Cách LinkedIn sử dụng LLM để phục vụ 1,3 tỷ người dùng
How LinkedIn Feed Uses LLMs to Serve 1.3 Billion Users
LinkedIn vừa thực hiện một bước chuyển mình quan trọng trong kiến trúc hệ thống Feed, từ mô hình phân mảnh gồm 5 pipeline truy xuất độc lập sang một hệ thống thống nhất dựa trên Large Language Models (LLM). Việc loại bỏ các hạ tầng rời rạc để thay thế bằng quy trình xử lý tập trung dựa trên LLM đã giúp đội ngũ kỹ thuật xóa bỏ sự phụ thuộc chồng chéo, đồng thời đồng nhất hóa logic tối ưu hóa hệ thống. Sự thay đổi này làm nổi bật bài toán hóc búa về việc cân bằng sức mạnh của các mô hình tiên tiến với giới hạn độ trễ cực thấp (dưới 50ms) để phục vụ hơn 1,3 tỷ người dùng. Qua đó, các lập trình viên có thể rút ra bài học rằng, việc chuyển đổi sang kiến trúc LLM thống nhất đòi hỏi phải giải quyết triệt để những thách thức kỹ thuật phức tạp như: tối ưu hóa cách mã hóa cấu trúc dữ liệu, tinh chỉnh hiệu năng suy luận (inference) ở quy mô lớn và khả năng lọc nhiễu hiệu quả từ các tập dữ liệu huấn luyện khổng lồ.
Trong bài viết này, chúng ta sẽ xem xét cách nhóm kỹ sư LinkedIn xây dựng lại Nguồn cấp dữ liệu và những thách thức họ gặp phải.
Cách ngừng trông trẻ cho đại lý của bạn (Được tài trợ)
 [[TAG _12]]
[[TAG _12]]Nhân viên hỗ trợ có thể tạo mã. Làm cho nó phù hợp với hệ thống của bạn, các quy ước nhóm và các quyết định trong quá khứ là một phần khó khăn. Cuối cùng, bạn là người trông coi đại lý và chứng kiến chi phí mã thông báo tăng lên.
Nhiều MCP, quy tắc hơn và cửa sổ ngữ cảnh lớn hơn cung cấp cho đại lý quyền truy cập vào thông tin nhưng không hiểu được. Các nhóm dẫn đầu có một công cụ ngữ cảnh để chỉ cung cấp cho các tổng đài viên những gì họ cần cho nhiệm vụ hiện tại.
Hãy tham gia hội thảo trực tuyến MIỄN PHÍ với chúng tôi vào ngày 23 tháng 4 để biết:
Trường hợp các nhóm gặp khó khăn trên đường cong trưởng thành của AI và lý do các bản sửa lỗi phổ biến lại không thành công ngắn
Cách công cụ ngữ cảnh giải quyết vấn đề chất lượng, hiệu quả và chi phí
Bản trình diễn trực tiếp: cùng một nhiệm vụ mã hóa khi có và không có công cụ ngữ cảnh
Nếu bạn muốn tối đa hóa giá trị nhận được từ các tác nhân AI thì đây là công cụ đáng giá của bạn thời gian.
LinkedIn từng chạy năm hệ thống riêng biệt chỉ để quyết định xem bài đăng nào sẽ hiển thị cho bạn. Một nội dung xu hướng được theo dõi. Một người khác đã thực hiện lọc cộng tác. Nhóm thứ ba xử lý việc truy xuất dựa trên nhúng.
Mỗi nhóm đều có cơ sở hạ tầng riêng, nhóm chuyên trách và logic tối ưu hóa riêng. Quá trình thiết lập đã thành công nhưng khi nhóm Nguồn cấp dữ liệu muốn cải thiện một phần, họ’sẽ phá vỡ một phần khác. Do đó, họ đã đặt cược triệt để và loại bỏ cả năm hệ thống, thay thế chúng bằng một mô hình truy xuất duy nhất được hỗ trợ bởi LLM. Điều đó đã giải quyết được vấn đề phức tạp nhưng lại đặt ra các câu hỏi mới, chẳng hạn như:
Làm cách nào để bạn dạy LLM hiểu dữ liệu hồ sơ có cấu trúc?
Làm cách nào để bạn tạo dự đoán phân phát máy biến áp trong thời gian dưới 50 mili giây cho 1,3 tỷ người dùng?
