Các tác nhân định hướng nghiên cứu: Khi một tác nhân đọc trước khi mã hóa
Research-Driven Agents: When an agent reads before it codes
Các nhà nghiên cứu vừa chứng minh rằng hiệu suất của các coding agent sẽ tăng vọt nếu chúng được bổ sung thêm bước "nghiên cứu tài liệu" (literature search) — cho phép mô hình đọc hiểu các bài báo khoa học và tham khảo cách triển khai của những repo đối thủ trước khi bắt tay vào viết code. Trong khi các agent truyền thống thường chỉ giỏi xử lý các tối ưu hóa cục bộ, phương pháp đa bước này đã giúp một agent nhận diện được các cải tiến về mặt kiến trúc (chẳng hạn như kỹ thuật kernel fusion) và mang lại mức tăng tốc 15% cho `llama.cpp`. Kết quả này có được là nhờ agent đã tự xác định đúng điểm nghẽn nằm ở băng thông bộ nhớ (memory bandwidth) thay vì năng lực tính toán (compute). Đối với cộng đồng lập trình viên, đây là tín hiệu cho thấy sự thay đổi trong tư duy xây dựng agent: kiến thức chuyên môn và bối cảnh ngoại vi (external context) đóng vai trò quyết định để giải quyết các vấn đề sâu về hệ thống. Trong tương lai, các team phát triển nên cân nhắc tích hợp các vòng lặp nghiên cứu tự động vào quy trình CI/CD. Việc này giúp mở khóa những không gian tối ưu hóa mà các agent bị giới hạn trong source code nội bộ khó lòng tiếp cận được.
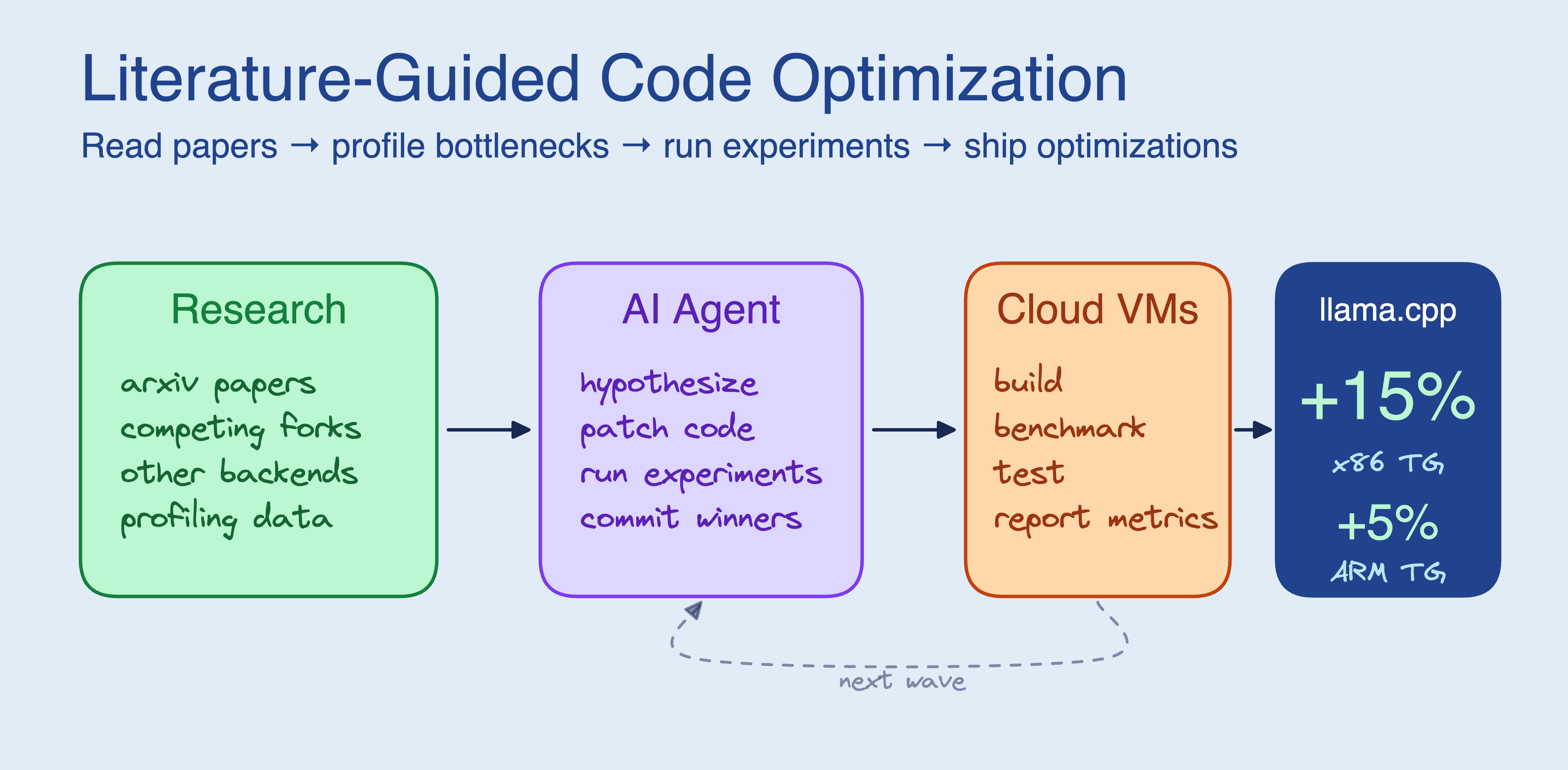
Các tác nhân mã hóa chỉ hoạt động từ mã sẽ tạo ra các giả thuyết nông cạn. Việc thêm một giai đoạn nghiên cứu — các bài báo arxiv, các nhánh phân nhánh cạnh tranh, các chương trình phụ trợ khác — đã tạo ra 5 sự hợp nhất hạt nhân giúp suy luận CPU llama.cpp nhanh hơn 15%.
