Các nguyên tắc Thấu hiểu máy móc
Principles of Mechanical Sympathy
Dù phần cứng ngày nay đã có những bước tiến vượt bậc, phần mềm hiện đại thường vẫn kém hiệu quả do thiếu sự tương thích với kiến trúc vật lý bên dưới. Bằng cách áp dụng triết lý "Mechanical Sympathy" (sự đồng cảm với máy móc) — tập trung vào việc thấu hiểu CPU cache hierarchy, cơ chế truy cập bộ nhớ và hành vi của cache line — các lập trình viên có thể xây dựng những hệ thống đạt hiệu suất cao hơn gấp nhiều lần. Nguyên tắc cốt lõi ở đây là ưu tiên các cấu trúc dữ liệu và thuật toán hướng đến việc truy cập bộ nhớ tuần tự (sequential) thay vì truy cập ngẫu nhiên (random access). Suy cho cùng, để viết được phần mềm hiệu năng cao, chúng ta cần vượt ra khỏi các lớp abstraction thông thường để tối ưu hóa cách code thực thi sao cho khớp với cách CPU thực sự đọc và xử lý dữ liệu.
Trong thập kỷ qua, phần cứng đã chứng kiến những tiến bộ vượt bậc, từ bộ nhớ hợp nhất định nghĩa lại cách thức hoạt động của GPU tiêu dùng cho đến các công cụ thần kinh có thể chạy các mô hình AI hàng tỷ thông số trên máy tính xách tay. Và...
Trong thập kỷ qua, phần cứng đã chứng kiến những tiến bộ vượt bậc, từ hợp nhất bộ nhớ đã xác định lại cách thức hoạt động của GPU dành cho người tiêu dùng, cho đến các công cụ thần kinh có thể chạy mô hình AI hàng tỷ thông số trên máy tính xách tay.
Tuy nhiên, phần mềm vẫn chậm do khởi động nguội kéo dài vài giây cho các chức năng không có máy chủ đơn giản, cho đến các đường dẫn ETL kéo dài hàng giờ chỉ đơn thuần là chuyển đổi các tệp CSV thành các hàng trong một cơ sở dữ liệu.
Trở lại năm 2011, một kỹ sư giao dịch tần số cao tên là Martin Thompson nhận thấy những vấn đề này, do họ thiếu Sự đồng cảm cơ học. Anh ấy đã mượn cụm từ này từ một Công thức 1 nhà vô địch:
Bạn không cần phải là kỹ sư để trở thành tay đua nhưng bạn cần Sự thông cảm cơ học.
-- Ngài Jackie Stewart, Nhà vô địch Thế giới Công thức 1
Mặc dù chúng tôi không (thường) lái xe đua nhưng ý tưởng này áp dụng cho người thực hành phần mềm. Bằng việc “đồng cảm” với phần cứng, phần mềm của chúng tôi tiếp tục hoạt động, chúng ta có thể tạo ra những hệ thống có hiệu suất đáng kinh ngạc. các đồng cảm cơ học LMAX Quy trình kiến trúc hàng triệu sự kiện mỗi giây trên một luồng Java.
Lấy cảm hứng từ công việc của Martin, tôi đã dành cả thập kỷ qua để tạo ra các hệ thống nhạy cảm với hiệu suất, từ nền tảng suy luận AI phục vụ hàng triệu người của các sản phẩm tại Wayfair, để mã hóa nhị phân mới hoạt động tốt hơn Bộ đệm giao thức.
Trong bài viết này, tôi đề cập đến các nguyên tắc đồng cảm cơ học mà tôi sử dụng mỗi ngày để tạo ra những hệ thống như thế này - những nguyên tắc có thể áp dụng được nhiều nhất mọi nơi, ở bất kỳ tỷ lệ nào.
Truy cập bộ nhớ không ngẫu nhiên
Sự đồng cảm về mặt cơ học bắt đầu bằng việc hiểu cách CPU lưu trữ, truy cập, và chia sẻ bộ nhớ.