Bạn huấn luyện mô hình như thế nào khi phần lớn dữ liệu bị nhiễu?
Trong Trong bài viết này, chúng ta sẽ xem cách nhóm kỹ thuật LinkedIn xây dựng lại Nguồn cấp dữ liệu và những thách thức mà họ gặp phải.
Tuyên bố từ chối trách nhiệm: Bài đăng này dựa trên thông tin chi tiết được chia sẻ công khai từ Nhóm kỹ thuật LinkedIn. Vui lòng nhận xét nếu bạn nhận thấy bất kỳ thông tin nào không chính xác.
Năm thủ thư, một thư viện
Trong nhiều năm, việc truy xuất nguồn cấp dữ liệu của LinkedIn’ dựa vào cái mà các kỹ sư gọi là kiến trúc không đồng nhất. Khi bạn mở Nguồn cấp dữ liệu, nội dung đến từ nhiều nguồn chuyên biệt chạy song song.
Chỉ mục theo trình tự thời gian của hoạt động mạng.
Các bài đăng thịnh hành của địa lý.
Lọc cộng tác dựa trên các thành viên tương tự.
Theo ngành cụ thể quy trình.
Một số hệ thống truy xuất dựa trên nhúng.
Mỗi hệ thống duy trì cơ sở hạ tầng, cấu trúc chỉ mục và chiến lược tối ưu hóa của riêng mình.
Xem sơ đồ bên dưới:
Cái này kiến trúc nổi lên nội dung đa dạng, phù hợp. Tuy nhiên, việc tối ưu hóa một nguồn truy xuất có thể làm suy giảm nguồn truy xuất khác và không nhóm nào có thể điều chỉnh đồng thời trên tất cả các nguồn. Gần như không thể cải thiện toàn diện.
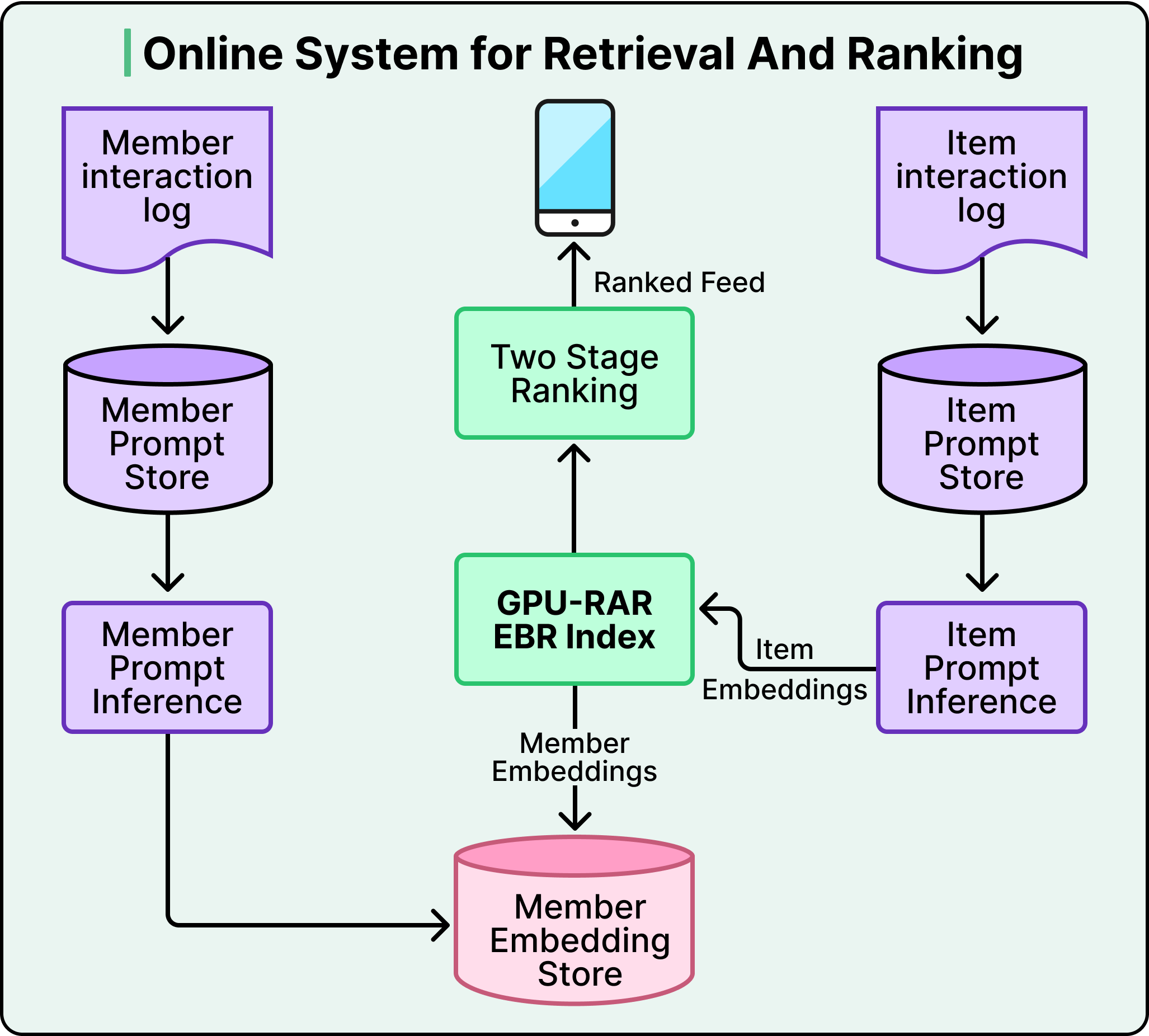
Vì vậy, nhóm Nguồn cấp dữ liệu đã hỏi một câu hỏi đơn giản. Điều gì sẽ xảy ra nếu họ thay thế tất cả các nguồn này bằng một hệ thống duy nhất được hỗ trợ bởi các phần nhúng do LLM tạo ra?