TL;DR: Các tác nhân mã hóa tạo ra sự tối ưu hóa tốt hơn khi họ đọc các bài báo và nghiên cứu các dự án cạnh tranh trước khi chạm vào mã. Chúng tôi đã thêm một giai đoạn tìm kiếm tài liệu vào vòng lặp autoresearch / pi-autoresearch , trỏ nó vào llama.cpp với 4 máy ảo đám mây và trong ~3 giờ, nó đã tạo ra 5 tối ưu hóa giúp tạo văn bản chú ý nhanh hơn 15% trên x86 và nhanh hơn +5% trên ARM (TinyLlama 1.1B). thiết lập đầy đủ hoạt động với bất kỳ dự án nào có bộ điểm chuẩn và thử nghiệm.
Ghi nhớ chính:
- Các tác nhân đọc giấy tờ và nghiên cứu các dự án cạnh tranh trước khi viết mã tìm các tối ưu hóa mà các tác nhân chỉ mã bỏ lỡ. Nghiên cứu tài liệu chỉ ra tác nhân tại các phản ứng tổng hợp của người vận hành có trong phụ trợ CUDA/Kim loại nhưng không có trong CPU.
- 5 trong số 30 thí nghiệm đã hạ cánh: 4 lần hợp nhất hạt nhân và sự song song thích ứng. Chiến thắng lớn nhất đã hợp nhất ba đường chuyền QK của Flash attention thành một vòng lặp AVX2 FMA duy nhất.
- Học dĩa và các phần phụ trợ khác hiệu quả hơn là tìm kiếm arxiv. ik_llama.cpp và phụ trợ CUDA trực tiếp thông báo cho hai trong số năm tối ưu hóa cuối cùng.
- Tổng chi phí: ~$ 29 ($ 20 trong máy ảo CPU, $ 9 trong cuộc gọi API) trong ~3 giờ với 4 máy ảo.
Trường hợp ngữ cảnh chỉ có mã hoạt động
Karpathy's ] autoresearch cho thấy rằng một tác nhân mã hóa có thể tự động cải thiện tập lệnh đào tạo mạng nơ-ron. Trong bài đăng trước của chúng tôi , chúng tôi đã chia tỷ lệ đó thành 16 GPU và xem tác nhân chạy ~910 thử nghiệm trong 8 giờ, khiến val_bpb giảm 2,87%. Tác nhân đã động não các ý tưởng chỉ từ ngữ cảnh mã và các thí nghiệm đều là các biến thể trên cùng một train.py .
Kể từ đó, pi-autoresearch đã tổng quát hóa vòng lặp thành một phần mở rộng có thể tái sử dụng cho bất kỳ mục tiêu chuẩn nào. Giám đốc điều hành Shopify Tobi Lütke đã chạy nó trên Liquid, công cụ mẫu Ruby xử lý 292 tỷ $ khối lượng hàng hóa hàng năm. Tác nhân đã chạy ~120 thử nghiệm, tạo ra 93 cam kết cắt giảm 53% thời gian phân tích cú pháp+ kết xuất và phân bổ 61% với hồi quy bằng không trong 974 bài kiểm tra đơn vị ( bài viết của Simon Willison , bài đăng của Tobi ).
Trong trường hợp đó, bề mặt tối ưu hóa có thể nhìn thấy trong nguồn. Tác nhân Liquid có thể đọc tokenizer, xem StringScanner là nút cổ chai và suy nghĩ các lựa chọn thay thế từ cơ sở mã.
Trường hợp ngữ cảnh chỉ có mã bị hỏng
Không phải mọi vấn đề tối ưu hóa đều hoạt động theo cách này. Cơ sở mã cho bạn biết mã hoạt động như thế nào, nhưng không phải tại sao nó chậm hoặc những lựa chọn thay thế tồn tại bên ngoài cơ sở mã này . Khi câu trả lời nằm bên ngoài nguồn (trong các bài báo arxiv, trong các dự án cạnh tranh, ví dụ: trong kiến thức về lĩnh vực mà một kỹ sư cao cấp sẽ mang lại), một tác nhân làm việc chỉ từ mã sẽ tạo ra các giả thuyết nông cạn.
Chúng tôi đã thấy điều này khi chỉ tác nhân vào đường dẫn suy luận CPU của llama.cpp . Không gian tìm kiếm tối ưu hóa không phải là “thử một tỷ lệ học tập khác." Đó là "tôi nên hợp nhất hai bộ nhớ này?", "khối lượng công việc này bị ràng buộc bởi tính toán hay bị ràng buộc bởi bộ nhớ?", "điều gì đã ik_llama.cpp đã thử?”
Làn sóng thử nghiệm đầu tiên của tác nhân cho thấy vấn đề. Chỉ làm việc từ bối cảnh mã, nó đã đi thẳng vào việc tối ưu hóa vi mô SIMD trong các sản phẩm DOT được lượng tử hóa nằm trong đường dẫn nóng nhân ma trận của GGML. Nó đã thử:
- AVX2 tìm nạp trước trong vòng lặp bên trong sản phẩm chấm Q4_0 (+0,8%)
- vòng lặp 2x mở ra với ắc quy kép (+0,9%)[
- Loại bỏ bộ đệm tạm thời trong
mul_mat(-2,8%, hồi quy)[ - Tính toán ranh giới khối nâng (+0,6%)[[TAG_83][TAG_84][TAG_85]]Tất cả trong tiếng ồn. Sau khi tác nhân chết:
“Kết quả Sóng 1 cho thấy rằng tối ưu hóa vi mô trong đường dẫn tính toán mang lại lợi nhuận không đáng kể vì tạo văn bản bị giới hạn băng thông bộ nhớ, không bị giới hạn tính toán.”
Một mô hình 606 MiB với ~49 token/s tiêu thụ ~30 GB/s băng thông bộ nhớ, gần với giới hạn DRAM của c6i.2xlarge. Không có thủ thuật SIMD nào sẽ giúp ích khi CPU bị đình trệ trong khi chờ trọng lượng mô hình đến từ DRAM. Nhưng một mình mã không cho bạn biết điều này. Bạn cần biết băng thông bộ nhớ của phần cứng mục tiêu, hiểu mô hình roofline và nhận ra rằng suy luận kích thước hàng loạt-1 bị ràng buộc bởi bộ nhớ. Đó là kiến thức về miền mà nhân viên chăm sóc khách hàng không có.
