngắn hơn giúp luân chuyển giữa các mô hình mà không cần lệnh lms unload thủ công. Đặt TTL thành 0 hoặc -1 để tắt tự động gỡ bỏ.
Nếu bạn luôn tải Gemma 4 với cùng một cài đặt, hãy lưu chúng làm mặc định cho mỗi mô hình thông qua ứng dụng máy tính. Truy cập My Models, nhấp vào biểu tượng bánh răng bên cạnh mô hình và cấu hình các tùy chọn tải lên GPU, kích thước ngữ cảnh và cài đặt flash attention ưa thích của bạn. Các giá trị mặc định này áp dụng ở mọi nơi, bao gồm cả khi tải qua lms load từ CLI.
LM Studio hỗ trợ speculative decoding cho các mô hình dense, ghép nối mô hình chính của bạn với một mô hình "draft" nhỏ hơn để tăng tốc độ tạo sinh. Mô hình draft đề xuất các token nhanh chóng và mô hình chính xác nhận chúng theo lô, điều này nhanh hơn so với việc tạo từng token một cách độc lập.
Tuy nhiên, speculative decoding gặp vấn đề với các mô hình MoE như Gemma 4 26B-A4B. Trong quá trình xác minh, mô hình chính phải tải hợp của tất cả các chuyên gia được kích hoạt trên tất cả các token dự đoán. Do các token khác nhau được định tuyến đến các chuyên gia khác nhau, điều này làm tăng đáng kể việc sử dụng băng thông bộ nhớ và thậm chí có thể làm chậm mọi thứ. Các phép đo trên Mixtral cho thấy tăng tốc 39% trên code nhưng chậm 54% trên math với cùng một cài đặt, nghĩa là không có cấu hình duy nhất nào hoạt động đáng tin cậy. Đây là một lĩnh vực nghiên cứu đang hoạt động với các phương pháp như MoE-Spec (lập ngân sách chuyên gia) và SP-MoE (tiền tải chuyên gia) đang cố gắng giải quyết nó, và một số kiến trúc MoE mới hơn như thiết kế lai của Qwen 3.5 phù hợp hơn với các phương pháp dự đoán. Hiện tại, hãy bỏ qua speculative decoding với Gemma 4 26B-A4B và dựa vào suy luận MoE vốn đã nhanh của nó.
Flash attention là một tối ưu hóa giúp giảm việc sử dụng bộ nhớ cho KV cache trong quá trình suy luận, cho phép bạn chứa được các độ dài ngữ cảnh dài hơn trong cùng một bộ nhớ. Nó có sẵn cho từng mô hình trong cài đặt của LM Studio. Đối với Gemma 4 trên Apple Silicon, việc bật flash attention có thể giảm đáng kể việc sử dụng bộ nhớ ở các độ dài ngữ cảnh cao hơn. Cờ --estimate-only tính đến flash attention trong các phép tính của nó, vì vậy hãy kiểm tra ước tính có và không có để thấy sự khác biệt.
Mọi thứ ở trên đều sử dụng CLI headless, nhưng LM Studio cũng cung cấp một ứng dụng máy tính đầy đủ cho macOS. Giao diện đồ họa hữu ích cho việc giám sát trực quan và thử nghiệm nhanh trước khi cam kết với quy trình làm việc CLI.
Ảnh chụp màn hình bên dưới hiển thị chế độ xem máy chủ của ứng dụng máy tính với Gemma 4 đã được tải. Một vài điểm đáng chú ý:
Server status hiển thị "Running" với điểm cuối cục bộ tại
http://192.168.1.121:1234
, có thể truy cập từ bất kỳ thiết bị nào trong mạng
Loaded Models hiển thị mô hình hoạt động với các chỉ số trực tiếp: 29 lượt tạo, 1.087 token đã xử lý, 17.99 GB trong bộ nhớ
Supported endpoints bao gồm các định dạng tương thích với LM Studio API, OpenAI và Anthropic, với
POST /v1/messagescho giao thức AnthropicDeveloper Logs truyền tiến trình xử lý prompt theo thời gian thực, hữu ích cho việc theo dõi các prompt dài như phân tích code xử lý qua mô hình
Ứng dụng máy tính cũng hỗ trợ khả năng nhìn thấy của Gemma 4. Trong ảnh chụp màn hình bên dưới, bạn có thể thấy mô hình đang phân tích hình ảnh đồ họa quảng cáo Timezone Scheduler. Nó đã xác định chính xác tiêu đề, bản đồ thế giới với các thanh màu múi giờ, lưới lịch so sánh Brisbane/New York/London, các huy hiệu tính năng và các biểu tượng ngăn xếp công nghệ ở dưới cùng. Nó đã tạo ra 504 token với tốc độ 54.51 tok/giây với thời gian để có token đầu tiên là 3.15 giây.