Về cơ bản, hệ thống này hoạt động thông qua kiến trúc bộ mã hóa kép. LLM được chia sẻ chuyển đổi cả thành viên và bài đăng thành vectơ trong cùng một không gian toán học. Quá trình đào tạo đẩy các đại diện của thành viên và bài đăng lại gần nhau khi có’sự tương tác thực sự và tách chúng ra khi không có’. Khi bạn mở Nguồn cấp dữ liệu của mình, hệ thống sẽ tìm nạp nội dung nhúng thành viên của bạn và chạy tìm kiếm lân cận gần nhất dựa trên chỉ mục các nội dung nhúng bài đăng, truy xuất các ứng viên phù hợp nhất dưới 50 tuổi mili giây.
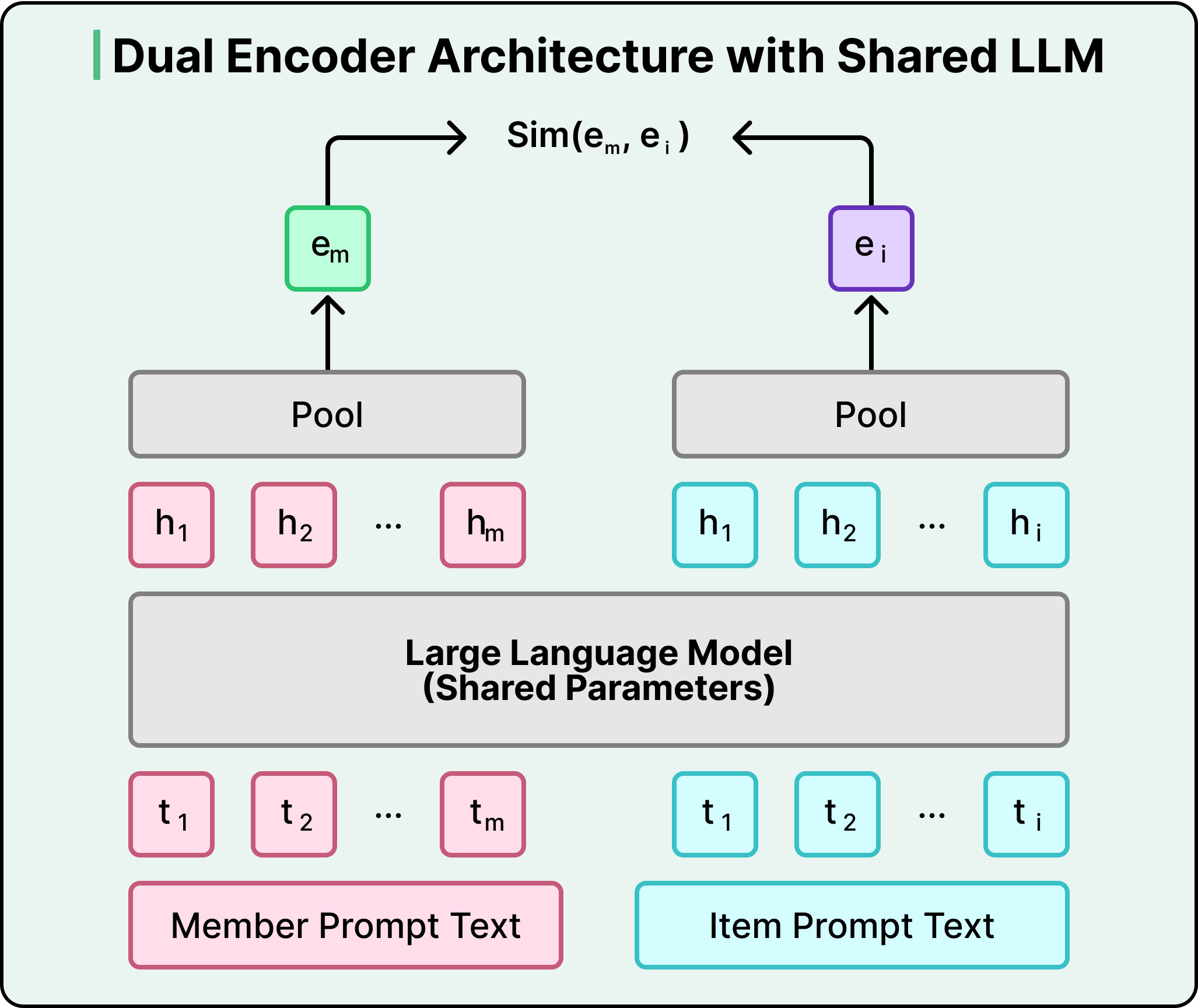
Một hệ thống dựa trên LLM hiểu rằng các chủ đề này có liên quan với nhau vì mô hình mang kiến thức thế giới từ quá trình đào tạo trước. Nó biết rằng các kỹ sư điện thường làm việc về tối ưu hóa lưới điện và cơ sở hạ tầng hạt nhân. Điều này đặc biệt hiệu quả đối với các tình huống bắt đầu từ đầu, khi một thành viên mới tham gia chỉ với dòng tiêu đề hồ sơ. LLM có thể suy ra những mối quan tâm có thể xảy ra mà không cần đợi lịch sử tương tác tích lũy.
Các lợi ích ở hạ nguồn kết hợp với các lợi ích. Thay vì nhận các ứng cử viên từ các nguồn khác nhau với các thành kiến khác nhau, lớp xếp hạng hiện nhận được một tập hợp các ứng cử viên mạch lạc được chọn thông qua sự tương đồng về ngữ nghĩa. Việc xếp hạng trở nên dễ dàng hơn và mỗi lần tối ưu hóa cho mô hình xếp hạng trở nên hiệu quả hơn.