Thêm giai đoạn nghiên cứu
Nếu nút cổ chai là chất lượng giả thuyết, hãy cung cấp cho tác nhân đầu vào tốt hơn. Trước khi chạy bất kỳ thử nghiệm nào, hãy yêu cầu nó đọc giấy tờ, nghiên cứu dĩa và xem những dự án khác đã thử. Sự chuẩn bị tương tự mà một kỹ sư cấp cao sẽ làm trước khi chạm vào mã lạ.
Vòng lặp tự động tìm kiếm ban đầu là: chỉnh sửa mã -> chạy thử nghiệm -> kiểm tra số liệu -> giữ hoặc loại bỏ.
pi-autoresearchđã khái quát hóa điều này cho bất kỳ dự án nào có số liệu chuẩn. Phiên bản của chúng tôi dựa trên đó và thêm một bước nghiên cứu và thực thi đám mây song song: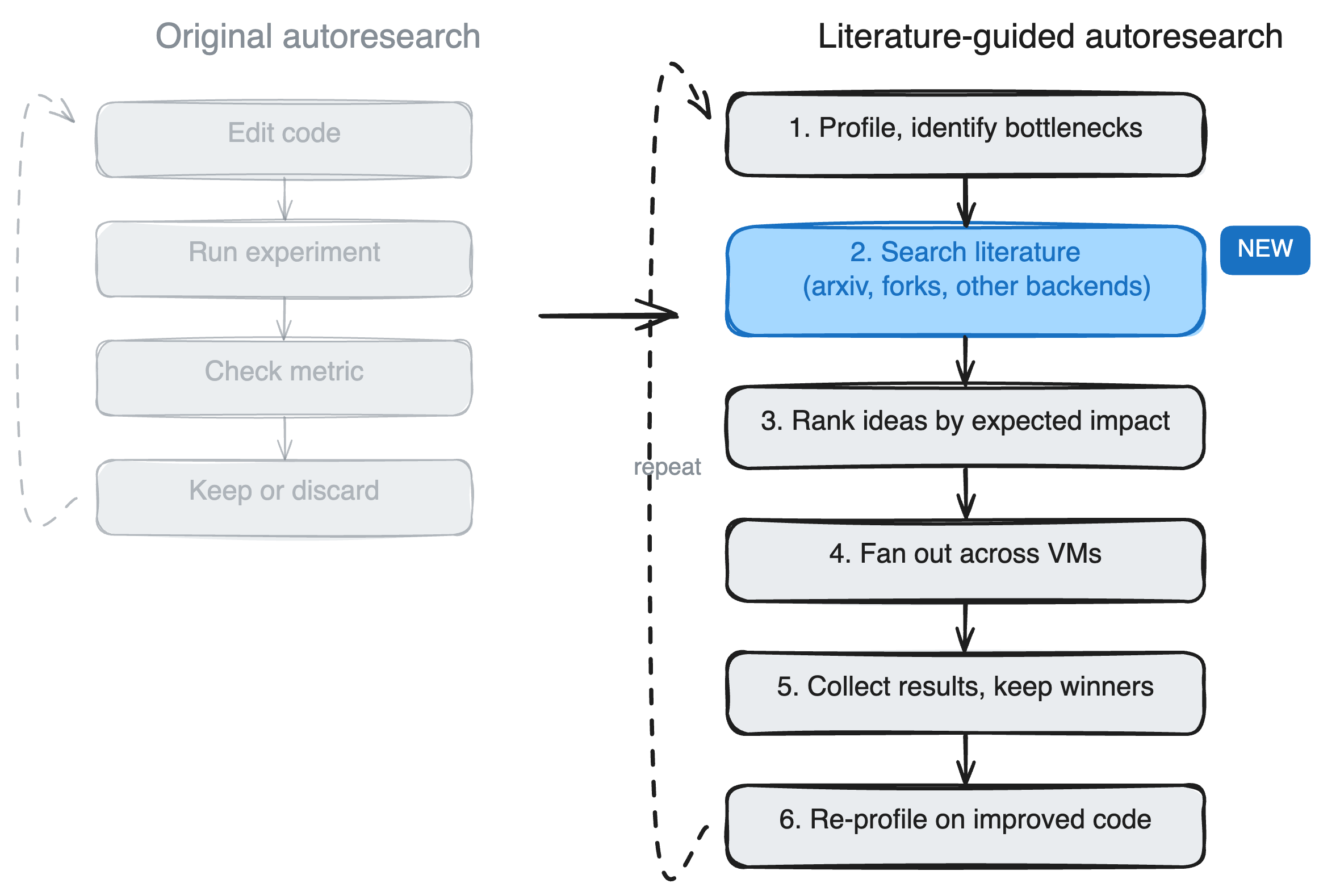
Tác nhân viết tập lệnh chuẩn của riêng mình ([TAG_107]] autoresearch.sh ) và kiểm tra độ chính xác ([TAG_109]] autoresearch.checks.sh ), sau đó sử dụng SkyPilot để thực hiện các thử nghiệm trên các máy ảo đám mây. Mỗi thử nghiệm chạy trên máy ảo riêng của nó: xây dựng dự án, chạy điểm chuẩn, chạy kiểm tra tính chính xác, số liệu báo cáo. Nhân viên chăm sóc khách hàng kiểm tra kết quả qua
nhật ký bầu trời, cam kết người chiến thắng và xếp hàng trong đợt tiếp theo.experiment.yaml: Mẫu nhiệm vụ SkyPilot cho một thí nghiệm
[resources: cpus : 4 [TAG_146]+[TAG_147]][TAG_148]] Memory:[ [8[+[ workdir : . envs : EXPERIMENT_ID: đường cơ sở EXPERIMENT_DESC: ["ĐO đường CƠ SỞ" BUILD_Cmd: [[TAG_252]]"make -j$(nproc)" BENCH_TIMEOUT: [300[TAG_270]] CHECK_TIMEOUT: 300 setup:][] |[TAG_307]][TAG_308]] cd ~/sky_workdir nếu [ -f setup_deps.sh]; sau đó bash setup_deps.sh khác eval "${BUILD_CMD}" fi run: |[TAG_368]] cd ~/sky_workdir # Xây dựng, điểm chuẩn, chạy kiểm tra, báo cáo các mục hàng SỐ LIỆU eval "${BUILD_CMD}" 2>&1 | tail -30 BENCH_OUTPUT=$(timeout "${BENCH_TIMEOUT}" bash autoresearch.sh 2>&1) echo "$BENCH_OUTPUT" # ... trích xuất các dòng SỐ LIỆU, chạy autoresearch.checks.sh ... echo "EXPERIMENT_STATUS: done"Không cần GPU để tối ưu hóa mã bị ràng buộc bởi CPU. Ghi đè bằng
--gpusnếu mục tiêu của bạn cần điểm chuẩn GPU.Nhật ký thử nghiệm
Chúng tôi đã chỉ ra Claude Code tại llama.cpp, cung cấp cho nó 4 máy ảo AWS thông qua SkyPilot và yêu cầu nó giúp suy luận CPU nhanh hơn.
