Làm thế nào Datadog định nghĩa lại sao chép dữ liệu
How Datadog Redefined Data Replication
Datadog đã tái cấu trúc lại chiến lược sao chép dữ liệu của mình, thoát khỏi cách chỉ cache từng endpoint đơn lẻ. Cách tiếp cận mới này giải quyết các hạn chế của việc cache hẹp, vốn dễ dẫn đến dữ liệu lỗi thời, tăng độ phức tạp và gây áp lực không mong muốn lên database. Các developer nên rút ra bài học từ đây bằng cách áp dụng các chiến lược caching rộng hơn và đảm bảo cơ chế sao chép dữ liệu của mình được thiết kế để có khả năng mở rộng (scalability) và hiệu quả, thay vì chỉ tập trung tối ưu cho từng request riêng lẻ.
Trong bài viết này, chúng ta sẽ xem xét cách Datadog thực hiện những thay đổi và những thách thức mà họ phải đối mặt.
Nếu bộ nhớ cache của bạn chỉ tăng tốc một vài điểm cuối, thì chiến lược bộ nhớ cache của bạn quá hẹp.
Mô hình đó không thể mở rộng. Nó tạo ra dữ liệu lỗi thời, sự phức tạp gia tăng và tải lên cơ sở dữ liệu của bạn nhiều hơn bạn nghĩ.
Các hệ thống hiện đại xem bộ nhớ cache khác đi. Nó được coi là một lớp dữ liệu thời gian thực, có cấu trúc, có thể truy vấn và luôn đồng bộ với dữ liệu nguồn.
Hướng dẫn này sẽ đi qua cách các nhóm thực hiện sự thay đổi đó—từ lưu trữ key-value cơ bản đến bộ nhớ cache có thể xử lý khối lượng công việc sản xuất thực tế.
Bên trong, bạn sẽ tìm hiểu:
Cách giảm áp lực cho cơ sở dữ liệu mà không cần thêm cơ sở hạ tầng
Cách phục vụ nhiều truy vấn hơn với độ trễ dưới mili giây
Cách giữ cho dữ liệu mới mà không cần chắp vá các pipeline dễ gãy
Nếu bạn đang gặp giới hạn về hiệu suất hoặc chi phí, hướng dẫn này là dành cho bạn.
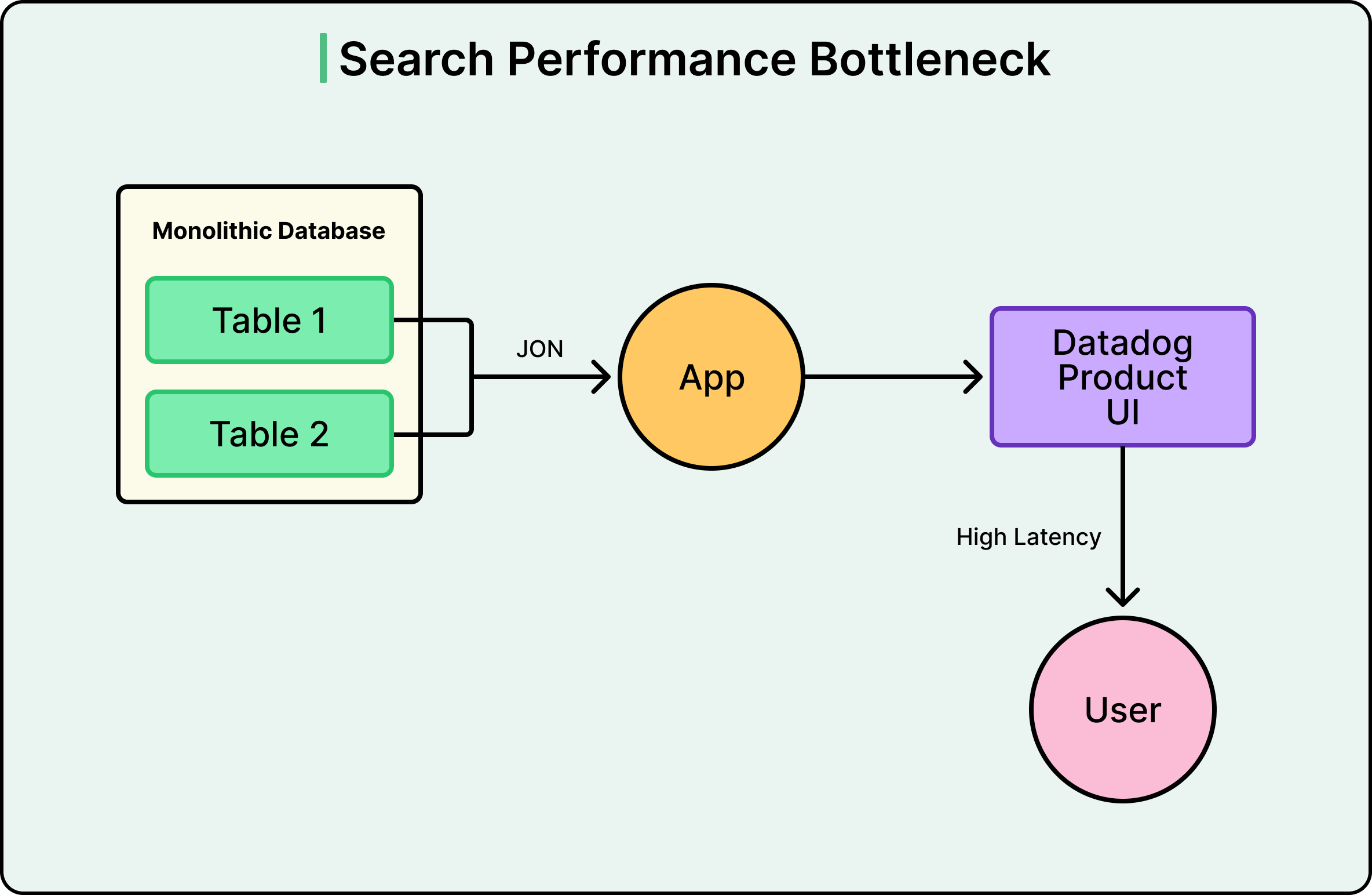
Trang Tóm tắt Chỉ số của Datadog gặp sự cố. Đối với một khách hàng, mỗi lần ai đó tải trang, cơ sở dữ liệu phải nối một bảng gồm 82.000 chỉ số hoạt động với 817.000 cấu hình chỉ số. Độ trễ p90 lên tới 7 giây. Mỗi lần người dùng nhấp vào bộ lọc, nó lại kích hoạt một phép nối tốn kém khác.
