Sự phát triển cơ sở dữ liệu của Nextdoor: Một nấc thang mở rộng
Nextdoor’s Database Evolution: A Scaling Ladder
Nextdoor vừa thực hiện một bước ngoặt quan trọng trong hạ tầng cơ sở dữ liệu khi chuyển đổi từ kiến trúc monolithic sang mô hình phân mảnh (partitioned) có khả năng mở rộng cao. Cụ thể, họ đã áp dụng hệ thống Vitess để xử lý lưu lượng ghi dữ liệu khổng lồ. Quá trình di chuyển này là yếu tố sống còn để giải quyết các nút thắt hiệu năng và rủi ro về độ tin cậy vốn tồn tại trong cấu trúc single-database ban đầu khi lượng dữ liệu người dùng tăng vọt. Đối với các lập trình viên, đây là bài học thực tế cho thấy kiến trúc hệ thống cần phải tiến hóa song hành với lưu lượng truy cập; việc tối ưu hóa sớm (early optimization) không quan trọng bằng việc xây dựng một hệ thống có tính module, cho phép thực hiện re-sharding hoặc phân tán dữ liệu khi nhu cầu thay đổi. Nhìn chung, sự chuyển dịch của Nextdoor minh chứng rằng việc lựa chọn chiến lược phân vùng hợp lý cùng các công cụ quản lý database chuyên dụng là chìa khóa để vừa duy trì tính toàn vẹn của dữ liệu, vừa đáp ứng tốt tốc độ tăng trưởng theo cấp số nhân.
Nextdoor hoạt động như một dịch vụ mạng xã hội siêu địa phương kết nối hàng xóm dựa trên vị trí địa lý của họ.
Nextdoor hoạt động như một dịch vụ mạng xã hội siêu địa phương (hyper-local), kết nối những người hàng xóm dựa trên vị trí địa lý của họ.
Nền tảng này cho phép mọi người chia sẻ tin tức địa phương, đề xuất các doanh nghiệp địa phương và tổ chức các sự kiện trong khu phố. Vì nền tảng dựa trên các tương tác có độ tin cậy cao trong các cộng đồng cụ thể, dữ liệu phải có tính sẵn sàng cao và cực kỳ chính xác.
Tuy nhiên, khi dịch vụ mở rộng ra hàng triệu người dùng trên khắp hàng nghìn khu phố trên toàn cầu, kiến trúc cơ sở dữ liệu cơ bản đã phải tiến hóa từ một thiết lập đơn giản thành một hệ thống phân tán phức tạp.
Hành trình kỹ thuật này tại Nextdoor nêu bật một quy tắc cơ bản trong thiết kế hệ thống.
Mỗi bước cải thiện hiệu suất đều tạo ra một yêu cầu mới về tính toàn vẹn của dữ liệu. Đội ngũ đã tuân theo một tiến trình có thể dự đoán được, chuyển từ một instance cơ sở dữ liệu duy nhất sang một hệ thống phân cấp phức tạp gồm các connection pooler, read replica, cache được đánh số phiên bản và các trình hòa giải (reconciler) chạy nền. Trong bài viết này, chúng ta sẽ xem xét cách đội ngũ kỹ thuật của Nextdoor đã xử lý sự tiến hóa này và những thách thức mà họ phải đối mặt.
Tuyên bố miễn trừ trách nhiệm: Bài viết này dựa trên các chi tiết được chia sẻ công khai từ Đội ngũ Kỹ thuật của Nextdoor. Vui lòng để lại bình luận nếu bạn nhận thấy bất kỳ điểm nào không chính xác.
Giới hạn của "Big Box"
Trong thời kỳ đầu, Nextdoor dựa vào một instance PostgreSQL duy nhất để xử lý mọi bài đăng, bình luận và cập nhật khu phố.
Đối với nhiều nền tảng đang phát triển, đây là điểm khởi đầu hợp lý nhất. Nó đơn giản để quản lý và PostgreSQL cung cấp một công cụ mạnh mẽ có khả năng xử lý khối lượng công việc đáng kể. Tuy nhiên, khi có nhiều hàng xóm tham gia hơn và khối lượng tương tác đồng thời tăng lên, đội ngũ đã gặp phải một bức tường không liên quan đến tổng lượng dữ liệu được lưu trữ, mà liên quan nhiều hơn đến giới hạn kết nối.
PostgreSQL sử dụng mô hình mỗi kết nối một tiến trình (process-per-connection). Nói cách khác, mỗi khi một application worker muốn giao tiếp với cơ sở dữ liệu, máy chủ sẽ tạo ra một tiến trình hoàn toàn mới để xử lý yêu cầu đó. Nếu một ứng dụng có năm nghìn web worker đang cố gắng truy cập cơ sở dữ liệu cùng lúc, máy chủ phải quản lý năm nghìn tiến trình riêng biệt. Mỗi tiến trình tiêu tốn một phần bộ nhớ và chu kỳ CPU chuyên biệt chỉ để duy trì sự tồn tại của nó.