Mục tiêu: Thông lượng suy luận CPU cho TinyLlama 1.1B (lượng tử hóa Q4_0), được đánh giá dựa trên hai kiến trúc:
- x86: AWS c6i.2xlarge (Intel Xeon Ice Lake, 8 vCPUs, AVX-512)
- ARM: AWS c7g.2xlarge (Graviton3, 8 vCPUs, NEON)
llama-bench -p 512 -n 128 -t 8 -r 5[[TAG_442].Nó bắt đầu với 4 máy ảo x86 để thiết lập các đường cơ sở và chạy thử nghiệm. Sau đó, nó đã cung cấp các máy ảo ARM để kiểm tra tính di động; mỗi phản ứng tổng hợp hạt nhân bao gồm cả đường dẫn AVX2/FMA và NEON, với các dự phòng vô hướng.
Nghiên cứu đã đưa ra kết quả gì
Giữa các đợt thử nghiệm, tác nhân đã chạy hai chuỗi nghiên cứu song song:
[[TAG_450]- Các dự án cạnh tranh: ik_llama.cpp (một ngã ba tập trung vào hiệu suất), llamafile's tinyBLAS, PowerInfer, ExLlamaV2 (tác giả của bài đăng này thậm chí còn không biết về một số dự án này)
- Arxiv papers: FlashAttention (IO-aware tiled attention), Blockbuster (block-level operator fusion), LLM Inference Acceleration via Efficient Operation Fusion, Online normalizer calculation for softmax, Inference Performance Optimization for Large Language Models on on CPU (Phân vùng luồng nhận biết bộ nhớ cache của Intel)
Những phát hiện hàng đầu:
- ik_llama.cpp's row-interleaved quantization repacking gave 2.9x PP improvement. Nó đã được tải lên llama.cpp dòng chính thông qua định dạng đóng gói lại
Q4_0_8x8. Nhân viên xác nhận nó đã hoạt động trong điểm chuẩn. - Bài báo bom tấn đề xuất hợp nhất toàn bộ khối FFN (RMSNorm + cổng matmul + lên matmul + SwiGLU + xuống matmul) thành một đường lát gạch cư trú trong bộ nhớ cache duy nhất. Tác nhân đã cố gắng thực hiện nó nhưng các ma trận trọng lượng được lượng tử hóa (
Q4_0_8x8), vàggml_CONCATkhông hoạt động với các tensor được lượng tử hóa được đóng gói lại. Việc thực hiện đúng yêu cầu thay đổi trình tải mô hình. - Tác nhân đã kiểm tra xem hỗ trợ AVX-512 của c6i.2xlarge có đang được sử dụng hay không. Đúng là như vậy.
-march =nativecho phép nó thông qua các macro tiền xử lý của trình biên dịch, mặc dù biến CMake hiển thịGGML_AVX512 =OFF(chỉ ảnh hưởng đến các bản dựng MSVC). - Cổng hợp nhất + trọng lượng tăng (PR # 19139 ) nối cổng và lên ma trận trọng lượng chiếu để loại bỏ một tải kích hoạt trên mỗi khối FFN. Điều này mang lại +12% PP cho các mô hình MoE nhưng chưa được triển khai cho các mô hình dày đặc.
Phân tích ngã ba hữu ích hơn tìm kiếm arxiv. Một số ý tưởng có thể thực hiện được đến từ việc nghiên cứu những gì ik_llama.cpp và llamafile đã xuất xưởng. Nghiên cứu các phụ trợ CUDA và Kim loại cũng trực tiếp dẫn đến tối ưu hóa #4 bên dưới: tác nhân nhận thấy rằng sự hợp nhất RMS_NORM + mul tồn tại trong mọi phụ trợ ngoại trừ CPU.
Trục: từ tính toán đến bộ nhớ
Sau khi Wave 1 thất bại, tác nhân đã thay đổi hướng:
[[tag_498]]“Tôi cần xoay vòng để tối ưu hóa làm giảm lưu lượng bộ nhớ hoặc cải thiện khả năng truy cập bộ nhớ mẫu.”
Matmul chiếm ~95% thời gian suy luận, vì vậy các hoạt động còn lại (softmax, định mức RMS, lượng tử hóa) chỉ để lại ~5% khoảng trống. Nhưng những hoạt động đó đủ nhỏ để bị ràng buộc bởi tính toán thay vì bị ràng buộc bởi bộ nhớ, vì vậy việc giảm số lần truyền bộ nhớ trong chúng có thể giúp ích.