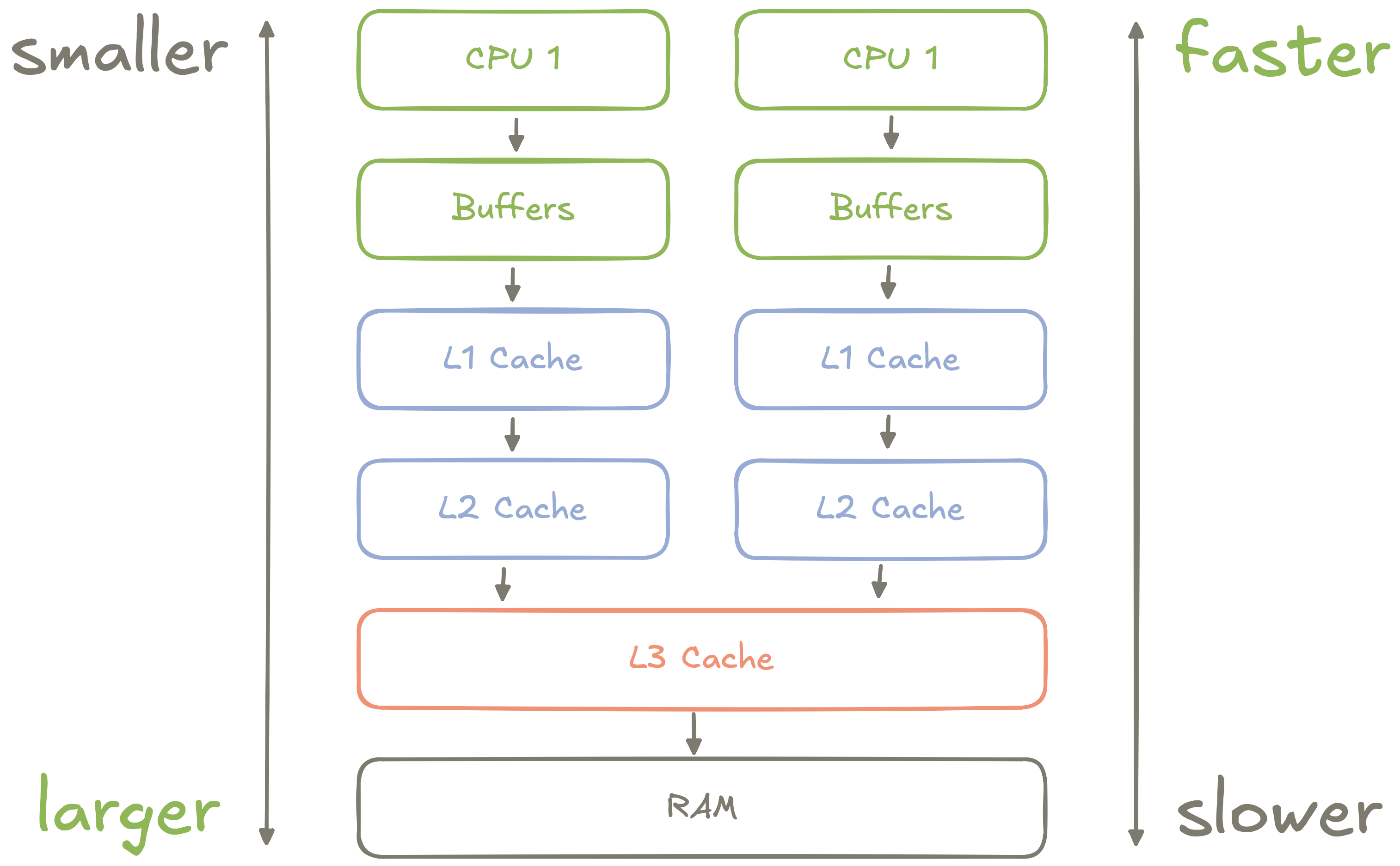
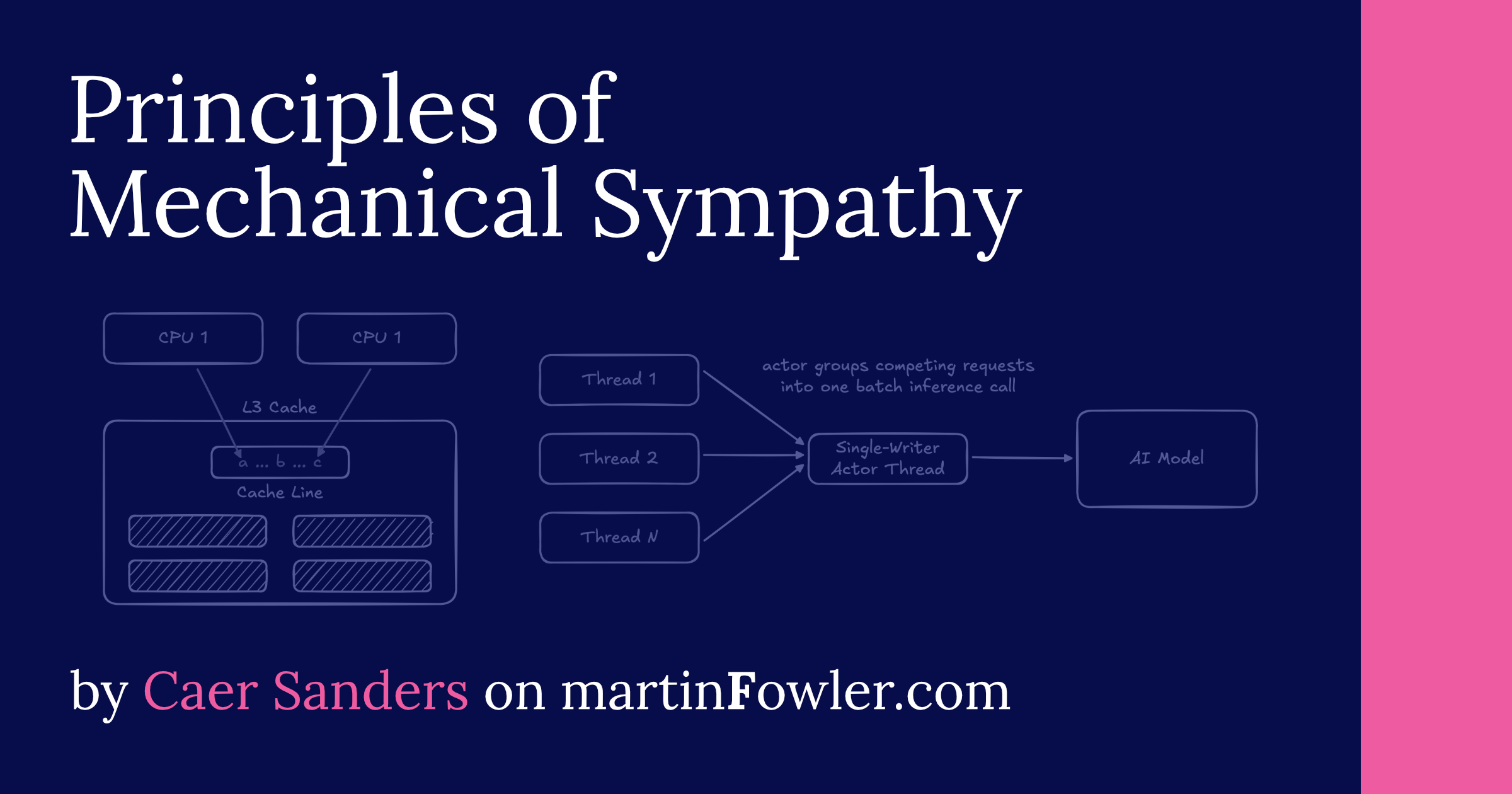
Hình 1: Sơ đồ trừu tượng về cách CPU bộ nhớ được sắp xếp
Hầu hết các CPU hiện đại - từ chip của Intel đến silicon của Apple - đều có tổ chức bộ nhớ vào một hệ thống phân cấp gồm các thanh ghi, bộ đệm và bộ nhớ đệm, mỗi bộ nhớ đệm có độ trễ truy cập:
khác nhau- Mỗi lõi CPU có lõi riêng các thanh ghi và bộ đệm tốc độ cao dùng để lưu trữ những thứ như biến cục bộ và hướng dẫn trong chuyến bay.
- Mỗi lõi CPU có Bộ nhớ đệm cấp 1 (L1) riêng, lớn hơn nhiều so với các thanh ghi và bộ đệm của lõi nhưng chậm hơn một chút.
- Mỗi lõi CPU có Bộ nhớ đệm cấp 2 (L2) riêng, thậm chí còn lớn hơn bộ đệm L1, và được sử dụng như một loại bộ đệm giữa bộ nhớ đệm L1 và L3.