Việc quản lý hàng nghìn tiến trình tạo ra một gánh nặng (overhead) khổng lồ cho hệ điều hành. Cuối cùng, máy chủ dành nhiều thời gian để chuyển đổi giữa các tiến trình này hơn là thực hiện các truy vấn thực tế giúp vận hành luồng tin tức khu vực (neighborhood feed). Đây thường là thời điểm mà việc mở rộng theo chiều dọc (vertical scaling), hay mua một máy chủ lớn hơn với nhiều nhân (core) hơn, bắt đầu cho thấy hiệu quả giảm dần. Gánh nặng từ mô hình “mỗi kết nối một tiến trình” vẫn là một nút thắt cổ chai bất kể bạn có thêm bao nhiêu phần cứng vào hệ thống.
Để giải quyết vấn đề này, Nextdoor đã giới thiệu một lớp middleware có tên là PgBouncer. Đây là một trình quản lý kết nối (connection pooler) nằm giữa ứng dụng và cơ sở dữ liệu. Thay vì mỗi application worker phải duy trì một đường truyền riêng biệt đến cơ sở dữ liệu, tất cả chúng đều giao tiếp với PgBouncer.
Giai đoạn Yêu cầu (The Request Phase): Một web worker yêu cầu một kết nối từ PgBouncer để thực thi một truy vấn nhanh.
Giai đoạn Phân bổ (The Assignment Phase): PgBouncer chỉ định một kết nối nhàn rỗi từ pool đã được thiết lập sẵn thay vì bắt buộc cơ sở dữ liệu phải tạo ra một tiến trình mới.
Giai đoạn Thực thi (The Execution Phase): Truy vấn chạy trên cơ sở dữ liệu bằng cách sử dụng kết nối được chia sẻ đó.
Giai đoạn Giải phóng (The Release Phase): Worker hoàn thành công việc của mình và kết nối quay trở lại pool ngay lập tức để worker tiếp theo sử dụng.
Điều này cho phép hàng nghìn application worker chia sẻ vài trăm kết nối cơ sở dữ liệu đang "ấm" (warm). Điều này đã loại bỏ hiệu quả nút thắt cổ chai về kết nối và cho phép cơ sở dữ liệu chính tập trung hoàn toàn vào việc xử lý dữ liệu.
