Mã của tôi phức tạp đến mức nào?
How Complex is my Code?
Bài viết này định nghĩa lại khái niệm "độ phức tạp của code" (code complexity) theo một cách tiếp cận mới, vượt xa phạm vi của Big O notation hay cyclomatic complexity truyền thống. Thay vì chỉ tập trung vào hiệu năng tính toán, tác giả nhấn mạnh rằng nguồn lực tinh thần (mental resources) mà lập trình viên phải bỏ ra để hiểu và bảo trì phần mềm cũng quan trọng không kém. Dù hiệu năng thuật toán vẫn là yếu tố sống còn, tác giả lập luận rằng "tải trọng nhận thức" (cognitive load) mà code gây ra thường bị xem nhẹ trong quá trình phát triển. Do đó, các kỹ sư cần nhìn nhận độ phức tạp dưới nhiều khía cạnh khác nhau thay vì chỉ tối ưu hóa các con số. Mục tiêu là tạo ra sự cân bằng giữa hiệu suất thực thi, tính dễ đọc và sự rõ ràng trong kiến trúc. Bằng cách kết hợp giữa tối ưu thuật toán và tư duy về tâm lý học ngôn ngữ lập trình (psycholinguistics of code), đội ngũ phát triển có thể xây dựng các hệ thống không chỉ mạnh mẽ về hiệu năng mà còn dễ bảo trì, dễ suy luận và ít lỗi hơn trong dài hạn.
Độ phức tạp của mã có thể có nghĩa là gì — từ ký hiệu Big O và Sự phức tạp theo chu kỳ đến mức đáng ngạc nhiên những hiểu biết sâu sắc mà ngôn ngữ học tâm lý có thể cung cấp cho các nhà phát triển phần mềm.
4 Tháng 4 năm 2026·12 phút
Độ phức tạp của mã có thể có nghĩa là gì — từ ký hiệu Big O và Sự phức tạp theo chu kỳ đến mức đáng ngạc nhiên những hiểu biết sâu sắc mà ngôn ngữ học tâm lý có thể cung cấp cho các nhà phát triển phần mềm.
Độ phức tạp là gì? #
“Độ phức tạp của thuật toán là lượng tài nguyên cần thiết để chạy thuật toán đó.”
(Wikipedia Định nghĩa)
Với định nghĩa này, có rất nhiều định nghĩa về Tài nguyên người ta có thể hãy nghĩ về khía cạnh mã đang chạy: ký ức cần thiết, thời gian cần thiết, nguồn lực tinh thần để hiểu mã, nguồn lực tinh thần cần thiết để hiểu mã vấn đề, kiến thức ngữ cảnh để hiểu cách mã giải quyết nó - tất cả đều là những cách giải thích hợp lý về tài nguyên cần thiết để chạy mã.
Độ phức tạp tính toán #
Tôi đã có nhiều bài giảng ở trường đại học điều đó hướng đến câu hỏi "mã này phức tạp đến mức nào?". Bắt đầu với định nghĩa chính thức về một vấn đề, cách các chương trình có thể được mô hình hóa để hiểu được tài nguyên của chúng, với thực tế tính toán mức độ sử dụng tài nguyên (thời gian hoặc bộ nhớ) tăng lên khi kích thước đầu vào tăng lên. Xem những chủ đề này như một phần mềm nhà phát triển và không còn là sinh viên khoa học máy tính, đôi khi tôi chỉ khám phá sơ qua những câu hỏi đó tại nơi làm việc.
Ví dụ: độ phức tạp về thời gian tính toán của mã này sẽ là O(n²), với n độ dài của danh sách.
Trong trường hợp xấu nhất của danh sách được sắp xếp ngược, điều này sẽ thực hiện, đối với mỗi phần tử trong số n phần tử của danh sách, n so sánh với
cái khác liệt kê các phần tử và sau đó n lần hoán đổi.
def insertion_sort(mảng: danh sách[int]) -> danh sách[int]:
cho chỉ mục trong phạm vi(1, len(mảng)):
hiện tại = mảng[chỉ mục]
người tiền nhiệm = chỉ mục - 1
while người tiền nhiệm >= 0 và mảng[tiền thân] > hiện tại:
mảng[tiền nhiệm + 1] = mảng[mảng tiền nhiệm]
tiền thân -= 1
mảng[tiền nhiệm + 1] = hiện tại
trở lại mảng
Một cách triển khai khác để giải quyết cùng một vấn đề có thể khác nhau về độ phức tạp tính toán. Sắp xếp bằng cách tạo bản đồ
Ví dụ: tất cả các giá trị có thể có trong danh sách phía trước sẽ nhanh hơn với O(n). Việc triển khai này trước tiên sẽ
cần O(n) để tìm mức tối đa, sau đó O(n) để lặp qua các giá trị và đặt chúng vào mảng đếm và
lại O(k) để xây dựng kết quả, trong đó k là cao nhất giá trị.