- Nhiều lõi CPU chia sẻ Bộ nhớ đệm cấp 3 (L3) cho đến nay vẫn là bộ nhớ đệm lớn nhất nhưng chậm hơn nhiều so với bộ nhớ đệm L1 hoặc L2. Bộ đệm này được sử dụng để chia sẻ dữ liệu giữa các lõi CPU.
- Tất cả lõi CPU chia sẻ quyền truy cập vào bộ nhớ chính, AKA RAM. Bộ nhớ này là do mức độ lớn, tốc độ truy cập chậm nhất của CPU.
Vì bộ đệm của CPU quá nhỏ nên các chương trình thường xuyên cần truy cập bộ nhớ đệm hoặc bộ nhớ chính chậm hơn. Để che giấu chi phí của việc truy cập này, CPU thực hiện một trò chơi cá cược:
- Bộ nhớ được truy cập gần đây sẽ có thể sẽ sớm được truy cập lại.
- Bộ nhớ gần bộ nhớ được truy cập gần đây sẽ có thể được truy cập sớm thôi.
- Quyền truy cập bộ nhớ sẽ có thể cũng tương tự mẫu.
Trong luyện tập, những lần đặt cược này có nghĩa là khả năng truy cập tuyến tính tốt hơn khả năng truy cập trong cùng một trang, trong đó lần lượt truy cập ngẫu nhiên trên các trang vượt trội hơn rất nhiều.
Ưu tiên các thuật toán và cấu trúc dữ liệu cho phép dự đoán, truy cập tuần tự vào dữ liệu. Ví dụ: khi xây dựng đường dẫn ETL, thực hiện quét tuần tự trên toàn bộ cơ sở dữ liệu nguồn và lọc ra các khóa không liên quan thay vì truy vấn từng mục một bằng khóa.
Dòng bộ nhớ đệm và chia sẻ sai
Trong bộ nhớ đệm L1, L2 và L3, bộ nhớ thường được lưu trữ theo “khối” được gọi là Dòng bộ nhớ đệm. Các dòng bộ đệm luôn là một lũy thừa tiếp giáp của hai về độ dài và thường dài 64 byte.
CPU luôn tải (“đọc”) hoặc lưu trữ bộ nhớ (“ghi”) theo bội số của một dòng bộ đệm, dẫn đến một vấn đề nhỏ: Điều gì xảy ra nếu hai CPU ghi vào hai biến riêng biệt trong cùng một dòng bộ đệm?