Nhóm đã thử các giải pháp thông thường, chẳng hạn như tối ưu hóa truy vấn, lập chỉ mục và điều chỉnh. Tuy nhiên, vấn đề không nằm ở truy vấn. Họ đang yêu cầu một cơ sở dữ liệu được thiết kế cho các giao dịch thực hiện công việc của một công cụ tìm kiếm. Việc sửa một trang duy nhất đó đã tạo ra một chuỗi các quyết định kiến trúc không chỉ giải quyết vấn đề hiệu suất. Nó đã dẫn Datadog đến việc định nghĩa lại cơ bản cách thức nhân bản dữ liệu hoạt động trên toàn bộ cơ sở hạ tầng của mình.
Trong bài viết này, chúng ta sẽ xem xét cách Datadog đã triển khai các thay đổi và những thách thức mà họ phải đối mặt.
Tuyên bố miễn trừ trách nhiệm: Bài viết này dựa trên các chi tiết được chia sẻ công khai từ Nhóm Kỹ thuật Datadog. Vui lòng bình luận nếu bạn nhận thấy bất kỳ điểm không chính xác nào.
Cơ sở dữ liệu chỉ đơn giản là thực hiện công việc sai
Datadog vận hành hàng nghìn dịch vụ, nhiều dịch vụ trong số đó được hỗ trợ bởi một cơ sở dữ liệu Postgres dùng chung. Trong một thời gian dài, cơ sở dữ liệu dùng chung đó là lựa chọn đúng đắn. Postgres đáng tin cậy, được hiểu rõ và hiệu quả về chi phí ở quy mô nhỏ đến trung bình. Tuy nhiên, khi khối lượng dữ liệu tăng lên, những điểm yếu bắt đầu lộ rõ, và trang Tóm tắt Chỉ số chỉ là triệu chứng dễ thấy nhất.
Phản ứng đầu tiên của nhóm là tối ưu hóa cơ sở dữ liệu. Họ đã thử điều chỉnh thứ tự nối, thêm các chỉ mục đa cột và sử dụng các phỏng đoán truy vấn dựa trên kích thước bảng. Không có cách nào hiệu quả và có một số vấn đề:
Sự phình to của đĩa và chỉ mục làm chậm quá trình chèn và cập nhật.
Các hoạt động VACUUM và ANALYZE làm tăng chi phí bảo trì.
Áp lực bộ nhớ làm tăng thời gian chờ I/O.
Việc giám sát bằng APM của chính Datadog đã xác nhận rằng các truy vấn này đang tiêu thụ một phần tài nguyên hệ thống không tương xứng và ngày càng tệ hơn khi dữ liệu tăng lên. Đến khi nhiều tổ chức vượt qua ngưỡng 50.000 chỉ số trên mỗi tổ chức, các dấu hiệu cảnh báo đã xuất hiện ở khắp mọi nơi, chẳng hạn như tải trang chậm, bộ lọc không đáng tin cậy và chi phí vận hành ngày càng tăng.
Xem sơ đồ bên dưới:
Postgres đang được yêu cầu thực hiện hai công việc cơ bản khác nhau cùng lúc. Các workload OLTP là những gì cơ sở dữ liệu quan hệ được thiết kế để xử lý. Tuy nhiên, tìm kiếm thời gian thực với việc lọc trên các tập dữ liệu khổng lồ, phi chuẩn hóa là một workload hoàn toàn khác, một loại workload mà các công cụ tìm kiếm như Elasticsearch được thiết kế chuyên biệt để xử lý.
