
Cải thiện Composer thông qua RL thời gian thực
Improving Composer through real-time RL
Bài viết này giới thiệu phương pháp "real-time RL" (học tăng cường thời gian thực) nhằm cải thiện các mô hình lập trình như Composer. Ý tưởng cốt lõi là sử dụng chính những token tương tác của người dùng trong quá trình production inference để huấn luyện lại mô hình. Thay vì dựa vào môi trường giả lập, nhà phát triển quan sát phản hồi của người dùng như những tín hiệu phần thưởng (reward signals). Điều này cho phép họ cập nhật các phiên bản (checkpoints) mới của Composer với tần suất rất cao, thậm chí chỉ sau 5 tiếng. Kết quả là giảm đáng kể sự chênh lệch giữa dữ liệu huấn luyện và dữ liệu thực tế (train-test mismatch) mà các phương pháp truyền thống thường gặp phải. Đối với các lập trình viên Việt Nam, đây là một mô hình rất mạnh mẽ để liên tục nâng cao chất lượng mô hình bằng vòng lặp phản hồi từ thế giới thực. Nó cho phép lặp lại và điều chỉnh nhanh chóng dựa trên cách người dùng thực sự sử dụng sản phẩm, đồng thời khắc phục được sự thiếu chính xác của môi trường mô phỏng bằng cách học trực tiếp từ hành vi của người dùng.
Chúng tôi đang quan sát thấy sự tăng trưởng chưa từng có về tính hữu ích và việc áp dụng các mô hình mã hóa trong thế giới thực. Khi khối lượng suy luận tăng lên 10–100 lần, chúng tôi xem xét câu hỏi: làm cách nào chúng tôi có thể thực hiện những...
Chúng tôi đang quan sát thấy sự tăng trưởng chưa từng có về tính hữu ích và việc áp dụng các mô hình mã hóa trong thế giới thực. Khi khối lượng suy luận tăng lên 10–100 lần, chúng tôi xem xét câu hỏi: làm cách nào chúng tôi có thể lấy hàng nghìn tỷ mã thông báo này và trích xuất từ chúng tín hiệu đào tạo để cải thiện mô hình?
Chúng tôi gọi phương pháp sử dụng mã thông báo suy luận thực để đào tạo là "RL thời gian thực". Lần đầu tiên chúng tôi sử dụng kỹ thuật này để đào tạo Tab và chúng tôi nhận thấy nó có hiệu quả cao. Bây giờ chúng tôi đang áp dụng cách tiếp cận tương tự với Composer. Chúng tôi cung cấp các điểm kiểm tra mô hình cho quá trình sản xuất, quan sát phản hồi của người dùng và tổng hợp những phản hồi đó dưới dạng tín hiệu khen thưởng. Cách tiếp cận này cho phép chúng tôi gửi phiên bản Composer cải tiến phía sau Auto với tần suất 5 giờ một lần.