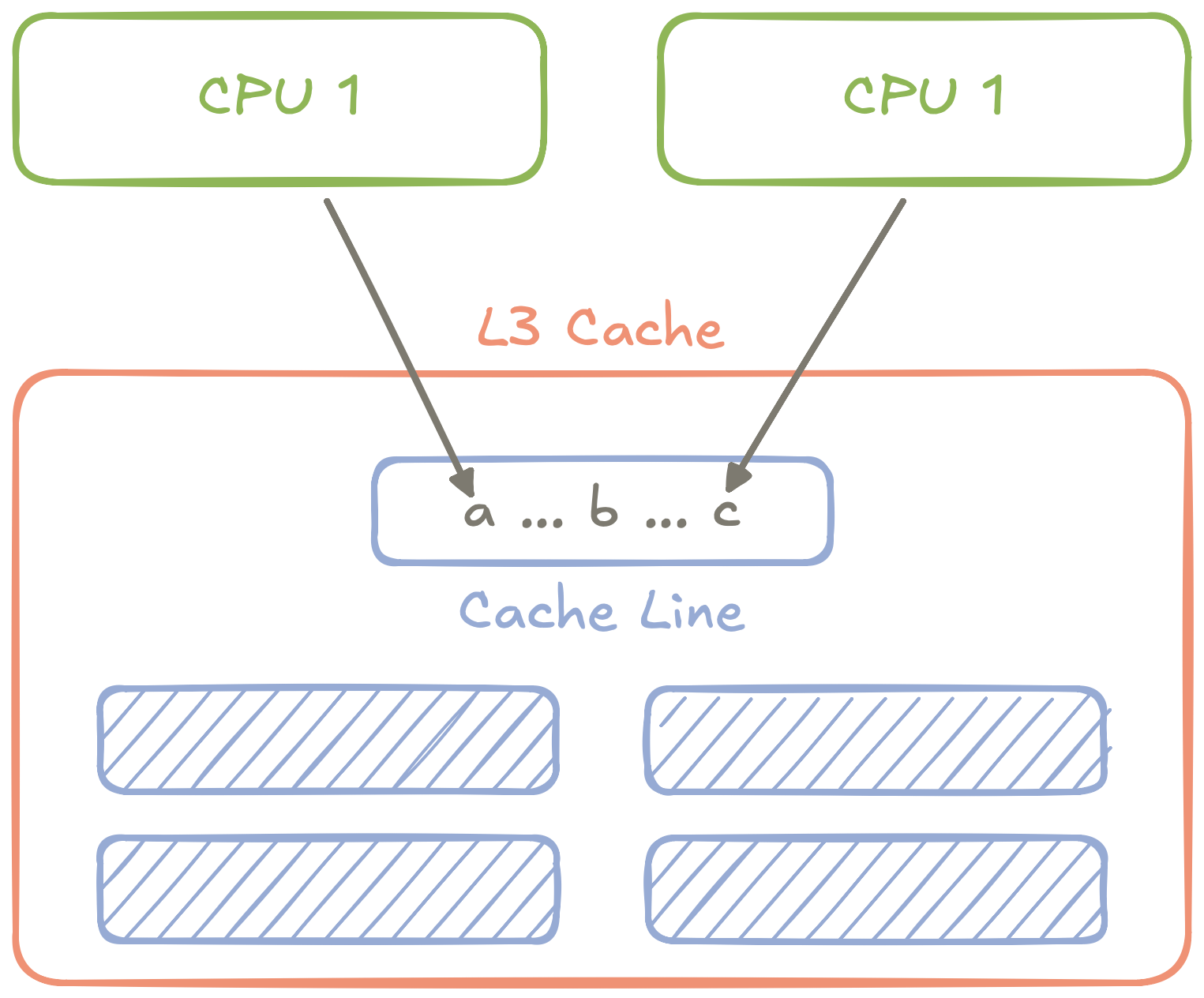
Hình 2: Sơ đồ trừu tượng về cách hoạt động của hai CPU truy cập hai biến khác nhau vẫn có thể xung đột nếu các biến đó trong cùng một dòng bộ đệm.
Bạn gặp phải Chia sẻ sai: Hai CPU tranh giành quyền truy cập vào hai CPU các biến khác nhau trong cùng một dòng bộ đệm, buộc CPU phải sử dụng lần lượt truy cập các biến thông qua bộ nhớ đệm L3 dùng chung.
Để ngăn chặn việc chia sẻ sai, nhiều thiết bị có độ trễ thấp các ứng dụng sẽ “đệm” các dòng trong bộ nhớ đệm có dữ liệu trống để mỗi dòng chứa một một cách hiệu quả biến. Cái sự khác biệt có thể đáng kinh ngạc:
- Nếu không có khoảng đệm, việc chia sẻ sai dòng bộ nhớ đệm sẽ khiến tốc độ tăng gần như tuyến tính độ trễ khi các luồng được thêm vào.
- Với phần đệm, độ trễ gần như không đổi khi các luồng được thêm vào.
Quan trọng là việc chia sẻ sai chỉ xuất hiện khi các biến đang được được viết cho. Khi chúng đang được đọc, mỗi CPU có thể sao chép dòng bộ đệm vào bộ đệm hoặc bộ đệm cục bộ của nó và sẽ không phải lo lắng về đồng bộ hóa trạng thái của các dòng bộ đệm đó với các bản sao của CPU khác.
Vì hành vi này, một trong những nạn nhân phổ biến nhất của hành vi lừa đảo chia sẻ là các biến nguyên tử. Đây chỉ là một trong số ít kiểu dữ liệu (trong hầu hết các ngôn ngữ) có thể được chia sẻ một cách an toàn và giữa các chuỗi (và nói rộng ra là lõi CPU).
Nếu bạn đang theo đuổi mục tiêu hiệu suất cuối cùng trong một ứng dụng đa luồng, hãy kiểm tra xem có bất kỳ cấu trúc dữ liệu nào đang tồn tại không được ghi bởi nhiều luồng - và nếu cấu trúc dữ liệu đó có thể là một nạn nhân của sự giả dối chia sẻ.
