Meta đã biến việc gỡ lỗi thành sản phẩm như thế nào
How Meta Turned Debugging Into a Product
Meta vừa biến một bài toán "khó nhằn" là debug các AI agent có tính không xác định (non-deterministic) thành một sản phẩm. Điều này cực kỳ quan trọng, bởi lẽ các công cụ sinh code AI hiện tại dù nhập input giống hệt nhau vẫn cho ra output khác nhau. Hậu quả là đa số các đội nhóm phải release AI agent mà chưa kiểm thử kỹ lưỡng. Các lập trình viên Việt Nam nên nhận thức rõ những khó khăn cố hữu trong việc testing AI agent và cân nhắc áp dụng các chiến lược hoặc công cụ để giải quyết vấn đề non-determinism này, nhằm đảm bảo chất lượng code được sinh ra bởi AI.
Trong bài viết này, chúng ta sẽ xem xét cách DrP hoạt động ở cấp độ cao và các lựa chọn thiết kế mà Meta đưa ra trong khi xây dựng nó.
Đầu vào giống nhau. Lời nhắc giống nhau. Đầu ra khác nhau. Đó là thực tế khi thử nghiệm các AI agent viết mã, và hầu hết các nhóm đang vận hành mà không giải quyết được vấn đề này.
Nick Nisi từ WorkOS đã giải quyết điều này bằng cách xây dựng các hệ thống đánh giá (eval systems) cho hai công cụ AI:
npx workos, một agent CLI cài đặt AuthKit vào dự án của bạn
Các kỹ năng của agent WorkOS cung cấp phản hồi LLM về SSO, đồng bộ hóa thư mục và RBAC.
Bài viết đề cập đến cách kiểm tra dựa trên cấu trúc dự án thực tế, chấm điểm đầu ra khác nhau mỗi lần, và phát hiện khi agent của bạn tạo ra các phương thức không tồn tại.