def counting_sort(mảng: danh sách[int]) -> danh sách[int]:
đếm = [0] * (max(mảng) + 1)
cho hiện tại ở mảng:
count[current] += 1
kết quả =
cho hiện tại, tần số trong liệt kê(count):
kết quả.extend([current] * tần số)
trở lại kết quả
Việc phân tích số lượng thao tác mà một thuật toán có thể thực hiện đã đưa ra gợi ý rằng thuật toán thứ hai có thể
có hiệu suất cao hơn. Nhưng trong trường hợp này, nó đặt ra câu hỏi: với giá nào? Chức năng đầu tiên rất dễ sử dụng
hiểu, vì nó phản ánh số lượng người sắp xếp theo trực giác — chỉ cần bắt đầu từ một và đặt từng phần tử tiếp theo vào vị trí của nó
trong
đã sắp xếp một phần của mảng. Điều thứ hai khó hiểu hơn: nó tạo ra một danh sách phụ thuộc vào mức tối đa
giá trị này có thể lớn không cần thiết đối với danh sách như [4500, 9000, 7200] và bị hạn chế vì giá trị âm
không thể sắp xếp các số.
Đối với nhà phát triển phần mềm, chỉ cần chọn thuật toán có độ phức tạp tính toán thấp hơn có thể dẫn đến dạng phức tạp khác nhau, không tiêu tốn tài nguyên thời gian tính toán mà thêm thời gian để hiểu chức năng, thời gian để ghi lại và thông báo các hạn chế cũng như thời gian khắc phục sự cố nếu ai đó sử dụng sai bộ số.
Độ phức tạp của mã miền #
Tôi xác định công việc của mình là viết mã miền/doanh nghiệp. Đối với tôi, thời gian tính toán và bộ nhớ máy tính là nguồn tài nguyên rẻ tiền so với thời gian suy nghĩ và trí nhớ của con người. 50 biến khởi tạo là một vấn đề, không phải vì biến ảo Máy AWS Tôi gặp khó khăn khi chạy mã của mình nhưng vì nhà phát triển cần phải dành hàng giờ mỗi lần họ đọc để hiểu lý do đằng sau 50 biến.
Vì vậy, tôi hỏi, làm cách nào để đo lường mức độ phức tạp của mã của tôi đối với con người?
Chắc chắn, dòng mã là sự đơn giản hóa của độ phức tạp — mọi người đều biết rằng nhiều dòng có thể bực bội, nhưng thậm chí hai dòng có thể ẩn đủ độ phức tạp để khiến một dòng bị chiếm dụng trong nhiều giờ.
Độ phức tạp theo chu kỳ #
Độ phức tạp theo chu kỳ đếm số lượng đường dẫn độc lập tuyến tính thông qua mã — tức là số lượng đường dẫn nếu,
cho, while và case nhánh (cộng 1 cho khai báo phương pháp).
Có nghiên cứu chắc chắn cho thấy mối tương quan giữa Độ phức tạp theo chu kỳ cao và mật độ lỗi. Một bản đồ nhiệt trên kho lưu trữ cũng có thể xác định lý do tại sao các mô-đun có độ phức tạp cao, điều này có thể rất tốt cho việc sắp xếp lại mức độ ưu tiên. Một chức năng có độ phức tạp cao rất có thể sẽ làm được nhiều việc hơn mức cần thiết và có thể hưởng lợi từ việc ủy quyền một số nhiệm vụ của nó. trách nhiệm. Nó cũng cung cấp một cơ sở tốt để ước tính số lượng thử nghiệm cần thiết để thực hiện một chức năng, liên quan đến nó. số lượng đường dẫn thực thi.
Độ phức tạp theo chu kỳ của cả insertion_sort và counting_sort là 3 - cả hai đều có hai vòng lặp + 1. Đối với điều này
ví dụ, cả hai cách triển khai dường như có cùng độ phức tạp. Nó không nắm bắt được ngữ nghĩa
độ phức tạp, kiến thức nền tảng hoặc những hạn chế không trực quan.
Halstead Độ phức tạp #
Halstead Độ phức tạp tuân theo ý tưởng rằng nỗ lực tinh thần tăng theo số lượng khái niệm riêng biệt mà bạn cần nắm giữ
bộ nhớ làm việc. Halstead lập luận rằng để hiểu một chương trình, bạn cần học từng toán tử riêng biệt và trung bình
bạn cần gặp người điều hành hai lần để tìm hiểu nó (một lần gặp nó, một lần để xác nhận). Một chương trình khó hơn
để hiểu các toán hạng khác biệt hơn (mảng, current, …) nó hiếm khi được sử dụng lại và
các toán tử khác biệt hơn (cho, +, =, …) nó có.