Nguyên tắc của một người viết
Chia sẻ sai không phải là vấn đề duy nhất phát sinh khi xây dựng hệ thống đa luồng. Có các vấn đề về an toàn và tính chính xác (như chủng tộc điều kiện), chi phí chuyển đổi ngữ cảnh khi số luồng vượt quá CPU lõi và chi phí sử dụng quá lớn của mutexes (“khóa”).
Những quan sát này đưa tôi đến với nguyên tắc đồng cảm một cách máy móc mà tôi sử dụng nhiều nhất: Người viết đơn Nguyên tắc.
Về khái niệm, nguyên tắc rất đơn giản: Nếu có một số dữ liệu (như biến trong bộ nhớ) hoặc tài nguyên (như ổ cắm TCP) mà ứng dụng ghi vào, tất cả những thao tác ghi đó phải được thực hiện bằng một chuỗi duy nhất.
Hãy xem xét một ví dụ tối thiểu về dịch vụ HTTP sử dụng văn bản và tạo ra các vectơ nhúng của văn bản đó. Những phần nhúng này sẽ là được tạo trong dịch vụ thông qua mô hình AI nhúng văn bản. Vì điều này ví dụ: chúng tôi sẽ giả sử đó là mô hình ONNX, nhưng Tensorflow, PyTorch hoặc bất kỳ mô hình nào các thời gian chạy AI khác sẽ hoạt động.
Hình 3: Sơ đồ trừu tượng của một văn bản đơn giản dịch vụ nhúng