Mọi tổ chức kỹ thuật đang phát triển cuối cùng đều phát hiện ra vấn đề giống nhau. Khi có sự cố xảy ra trong production, các kỹ sư sẽ gỡ lỗi. Khi nó xảy ra lần nữa, họ lại gỡ lỗi. Hàng trăm nhóm, hàng nghìn sự cố, mỗi sự cố được điều tra gần như từ đầu.
Kỹ sư có kinh nghiệm biết phải tìm ở đâu và những mẫu nào cần kiểm tra, nhưng kiến thức đó nằm trong đầu họ, không phải trong hệ thống. Theo thời gian, các runbook trở nên lỗi thời, và các script mà một người nào đó viết trở thành kiến thức "bộ lạc" (tribal knowledge).
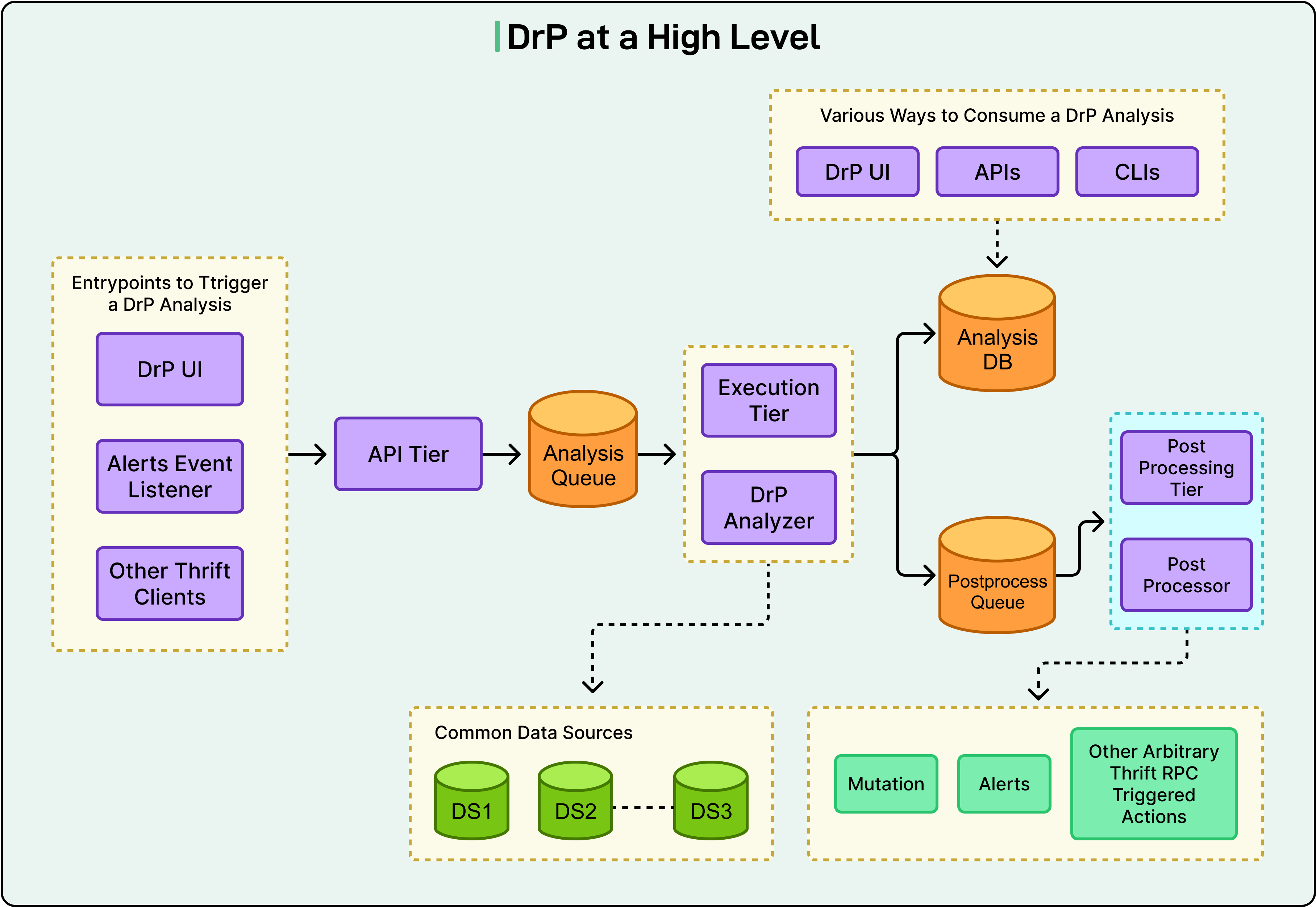
Meta đã gặp phải rào cản này từ nhiều năm trước. Câu trả lời của họ là DrP, một nền tảng cho phép các kỹ sư biến kiến thức chuyên môn về điều tra thành mã thực tế. Nó là một thành phần phần mềm chạy tự động, được kiểm tra thông qua review mã và cải thiện theo thời gian. Hiện tại, nó đang hoạt động trên 300 nhóm và thực hiện 50.000 phân tích tự động hàng ngày.
Mặc dù công cụ cụ thể của Meta rất thú vị để tìm hiểu, nhưng điều đáng chú ý hơn nữa là nguyên tắc cơ bản rằng bản thân việc gỡ lỗi có thể được thiết kế như một quy trình kỹ thuật. Trong bài viết này, chúng ta sẽ xem xét cách DrP hoạt động ở cấp độ cao và các lựa chọn thiết kế mà Meta đã đưa ra khi xây dựng nó.
Tuyên bố miễn trừ trách nhiệm: Bài viết này dựa trên các chi tiết được chia sẻ công khai từ Đội ngũ Kỹ thuật của Meta. Vui lòng bình luận nếu bạn nhận thấy bất kỳ điểm không chính xác nào.
Tại sao Điều tra Thủ công Lại Thất bại
Cách hầu hết các nhóm điều tra sự cố có một mô hình thất bại có thể dự đoán được, và việc viết tài liệu tốt hơn cũng không khắc phục được.