Phân chia công việc và vấn đề về "Độ trễ" (Lag)
Sau khi việc quản lý kết nối đã ổn định, nút thắt tiếp theo xuất hiện dưới dạng lưu lượng truy cập đọc (read traffic).
Trong một mạng xã hội như Nextdoor, tỷ lệ người đọc tin tức so với người viết bài bị lệch rất lớn. Cứ mỗi người lưu một cập nhật khu vực mới, thì hàng trăm người khác có thể xem nó. Một máy chủ cơ sở dữ liệu duy nhất phải xử lý cả "Ghi" (Writes) và "Đọc" (Reads) cùng một lúc. Điều này tạo ra sự tranh chấp tài nguyên, nơi các truy vấn đọc nặng có thể làm chậm khả năng lưu dữ liệu mới của hệ thống.
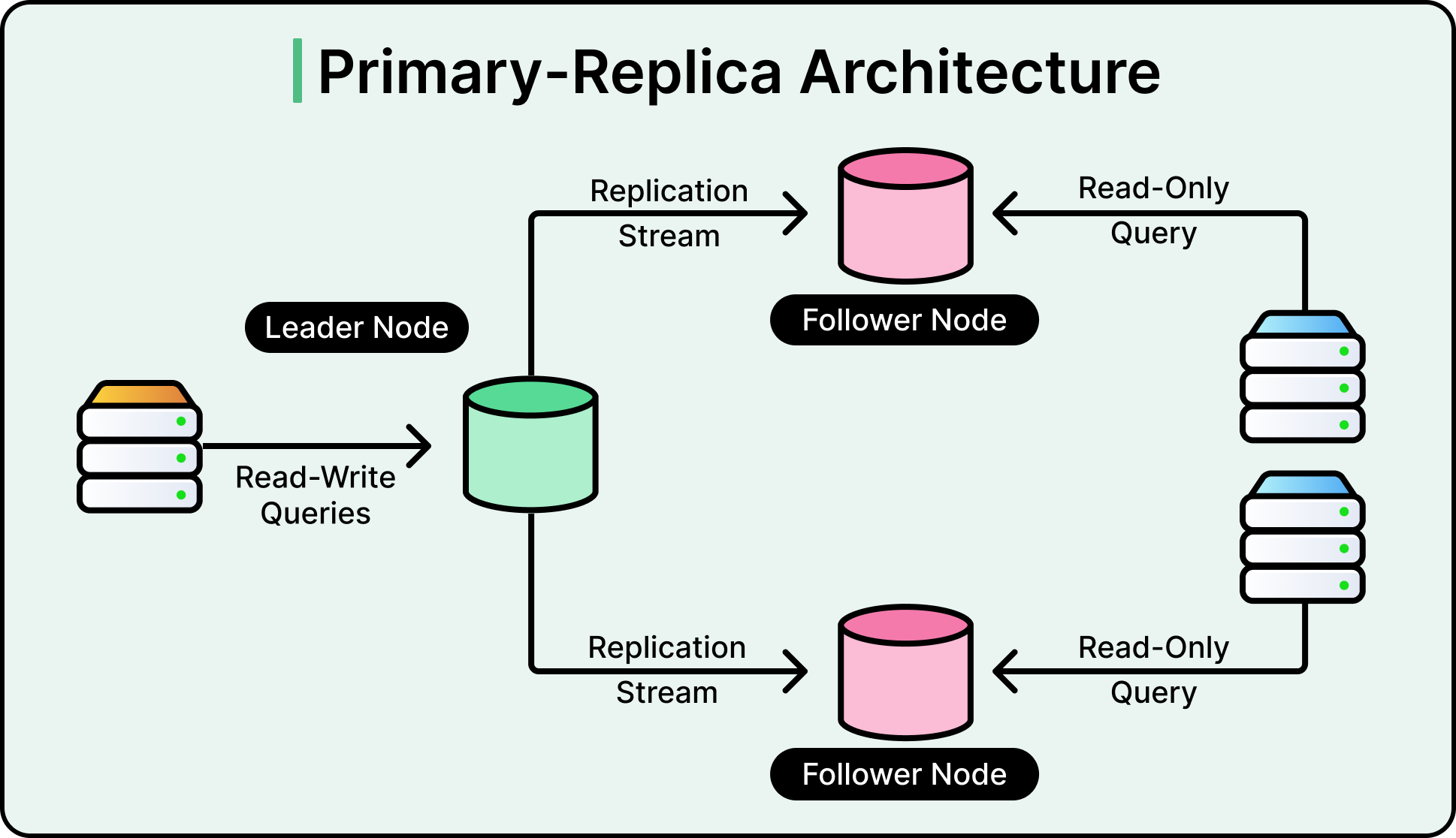
Giải pháp là chuyển sang kiến trúc Primary-Replica. Trong thiết lập này, một máy chủ cơ sở dữ liệu được chỉ định là Primary (Chính). Đây là máy chủ duy nhất được phép sửa đổi hoặc thay đổi dữ liệu. Một số máy chủ khác, được gọi là Read Replicas (Bản sao đọc), duy trì các bản sao dữ liệu từ Primary. Tất cả lưu lượng truy cập "Đọc" từ ứng dụng được chuyển hướng đến các bản sao này, trong khi chỉ có lưu lượng "Ghi" mới được gửi đến Primary.
Xem sơ đồ bên dưới:
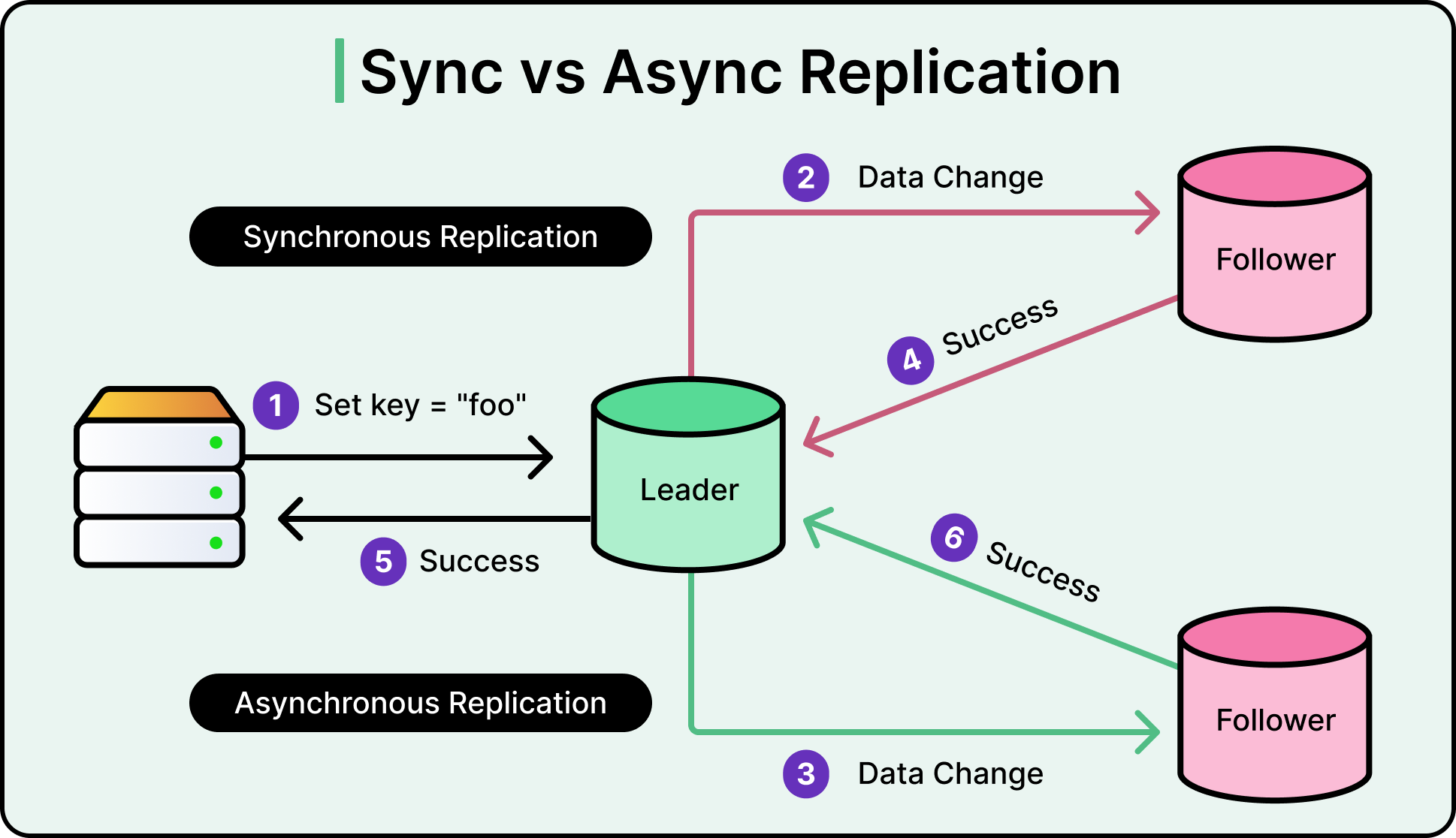
Việc phân tách công việc này cho phép mở rộng quy mô đọc theo chiều ngang (horizontal scaling) một cách mạnh mẽ. Tuy nhiên, điều này tạo ra thách thức về Asynchronous Replication (Sao chép bất đồng bộ). Cơ sở dữ liệu Primary sẽ gửi các thay đổi của nó đến các bản sao (replicas) bằng cách sử dụng luồng nhật ký (log stream). Cần một khoảng thời gian để bài đăng mới được lưu trên Primary truyền qua mạng và xuất hiện trên các replica. Độ trễ này được gọi là replication lag (độ trễ sao chép).