Tối ưu hóa đã hạ cánh
Năm trong số hơn30 thử nghiệm đã được đưa vào mã cuối cùng. Mỗi mục tiêu tập trung vào một phần khác nhau của chi phí không tính thuế:
1. Softmax fusion
Mã hiện có đã sao chép -> scale -> thêm mặt nạ trong ba lần truyền dữ liệu riêng biệt. Tác nhân hợp nhất chúng thành một:
// Trước: 3 lượt memcpy([TAG_530]]wp , [TAG_535]]sp [TAG_537], [TAG_539]]]nc[[TAG_540] [TAG_541]]*[TAG_542]] sizeof(float)); // vượt qua 1: sao chép ggml_ vec_scale_f32(nc, wp, tỷ lệ); // vượt qua 2: quy mô ggml _vec_add_f32(nc, wp, wp, mp_f32); // vượt qua 3: thêm mặt nạ // Sau: 1 lần vượt qua for (int i = 0; i < nc; i++) { wp[i] = sp[i] * tỷ lệ + mp_f32[i];2. Hợp nhất định mức RMS
Mẫu tương tự. Bản gốc đã thực hiện
memcpy(y, x)rồiggml_vec_scale_f32(y,scale)dưới dạng hai lượt. Hợp nhất thànhy[i] = x[i] *scaletrong một lần truyền.3. Song song hóa thích ứng from_float
Vòng lượng tử hóa
from_float(chuyển đổi kích hoạt sang định dạng đầu vào sản phẩm chấm) đã sử dụng chiến lược song song hóa một kích thước phù hợp cho tất cả. Giờ đây nó sẽ phân vùng theo hàng khi có nhiều hàng (xử lý nhanh chóng) và theo phần tử khi có ít hàng (tạo văn bản).Được xác minh thông qua so sánh A/B rõ ràng trên cùng một VM (không cần chú ý nhanh, để tách biệt tác động của ba điều này thay đổi):
pp (mã thông báo/giây) tg (mã thông báo/số) Đường cơ sở 210,65 ± 0,64 48,90 ± 0,50 Được tối ưu hóa 215,97 ± 1,52 49,33 ± năm TAG_751]] +0,9% Văn bản thế hệ hầu như không thay đổi, như mong đợi: TG bị giới hạn băng thông bộ nhớ (như được mô tả trong Sóng 1 ở trên) và những thay đổi này không chạm đến đường dẫn matmul. Quá trình xử lý nhanh chóng tăng +2,5% vì PP bị giới hạn tính toán và được hưởng lợi từ việc truyền ít bộ nhớ hơn.
4. Sự kết hợp RMS_NORM + MUL ở cấp độ đồ thị
Điều này đến trực tiếp từ giai đoạn nghiên cứu. Trong khi nghiên cứu cách các chương trình phụ trợ khác xử lý các hoạt động tương tự, nhân viên đã phát hiện ra một lỗ hổng:
“RMS Norm + MUL fusion không tồn tại cho chương trình phụ trợ CPU, nó chỉ có trong CUDA. Thay vì thực hiện định mức RMS (đọc x, tính tổng, viết y=x*scale) rồi MUL (đọc y, đọc trọng số, viết y=y*weights), chúng tôi thực hiện điều đó trong một lần: y = x *scale * trọng lượng.”
Các chương trình phụ trợ CUDA và Metal đã hợp nhất những điều này nhưng chương trình phụ trợ CPU thì không. Tác nhân sẽ không tìm kiếm điều này mà không nghiên cứu các chương trình phụ trợ khác trong giai đoạn nghiên cứu. Chỉ xét riêng mã CPU, phương pháp hai bước có vẻ ổn.
Nó đã triển khai tính năng phát hiện mẫu trong vòng thực thi biểu đồ CPU. Khi thấy
RMS_NORMtheo sau làMULtrong đó đầu vào của MUL là đầu ra RMS_NORM, nó sẽ gọi một hạt nhân hợp nhất tính toány = x * (1/sqrt(mean_sq + eps)) * trọng sốtrong một lần chuyển với nội tại AVX2 và NEON rõ ràng:// Định mức RMS hợp nhất + nhân (AVX2 đường dẫn) __m256 vscale = _mm256_set1_ps(tỷ lệ); cho (; i + 7 < ne; i += 8) { __m256 vx = _mm256_loadu_ps(x + i); __m256 vw = _mm256_loadu_ps(w + i); _mm256_storeu_ps(y + i, _mm256_mul_ps(_mm256_mul_p s(vx, vw), vscale));Phiên bản đầu tiên không giúp ích được gì và nhân viên hỗ trợ đã tìm ra lý do:
“Sự hợp nhất tiết kiệm một lượt bộ nhớ nhưng vòng lặp vô hướng hợp nhất chậm hơn vòng lặp ban đầu Các đường chuyền riêng biệt được tối ưu hóa SIMD. Mã ban đầu được sử dụng
memcpy(được tối ưu hóa cao) +ggml_vec_scale_f32(SIMD) +binary_op<op_mul>(SIMD). Vòng lặp hợp nhất của chúng tôiy[i] = x[i] *scale * w[i]là vô hướng và trình biên dịch có thể không vector hóa hai phép nhân một cách hiệu quả.”Vì vậy, nó viết lại hạt nhân với các bản chất AVX2 và NEON rõ ràng. Bản thân tác động đo được nằm trong phạm vi nhiễu nhưng nó kết hợp với sự kết hợp chú ý flash và giảm phương sai TG, có thể là do các kiểu truy cập bộ nhớ dễ dự đoán hơn.