Kiến thức bị mắc kẹt trong con người. Người gỡ lỗi giỏi nhất của bạn mang theo các mô hình tư duy mà không ai khác có, chẳng hạn như dịch vụ nào hay gặp sự cố, chỉ số nào thực sự quan trọng và bảng điều khiển nào hiển thị sai trong các điều kiện nhất định. Khi người đó ngủ, đi nghỉ hoặc rời công ty, kiến thức đó sẽ biến mất. Nếu bạn đã từng bị đánh thức lúc 2 giờ sáng và ước gì ai đó đã giải quyết vấn đề này vào lần trước khi nó xảy ra, bạn đã cảm nhận được vấn đề này.
Các hệ thống thay đổi thường xuyên, đôi khi hàng chục lần mỗi ngày. Runbook đã chính xác vào tháng trước giờ đây tham chiếu đến một bảng điều khiển đã được đổi tên và một dịch vụ đã được tái cấu trúc. Phần mềm hiện đại phát triển quá nhanh để tài liệu tĩnh có thể theo kịp.
Các nhóm thường viết các script tùy chỉnh để tự động hóa các kiểm tra của riêng họ, và đó là một điều tốt. Nhưng các script đó không thể vượt qua ranh giới dịch vụ. Chúng cũng không được kiểm tra một cách có hệ thống. Cuối cùng, chúng trở thành một dạng kiến thức "bộ lạc" của riêng chúng, hữu ích cho tác giả và khó hiểu đối với những người khác.
Những vấn đề này không chỉ riêng Meta. Mọi tổ chức ở một quy mô nhất định đều gặp phải rào cản tương tự. Ngành công nghiệp đã tiếp cận nó theo những cách khác nhau. Một số công ty tập trung vào việc điều phối mọi người tốt hơn trong các sự cố (Netflix đã xây dựng và mã nguồn mở Dispatch cho mục đích này), những công ty khác tập trung vào tự động hóa quá trình điều tra (phương pháp của Meta), và những công ty khác lại dựa vào chẩn đoán do AI điều khiển.
Có ít nhất ba cấp độ riêng biệt cho việc phản ứng sự cố:
Phối hợp (tập hợp đúng người)
Điều tra (tìm hiểu điều gì đã sai)
Khắc phục (sửa chữa nó).
Meta đã đầu tư sâu nhất vào lớp điều tra, và cách tiếp cận của họ đáng để nghiên cứu vì nó đã được áp dụng trong production hơn năm năm ở quy mô lớn.
Bạn cũng có thể xem xét điều này như một sự tiến bộ về mức độ trưởng thành từ kiến thức "bộ lạc" sang runbook trên wiki, sang script tùy chỉnh, sang các trình phân tích có thể kiểm tra được và cuối cùng là một nền tảng có thể kết hợp. Hầu hết các nhóm bị kẹt ở bước hai hoặc ba, trong khi DrP đại diện cho bước năm.
4 quy trình kỹ thuật mà các AI agent có thể đóng góp nhiều hơn (Được tài trợ)

AI đã thay đổi cách kỹ sư viết code. Nhưng 70% thời gian kỹ thuật không phải là viết code, mà là chạy code.
Hầu hết các nhóm vẫn hoạt động thủ công để phân loại cảnh báo, điều tra sự cố, gỡ lỗi hệ thống và triển khai với ngữ cảnh sản xuất đầy đủ.
Một làn sóng các tổ chức kỹ thuật mới bao gồm cả những tổ chức tại Coinbase, Zscaler và DoorDash đang triển khai các agent AI dành riêng cho các hệ thống sản xuất của họ.
Hướng dẫn thực tế này bao gồm bốn quy trình làm việc mà các nhóm hàng đầu đang thấy có tác động đo lường được, và sự chuyển giao giữa người và agent thực sự trông như thế nào trong mỗi quy trình.
Xem xét điều tra như một phần mềm
Triết lý cốt lõi của DrP là các quy trình điều tra nên được viết thành code, trải qua quá trình xem xét code, có CI/CD và được kiểm thử, giống như bất kỳ phần mềm nào khác mà nhóm triển khai.