Xem sơ đồ dưới đây để thấy sự khác biệt giữa sao chép đồng bộ và bất đồng bộ:
Để giải quyết vấn đề người dùng đăng bài xong rồi thấy nó biến mất khi tải lại trang, Nextdoor sử dụng Time-Based Dynamic Routing (Định tuyến động dựa trên thời gian). Đây là một logic định tuyến thông minh đảm bảo người dùng luôn thấy kết quả từ các hành động của chính họ. Cơ chế hoạt động như sau:
The Write Marker (Dấu vết ghi): Khi người dùng thực hiện một hành động ghi, chẳng hạn như đăng một bình luận, ứng dụng sẽ ghi lại dấu thời gian chính xác của sự kiện đó.
The Protected Window (Cửa sổ được bảo vệ): Trong một khoảng thời gian cụ thể sau khi ghi, thường là vài giây, hệ thống sẽ coi người dùng đó là đối tượng nhạy cảm.
Dynamic Routing (Định tuyến động): Trong khoảng thời gian này, mọi yêu cầu đọc từ người dùng đó sẽ được định tuyến động trực tiếp đến cơ sở dữ liệu Primary thay vì replica.
The Handover (Chuyển giao): Khi cửa sổ thời gian kết thúc và hệ thống xác nhận rằng các replica đã cập nhật kịp với Primary, lưu lượng truy cập của người dùng sẽ được định tuyến lại về các replica để tiết kiệm tài nguyên.
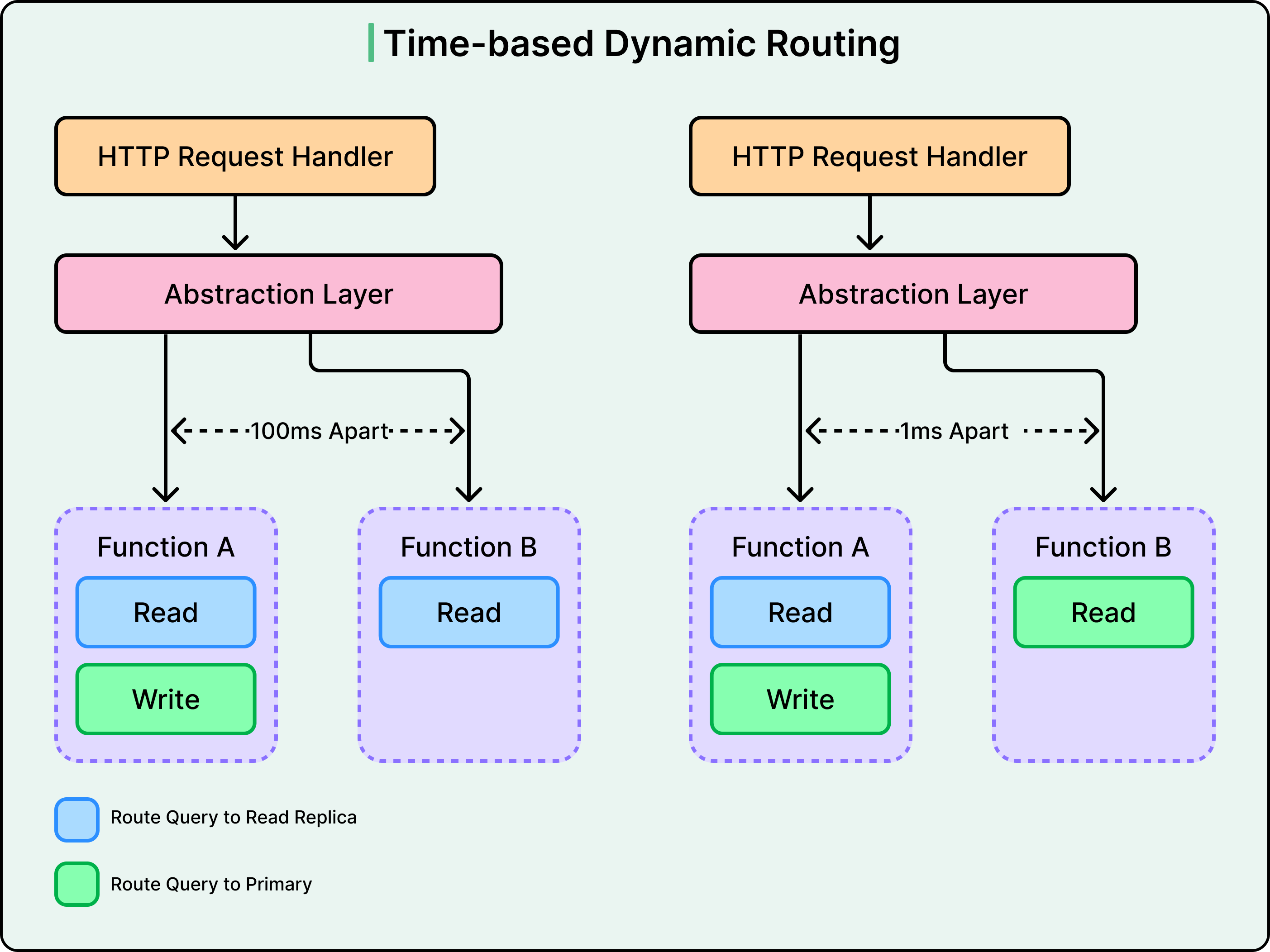
Điều này đảm bảo rằng trong khi những người dùng khác trong khu vực thấy dữ liệu nhất quán theo thời gian (eventually consistent), thì chính người đã thực hiện thay đổi đó luôn thấy dữ liệu nhất quán mạnh (strongly consistent).
Thư viện Tốc độ cao
Ngay cả khi có nhiều bản sao (replica), việc truy cập vào cơ sở dữ liệu cho mỗi lần tải trang là một hoạt động tốn kém.
Các cơ sở dữ liệu phải đọc dữ liệu từ ổ đĩa hoặc một bộ nhớ đệm lớn và thường thực hiện các lệnh join phức tạp giữa các bảng khác nhau để tập hợp thành một bản ghi duy nhất. Để đạt được tốc độ phản hồi tính bằng mili giây như người dùng mong đợi, Nextdoor đã triển khai một lớp cache sử dụng Valkey. Đây là một kho lưu trữ dữ liệu hiệu suất cao mã nguồn mở, lưu trữ thông tin trong RAM để truy cập gần như tức thời.