Dịch vụ này sẽ nhanh chóng gặp sự cố: Hầu hết thời gian chạy AI có thể mỗi lần chỉ thực hiện một lệnh gọi suy luận cho một mô hình. Trong sự ngây thơ kiến trúc ở trên, chúng tôi sử dụng mutex để giải quyết vấn đề này. Thật không may, nếu có nhiều yêu cầu truy cập dịch vụ cùng một lúc, họ sẽ xếp hàng chờ mutex và nhanh chóng bị khuất phục trước người dẫn đầu chặn.
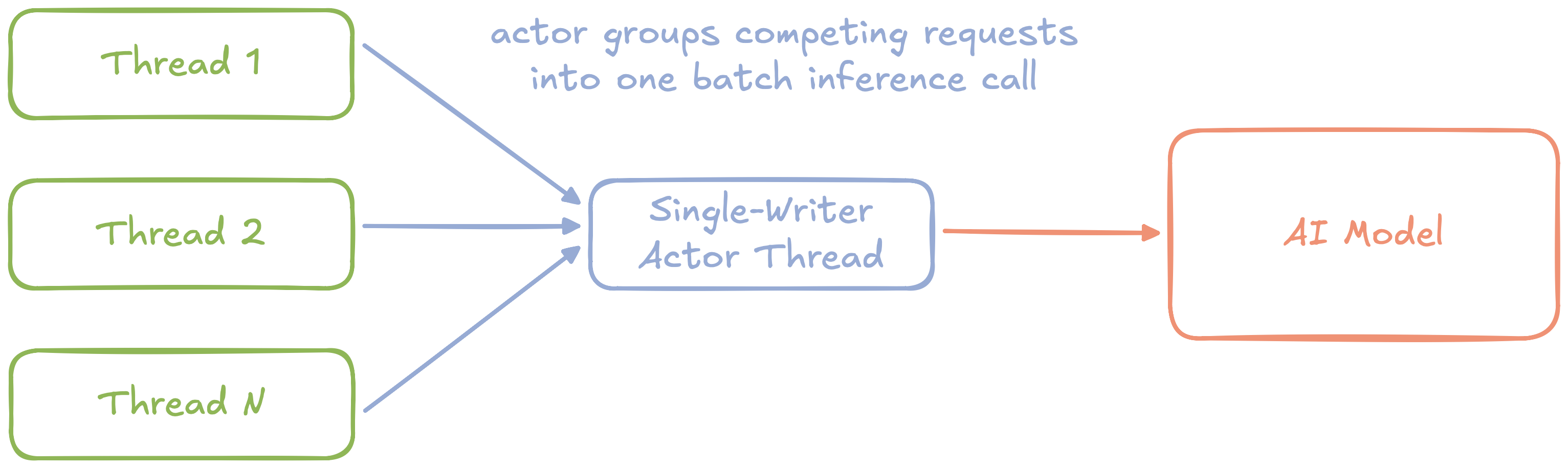
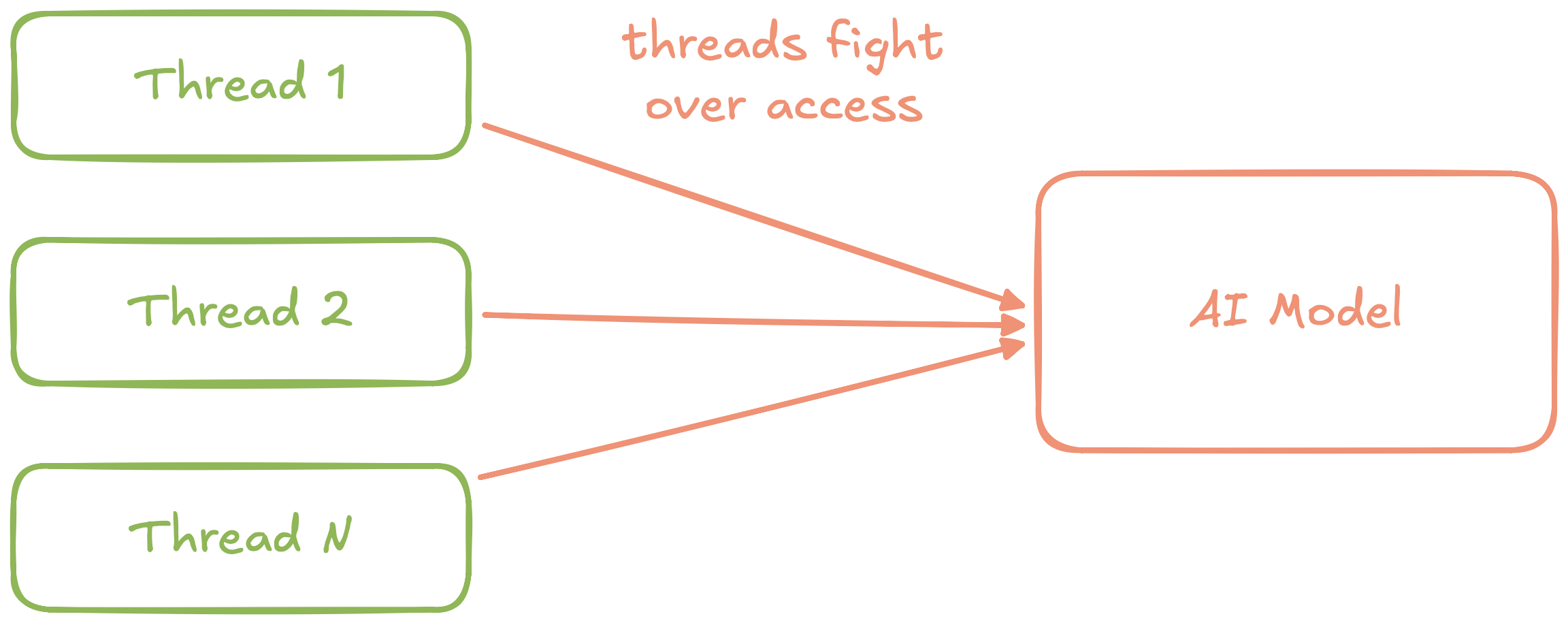
Hình 4: Sơ đồ trừu tượng của việc nhúng văn bản dịch vụ sử dụng nguyên tắc ghi đơn với tính năng phân nhóm
Chúng tôi có thể loại bỏ những vấn đề này bằng cách tái cấu trúc bằng trình ghi đơn nguyên tắc. Đầu tiên, chúng ta có thể bao bọc quyền truy cập vào mô hình trong một vùng chuyên dụng Chủ đề Diễn viên. Thay vì các luồng yêu cầu cạnh tranh một mutex, giờ đây chúng gửi tin nhắn không đồng bộ tới diễn viên.
Vì diễn viên là người viết đơn nên có thể nhóm độc lập yêu cầu lệnh gọi suy luận hàng loạt single tới mô hình cơ bản và sau đó gửi kết quả không đồng bộ trở lại yêu cầu riêng lẻ chủ đề.