Đơn vị cốt lõi là "analyzer", một quy trình điều tra theo chương trình. Các kỹ sư sử dụng SDK của DrP để mã hóa các bước gỡ lỗi của họ, chẳng hạn như dữ liệu nào cần lấy, những bất thường nào cần tìm và cây quyết định nào cần tuân theo. Đầu ra là các kết quả được cấu trúc (cả dạng con người đọc được và máy đọc được) chứ không chỉ là một trang wiki mà ai đó có thể lướt qua.
Điều này khác với việc “chỉ viết một script” ở chỗ nó có sự chặt chẽ về kỹ thuật xung quanh nó.
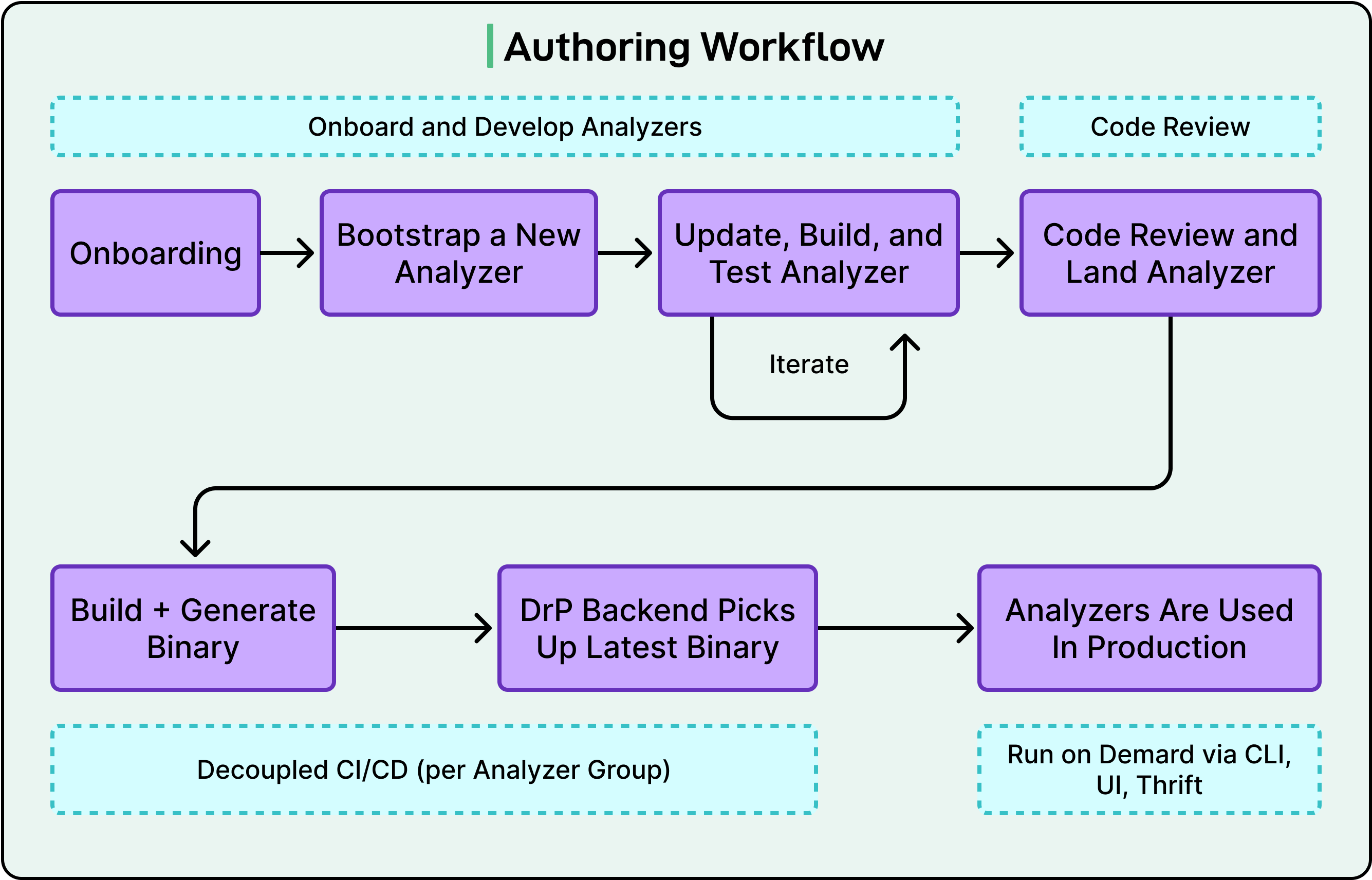
Các trình phân tích (analyzers) phải qua quá trình xem xét mã nguồn (code review). Chúng có chức năng kiểm thử ngược tự động tích hợp vào quy trình xem xét, vì vậy bạn có thể xác minh rằng một trình phân tích sẽ phát hiện ra các sự cố của tháng trước trước khi bạn triển khai nó. Chúng được triển khai thông qua quy trình CI/CD. Khi hệ thống cơ bản thay đổi, trình phân tích sẽ được cập nhật thông qua quy trình phát triển tương tự như bất kỳ mã nào khác.
Xem sơ đồ bên dưới hiển thị quy trình tạo nội dung cho cùng một quy trình:
SDK cũng cung cấp các thư viện chia sẻ cho các mẫu điều tra phổ biến, chẳng hạn như phát hiện bất thường (phát hiện hành vi lạ trong các số liệu), tương quan chuỗi thời gian (kiểm tra xem một đỉnh số liệu có khớp với một lần triển khai hoặc thay đổi cấu hình hay không), và phân tích chiều (tự động chia nhỏ các số liệu theo khu vực, loại thiết bị hoặc các thuộc tính khác để cô lập vấn đề đang tập trung ở đâu). Kỹ sư không cần phải tạo lại những thứ này từ đầu cho mỗi bộ phân tích.