Nhưng việc thay thế năm hệ thống bằng một LLM đã tạo ra một vấn đề mới. LLM yêu cầu văn bản và hệ thống đề xuất chạy trên dữ liệu có cấu trúc và số.
Mô hình chỉ tốt như đầu vào của nó
Để cung cấp dữ liệu có cấu trúc vào LLM, LinkedIn đã xây dựng “thư viện lời nhắc” giúp chuyển đổi các tính năng có cấu trúc thành chuỗi văn bản theo mẫu. Đối với bài đăng, nó bao gồm thông tin tác giả, số lượng tương tác và văn bản bài đăng. Đối với các thành viên, nó kết hợp thông tin hồ sơ, kỹ năng, lịch sử công việc và chuỗi bài đăng được sắp xếp theo thứ tự thời gian mà họ’đã tương tác trước đó. Hãy coi đó là kỹ thuật nhanh chóng cho các hệ thống đề xuất.
Ví dụ nổi bật nhất là những gì đã xảy ra với các tính năng số. Ban đầu, LinkedIn chuyển số lượng tương tác thô trực tiếp vào lời nhắc. Ví dụ: một bài đăng có 12.345 lượt xem sẽ xuất hiện dưới dạng “lượt xem:12345” trong văn bản. Mô hình xử lý các chữ số đó giống như bất kỳ mã thông báo văn bản nào khác. Khi nhóm đo lường mối tương quan giữa số lượng mặt hàng phổ biến và điểm tương tự khi nhúng, họ nhận thấy về cơ bản nó bằng 0 (-0,004). Mức độ phổ biến là một trong những tín hiệu liên quan mạnh nhất trong khuyến nghị. Và mô hình đã hoàn toàn bỏ qua nó.