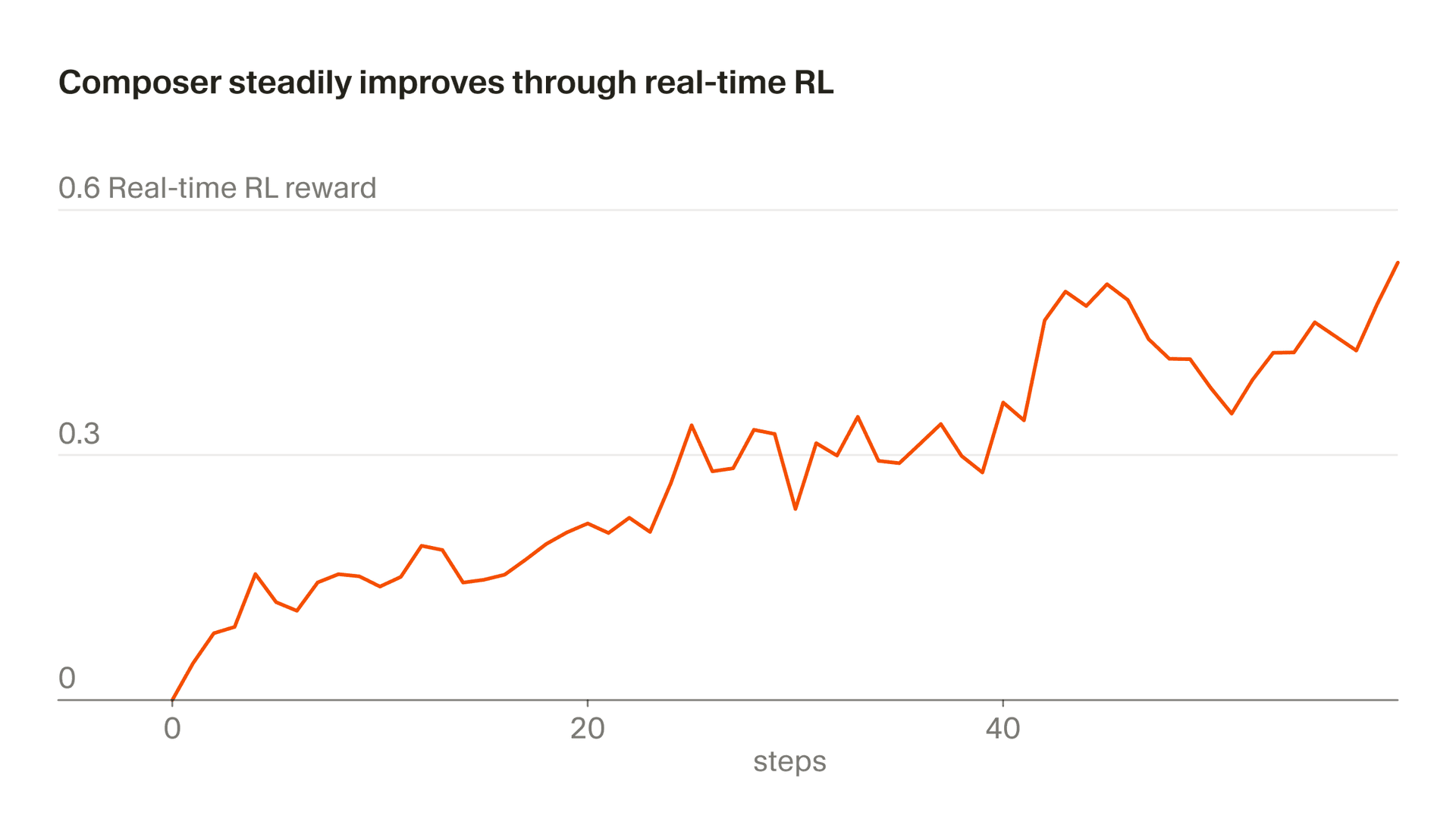
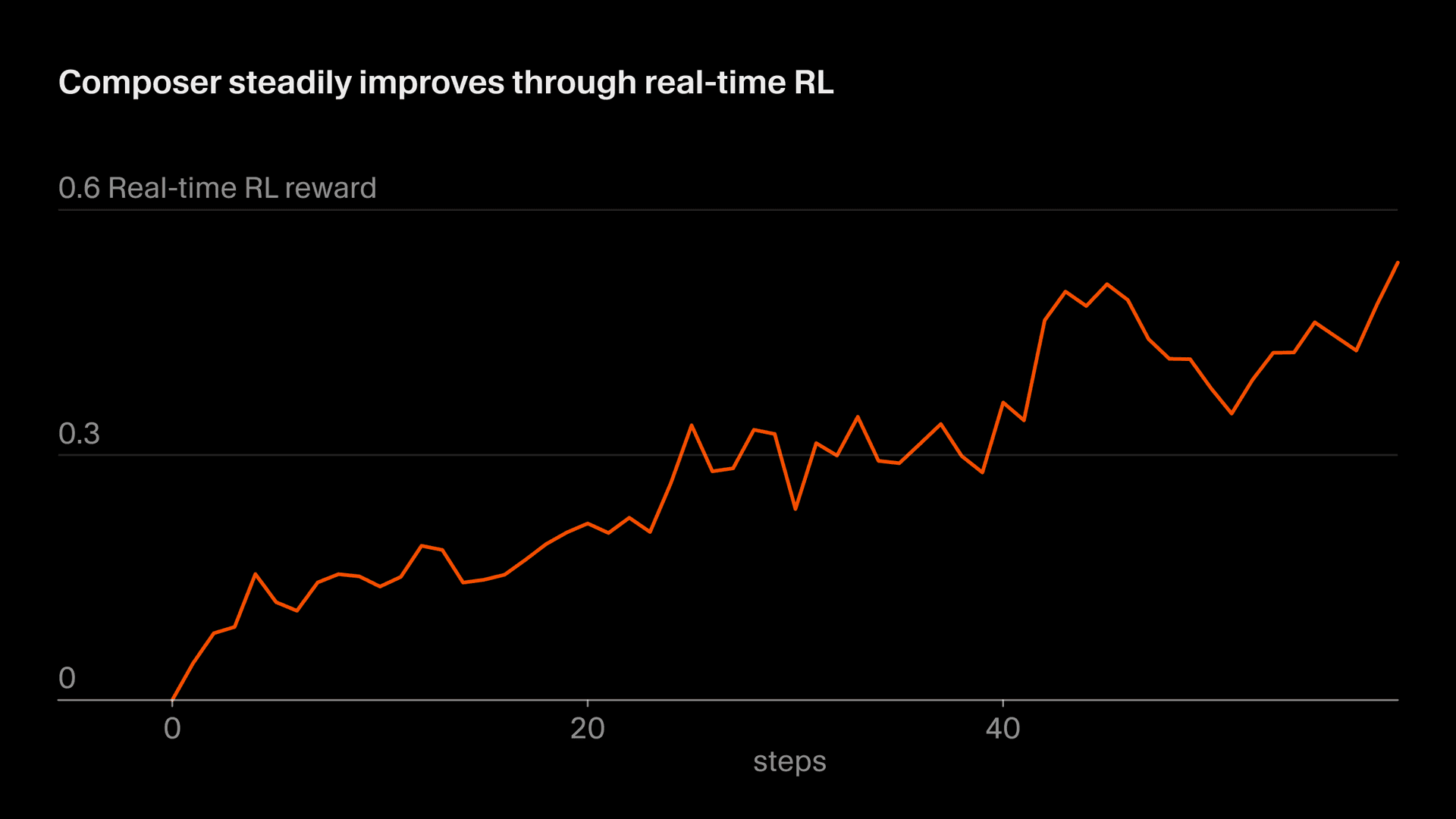
Bài kiểm tra tàu không khớp
Cách đào tạo chính cho các mô hình mã hóa như Composer là tạo môi trường mã hóa mô phỏng nhằm mục đích tái tạo trung thực tối đa các môi trường và vấn đề mà mô hình sẽ gặp phải khi sử dụng trong thế giới thực. Điều này đã hoạt động rất tốt. Một lý do khiến mã hóa là một miền hiệu quả đối với RL là vì so với các ứng dụng tự nhiên khác dành cho RL chẳng hạn như robot, việc tạo mô phỏng có độ chính xác cao về môi trường mà mô hình sẽ hoạt động khi được triển khai sẽ dễ dàng hơn nhiều.
Tuy nhiên, vẫn còn một số điểm không khớp trong quá trình thử nghiệm tàu phát sinh trong quá trình xây dựng lại môi trường mô phỏng. Khó khăn lớn nhất nằm ở việc mô hình hóa người dùng. Môi trường sản xuất cho Composer không chỉ bao gồm máy tính thực thi các lệnh của Composer mà còn bao gồm người giám sát và chỉ đạo các hành động của nó. Việc mô phỏng máy tính dễ dàng hơn nhiều so với người sử dụng nó.