Sự thay đổi trong tư duy cũng quan trọng không kém công nghệ. DrP có người dùng (kỹ sư trực ca), một đội ngũ nền tảng, các pipeline triển khai và các số liệu sử dụng. Nó được bảo trì và cải tiến liên tục, không bị bỏ rơi sau khi tác giả ban đầu chuyển sang đội khác.
Nền Tảng Vượt Trội So Với Script
Viết bộ phân tích dưới dạng mã là nền tảng. Nhưng lợi thế thực sự đến từ những gì xảy ra khi bạn kết nối chúng.
Trong kiến trúc microservices, nguyên nhân gốc rễ hiếm khi nằm ở dịch vụ đang hiển thị các triệu chứng. Tỷ lệ lỗi API của bạn tăng đột biến, nhưng nguyên nhân thực tế có thể là một thay đổi cấu hình trong dịch vụ lưu trữ ở ba lớp bên dưới. Với các script độc lập, mỗi đội chỉ có thể điều tra trong phạm vi của mình. Với DrP, các bộ phân tích có thể liên kết qua các ranh giới dịch vụ. Bộ phân tích API phát hiện ra vấn đề nằm ở hạ nguồn, gọi bộ phân tích Dịch vụ Lưu trữ, chuyển tiếp ngữ cảnh mà nó đã thu thập được, và nhận về một nguyên nhân gốc rễ đã được xác nhận. Điều này xảy ra tự động, mà không cần ai phải gửi tin nhắn trên Slack.
DrP cũng tích hợp trực tiếp vào vòng đời cảnh báo. Các bộ phân tích được kích hoạt tự động khi có cảnh báo. Kết quả sẽ chú thích cho chính cảnh báo đó, vì vậy kỹ sư trực ca sẽ thấy chẩn đoán cùng với thông báo cảnh báo, trước khi họ mở bất kỳ bảng điều khiển nào.