Vấn đề là cơ bản. LLM không’không hiểu mức độ. Họ xử lý “12345” dưới dạng một chuỗi mã thông báo chữ số chứ không phải dưới dạng số lượng.
Việc khắc phục khá đơn giản. Thay vì chuyển số lượng thô, LinkedIn đã chuyển đổi chúng thành các nhóm phần trăm được bọc trong các mã thông báo đặc biệt. Điều này có nghĩa là “Lượt xem:12345” đã trở thành <view_percentile>71</view_percentile>, cho thấy bài đăng này nằm ở phân vị thứ 71 về số lượt xem. Hầu hết các giá trị từ 1 đến 100 được LLM xử lý dưới dạng một đơn vị thay vì một chuỗi nhiều chữ số, mang lại cho mô hình một vốn từ vựng ổn định, dễ học về số lượng. Mô hình có thể biết rằng mọi thứ trên 90 có nghĩa là “rất phổ biến” mà không cần cố gắng phân tích các chuỗi chữ số tùy ý.
Mối tương quan giữa các tính năng phổ biến và mức độ tương tự khi nhúng đã tăng gấp 30 lần. Recall@10, thước đo xem 10 bài đăng được truy xuất hàng đầu có thực sự phù hợp hay không, được cải thiện 15%. LinkedIn đã áp dụng chiến lược tương tự cho tỷ lệ tương tác, tín hiệu gần đây và điểm số mối quan hệ.
Ít dữ liệu hơn, mô hình tốt hơn
Khi xây dựng lịch sử tương tác của thành viên’ cho hoạt động đào tạo, LinkedIn ban đầu bao gồm mọi thứ. Mọi bài đăng được hiển thị cho thành viên đều được đưa vào trình tự, cho dù họ tương tác với bài đăng đó hay cuộn qua. Ý tưởng là nhiều dữ liệu hơn có nghĩa là mô hình tốt hơn.
Tuy nhiên, điều này’đã không xảy ra. Việc bao gồm các bài đăng được cuộn qua không chỉ khiến hiệu suất của mô hình kém hơn mà còn khiến việc đào tạo trở nên tốn kém hơn đáng kể. Tính toán GPU cho các mô hình máy biến áp chia tỷ lệ bậc hai theo độ dài ngữ cảnh.
Khi nhóm lọc để chỉ bao gồm các bài đăng có sự tương tác tích cực, kết quả đã cải thiện trên mọi thứ nguyên.
Dấu chân bộ nhớ trên mỗi chuỗi giảm đi 37%.
Hệ thống có thể xử lý thêm 40% trình tự huấn luyện mỗi lần lô.
Các lần lặp lại quá trình đào tạo chạy nhanh hơn 2,6 lần
Lý do là do tín hiệu rõ ràng. Một bài đăng được cuộn qua là không rõ ràng. Có lẽ bài viết không liên quan. Có lẽ thành viên đó đang bận. Có thể tiêu đề hơi thú vị nhưng chưa đủ để dừng lại. Các bài đăng mà bạn chủ động chọn tham gia là mục tiêu học tập rõ ràng hơn nhiều.
Lợi ích tăng lên nhờ sự thay đổi này. Chất lượng tín hiệu tốt hơn có nghĩa là đào tạo nhanh hơn. Đào tạo nhanh hơn có nghĩa là thử nghiệm nhiều hơn. Nhiều thử nghiệm hơn có nghĩa là điều chỉnh siêu tham số tốt hơn. Khi một thay đổi duy nhất cải thiện cả chất lượng và hiệu quả thì lợi ích sẽ nhân lên trong toàn bộ chu trình phát triển.
Chiến lược đào tạo còn có một yếu tố thông minh hơn. LinkedIn đã sử dụng hai loại ví dụ tiêu cực:
Phủ định dễ là các bài đăng được lấy mẫu ngẫu nhiên không bao giờ được hiển thị cho thành viên, cung cấp tín hiệu tương phản rộng.
Phủ định cứng là các bài đăng thực sự được hiển thị nhưng không được tương tác, các trường hợp gần như đúng mà người mẫu phải tìm hiểu sự khác biệt về sắc thái giữa có liên quan và thực sự có giá trị.