5. Sự chú ý của Flash KQ tổng hợp
Đường dẫn chú ý của flash được xếp kề có tỷ lệ -> pad -> thêm mặt nạ -> tìm giá trị tối đa khi riêng biệt vượt qua ô QK. Nhân viên đã hợp nhất những thông tin này thành một thẻ FMA AVX2 duy nhất:
// Trước: 3 lần vượt qua ô KQ ggml_ vec_scale_f32(M, kq, tỷ lệ); // vượt qua 1 ggml _vec_add_f32(M, kq, kq, mask_row); // vượt qua 2 ggm l_vec_max_f32(M, &max, kq); // vượt qua 3 // Sau: 1 thẻ AVX2 FMA __m256 vscale = _mm256_set1_ps(tỷ lệ); __m256 vmax = _mm256_set1_ps(-INFINITY); for (int i = 0; i [[TAG_1706] M; i += 8) { __m256 v = _mm256_fmadd_ps(_mm256_loadu_ps([[TAG _1141]]&kq[i]), vscale, _mm256_loadu_ps(&[[TAG _1165]]mask_row[i])); _mm256_storeu_ps(& kq[i], v); vmax = _mm256_max_ps(vmax, v);Để rõ ràng: sự kết hợp hạt nhân của tác nhân nhắm mục tiêu cụ thể vào đường dẫn xếp kề của sự chú ý flash. Sự chú ý nhanh chóng (
-fa 1) là một tính năng llama.cpp có sẵn, không phải là tính năng do tác nhân phát minh ra. Tuy nhiên, sự kết hợp của tác nhân tồn tại bên trong đường dẫn mã đó, vì vậy điểm chuẩn cần kích hoạt-fa 1để thực hiện chúng. Nhân viên hỗ trợ đã nhận ra điều này một nửa và chuyển đổi điểm chuẩn cho phù hợp.Kết quả
So sánh cuối cùng là giữa táo với táo: đường cơ sở có bật FA và được tối ưu hóa khi bật FA. Cả hai đều sử dụng cùng một lá cờ; sự khác biệt là các hạt nhân hợp nhất. Đã xác minh thông qua các bản dựng A/B rõ ràng với 5 lần lặp lại:
x86, Intel Xeon (c6i.2xlarge, AVX-512)
Cấu hình pp512 (t/s) tg128 (t/s) Đường cơ sở + FA 241,24 ± 2,24 41,37 ± 19,24 Được tối ưu hóa + FA 244,22 ± 1,78 47,62 ± 0,59 Thay đổi +1,2%[[T AG_1280]] +15,1% ARM, Graviton3 (c7g.2xlarge, NEON)
Cấu hình pp512 (t/s) tg128 (t/s) Baseline + FA 292,99 ± 2,47 94,07 ± 19,87 Được tối ưu hóa + FA 298,56 ± 4,28 98,77 ± 2,59 Thay đổi +1,9% +5% Cải thiện TG lớn hơn PP vì đường dẫn chú ý hợp nhất quan trọng hơn trong quá trình nhắn tin thế hệ, trong đó sự chú ý chiếm một phần lớn hơn trong tổng thời gian chạy. Sự khác biệt cũng cần lưu ý: đường cơ sở+FA TG có độ ồn ±19 t/s, trong khi tối ưu hóa+FA có ±0,59 t/s trên x86. Sự kết hợp này loại bỏ hoạt động ghi trung gian gây ô nhiễm bộ đệm, khiến các đường dẫn nóng dễ dự đoán hơn.
Lưu ý: chúng tôi đã chạy trên các phiên bản EC2 thuê chung với 5 lần lặp lại. Những người hàng xóm ồn ào có thể thay đổi kết quả trên phần cứng dùng chung (xem Máy ảo đám mây rất ồn bên dưới). Chúng tôi tin rằng hướng đi này là có thật trên cả kiến trúc và nhiều VM nhưng xử lý tỷ lệ phần trăm chính xác cho phù hợp.
Chúng tôi chưa gửi PR. Sự khác biệt hoàn toàn là tại đây.
Những gì không hiệu quả
Các thử nghiệm đã không thành công
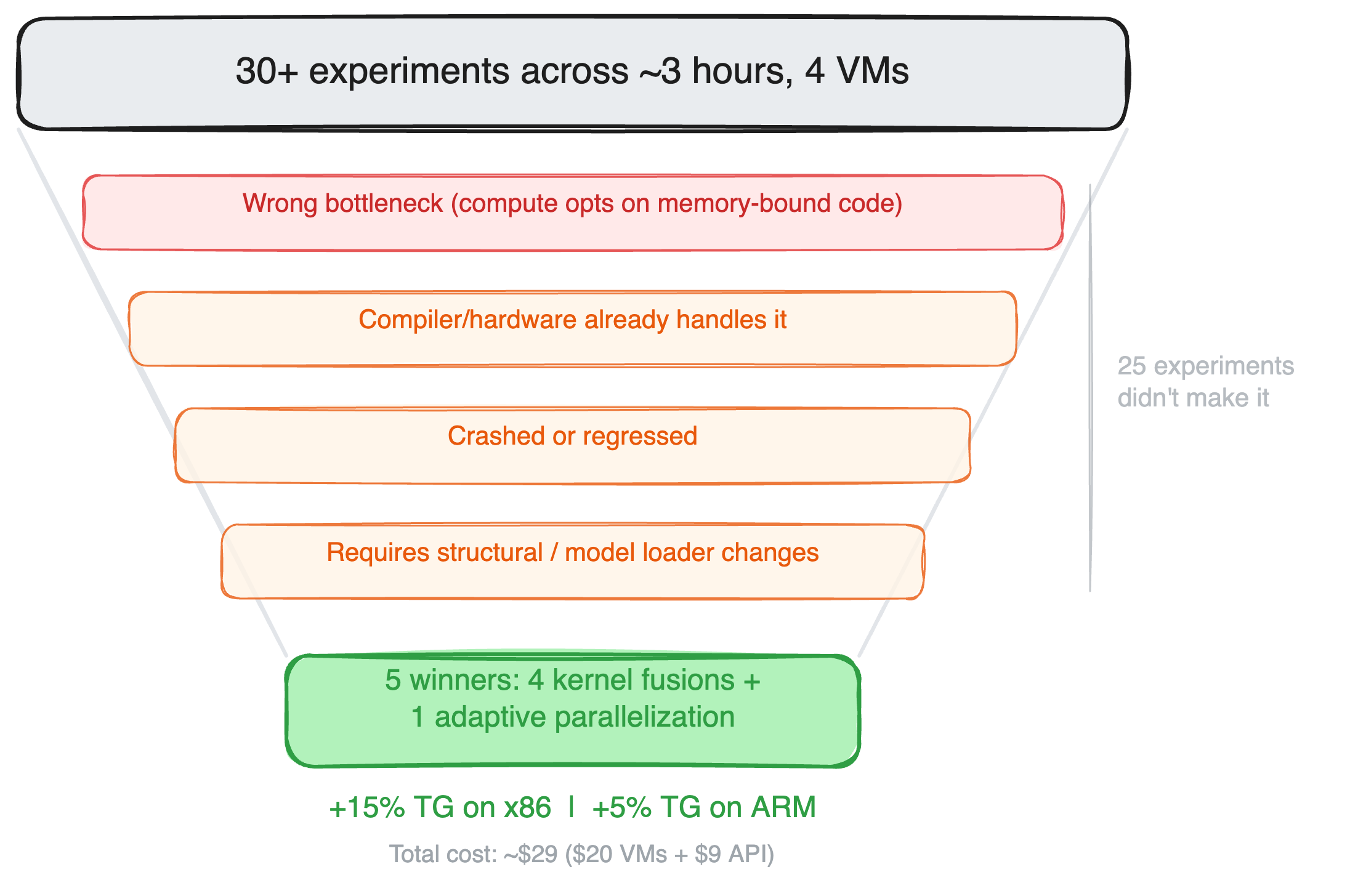
25 trong số hơn 30 thử nghiệm đã không thành công. Một số lỗi tiêu biểu:
- SIMD softmax với tổng theo chiều ngang bị trì hoãn: các tổng một phần được tích lũy trong vectơ
__m256và đã thực hiện giảm theo chiều ngang một lần ở cuối. Cải thiện 0%. Trình biên dịch cũng tự động vectơ hóa vòng lặp vô hướng. - Điều chỉnh kích thước ô chú ý flash: đã kiểm tra Q=32/KV=128, Q=128/KV=32, Q=32/KV=32. Kích thước 64×64 mặc định đã là tối ưu.