Sau khi điều tra, một hệ thống xử lý hậu kỳ có thể khép lại quy trình: tạo một tác vụ hoàn tác, tạo một lỗi, hoặc kích hoạt một bước giảm thiểu. Và cũng có một vòng lặp phản hồi rộng hơn.
DrP Insights định kỳ phân tích kết quả trên tất cả các cuộc điều tra để xác định và xếp hạng các nguyên nhân cảnh báo phổ biến nhất trong toàn tổ chức. Các cuộc điều tra cá nhân trở thành bài học cho tổ chức.
Một Cuộc Điều Tra: Từ Đầu Đến Cuối
Để cụ thể hóa điều này, đây là những gì một cuộc điều tra do DrP cung cấp trông như thế nào trong thực tế. Đây là một kịch bản có thể xảy ra dựa trên các khả năng đã được ghi lại của DrP, không phải là một sự cố cụ thể của Meta.
Hãy xem xét trường hợp tỷ lệ lỗi tăng đột biến trên một dịch vụ API. Cảnh báo được kích hoạt và tự động kích hoạt bộ phân tích liên quan. Từ đó, cuộc điều tra diễn ra qua một loạt các bước tự động:
Bộ phân tích lấy dữ liệu tỷ lệ lỗi và chạy phân tích chiều, chia theo khu vực, loại thiết bị và trung tâm dữ liệu. Nó cô lập vấn đề ở một khu vực.
Nó chạy tương quan chuỗi thời gian, so sánh sự gia tăng lỗi với các tín hiệu khác như độ trễ, sự kiện triển khai và thay đổi cấu hình. Nó tìm thấy sự trùng khớp mạnh mẽ với một thay đổi cấu hình gần đây trên một dịch vụ lưu trữ hạ nguồn.
-
Vì dịch vụ lưu trữ là một dependency riêng biệt, bộ phân tích sẽ kết nối vào bộ phân tích Storage Service, truyền ngữ cảnh khu vực. Bộ phân tích đó xác nhận độ trễ phản hồi của thay đổi cấu hình đã đẩy qua ngưỡng thời gian chờ của API.
Các phát hiện được hiển thị cho kỹ sư phụ trách theo lịch trình dưới dạng một bản tóm tắt có cấu trúc: khu vực bị ảnh hưởng, nguyên nhân gốc rễ, dấu thời gian tương quan và liên kết đến thay đổi gây lỗi.
Hệ thống xử lý hậu kỳ tạo ra một tác vụ hoàn tác được giao cho nhóm lưu trữ.
Kỹ sư xem xét phân tích, phê duyệt hoàn tác và sự cố được giải quyết. Cuộc điều tra có thể đã mất 45 phút làm thủ công trên nhiều công cụ và nhóm đã diễn ra trong nền trước khi kỹ sư đọc xong cảnh báo.
Kết luận
DrP đã giảm thời gian trung bình để giải quyết sự cố từ 20-80% trên các nhóm của Meta, với hơn 2.000 bộ phân tích đang hoạt động. Những con số đó rất thuyết phục, nhưng bài học sâu sắc không nằm ở một công cụ cụ thể tại một công ty cụ thể.
Kiến thức điều tra quá có giá trị để chỉ tồn tại trong đầu mọi người hoặc trong các tài liệu lỗi thời. Nó có thể được mã hóa thành phần mềm có thể kiểm thử và kết hợp.
Tuy nhiên, điều này không loại bỏ nhu cầu về phán đoán của con người. DrP cố tình giữ các kỹ sư tham gia, trình bày các phát hiện để xem xét thay vì tự động khắc phục. Và nó không miễn phí; các bộ phân tích là mã, và mã cần được bảo trì. Bạn đang đánh đổi công việc trực ban không thể đoán trước để lấy công việc kỹ thuật dễ quản lý hơn. Nhưng dù bạn làm việc ở đâu, câu hỏi đáng để đặt ra là: kiến thức gỡ lỗi của nhóm bạn có được tích hợp vào hệ thống của bạn không, hay nó đang chờ rời đi?
Tài liệu tham khảo:
Tác giả: ByteByteGo