Đội ngũ này sử dụng mô hình Look-aside Cache. Khi ứng dụng cần dữ liệu, nó sẽ thực hiện theo một trình tự cụ thể:
Kiểm tra Cache: Ứng dụng tìm kiếm dữ liệu trong Valkey bằng một khóa (key) duy nhất.
Cache Hit: Nếu tìm thấy dữ liệu, nó được trả về ngay lập tức cho người dùng mà không cần chạm vào cơ sở dữ liệu.
Cache Miss: Nếu không có dữ liệu, ứng dụng sẽ truy vấn cơ sở dữ liệu PostgreSQL để tìm thông tin chính xác.
Bước Nạp dữ liệu: Ứng dụng lấy kết quả từ cơ sở dữ liệu, lưu một bản sao vào Valkey cho các yêu cầu trong tương lai, sau đó trả dữ liệu về cho người dùng.

Hiệu quả là yếu tố sống còn khi quản lý cache ở quy mô này. RAM đắt hơn nhiều so với lưu trữ trên ổ cứng, vì vậy dữ liệu phải được tối ưu dung lượng nhỏ nhất có thể.
Nextdoor sử dụng định dạng tuần tự hóa nhị phân có tên là MessagePack. Nói cách khác, thay vì lưu trữ dữ liệu dưới định dạng văn bản cồng kềnh như JSON, họ chuyển đổi nó thành định dạng nhị phân nén cao, giúp máy tính phân tích nhanh hơn nhiều.
MessagePack đặc biệt hữu ích với Nextdoor vì nó hỗ trợ lược đồ tiến hóa (schema evolution). Nếu đội ngũ kỹ thuật thêm một trường mới vào hồ sơ của hàng xóm, dữ liệu được cache cũ hơn vẫn có thể được đọc mà không làm ứng dụng bị treo. Đối với các mảng dữ liệu lớn hơn nữa, họ sử dụng phương pháp nén Zstd. Bằng cách kết hợp hai công cụ này, Nextdoor giảm đáng kể dung lượng bộ nhớ cho các máy chủ cache của mình.
Đánh số phiên bản và cập nhật nguyên tử (Atomic Updates)
Caching có thể tạo ra vấn đề nghiêm trọng khi nó bắt đầu cung cấp thông tin sai lệch trong một số tình huống cụ thể. Ví dụ, nếu cơ sở dữ liệu được cập nhật nhưng cache không được làm mới, người dùng có thể thấy thông tin cũ, không chính xác. Hầu hết các chiến lược caching đơn giản dựa vào "Time to Live" (TTL). Đây là một bộ hẹn giờ cho biết cache cần xóa một mục sau vài phút. Đối với một mạng xã hội thời gian thực, việc đợi vài phút để một bài đăng cập nhật không phải là giải pháp chấp nhận được.