Độ khó của các ví dụ tiêu cực định hình những gì mô hình học được. Những âm bản dễ dàng dạy về sự phân biệt rộng rãi, trong khi những âm bản khó dạy những điều chi tiết. Sử dụng cả hai cùng nhau là mô hình phổ biến và hiệu quả trên các hệ thống truy xuất và tại LinkedIn, việc chỉ thêm hai âm bản cứng cho mỗi thành viên đã cải thiện khả năng ghi nhớ lên 3,6%.
Với việc truy xuất tạo ra các ứng viên chất lượng cao, câu hỏi tiếp theo là làm thế nào để xếp hạng họ. Câu trả lời của LinkedIn’ là ngừng coi mỗi bài đăng là một quyết định riêng biệt.
Nguồn cấp dữ liệu là một câu chuyện, không phải là ảnh chụp nhanh
Các mô hình xếp hạng truyền thống đánh giá từng cặp bài đăng của thành viên một cách độc lập. Cách này hiệu quả nhưng thiếu một số điều cơ bản về cách các chuyên gia xem nội dung.
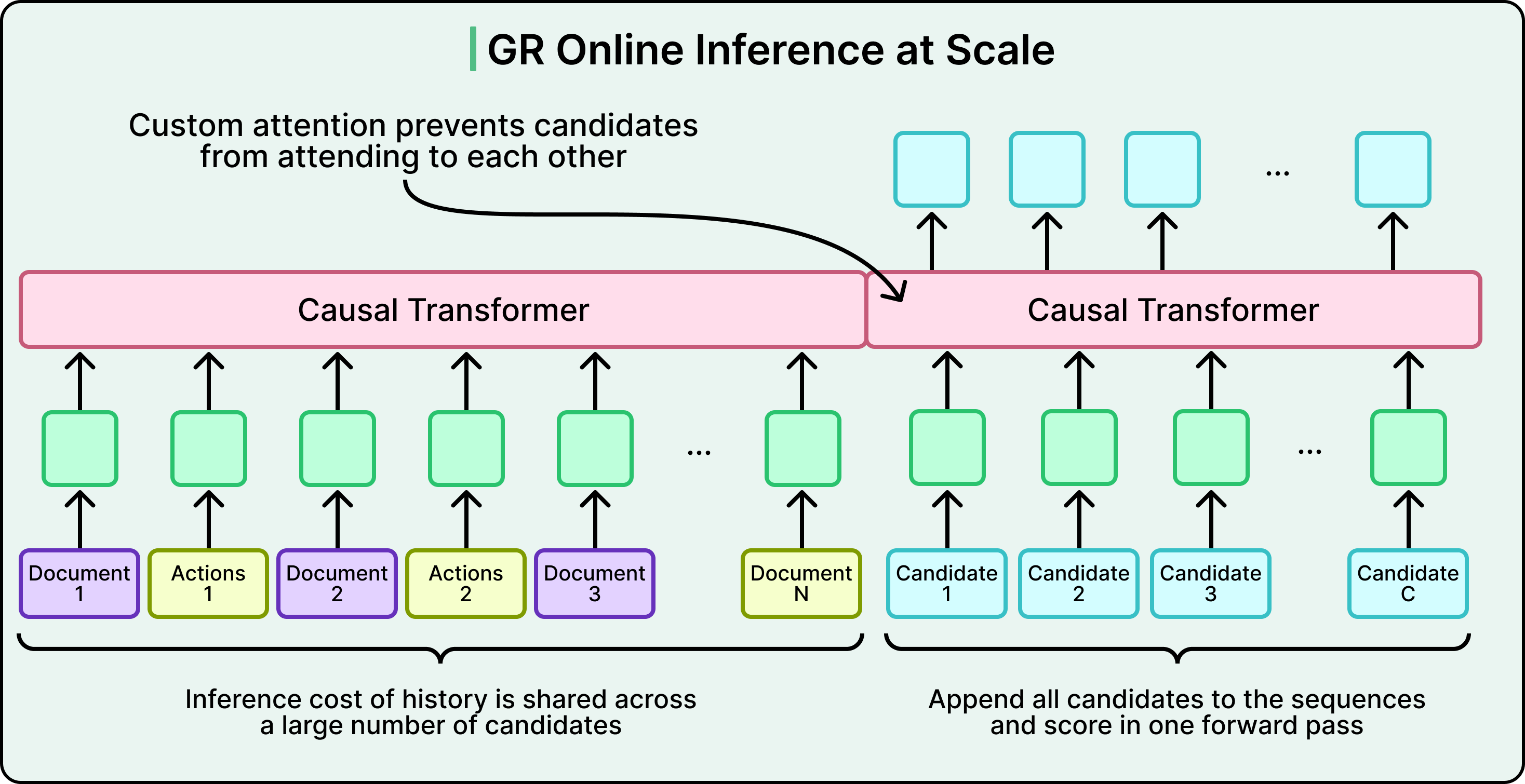
LinkedIn đã xây dựng mô hình Generative recommender (GR) xử lý lịch sử tương tác Nguồn cấp dữ liệu của bạn dưới dạng một chuỗi. Thay vì chấm điểm từng bài đăng một cách riêng biệt, GR xử lý hơn một nghìn tương tác lịch sử của người dùng’ để hiểu các xu hướng tạm thời và mối quan tâm lâu dài.