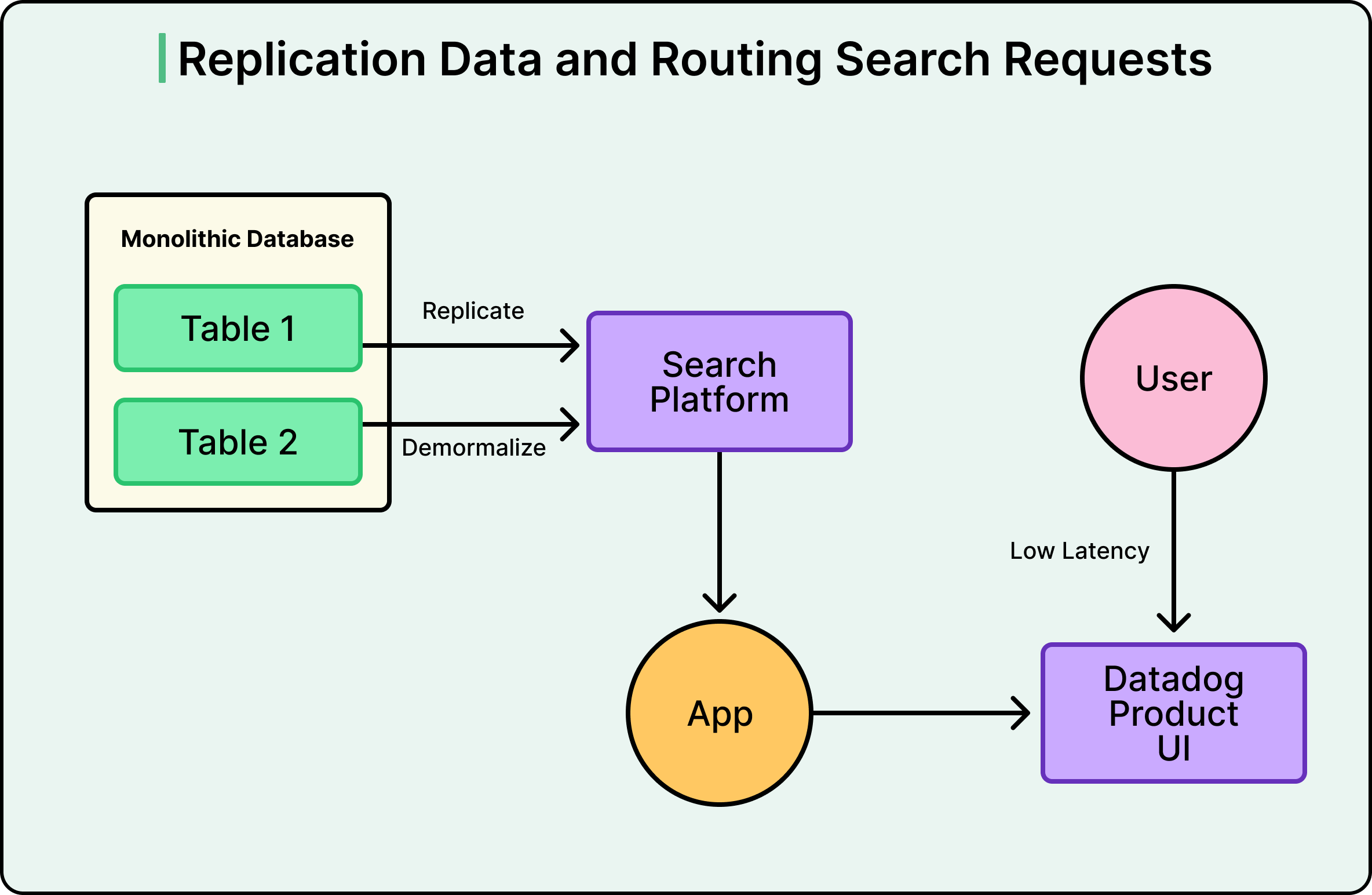
Do đó, thay vì làm cho Postgres tốt hơn trong việc tìm kiếm, Datadog đã ngừng làm cho nó tìm kiếm nữa. Họ đã sao chép dữ liệu từ Postgres vào một nền tảng tìm kiếm chuyên dụng, làm phẳng cấu trúc quan hệ thành các tài liệu phi chuẩn hóa trong quá trình này. Cơ chế đằng sau điều này là Change Data Capture, hay CDC.
Postgres đã ghi lại mọi thay đổi (mọi insert, update và delete) trong Write-Ahead Log, hay WAL. Nhật ký này tồn tại chủ yếu để phục hồi sau sự cố, nhưng nó cũng có thể được đọc bởi các công cụ bên ngoài. Datadog đã sử dụng Debezium, một công cụ CDC mã nguồn mở, để đọc nhật ký đó và truyền các thay đổi vào Kafka, một bộ chuyển tiếp thông báo bền vững. Từ Kafka, các trình kết nối sink đã đẩy dữ liệu vào nền tảng tìm kiếm.
Ưu điểm của phương pháp này là bản thân ứng dụng không cần phải thay đổi cách nó ghi dữ liệu. Nó vẫn ghi vào Postgres như trước. Tuy nhiên, các truy vấn tìm kiếm giờ đây sẽ truy cập nền tảng tìm kiếm thay thế, một nền tảng được thiết kế chuyên biệt cho chính xác workload đó.
Xem sơ đồ bên dưới:
Tại sao lại là Async?
Trước khi mở rộng mô hình đó, đội ngũ đã phải đối mặt với một lựa chọn thiết kế quan trọng: sao chép đồng bộ (synchronous) hay bất đồng bộ (asynchronous).