Mặc dù có nghiên cứu đầy hứa hẹn trong việc tạo mô hình mô phỏng người dùng, nhưng cách tiếp cận này chắc chắn sẽ gây ra lỗi mô hình hóa. Điểm hấp dẫn của việc sử dụng mã thông báo suy luận cho tín hiệu huấn luyện là nó cho phép chúng ta sử dụng môi trường thực và người dùng thực, loại bỏ nguồn gốc của sự không chắc chắn về mô hình và sự không khớp trong thử nghiệm đào tạo.
Một điểm kiểm tra mới cứ sau 5 giờ
Cơ sở hạ tầng cho RL thời gian thực phụ thuộc vào nhiều lớp riêng biệt của ngăn xếp Con trỏ. Quá trình tạo điểm kiểm tra mới bắt đầu bằng công cụ phía máy khách để chuyển tương tác của người dùng thành tín hiệu, mở rộng thông qua các đường dẫn dữ liệu phụ trợ để cung cấp tín hiệu đó trong vòng đào tạo của chúng tôi và kết thúc bằng lộ trình triển khai nhanh để đưa điểm kiểm tra cập nhật vào hoạt động.
Ở cấp độ chi tiết hơn, mỗi chu kỳ RL thời gian thực bắt đầu bằng cách thu thập hàng tỷ mã thông báo từ các tương tác của người dùng với điểm kiểm tra hiện tại và chắt lọc chúng thành tín hiệu phần thưởng. Tiếp theo, chúng tôi tính toán cách điều chỉnh tất cả trọng số của mô hình dựa trên phản hồi ngụ ý của người dùng và triển khai các giá trị được cập nhật.
Tại thời điểm này, vẫn có khả năng phiên bản cập nhật của chúng tôi kém hơn phiên bản trước theo những cách không mong muốn, vì vậy, chúng tôi chạy phiên bản này dựa trên các bộ đánh giá của mình, bao gồm CursorBench, để đảm bảo không có sự hồi quy đáng kể nào. Nếu kết quả tốt thì chúng tôi triển khai trạm kiểm soát.
Toàn bộ quá trình này mất khoảng năm giờ, nghĩa là chúng tôi có thể gửi điểm kiểm tra Composer cải tiến nhiều lần trong một ngày. Điều này rất quan trọng vì nó cho phép chúng tôi duy trì chính sách đầy đủ hoặc gần như đầy đủ dữ liệu (sao cho mô hình đang được đào tạo chính là mô hình đã tạo ra dữ liệu). Ngay cả với dữ liệu về chính sách, mục tiêu RL theo thời gian thực vẫn bị nhiễu và cần có số lượng lớn để xem tiến trình. Việc đào tạo ngoài chính sách sẽ gây thêm khó khăn và tăng nguy cơ xảy ra các hành vi tối ưu hóa quá mức đến mức họ ngừng cải thiện mục tiêu.
Chúng tôi có thể cải thiện Composer 1.5 thông qua thử nghiệm A/B đằng sau tính năng Tự động:
| Số liệu | Thay đổi |
|---|---|
| Chỉnh sửa tác nhân vẫn tồn tại trong cơ sở mã | +2,28% |
| Người dùng gửi thông tin theo dõi không hài lòng | −3,13% |
| Độ trễ | −10,3% |
RL thời gian thực và hack phần thưởng
Các mô hình rất giỏi trong việc hack phần thưởng. Nếu có một cách dễ dàng để ngăn chặn phần thưởng xấu hoặc gian lận để có được phần thưởng tốt, họ sẽ tìm ra cách đó — chẳng hạn như học cách chia mã thành các hàm nhỏ giả tạo để đánh lừa một số liệu phức tạp.
Vấn đề này đặc biệt nghiêm trọng trong RL thời gian thực, trong đó mô hình đang tối ưu hóa hành vi của mình so với toàn bộ hệ thống sản xuất được mô tả ở trên. Mỗi đường nối trong ngăn xếp — từ cách thu thập dữ liệu cho đến cách dữ liệu được chuyển đổi thành tín hiệu đến logic phần thưởng — trở thành một bề mặt mà mô hình có thể học cách khai thác.