Sự khác biệt thực tế rất quan trọng. Nếu người dùng tương tác với nội dung máy học vào thứ Hai, hệ thống phân tán vào thứ Ba và mở lại LinkedIn vào thứ Tư, thì mô hình tuần tự sẽ hiểu đây không phải là những sự kiện ngẫu nhiên’. Chúng’là sự tiếp nối của một quỹ đạo học tập. Mô hình theo điểm truyền thống nhìn thấy ba quyết định độc lập, trong khi mô hình tuần tự nhìn thấy câu chuyện.
Mô hình GR sử dụng một máy biến áp có sự chú ý nhân quả, nghĩa là mỗi vị trí trong lịch sử chỉ có thể tham dự vào các vị trí trước đó, phản ánh cách bạn thực sự trải nghiệm nội dung theo thời gian. Các bài đăng gần đây có thể quan trọng hơn trong việc dự đoán mối quan tâm trước mắt, nhưng một bài đăng từ hai tuần trước có thể đột nhiên trở nên có liên quan nếu hoạt động gần đây gợi ý sự quan tâm mới.
Xem sơ đồ bên dưới hiển thị máy biến áp kiến trúc:
 [[TAG_333 ]]
[[TAG_333 ]]Trên đầu máy biến áp, đầu dự đoán Hỗn hợp các chuyên gia nhiều cổng (MMoE) định tuyến các dự đoán tương tác khác nhau như lượt nhấp, lượt thích, nhận xét và lượt chia sẻ thông qua các cổng chuyên biệt trong khi chia sẻ cùng một cách trình bày tuần tự bên dưới.
Xem sơ đồ bên dưới thể hiện Nhóm chuyên gia điển hình kiến trúc.
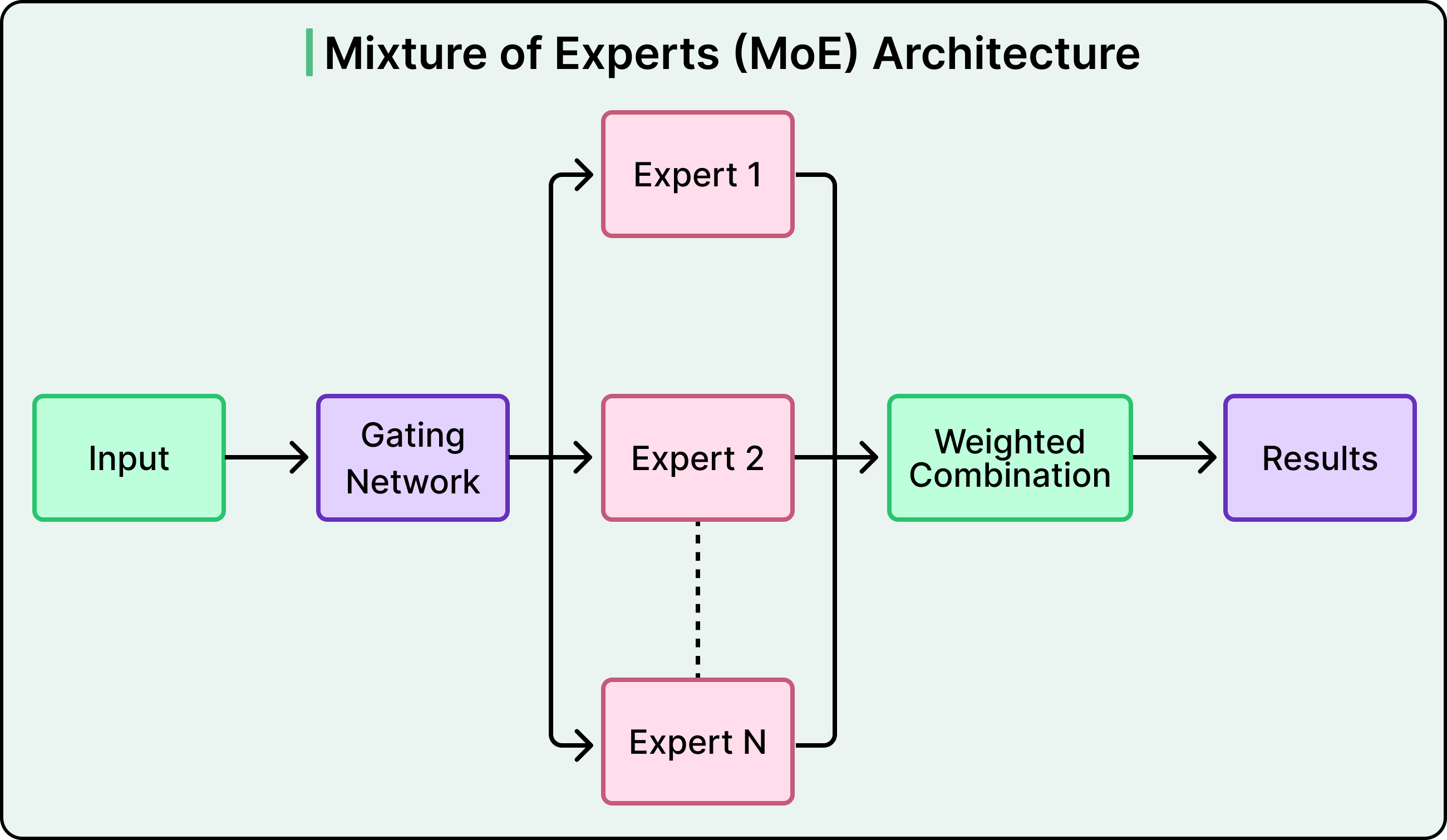
Tươi Ness cần có giải pháp riêng.