Tránh bảo vệ tài nguyên có thể ghi bằng mutex. Thay vào đó, hãy dành một chuỗi duy nhất (“tác nhân”) để sở hữu mọi nội dung viết và sử dụng thông báo không đồng bộ để gửi nội dung ghi từ các chuỗi khác cho tác nhân.
Pha trộn tự nhiên
Sử dụng nguyên tắc ghi đơn, chúng tôi đã xóa mutex khỏi dịch vụ AI đơn giản và hỗ trợ thêm cho các cuộc gọi suy luận hàng loạt. Nhưng làm thế nào Tác nhân có nên tạo các lô này không?
Nếu chúng tôi đợi kích thước lô được xác định trước, các yêu cầu có thể chặn một khoảng thời gian không giới hạn cho đến khi có đủ yêu cầu. Nếu chúng ta tạo ra theo đợt trong khoảng thời gian cố định, các yêu cầu sẽ chặn với số lượng giới hạn thời gian giữa mỗi đợt.
Có một cách tốt hơn một trong hai cách tiếp cận sau: Phân nhóm tự nhiên.
Với việc tạo lô tự nhiên, tác nhân bắt đầu tạo một lô ngay khi các yêu cầu có sẵn trong hàng đợi của nó và hoàn thành lô đó ngay khi như đã đạt đến kích thước lô tối đa hoặc hàng đợi trống.
Mượn một ví dụ hoạt động từ bài đăng gốc của Martin về tự nhiên theo đợt, chúng ta có thể thấy độ trễ giảm dần theo yêu cầu theo thời gian như thế nào:
| Chiến lược | Tốt nhất (µs) | Tệ nhất (µs) |
|---|---|---|
| Hết thời gian | 200 | 400 |
| Tự nhiên | 100 | 200 |
Ví dụ này giả định mỗi lô có độ trễ cố định là 100µs.
Với chiến lược phân nhóm dựa trên thời gian chờ, giả sử thời gian chờ là 100µs,
độ trễ trong trường hợp tốt nhất sẽ là 200µs khi tất cả yêu cầu trong lô được
đã nhận đồng thời (100µs cho chính yêu cầu đó và 100µs
chờ thêm yêu cầu trước khi gửi một đợt). Độ trễ trong trường hợp xấu nhất
sẽ là 400µs khi một số yêu cầu được nhận hơi muộn.
Với chiến lược phân khối tự nhiên, độ trễ trong trường hợp tốt nhất sẽ là 100µs
khi tất cả các yêu cầu trong đợt được nhận cùng một lúc. Trường hợp xấu nhất
độ trễ sẽ là 200µs khi một số yêu cầu được nhận hơi muộn.
Trong cả hai trường hợp, hiệu suất của việc tạo khối tự nhiên tốt gấp đôi so với chiến lược dựa trên thời gian chờ.
Nếu một người ghi xử lý các lô ghi (hoặc đọc!), hãy xây dựng từng lô một cách tham lam: Bắt đầu lô ngay khi có dữ liệu và kết thúc khi hàng đợi dữ liệu trống hoặc lô đó đầy đủ.
Những nguyên tắc này hoạt động tốt cho từng ứng dụng nhưng có quy mô theo toàn bộ hệ thống. Truy cập dữ liệu tuần tự, có thể dự đoán được áp dụng cho dữ liệu lớn hồ nhiều như một mảng trong bộ nhớ. Nguyên tắc một người viết có thể thúc đẩy hiệu suất của một ứng dụng sử dụng nhiều IO hoặc cung cấp nền tảng vững chắc cho Cấu trúc CQRS.
Khi chúng tôi viết phần mềm có sự tương thích về mặt cơ học, hiệu suất diễn ra một cách tự nhiên ở mọi quy mô.
Nhưng trước khi bạn tiếp tục: hãy ưu tiên khả năng quan sát trước khi tối ưu hóa. Bạn không thể cải thiện những gì bạn không thể biện pháp. Trước khi áp dụng bất kỳ biện pháp nào trong số này nguyên tắc, xác định SLI, SLO và SLA để bạn biết cần tập trung vào đâu và khi nào nên dừng.
Ưu tiên khả năng quan sát trước khi tối ưu hóa, trước khi áp dụng những nguyên tắc này, đo lường hiệu suất và hiểu mục tiêu của bạn.
Tác giả: zdw