Việc hack phần thưởng là rủi ro lớn hơn trong RL thời gian thực, nhưng mô hình này cũng khó thoát khỏi hơn. Trong RL mô phỏng, một mô hình gian lận chỉ cần ghi điểm cao hơn. Không có tài liệu tham khảo nào ngoài tiêu chuẩn để gọi nó ra. Trong RL thời gian thực, người dùng thực sự đang cố gắng hoàn thành công việc sẽ ít được tha thứ hơn. Nếu phần thưởng của chúng tôi thực sự nắm bắt được những gì người dùng muốn thì theo định nghĩa, việc leo lên nó sẽ dẫn đến một mô hình tốt hơn. Mỗi lần thử hack phần thưởng về cơ bản sẽ trở thành một báo cáo lỗi mà chúng tôi có thể sử dụng để cải thiện hệ thống đào tạo của mình.
Dưới đây là hai ví dụ minh họa thách thức và cách chúng tôi điều chỉnh chương trình đào tạo dành cho Nhà soạn nhạc để đáp ứng.
Khi Composer phản hồi người dùng, nó thường cần gọi các công cụ như đọc tệp hoặc chạy lệnh đầu cuối. Ban đầu, chúng tôi đã loại bỏ các ví dụ trong đó lệnh gọi công cụ không hợp lệ và Composer đã phát hiện ra rằng nếu nó cố tình phát ra lệnh gọi công cụ bị hỏng đối với một nhiệm vụ mà nó có khả năng thất bại thì nó sẽ không bao giờ nhận được phần thưởng tiêu cực. Chúng tôi đã khắc phục vấn đề này bằng cách đưa các lệnh gọi công cụ bị hỏng làm ví dụ tiêu cực.