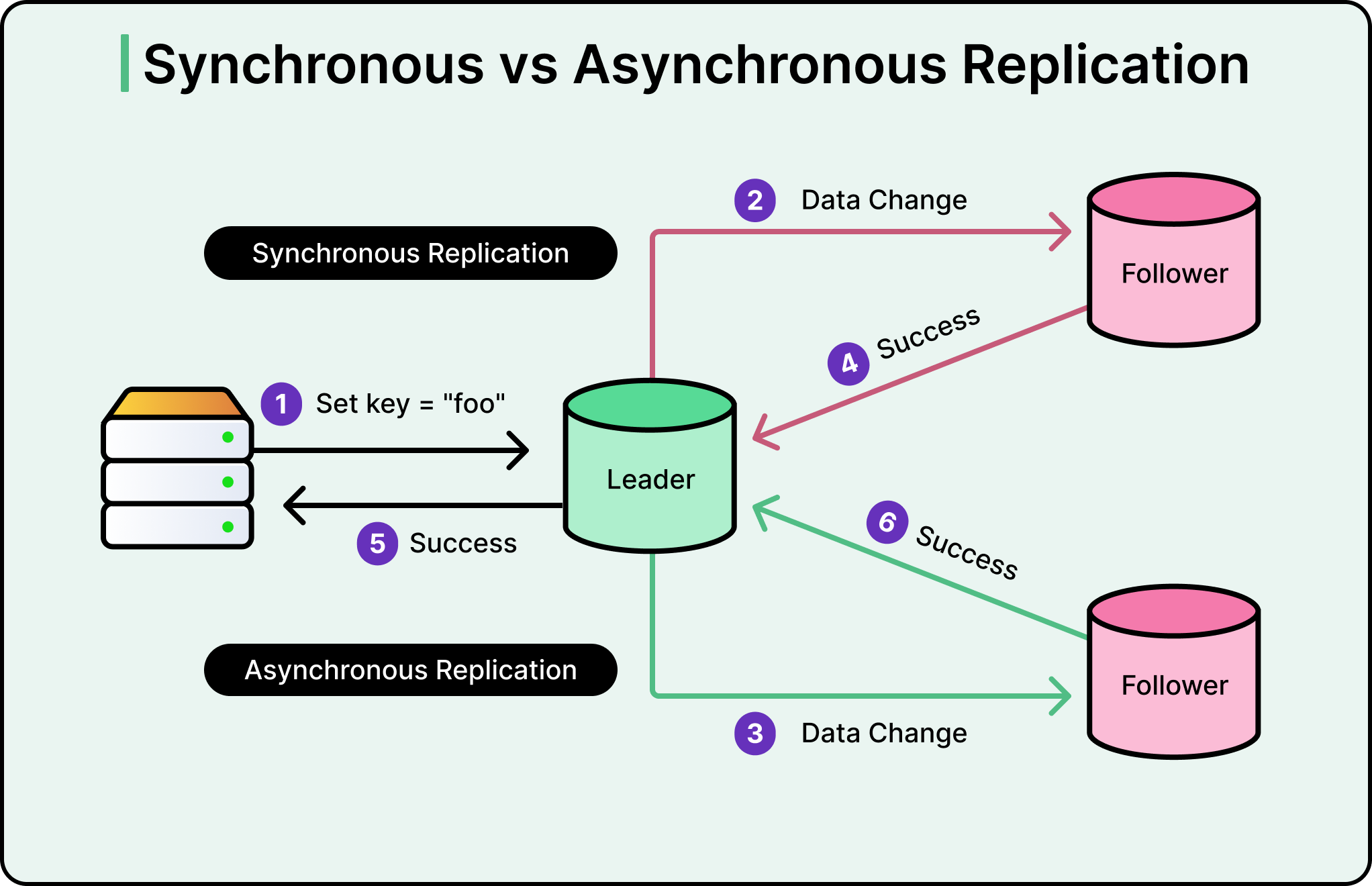
Trong sao chép đồng bộ, cơ sở dữ liệu chính sẽ không xác nhận một thao tác ghi cho ứng dụng cho đến khi mọi bản sao đã xác nhận nhận được nó. Điều này đảm bảo tính nhất quán mạnh mẽ (strong consistency), nghĩa là mọi hệ thống luôn có cùng dữ liệu. Nhưng nó chậm. Nếu một bản sao nằm cách xa qua mạng hoặc tạm thời không hoạt động, toàn bộ quy trình ghi sẽ bị đình trệ, chờ xác nhận. Một người tiêu thụ chậm sẽ trở thành điểm nghẽn cho mọi thứ.
Sao chép bất đồng bộ thì khác. Cơ sở dữ liệu chính xác nhận thao tác ghi ngay lập tức, và các bản sao sẽ cập nhật sau. Ứng dụng không bao giờ phải chờ đợi các hệ thống phía dưới. Điều này nhanh hơn và mạnh mẽ hơn, nhưng nó tạo ra một khoảng thời gian mà bản sao bị chậm hơn nguồn. Khoảng cách này được gọi là độ trễ sao chép (replication lag). Dữ liệu sẽ đến đích, nhưng không phải ngay lập tức.
Xem sơ đồ bên dưới:
Datadog đã chọn phương thức bất đồng bộ. Với quy mô của họ, với hàng nghìn dịch vụ trải rộng trên nhiều trung tâm dữ liệu, việc sao chép đồng bộ sẽ làm ảnh hưởng hiệu suất ứng dụng của họ đến độ trễ mạng và tình trạng của mọi hệ thống tiêu thụ hạ nguồn. Điều đó là không thể chấp nhận được.
Một yếu tố giúp ích cho việc ra quyết định là chi phí hữu hình. Trong một khoảng thời gian ngắn sau khi ghi, nền tảng tìm kiếm có thể hiển thị kết quả hơi lỗi thời. Nếu người dùng thêm cấu hình chỉ số mới và ngay lập tức tìm kiếm nó, nền tảng tìm kiếm có thể vẫn chưa có bản cập nhật. Đối với các trường hợp sử dụng của Datadog (tìm kiếm, lọc, bảng điều khiển phân tích), độ trễ vài trăm mili giây là một sự đánh đổi hoàn toàn chấp nhận được so với thời gian tải trang 7 giây.
Debezium thu thập các thay đổi từ WAL, và Kafka hoạt động như một bộ đệm bền bỉ giữa nguồn và tất cả các hệ thống tiêu thụ. Vì Kafka lưu trữ tin nhắn vào đĩa và hỗ trợ phát lại, các thay đổi sẽ không bị mất ngay cả khi một hệ thống tiêu thụ tạm thời gặp sự cố. Hệ thống tiêu thụ chỉ cần tiếp tục từ điểm nó đã dừng lại.
Sự đánh đổi giữa tính nhất quán và tính khả dụng này xuất hiện ở mọi nơi trong các hệ thống phân tán. Đó là một trường hợp thực tế của định lý CAP, mô tả sự căng thẳng cơ bản giữa tính nhất quán, tính khả dụng và khả năng chịu lỗi phân vùng.
Sao chép bất đồng bộ đã giải quyết vấn đề hiệu suất. Tuy nhiên, nó đã tạo ra một thách thức mới. Điều gì xảy ra khi hình dạng dữ liệu của bạn thay đổi?