Nextdoor đã xây dựng một công cụ đánh số phiên bản phức tạp để đảm bảo cache luôn được cập nhật. Họ thêm một cột đặc biệt có tên là system_version vào các bảng cơ sở dữ liệu và sử dụng PostgreSQL Triggers để quản lý con số này. Để tham khảo, trigger là một đoạn mã nhỏ tự động chạy bên trong cơ sở dữ liệu bất cứ khi nào một hàng dữ liệu được tác động. Mỗi khi một bài đăng được cập nhật, trigger sẽ tăng số phiên bản lên. Điều này đảm bảo cơ sở dữ liệu vẫn là nguồn sự thật cuối cùng về việc phiên bản nào của bài đăng là mới nhất.
Khi ứng dụng cố gắng cập nhật cache, nó không chỉ ghi đè lên dữ liệu cũ. Nó sử dụng một tập lệnh Lua được thực thi bên trong Valkey. Tập lệnh này thực hiện một thao tác "Compare and set" nguyên tử hoạt động như sau:
Lấy siêu dữ liệu: Tập lệnh truy xuất số phiên bản hiện được lưu trữ trong mục cache.
So sánh phiên bản: Nó so sánh phiên bản đó với số phiên bản của bản cập nhật mới đang được ứng dụng gửi tới.
Ghi có điều kiện: Nếu phiên bản mới lớn hơn hẳn phiên bản đã cache, bản cập nhật sẽ được lưu lại.
Từ chối: Nếu phiên bản đã cache đã bằng hoặc cao hơn bản cập nhật mới, tập lệnh sẽ từ chối hoàn toàn thay đổi đó.
Điều này ngăn chặn các "điều kiện đua" (race conditions). Hãy tưởng tượng hai máy chủ khác nhau cùng cố gắng cập nhật một bài đăng tại cùng một thời điểm. Nếu không có logic này, một bản cập nhật cũ hơn có thể đến sau đó một mili giây và ghi đè lên một bản cập nhật mới hơn. Điều này sẽ khiến cache vĩnh viễn không đồng bộ với cơ sở dữ liệu. Bằng cách sử dụng Lua, toàn bộ quá trình kiểm tra phiên bản và cập nhật dữ liệu diễn ra như một bước duy nhất, không thể phá vỡ và không bị gián đoạn.
CDC và đối soát dữ liệu (Reconciliation)
Ngay cả với việc đánh số phiên bản và các tập lệnh Lua, sai sót vẫn có thể xảy ra.