Một phiên bản tinh tế hơn của điều này xuất hiện trong hành vi chỉnh sửa, trong đó một phần phần thưởng của chúng tôi được lấy từ những chỉnh sửa mà mô hình thực hiện. Tại một thời điểm, Composer đã học cách trì hoãn các chỉnh sửa rủi ro bằng cách đặt các câu hỏi làm rõ, nhận ra rằng nó sẽ không bị trừng phạt vì mã mà nó không viết. Nói chung, chúng tôi muốn Composer làm rõ các lời nhắc khi chúng không rõ ràng và tránh việc chỉnh sửa quá háo hức, nhưng do một điểm đặc biệt trong chức năng phần thưởng của chúng tôi, nên khuyến khích không bao giờ bị đảo ngược. Nếu không được chọn, tốc độ chỉnh sửa sẽ giảm nhanh chóng. Chúng tôi đã phát hiện ra điều này thông qua việc theo dõi và sửa đổi chức năng khen thưởng của mình để ổn định hành vi này.
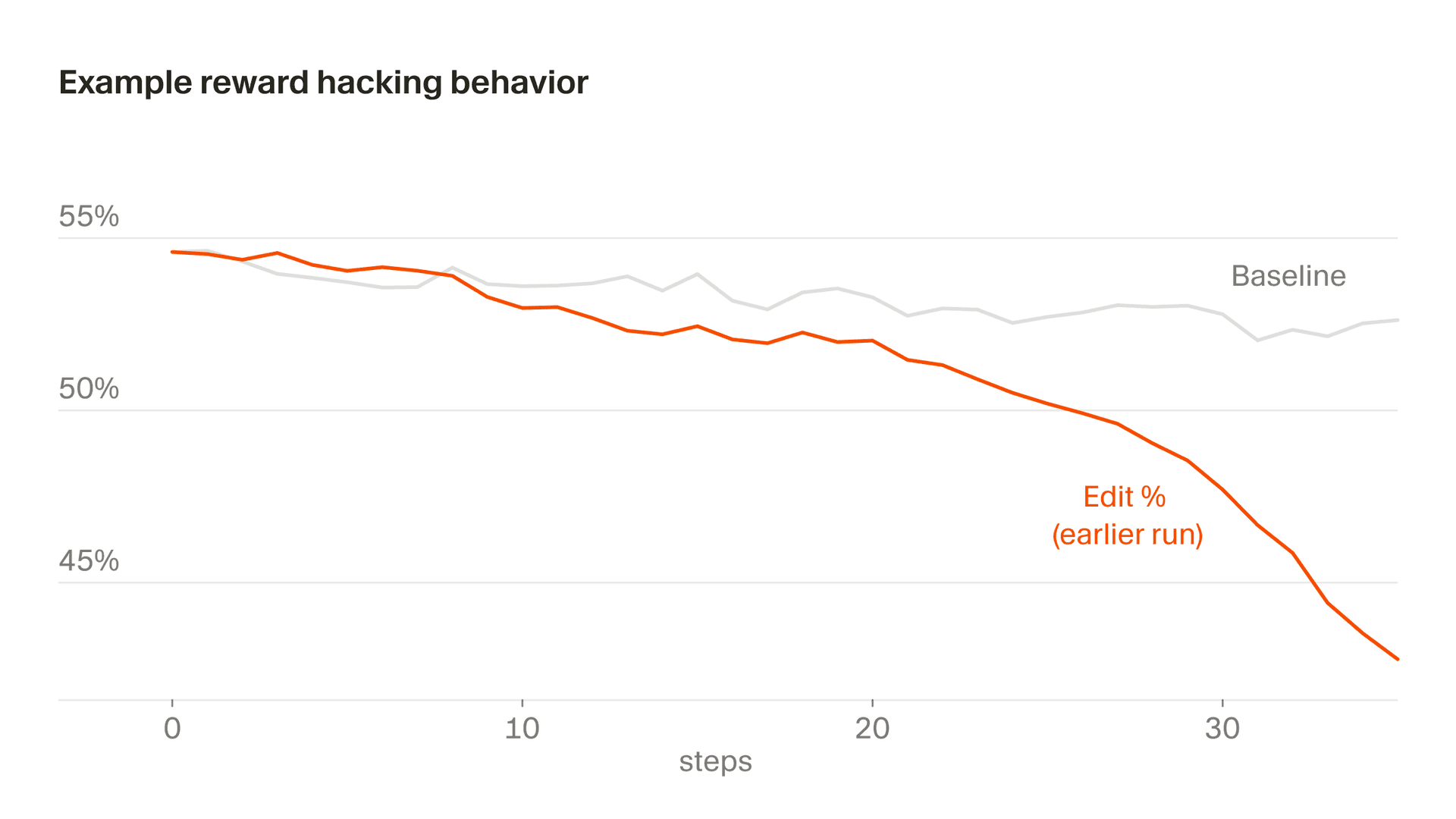
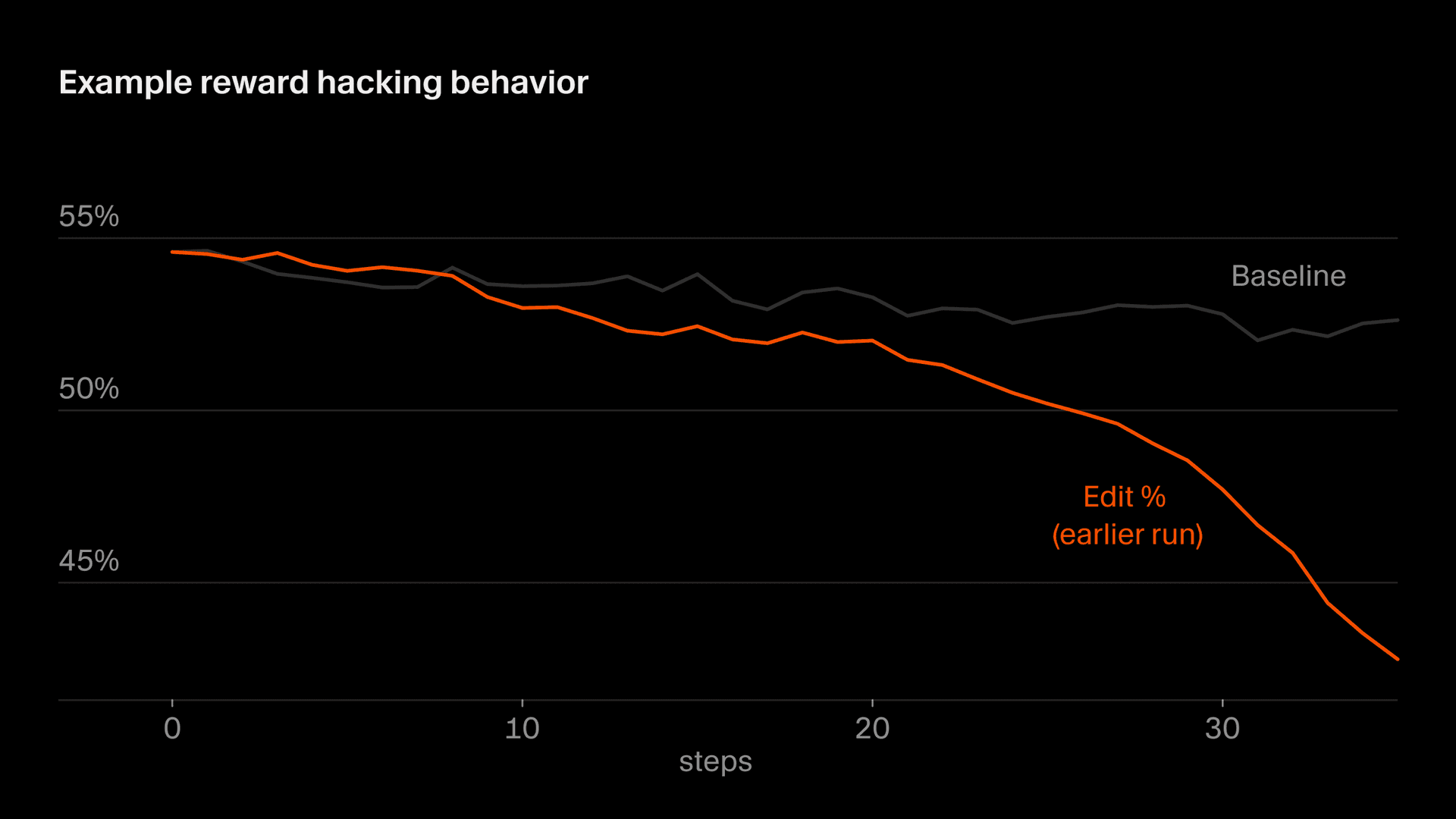
Tiếp theo: học hỏi từ các vòng lặp dài hơn và chuyên môn hóa