Vấn đề với Sự Tiến hóa Lược đồ
Trong một ứng dụng thông thường, việc thay đổi lược đồ cơ sở dữ liệu là giữa bạn và cơ sở dữ liệu của bạn. Bạn chạy một bản di chuyển, thêm một cột, thay đổi một kiểu dữ liệu và tiếp tục. Với CDC, mọi thay đổi lược đồ sẽ lan truyền đến mọi hệ thống tiêu thụ hạ nguồn, và nếu các hệ thống tiêu thụ đó chưa sẵn sàng cho thay đổi, đường ống sẽ bị hỏng.
Hãy xem xét một ví dụ cụ thể. Một nhóm thêm một trường khu vực bắt buộc vào bảng bằng cách sử dụng ALTER TABLE ... ALTER COLUMN ... SET NOT NULL. Debezium bắt đầu tạo các tin nhắn bao gồm trường này. Nhưng các tin nhắn đã có trong Kafka được ghi theo lược đồ cũ và không có nó. Các hệ thống tiêu thụ mong đợi mọi tin nhắn đều có trường khu vực không được null bắt đầu gặp lỗi và đường ống bị dừng.
Datadog đã xây dựng một hệ thống phòng thủ hai phần chống lại điều này.
Tuyến phòng thủ đầu tiên là một hệ thống xác thực tự động phân tích các tệp SQL di chuyển lược đồ trước khi nó được áp dụng cho cơ sở dữ liệu. Nó phát hiện các thay đổi rủi ro, như thêm các ràng buộc NOT NULL, và chặn chúng triển khai mà không có sự phối hợp. Hầu hết các bản di chuyển đều được thông qua tự động. Những bản di chuyển không được gắn cờ yêu cầu nhóm làm việc trực tiếp với nhóm nền tảng để phối hợp triển khai an toàn.
Tuyến phòng thủ thứ hai là một Kafka Schema Registry đa người thuê được cấu hình cho khả năng tương thích ngược. Điều này có nghĩa là bất kỳ lược đồ mới nào cũng phải được đọc bởi các hệ thống tiêu thụ chỉ hiểu lược đồ cũ. Trên thực tế, điều này hạn chế các thay đổi lược đồ thành các hoạt động an toàn, như thêm các trường tùy chọn hoặc xóa các trường hiện có. Khi Debezium thu thập một lược đồ đã cập nhật, nó sẽ tuần tự hóa dữ liệu ở định dạng Avro và đẩy cả dữ liệu và bản cập nhật lược đồ tới Registry.
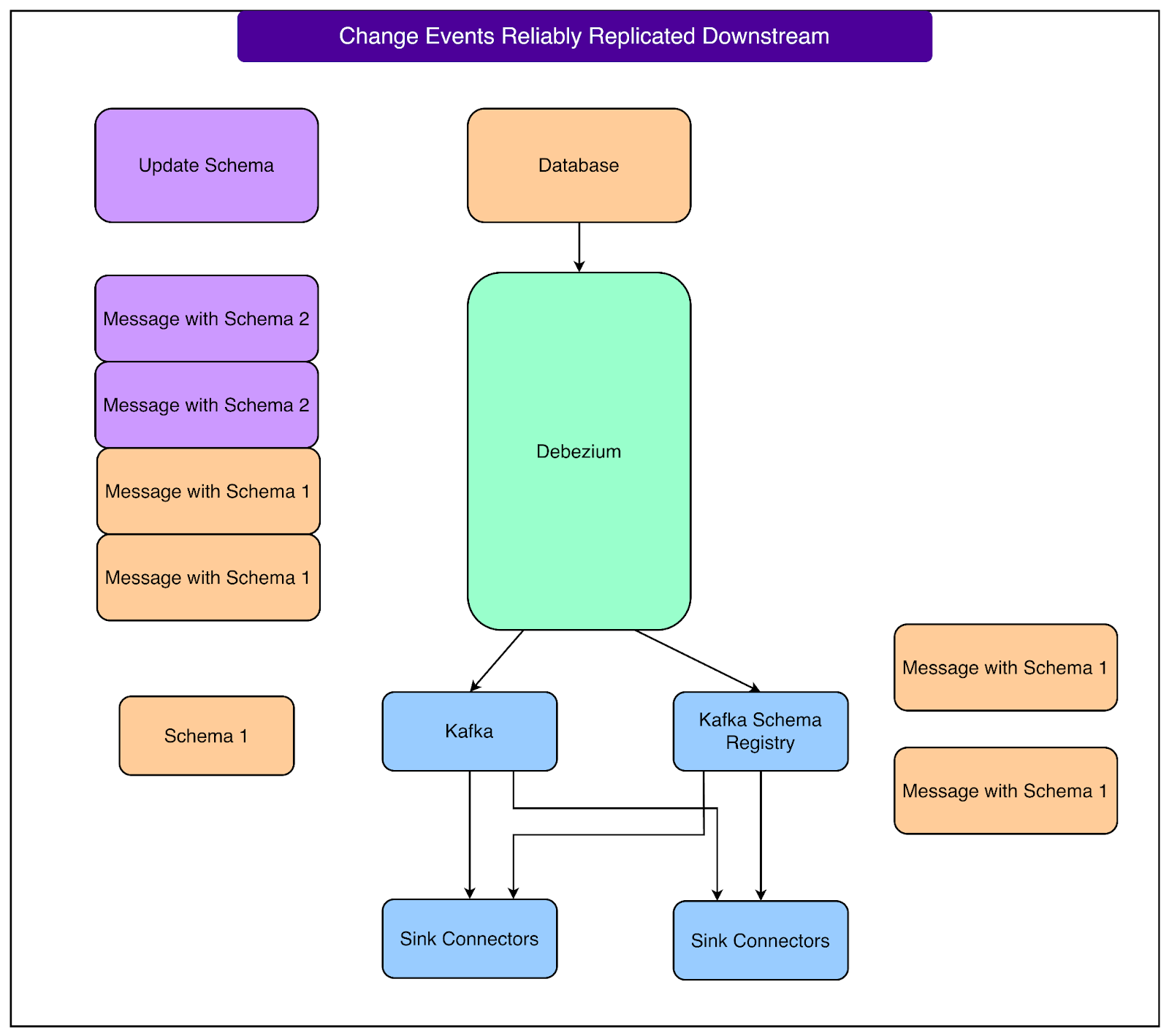
Registry kiểm tra schema mới so với schema hiện có và chấp nhận hoặc từ chối nó dựa trên các quy tắc tương thích ngược. Datadog sử dụng Avro serialization cụ thể vì nó hỗ trợ đàm phán schema theo cách này một cách tự nhiên. Tài liệu về Confluent Schema Registry bao gồm các cơ chế của chế độ tương thích ngược, tương thích xuôi và tương thích đầy đủ.