Một sự cố phân vùng mạng (network partition) có thể ngăn cản bản cập nhật cache đến được Valkey, hoặc một tiến trình ứng dụng có thể bị treo trước khi kịp hoàn thành bước điền dữ liệu. Nextdoor cần một mạng lưới an toàn cuối cùng để nắm bắt những sai lệch này. Họ đã triển khai Change Data Capture, hay còn gọi là CDC, bằng cách sử dụng một công cụ có tên là Debezium.
Xem sơ đồ bên dưới:
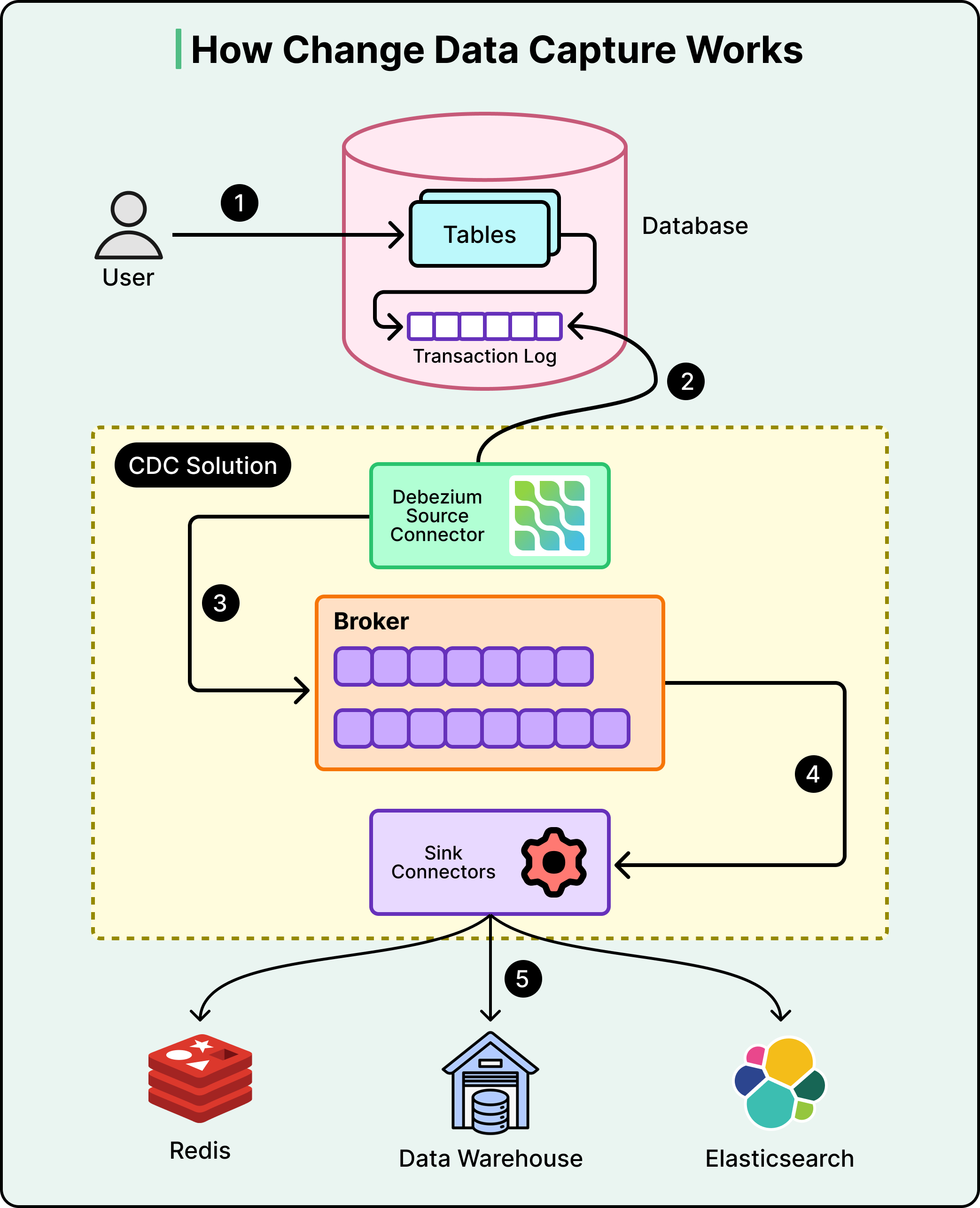
CDC hoạt động bằng cách "lắng nghe" các nhật ký nội bộ của cơ sở dữ liệu PostgreSQL. Cụ thể, nó theo dõi Write-Ahead Log, nơi mọi thay đổi đều được ghi lại trước khi được commit. Mỗi khi có thay đổi xảy ra trong cơ sở dữ liệu, Debezium sẽ nắm bắt sự kiện đó và biến nó thành một thông điệp trong luồng dữ liệu (data stream). Một dịch vụ nền được gọi là Reconciler sẽ theo dõi luồng này.
Quy trình đối soát (reconciliation flow) cung cấp một cơ chế "tự phục hồi" cho toàn bộ hệ thống:
Cập nhật cơ sở dữ liệu: Người dùng cập nhật tiểu sử khu phố của họ trong cơ sở dữ liệu PostgreSQL chính.
Nắm bắt nhật ký: Debezium phát hiện mục nhật ký mới và xuất bản một thông điệp sự kiện thay đổi.
Hành động của Reconciler: Dịch vụ nền nhận thông điệp này và xác định khóa cache nào cần được sửa chữa.
Vô hiệu hóa: Dịch vụ yêu cầu cache xóa mục cũ đi. Lần tới khi một người hàng xóm yêu cầu tiểu sử đó, ứng dụng sẽ gặp phải tình trạng "Cache Miss" và lấy dữ liệu hoàn toàn mới từ cơ sở dữ liệu.
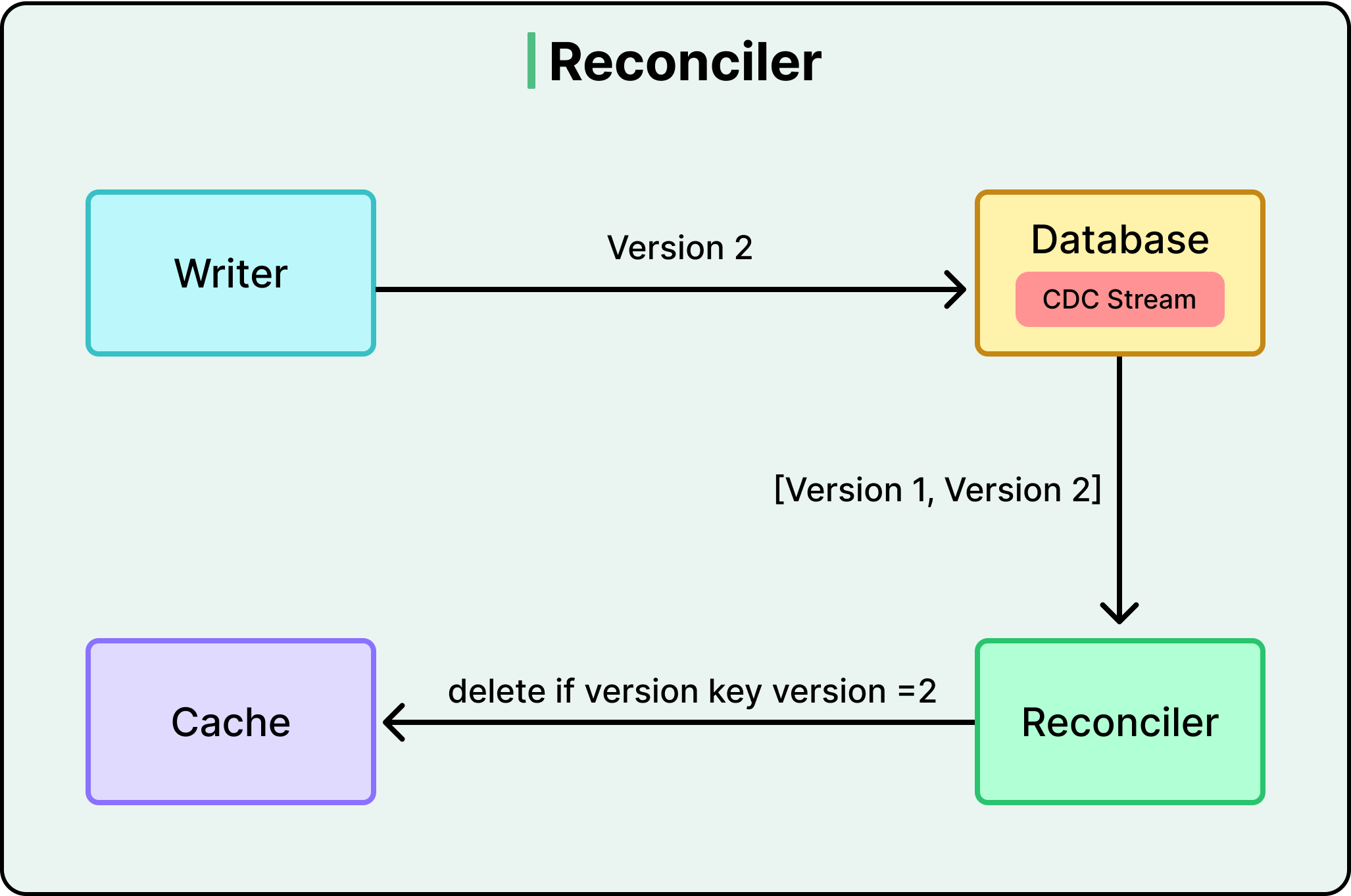
Quy trình này cung cấp tính nhất quán cuối cùng (eventual consistency). Mặc dù việc cập nhật cache chính có thể thất bại trong một phần giây, CDC Reconciler cuối cùng sẽ phát hiện ra sự thay đổi và sửa lỗi cho cache. Nó hoạt động giống như một thám tử liên tục kiểm tra hệ thống để đảm bảo rằng "sự thật nhanh" trong cache khớp với "sự thật chính xác" trong cơ sở dữ liệu.
Phân mảnh (Sharding)
Sẽ đến một thời điểm mà ngay cả cơ sở dữ liệu Primary được tối ưu hóa tốt nhất cũng không thể xử lý khối lượng ghi dữ liệu đầu vào. Khi một nền tảng xử lý hàng tỷ dòng dữ liệu, bản thân phần cứng sẽ đạt đến giới hạn vật lý. Đây là lúc Nextdoor chuyển sang nấc thang cuối cùng. Nấc thang này chính là Sharding.