- Đã hợp nhất cổng+tăng matmul thông qua
ggml_concat: đã cố gắng ghép cổng và tăng ma trận trọng số tại thời điểm xây dựng biểu đồ để tiết kiệm một tải kích hoạt đầu vào. Đã xảy ra sự cố vìggml_concatkhông hỗ trợ tensor lượng tử hóa được đóng gói lại (Q4_0_8x8). Việc triển khai đúng cách yêu cầu thay đổi trình tải mô hình chứ không phải thao tác với thời gian biểu đồ. - Tìm nạp trước V trong quá trình tính toán softmax: đã thử tìm nạp trước dữ liệu V trong khi tính toán softmax trên QK. Cải thiện 0%. Trình tìm nạp trước phần cứng đã xử lý quyền truy cập tuần tự.
- Loại bỏ tải dư thừa trong sgemm của llamafile: hàm Q4_0
loadthực hiệndenibble +trừ 8và vòng lặp bên trong gọi nó 3 lần cho cùng một mục đích khối. Tác nhân đã lưu vào bộ đệm các giá trị đã tải. Cải thiện 0% vì tính năng loại bỏ biểu thức con phổ biến của trình biên dịch đã xử lý được vấn đề này.
Một chủ đề định kỳ: trình biên dịch và phần cứng đang thực hiện nhiều việc mà bạn nghĩ nên thử theo cách thủ công. Nếu không có kinh nghiệm về hành vi của trình biên dịch, tác nhân không thể dự đoán được "sự tối ưu hóa" nào mà trình biên dịch sẽ xử lý.
Lỗi điểm chuẩn
autoresearch.shcủa chúng tôi có lỗi phân tích cú pháp JSON được báo cáo là 14 t/s thay vì 52 t/s đối với văn bản thế hệ. Nhiều thử nghiệm đã chạy sai đường cơ sở trước khi chúng tôi phát hiện ra nó. Lỗi:llama-benchxuất JSON với các trườngn_promptvàn_genvà tập lệnh phân tích cú pháp được lọc trên tên trường không như vậy tồn tại.Con người cũng sẽ mắc lỗi này nhưng có thể sẽ phát hiện ra những con số thấp một cách vô lý sớm hơn. Tác nhân tin cậy vào tập lệnh của chính mình.
Các máy ảo trên đám mây rất ồn ào
Các phiên bản EC2 trên phần cứng dùng chung có chênh lệch lên tới 30% giữa các lần chạy do các máy ảo lân cận bị nhiễu. Chúng tôi đã học được điều này một cách khó khăn: exp-08 cho thấy “cải thiện +2,1%” nhưng hóa ra lại nằm trong phạm vi nhiễu khi đo lại đường cơ sở. VM-02 luôn thể hiện phương sai cao hơn các máy khác.
Các biện pháp giảm nhẹ: thay thế các máy ảo ồn ào bằng các máy ảo mới (các máy ảo mới thường xuất hiện trên các máy chủ yên tĩnh hơn), sử dụng stddev làm tín hiệu chất lượng và chỉ tin cậy các kết quả có stddev < 2% giá trị trung bình.
Mã xem lại
Sau khi thực hiện tối ưu hóa, nhân viên đã xem xét các thay đổi của chính mình so với các quy ước và quy ước cơ sở mã trước đây của llama.cpp phản hồi của người bảo trì. Nó đã phát hiện ra một lỗi về tính chính xác trong mã tổng hợp biểu đồ của chính nó: tính năng phát hiện mẫu cuộn bằng tay không kiểm tra xem đầu ra định mức RMS trung gian có những người tiêu dùng khác trong biểu đồ hay không. Nếu một nút khác đọc từ đầu ra đó thì hạt nhân hợp nhất (chỉ ghi vào đầu ra MUL) sẽ không được khởi tạo.
Cách khắc phục: sử dụng cơ sở hạ tầng
ggml_can_fuse()hiện có để xác thực số lượng sử dụng, cờ tính toán, cờ đầu ra và xem chuỗi nguồn. Mọi chương trình phụ trợ khác (CUDA, Metal, Vulkan, OpenCL) đều đã sử dụng tính năng này.Điều này có ý nghĩa gì đối với các tác nhân mã hóa
Vòng lặp tự động nghiên cứu tiêu chuẩn (động não từ mã, chạy thử nghiệm, kiểm tra số liệu) hoạt động khi bề mặt tối ưu hóa hiển thị trong nguồn. Kết quả của Liquid đã chứng minh điều đó. Nhưng đối với các vấn đề mà cơ sở mã không chứa đủ thông tin để tạo ra các giả thuyết tốt, việc cấp cho tác nhân quyền truy cập vào các bài báo và các hoạt động triển khai cạnh tranh sẽ thay đổi những gì nó cố gắng thực hiện.