Kết hợp hai hệ thống này có nghĩa là hầu hết các thay đổi schema đều được xử lý tự động, các thay đổi gây lỗi được phát hiện sớm và các trình tiêu thụ ở các giai đoạn sau không gặp phải các pipeline bị lỗi.
Với sao chép không đồng bộ đang chạy và quản lý phiên bản schema được kiểm soát, Datadog đã có một pipeline hoạt động. Tuy nhiên, việc thiết lập mỗi pipeline mới vẫn yêu cầu một kỹ sư cấu hình thủ công bảy hoặc nhiều thành phần trên nhiều hệ thống. Đó là nơi tự động hóa đã thay đổi cuộc chơi.
Từ Một Pipeline Đến Một Nền Tảng
Một pipeline CDC duy nhất liên quan đến nhiều bộ phận chuyển động. Ví dụ, bạn cần bật logical replication trên Postgres bằng cách đặt wal_level thành logical. Ngoài ra, bạn cần tạo người dùng Postgres với các quyền phù hợp, thiết lập các replication slot và publication, triển khai các Debezium instance, tạo các Kafka topic với ánh xạ chính xác, thiết lập heartbeat table để giám sát và cấu hình sink connector để đẩy dữ liệu vào đích.
Thực hiện tất cả những điều đó thủ công cho một pipeline là tẻ nhạt. Nhưng thực hiện nó trên nhiều pipeline và nhiều trung tâm dữ liệu có nghĩa là gánh nặng vận hành sẽ tăng lên nhanh chóng.
Xem sơ đồ bên dưới:
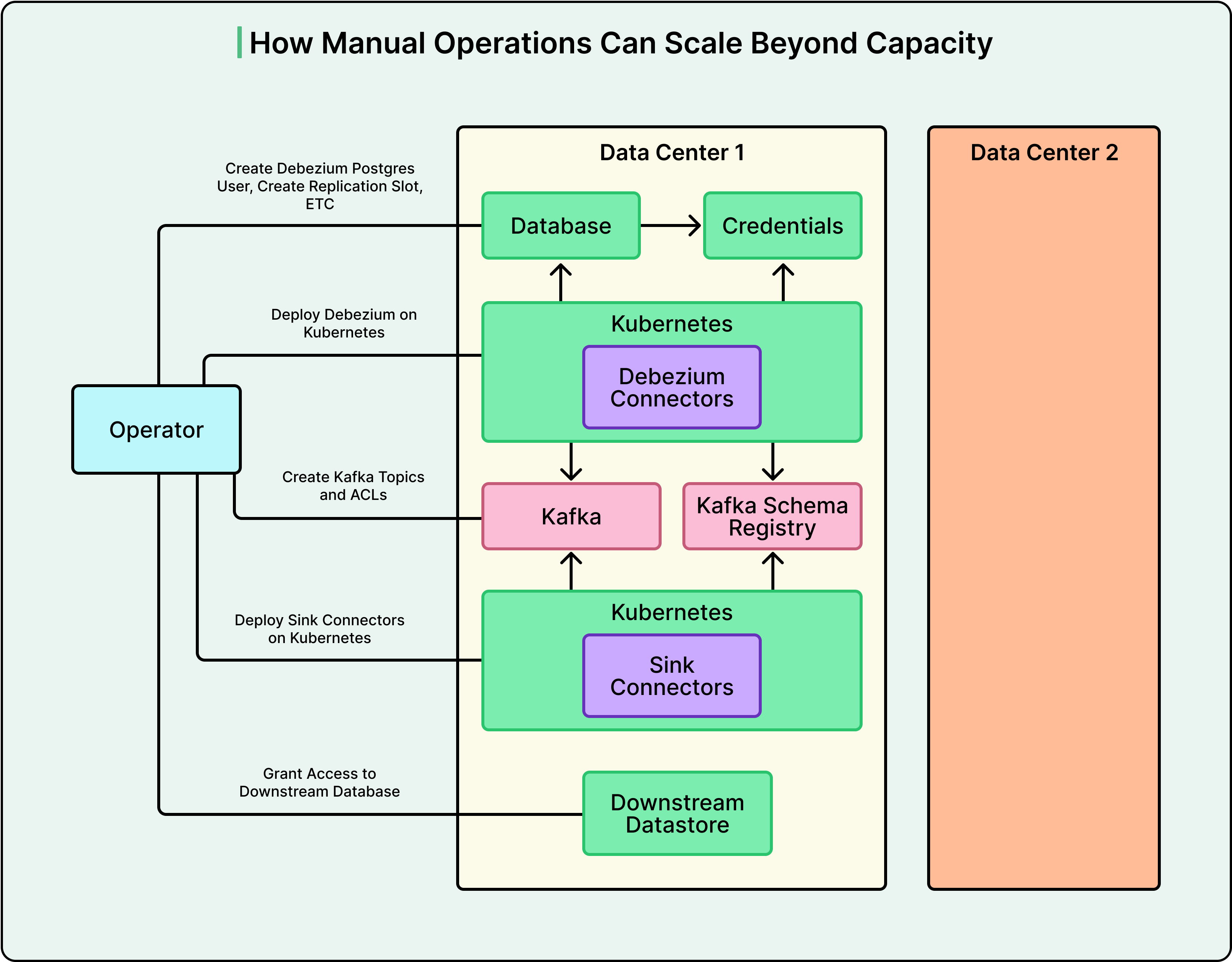
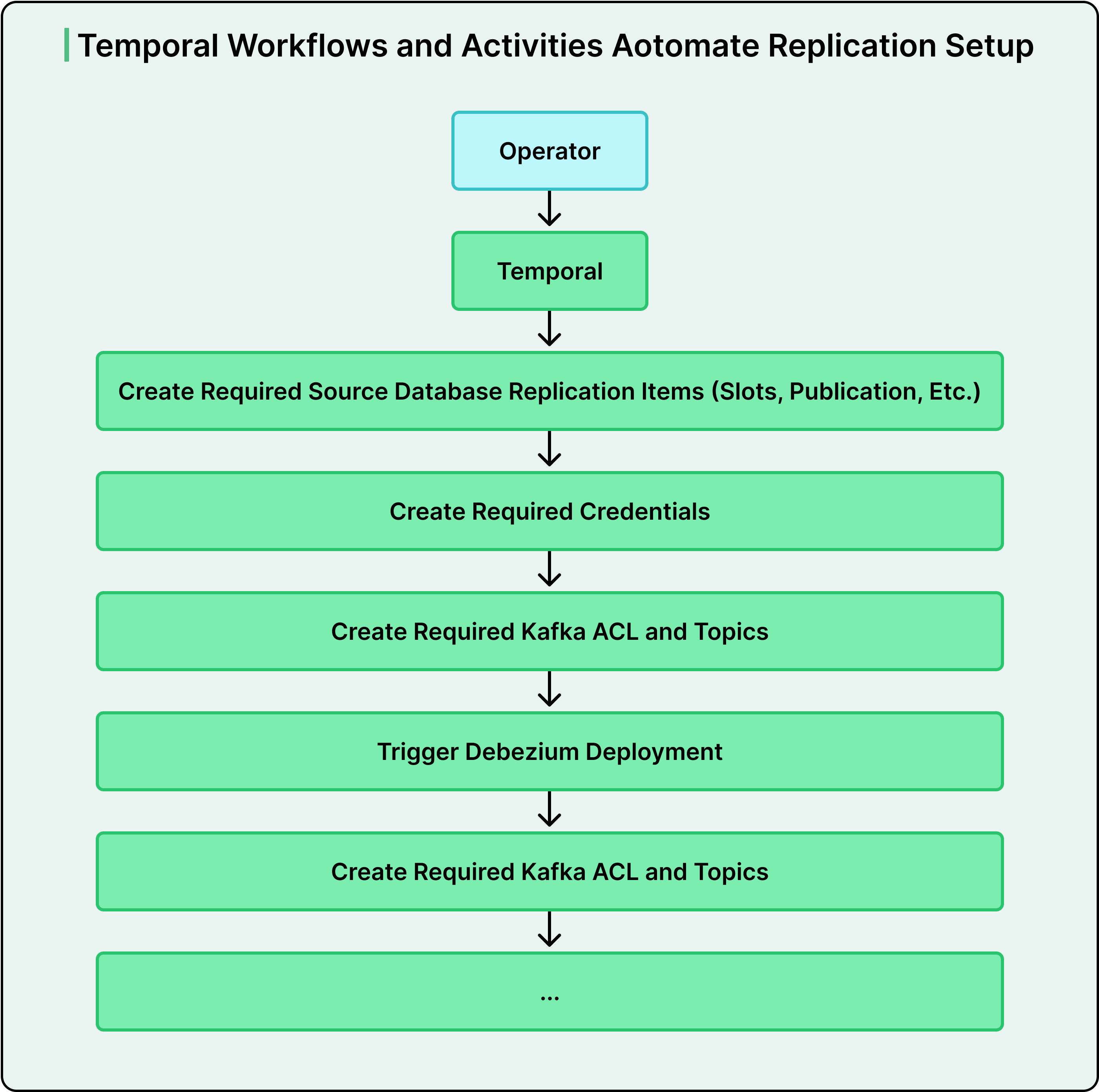
Datadog đã biến tự động hóa thành một nguyên tắc nền tảng. Sử dụng Temporal, một công cụ điều phối quy trình làm việc (workflow orchestration engine), họ đã chia nhỏ quy trình cấp phép thành các tác vụ mô-đun, đáng tin cậy và kết nối chúng thành các quy trình làm việc cấp cao hơn. Nếu một bước thất bại, quy trình làm việc sẽ thử lại hoặc hoàn tác một cách gọn gàng. Các nhóm không tương tác trực tiếp với cơ sở hạ tầng. Họ yêu cầu một pipeline thông qua nền tảng, và quá trình tự động hóa sẽ xử lý mọi thứ từ đầu đến cuối.