Claude Code bí danh claude-lm cùng với Google Gemma 4 phân tích kho lưu trữ GitHub benchmark comparison Timezones Scheduler của tôi.


Lớp phủ giám sát hệ thống trong ảnh chụp màn hình cho thấy câu chuyện thực sự về suy luận cục bộ trông như thế nào trên phần cứng. Trên M4 Pro của tôi (4 E-Cores + 10 P-Cores, 20 GPU-Cores):
Áp lực bộ nhớ: 46.69 GB đã sử dụng trên tổng số 48.00 GB vật lý, với 38.07 GB bộ nhớ được giữ cố định (chủ yếu là mô hình cộng với ngữ cảnh). Swap đã sử dụng: 27.49 GB. Hệ thống vẫn phản hồi mặc dù sử dụng bộ nhớ gần đầy
Sử dụng GPU: 90% trong quá trình suy luận, với tần số P-Cluster ở 4.50 GHz và GPU ở 1.45 GHz
Sử dụng CPU: E-Core ở 82.42%, P-Core ở 35.96% trong quá trình tạo
Nhiệt độ: Các lõi CPU trung bình 91 độ C, GPU trung bình 92.46 độ C, nằm trong phạm vi tải liên tục bình thường cho M4 Pro
Tiêu thụ điện: Tổng gói 23.56W (CPU 11.06W, GPU 13.32W), hoạt động hiệu quả để chạy mô hình 26B tham số
Đây là điều làm cho Apple Silicon trở nên hấp dẫn đối với công việc LLM cục bộ. Kiến trúc bộ nhớ hợp nhất có nghĩa là CPU và GPU chia sẻ cùng một nhóm bộ nhớ, vì vậy không có việc sao chép dữ liệu giữa RAM CPU riêng biệt và VRAM GPU như trên các thiết lập GPU rời. Mô hình được tải một lần vào bộ nhớ hợp nhất và cả CPU và GPU đều truy cập trực tiếp.
Sau khi mô hình được tải, hãy khởi động máy chủ cục bộ:
lms server startThao tác này sẽ hiển thị một API tương thích với OpenAI tại http://localhost:1234/v1. Bất kỳ công cụ nào hoạt động với định dạng API của OpenAI (Continue, Cursor, các tập lệnh tùy chỉnh) đều có thể trỏ đến máy chủ cục bộ của bạn. LM Studio 0.4.0 cũng đã thêm một điểm cuối tương thích với Anthropic tại POST /v1/messages, có nghĩa là các công cụ nói giao thức Anthropic có thể kết nối trực tiếp mà không cần bộ chuyển đổi. Bạn có thể thay đổi cổng bằng lms server start --port 8080 nếu 1234 xung đột với thứ gì đó khác.
Máy chủ cũng hỗ trợ tải mô hình JIT (Just-In-Time): nếu một máy khách yêu cầu một mô hình hiện không được tải, LM Studio có thể tự động tải nó theo yêu cầu và tự động dỡ nó sau khi TTL hết hạn. Điều này hữu ích cho việc phục vụ nhiều mô hình mà không giữ tất cả chúng trong bộ nhớ.
Để giám sát những gì máy chủ đang làm trong thời gian thực, hãy truyền trực tiếp nhật ký:
lms log stream --source model --statsThao tác này hiển thị đầu vào/đầu ra của mỗi yêu cầu cùng với token/giây và độ trễ. Đối với nguồn cấp dữ liệu có thể đọc được bằng máy, hãy thêm --json. Bạn cũng có thể lọc chỉ các sự kiện cấp máy chủ (khởi động, lượt truy cập điểm cuối) bằng --source server.
Kết hợp với daemon không đầu, bạn có thể chạy cái này trên một máy chuyên dụng và phục vụ các mô hình trên mạng của mình. Máy chủ có thể truy cập được tại địa chỉ IP cục bộ của máy bạn (ví dụ:
http://192.168.1.121:1234
), vì vậy các thiết bị khác trong cùng một mạng có thể sử dụng nó làm điểm cuối suy luận được chia sẻ. Nếu bạn cần kiểm soát truy cập, hãy bật Yêu cầu xác thực trong cài đặt máy chủ và tạo mã thông báo API với quyền mỗi mã thông báo, được truy cập thông qua tiêu đề Authorization: Bearer $LM_API_TOKEN tiêu chuẩn.
Điểm cuối tương thích Anthropic mở ra một trường hợp sử dụng thú vị: chạy Claude Code chống lại một mô hình cục bộ thay vì API Anthropic. Điều này có nghĩa là hỗ trợ viết mã hoàn toàn ngoại tuyến, không mất phí mà không có dữ liệu nào rời khỏi máy của bạn.