Các thử nghiệm Wave 1 trên llama.cpp đều là các biến thể của việc "làm cho vòng lặp này nhanh hơn", loại giả thuyết bạn nhận được khi ngữ cảnh duy nhất của bạn là mã. Sau khi đọc các tài liệu về sự kết hợp toán tử và nghiên cứu cách các phần phụ trợ CUDA/Metal xử lý các hoạt động tương tự, nhân viên bắt đầu đặt các câu hỏi khác nhau: “Tôi có thể kết hợp hai hoạt động này để loại bỏ thẻ nhớ không?” và “mẫu này có tồn tại trong các chương trình phụ trợ khác ngoài CPU không?” Những câu hỏi đó đã dẫn đến tối ưu hóa #4 và #5.
Đây là cách hoạt động này so với công việc tự động nghiên cứu GPU trước đây của chúng tôi. Xin lưu ý rằng những mục tiêu này nhắm đến các vấn đề rất khác nhau (siêu tham số đào tạo ML so với hạt nhân C++ đã biên dịch), do đó, các con số không thể so sánh trực tiếp:
GPU Tự động nghiên cứu Văn học có hướng dẫn Tự động nghiên cứu Target Đào tạo ML (karpathy/autoresearch) Bất kỳ dự án OSS nào Tính toán Cụm GPU (H100/H200) Máy ảo CPU (giá rẻ) Chiến lược tìm kiếm Nhân viên tư vấn từ mã bối cảnh Nhân viên hỗ trợ đọc giấy tờ + các điểm nghẽn trong hồ sơ Thử nghiệm đếm ~910 sau 8 giờ 30+ sau ~3 giờ Chi phí thử nghiệm ~5 mỗi phút tối thiểu (chạy đào tạo) ~5 phút mỗi lần (bản dựng + điểm chuẩn) Tổng chi phí ~$300 (GPU) ~$20 (CPU VM) + ~$9 (API) Số lượng thử nghiệm thấp hơn vì mỗi thử nghiệm llama.cpp bao gồm bản dựng CMake đầy đủ (~2 phút) cộng với điểm chuẩn (~3 phút) và nhân viên đã dành thời gian giữa các đợt đọc giấy tờ và lập hồ sơ. Với tính năng tự động nghiên cứu GPU, tác nhân có thể thực hiện 10-13 thử nghiệm trên mỗi đợt và nhận được kết quả sau 5 phút. Tại đây, nó đã chạy 4 thử nghiệm trên mỗi đợt (mỗi đợt một VM) và dành thời gian giữa các đợt để thực hiện nghiên cứu.
Hãy thử trên dự án của riêng bạn
Thiết lập này hoạt động với bất kỳ dự án nào có điểm chuẩn và bộ thử nghiệm. Sao chép mục tiêu của bạn, tải xuống hai tệp và chỉ cho tác nhân mã hóa của bạn theo hướng dẫn:
# Sao chép dự án mục tiêu của bạn git bản sao https://github.com/<org>/<project>.git cd <dự án> # Tải xuống mẫu thử nghiệm và hướng dẫn dành cho tác nhân curl -fsSL https://raw.githubusercontent.com/skypilot-org/skypilot/master/examples/autonomous-code-optimization/experiment.yaml -o thí nghiệm.yaml curl -fsSL https://raw.githubusercontent.com/skypilot-org/skypilot/master/examples/autonomous-code-optimization/instructions.md -oguides.md # Hướng tác nhân mã hóa của bạn theo hướng dẫn claude "Đọc hướng dẫn.md và tối ưu hóa <dự án> cho <chỉ số của bạn>."Hoặc sử dụng một dòng thiết lập:
export TARGET_REPO="https://github.com/<org>/<project>.git" curl -fsSL https://raw.githubusercontent.com/skypilot-org/skypilot/master/examples/autonomous-code-optimization/setup.sh | bashML các khung suy luận là những ứng cử viên sáng giá vì chúng di chuyển nhanh, có số liệu thông lượng rõ ràng và các cơ hội tối ưu hóa mới liên tục xuất hiện với từng tính năng chính. Một số điểm xuất phát:
Dự án Số liệu Văn học góc vLLM mã thông báo/số thông qua benchmark_throughput.pyPagedLập lịch chú ý, lưu tiền tố vào bộ nhớ đệm, suy đoán giải mã SGLang mã thông báo/giây, TTFT RadixAttention, bị ràng buộc giải mã, điền trước theo khối llama.cpp mã thông báo/s thông qua llama-benchKết hợp toán tử, matmul lượng tử hóa, tiết kiệm bộ nhớ đệm chú ý TensorRT-LLM mã thông báo/giây thông qua điểm chuẩn/Hợp nhất hạt nhân, tối ưu hóa bộ nhớ đệm KV, đang hoạt động phân nhóm ggml test-backend-opsperfHạt SIMD, định dạng lượng tử hóa, tối ưu hóa đồ thị whisper.cpp yếu tố thời gian thực thông qua benchGiải mã suy đoán, tìm kiếm chùm tia theo đợt Chúng tôi cũng đã thử nhiều dự án có uy tín hơn (Valkey/Redis, PostgreSQL, CPython, SQLite) và thấy khó cải thiện bề mặt hơn. Các cơ sở mã đó đã được tối ưu hóa bởi hàng trăm người đóng góp trong nhiều thập kỷ và lợi ích mà tác nhân tìm thấy là rất nhỏ.
Đặt
infra:trong YAML để nhắm mục tiêu một chương trình phụ trợ cụ thể (infra: k8scho Kubernetes,infra: awsdành cho AWS, v.v.).Quá trình thiết lập đầy đủ có tại
skypilot/examples/autonomous-code-optimization.Để nhận được thông tin cập nhật mới nhất, vui lòng gắn dấu sao và xem dự án GitHub repo, theo dõi @skypilot_org hoặc tham gia SkyPilot cộng đồng Slack.
Tác giả: hopechong