Ba quy trình nền chạy liên tục giúp hệ thống luôn cập nhật, nắm bắt hoạt động của nền tảng, tạo các nội dung nhúng cập nhật thông qua máy chủ suy luận LLM và nhập chúng vào chỉ mục được GPU tăng tốc.
Mỗi quy trình tối ưu hóa độc lập, trong khi hệ thống toàn diện luôn hoạt động mới trong vòng vài phút. Các mô hình của LinkedIn’ cũng được kiểm tra thường xuyên để đảm bảo các bài đăng từ những người sáng tạo khác nhau cạnh tranh bình đẳng, với thứ hạng dựa vào các tín hiệu chuyên nghiệp và mô hình tương tác, chứ không bao giờ dựa vào thuộc tính nhân khẩu học.
Kết luận
Có một số mô hình bài học rút ra:
Việc thay thế năm hệ thống truy xuất bằng một hệ thống sẽ đổi lấy khả năng phục hồi tính đơn giản.
Các phần nhúng dựa trên LLM phong phú hơn nhưng đắt hơn các giải pháp thay thế nhẹ.
Nút thắt cổ chai hiếm khi nằm ở kiến trúc mô hình. Đó’là mọi thứ xung quanh nó.
Đầu tư vào cơ sở hạ tầng thể hiện nỗ lực mà hầu hết các nhóm ’không thể lặp lại. Và cách tiếp cận này dựa trên dữ liệu văn bản đa dạng thức của LinkedIn’. Đối với các nền tảng chủ yếu là trực quan, phép tính sẽ khác.
Lần tới khi bạn mở LinkedIn và nhìn thấy bài đăng từ người nào đó mà bạn không[TAG_536]]theo dõi, về một chủ đề mà bạn không[TAG_537]]không tìm kiếm, nhưng đó’chính xác là những gì bạn cần đọc, đó’ là tất cả những điều này phối hợp với nhau trong mui xe.
Tài liệu tham khảo:
Tác giả: ByteByteGo