Tôi đã thiết lập một hàm shell trong ~/.zshrc có tên claude-lm để cấu hình tất cả các biến môi trường cần thiết và khởi động Claude Code được trỏ đến máy chủ LM Studio cục bộ:
claude-lm() {
export ANTHROPIC_BASE_URL=http://localhost:1234
export ANTHROPIC_AUTH_TOKEN=lmstudio
export CLAUDE_CODE_MAX_TOOL_USE_CONCURRENCY="2"
export CLAUDE_CODE_NO_FLICKER="0"
export ANTHROPIC_MODEL="gemma-4-26b-a4b"
export CLAUDE_CODE_AUTO_COMPACT_WINDOW="48000"
export CLAUDE_AUTOCOMPACT_PCT_OVERRIDE="90"
export ANTHROPIC_DEFAULT_OPUS_MODEL="google/gemma-4-26b-a4b"
export ANTHROPIC_DEFAULT_SONNET_MODEL="google/gemma-4-26b-a4b"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="google/gemma-4-26b-a4b"
export CLAUDE_CODE_SUBAGENT_MODEL="google/gemma-4-26b-a4b"
export API_TIMEOUT_MS="30000000"
export BASH_DEFAULT_TIMEOUT_MS="2400000"
export BASH_MAX_TIMEOUT_MS="2500000"
export CLAUDE_CODE_MAX_OUTPUT_TOKENS="8000"
export CLAUDE_CODE_FILE_READ_MAX_OUTPUT_TOKENS="8000"
export CLAUDE_CODE_ATTRIBUTION_HEADER="0"
export CLAUDE_CODE_DISABLE_1M_CONTEXT="1"
export CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING="1"
claude "$@"
}Giải thích các biến quan trọng:
ANTHROPIC_BASE_URLvàANTHROPIC_AUTH_TOKENchỉ định Claude Code đến máy chủ LM Studio cục bộ. Mã tokenlmstudiolà mã giữ chỗ; LM Studio không yêu cầu xác thực theo mặc địnhANTHROPIC_MODELvà ba biếnDEFAULT_*_MODELbuộc tất cả các lựa chọn mô hình Claude Code (Opus, Sonnet, Haiku) phải đi qua Gemma 4. Nếu không có các biến này, Claude Code sẽ cố gắng gọi các tên mô hình Anthropic mà LM Studio không nhận dạngCLAUDE_CODE_SUBAGENT_MODELđảm bảo bất kỳ tác nhân phụ nào mà Claude Code tạo ra cũng sử dụng mô hình cục bộCLAUDE_CODE_AUTO_COMPACT_WINDOWvàCLAUDE_AUTOCOMPACT_PCT_OVERRIDEquản lý việc nén cửa sổ ngữ cảnh. Với cửa sổ ngữ cảnh 48K, việc nén sẽ kích hoạt khi sử dụng 90% để tránh vượt quá giới hạn giữa chừngAPI_TIMEOUT_MSđược đặt cao (30 triệu mili giây / ~8,3 giờ) vì suy luận cục bộ chậm hơn API Anthropic và các tác vụ phức tạp cần thời gian để hoàn thànhBASH_DEFAULT_TIMEOUT_MSvàBASH_MAX_TIMEOUT_MSkéo dài thời gian chờ lệnh shell lên 40-42 phút cho các hoạt động chạy dàiCLAUDE_CODE_MAX_OUTPUT_TOKENSvàCLAUDE_CODE_FILE_READ_MAX_OUTPUT_TOKENSgiới hạn đầu ra ở 8K token mỗi phản hồi, giúp thời gian tạo hợp lý trên phần cứng cục bộCLAUDE_CODE_DISABLE_1M_CONTEXTvàCLAUDE_CODE_DISABLE_ADAPTIVE_THINKINGtắt các tính năng giả định khả năng của API Anthropic mà mô hình cục bộ không hỗ trợ
Sau khi thêm vào ~/.zshrc và chạy source ~/.zshrc, bạn có thể bắt đầu phiên Claude Code hoàn toàn cục bộ bằng lệnh:
claude-lmNó hoạt động như Claude Code thông thường nhưng mọi yêu cầu đều ở trên máy của bạn. Điểm đánh đổi là tốc độ: Gemma 4 ở tốc độ 51 token/giây chậm hơn đáng kể so với API Anthropic đối với các tác vụ tạo mã lớn, nhưng đối với xem xét mã, chỉnh sửa nhỏ và khám phá thì nó hoàn toàn có thể sử dụng được.
Các mô hình MoE là lựa chọn tối ưu cho suy luận cục bộ. Kiến trúc 26B-A4B của Gemma 4 (tổng cộng 26B, hoạt động 4B) mang lại chất lượng tương đương khoảng 10B dày đặc với chi phí suy luận 4B. Hãy tìm kiếm các mô hình MoE tương tự khi chọn mô hình để chạy cục bộ.