Sharding là quá trình chia nhỏ một bảng dữ liệu khổng lồ thành các phần nhỏ hơn và phân tán chúng trên các cụm cơ sở dữ liệu hoàn toàn khác nhau. Nextdoor thường thực hiện sharding dữ liệu theo một định danh duy nhất, chẳng hạn như ID Khu dân cư (Neighborhood ID).
Tách cụm (The Cluster Split): Tất cả dữ liệu cho các Khu dân cư từ 1 đến 500 có thể nằm trên Cụm A, trong khi các Khu dân cư từ 501 đến 1.000 nằm trên Cụm B.
Khóa Shard (The Shard Key): Ứng dụng sử dụng neighborhood_id để biết chính xác cụm cơ sở dữ liệu nào cần truy vấn cho bất kỳ yêu cầu nào.
Sharding cho phép khả năng mở rộng lớn hơn nhiều vì chúng ta có thể tiếp tục thêm nhiều cụm hơn dựa trên sự phát triển. Tuy nhiên, nó đi kèm với cái giá rất đắt về độ phức tạp. Một khi đã shard cơ sở dữ liệu, chúng ta không còn có thể dễ dàng thực hiện lệnh "Join" giữa các dữ liệu nằm trên hai shard khác nhau.
Kết luận
Hành trình cơ sở dữ liệu của Nextdoor cho thấy kỹ thuật tuyệt vời hiếm khi là việc chọn công cụ phức tạp nhất ngay từ đầu. Đó là một quá trình tiến triển có kỷ luật.
Họ bắt đầu với một máy chủ duy nhất và thêm connection pooling khi hàng đợi trở nên quá dài. Họ thêm các bản sao (replica) khi lưu lượng đọc trở nên quá tải. Cuối cùng, họ xây dựng một hệ thống cache có đánh phiên bản đẳng cấp thế giới để cung cấp tốc độ mà người dùng mong đợi mà không phải đánh đổi độ chính xác cần thiết.
Bài học rút ra là sự phức tạp phải được đánh đổi. Mỗi lớp trong thang đo mở rộng giải quyết một vấn đề nhưng lại tạo ra một thách thức mới trong tính nhất quán của dữ liệu. Bằng cách xây dựng các mạng lưới an toàn mạnh mẽ như lập phiên bản (versioning) và đối chiếu (reconciliation), đội ngũ kỹ thuật của Nextdoor đã đảm bảo rằng hệ thống của họ có thể phát triển mà không làm mất đi niềm tin của cộng đồng mà họ phục vụ.
Tài liệu tham khảo:
Tác giả: ByteByteGo