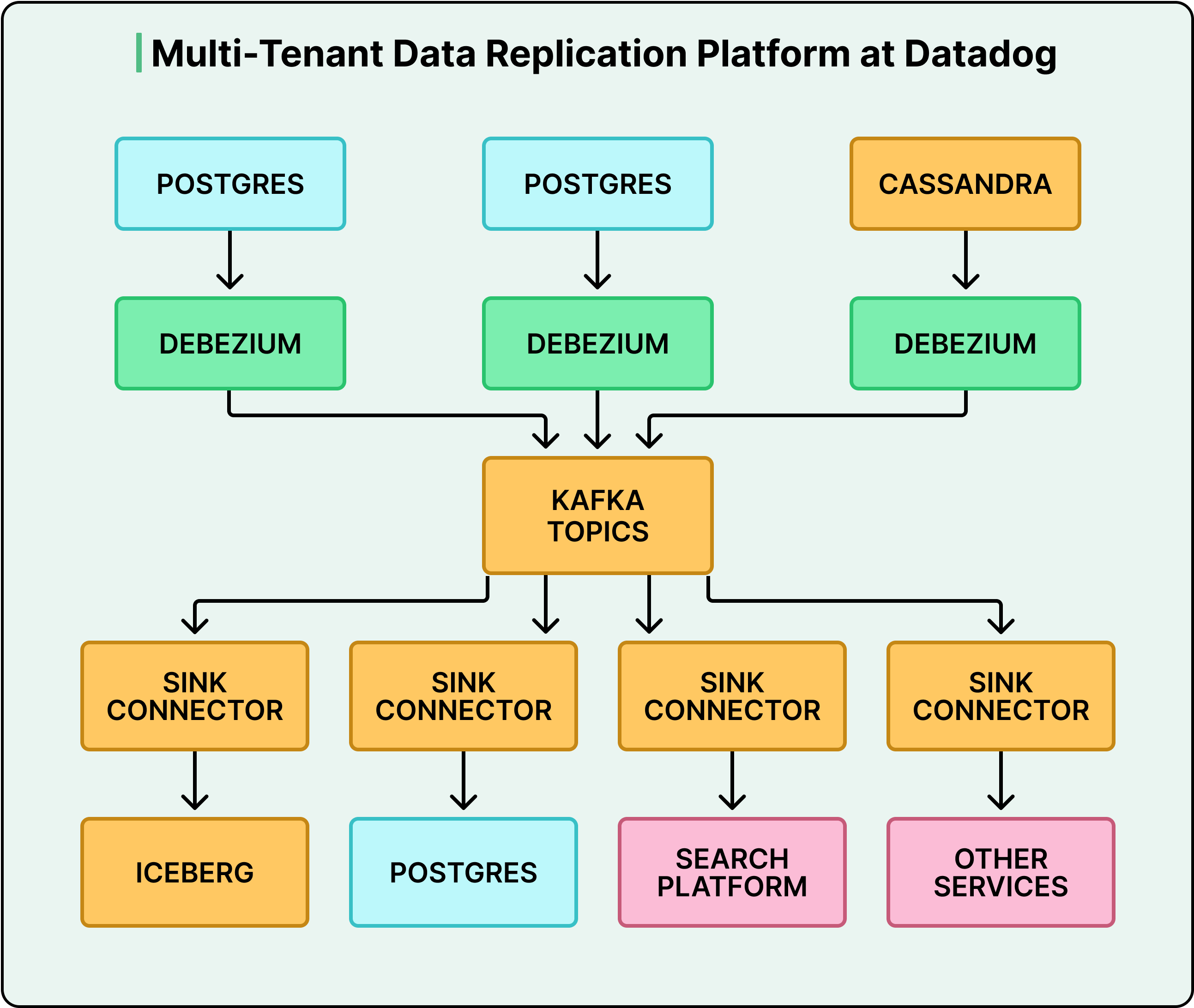
Đây là điều đã biến một bản sửa lỗi đơn lẻ thành một khả năng trên toàn công ty. Điều bắt đầu là "nhân bản bảng Postgres duy nhất này sang một công cụ tìm kiếm" đã mở rộng ra sao chép Postgres-sang-Postgres để phân rã cơ sở dữ liệu nguyên khối dùng chung lớn của họ, các pipeline Postgres-sang-Iceberg cho phân tích dựa trên sự kiện, sao chép Cassandra để hỗ trợ các nguồn dữ liệu phi SQL và sao chép Kafka giữa các vùng để cải thiện khả năng định vị dữ liệu cho các sản phẩm như Datadog On-Call.
Xem sơ đồ bên dưới:
Kết luận
Mỗi lựa chọn kiến trúc mà Datadog đưa ra đều đi kèm với một cái giá:
Nhân bản bất đồng bộ có nghĩa là các hệ thống hạ nguồn luôn chậm hơn một chút so với nguồn.
Các ràng buộc về tiến hóa lược đồ có nghĩa là bạn không thể tùy ý thay đổi cơ sở dữ liệu của mình mà không xem xét đến pipeline.
Bản thân cơ sở hạ tầng (Debezium, Kafka, Schema Registry, Temporal) đại diện cho rất nhiều bộ phận chuyển động cần vận hành, giám sát và bảo trì.
Cuối cùng, việc xây dựng tất cả những điều này thành một nền tảng đòi hỏi một đội ngũ chuyên trách để sở hữu nó.
Cách tiếp cận này hợp lý khi bạn có các khối lượng công việc thực sự không thuộc về cơ sở dữ liệu chính của bạn, khi nhiều nhóm cần cùng dữ liệu với các hình dạng khác nhau và khi quy mô của bạn khiến việc quản lý pipeline thủ công trở nên không thể chấp nhận được. Datadog đã đáp ứng cả ba tiêu chí. Tuy nhiên, nếu bạn chỉ có một vài luồng dữ liệu đơn giản, thì chi phí overhead là không cần thiết. Một bản đồng bộ hóa theo lô định kỳ hoặc một bản sao đọc đơn giản có thể là tất cả những gì bạn cần. Không phải mọi vấn đề đều cần một nền tảng.
Tài liệu tham khảo:
Tác giả: ByteByteGo