Tiến trình không có giao diện đồ họa thay đổi quy trình làm việc. Trước phiên bản 0.4.0, LM Studio yêu cầu ứng dụng desktop phải mở. Bây giờ lms daemon up chạy ở chế độ nền và bạn tương tác hoàn toàn thông qua CLI hoặc API. Điều này làm cho nó khả thi cho việc triển khai máy chủ và các phiên SSH.
Độ dài ngữ cảnh là biến bộ nhớ chính. Bản thân mô hình sử dụng cố định khoảng 17,6 GiB. Tỷ lệ mở rộng ngữ cảnh gần như tuyến tính, vì vậy bạn có thể chọn chính xác sự đánh đổi mong muốn giữa cửa sổ ngữ cảnh và bộ nhớ khả dụng.
--estimate-only ngăn ngừa những bất ngờ. Luôn kiểm tra ước tính bộ nhớ trước khi tải một mô hình lớn với độ dài ngữ cảnh lớn. Nó mất một giây và giúp bạn tránh tình huống hết bộ nhớ.
Điểm cuối tương thích với Anthropic là một sự thay đổi cuộc chơi. Có khả năng chỉ định Claude Code vào một mô hình cục bộ bằng một bí danh shell có nghĩa là bạn có thể chuyển đổi giữa suy luận đám mây và cục bộ tùy thuộc vào tác vụ. Việc xem xét mã nhạy cảm với quyền riêng tư, làm việc ngoại tuyến hoặc chỉ đơn giản là tiết kiệm chi phí API cho các phiên khám phá đều được hưởng lợi.
Gemma 4 không tự nhận dạng bằng tên trong lms chat. Khi được hỏi "bạn là mô hình nào?", nó trả lời một cách chung chung là "một trợ lý AI". Đây là một hạn chế nhỏ về cách LM Studio xử lý các lời nhắc hệ thống, không phải là vấn đề của Gemma. Bạn có thể ghi đè điều này bằng một lời nhắc hệ thống tùy chỉnh.
Cửa sổ ngữ cảnh mặc định 48K là thận trọng đối với một mô hình hỗ trợ 256K. Nếu bạn có đủ bộ nhớ, bạn nên tải với độ dài ngữ cảnh cao hơn cho các tác vụ như phân tích tài liệu dài hoặc xem xét mã nhiều tệp.
Chạy Claude Code với một mô hình cục bộ không phải là một sự thay thế hoàn hảo cho API Anthropic. Các tác vụ phức tạp nhiều bước dựa vào khả năng suy nghĩ mở rộng của Claude hoặc cửa sổ ngữ cảnh rất lớn sẽ gặp phải những hạn chế. Thiết lập cục bộ hoạt động tốt nhất cho các tác vụ tập trung, một tệp mà cửa sổ ngữ cảnh 48K là đủ.
Áp lực bộ nhớ trên máy 48 GB với Gemma 4 đã được tải là có thật. Hệ thống đã sử dụng 46,69 GB trong tổng số 48 GB với 27,49 GB swap trong quá trình thử nghiệm. Nếu bạn chạy các ứng dụng ngốn bộ nhớ cùng với mô hình, hãy chuẩn bị cho tình trạng swap liên tục. Cấu hình 64 GB trở lên sẽ thoải mái hơn cho việc sử dụng liên tục.
Tôi đang thử nghiệm các mô hình cục bộ khác cùng với Gemma 4 cho các trường hợp sử dụng khác nhau: Qwen 3.5 35B cho các tác vụ lập trình, GLM 4.7 Flash cho soạn thảo nhanh và Nemotron 3 Nano cho trích xuất có cấu trúc. Một bài viết so sánh chi tiết về nơi mỗi mô hình hoạt động tốt nhất đang được chuẩn bị.
Nếu bạn muốn thử thiết lập này:
Cài đặt:
curl -fsSL https://lmstudio.ai/install.sh | bashKhởi động daemon:
lms daemon upTải Gemma 4:
lms get google/gemma-4-26b-a4bTrò chuyện cục bộ:
lms chat google/gemma-4-26b-a4b --statsKết nối Claude Code: thêm hàm
claude-lmvào~/.zshrccủa bạn, sau đó chạyclaude-lmthay vìclaude
Nếu bạn quan tâm đến việc xây dựng AI thực tế cho ứng dụng web, quy trình làm việc của nhà phát triển và cơ sở hạ tầng, hãy đăng ký để nhận các bài viết trong tương lai. Bạn cũng có thể theo dõi các cập nhật ngắn hơn của tôi trên Threads (@george_sl_liu) và Bluesky (@georgesl.bsky.social) hoặc đăng ký và theo dõi.
Tác giả: vbtechguy