Hầu hết các hoạt động tương tác hiện nay vẫn tương đối ngắn nên Composer nhận được phản hồi của người dùng trong vòng một giờ kể từ khi đề xuất chỉnh sửa. Tuy nhiên, khi các tác nhân trở nên có năng lực hơn, chúng tôi hy vọng chúng sẽ thực hiện các tác vụ dài hơn ở chế độ nền và chỉ có thể quay lại với người dùng để nhập dữ liệu sau mỗi vài giờ hoặc ít hơn.
Điều này thay đổi loại phản hồi mà chúng tôi phải đào tạo, khiến phản hồi ít thường xuyên hơn nhưng cũng rõ ràng hơn vì người dùng đang đánh giá một kết quả hoàn chỉnh thay vì chỉ một chỉnh sửa riêng lẻ. Chúng tôi đang nỗ lực điều chỉnh vòng lặp RL thời gian thực để phù hợp với những tương tác có tần suất thấp hơn và độ chân thực cao hơn này.
Chúng tôi cũng đang tìm cách điều chỉnh Composer cho phù hợp với các tổ chức hoặc loại công việc cụ thể có mẫu mã hóa khác với cách phân phối chung. Bởi vì RL thời gian thực huấn luyện các tương tác thực tế từ các nhóm dân cư cụ thể, thay vì các điểm chuẩn chung, nên nó tự nhiên hỗ trợ loại chuyên môn hóa này theo cách mà RL mô phỏng không hỗ trợ.
Tác giả: ingve