HALSTEAD_LEARNING_CONSTANT = 2
# Sự đa dạng của các toán tử và toán hạng tạo nên một hàm phức tạp
halstead_difficulty = (distinct_operator_count / HALSTEAD_LEARNING_CONSTANT) * (total_operands / distinct_operand_count)
# Các bit cần thiết để mã hóa hàm
halstead_volume = (total_operands + total_operands) * log_2(distinct_operator_count + distinct_operand_count)
# nỗ lực tinh thần ước tính
halstead_cognitive_complexity = halstead_difficulty * halstead_volume
Điều này cho kết quả là counting_sort ít khó hơn và mặc dù có âm lượng cao hơn nhưng lại kém về mặt nhận thức hơn
phức tạp.
# Insert_sort
halstead_difficulty = (12 / 2) * (24 / 6) = 6 * 4 = 24
halstead_volume = 46 × log₂(18) = 46 × 4,17 = 192
# count_sort
halstead_difficulty = (13 / 2) × (27 / 10) = 6,5 × 2,7 = 17,6
halstead_volume = 51 × log₂(23) = 51 × 4,52 = 230
Mặc dù đây là một phép đo rất thú vị về mức độ phức tạp về mặt tinh thần nhưng Halstead lại đo lường mật độ tái sử dụng mã thông báo chứ không phải về mặt khái niệm khó khăn. Càng nghĩ lâu về câu hỏi này, tôi càng nghĩ câu trả lời không nằm ở khoa học máy tính mà nằm ở ngôn ngữ học.
Độ phức tạp về ngôn ngữ #
Tâm lý học nghiên cứu cách con người xử lý ngôn ngữ và đã xác định một số yếu tố dự đoán đáng tin cậy về khả năng đọc độ khó:
- Quen thuộc các từ đã biết được xử lý nhanh hơn hơn những cái chưa biết. Mã tương đương là liệu một mẫu (như
sắp xếp một mảng theo cách trực quan) được nhận dạng ngay lập tức hoặc yêu cầu giải mã. Trình độ kỹ năng cũng
vấn đề ở đây là vì các mẫu lập trình hoặc thậm chí các khái niệm mới như câu lệnh
matchcó thể xa lạ với các cá nhân. - Tải bộ nhớ làm việc câu (và hàm) có nhiều mệnh đề lồng nhau sẽ khó hơn vì bạn phải giữ cấu trúc chưa được giải quyết trong đầu. Văn bản
- Mạch lạc sẽ dễ dàng hơn khi mỗi câu kết nối rõ ràng với cái trước đó. Trong mã, điều này có thể liên quan đến khoảng cách giữa việc khai báo biến và cách sử dụng nó, cũng như việc liệu mục tiêu của hàm có được đọc rõ ràng hay không suy nghĩ hoặc một mớ các phát biểu.
Đo lường độ phức tạp ngôn ngữ #
Ngay cả cái nhìn hời hợt về độ phức tạp ngôn ngữ so với độ phức tạp lập trình cũng cho thấy điểm chung tài sản. Trong lịch sử, cả hai dường như đã ảnh hưởng lẫn nhau. Ngôn ngữ tự nhiên truyền cảm hứng cho ngôn ngữ hình thức và ngữ pháp chính thức đã tạo thành cơ sở cho các trình biên dịch và ngược lại, các chương trình phức tạp như Cyclomatic Complexity cây phân tích đầy cảm hứng trong ngôn ngữ học; chỉ kể tên một trong nhiều ví dụ.
Chỉ số phụ Số lượng mệnh đề phụ, mỗi mệnh đề thêm một "nhánh" mới để phân tích cú pháp. “Nếu nó trời mưa, tôi sẽ ở trong nhà” có chỉ số phụ là 2 vì mệnh đề phụ “nếu trời mưa” ( có điều kiện). Ánh xạ điều này với khoa học máy tính, nó có cảm giác gần với Độ phức tạp theo chu kỳ, vì nó không đánh giá độ dài của câu, nhưng việc bổ sung một nhánh thông tin mới.
Khoảng cách phụ thuộc trung bình (MDD) Khoảng cách cú pháp trung bình giữa các từ và các từ của chúng thống đốc (người đứng đầu) trên tất cả
cặp phụ thuộc trong một câu hoặc văn bản. Trong ngữ pháp phụ thuộc, mỗi từ trong câu có thể phụ thuộc vào một từ khác
được gọi là thống đốc của nó. Thống đốc là từ mà người phụ thuộc thuộc về hoặc sửa đổi. Trong “Nếu trời mưa, tôi
sẽ ở trong nhà”, “nếu” và “nó” phụ thuộc vào “mưa” và mọi thứ khác đều phụ thuộc vào “ở lại”, điều này dẫn đến
MDD = (2+1+3+1+1+1) / 6 = 9/6 = 1,5.
Điều này làm tôi nhớ đến khoảng cách phạm vi thay đổi; số dòng giữa phần khai báo của một biến và cách sử dụng nó. Như trong
câu, hàm sẽ dễ đọc hơn khi các biến được xác định gần nơi chúng được sử dụng, so với việc thiết lập
trả trước mười biến rồi sử dụng chúng trên 20 dòng mã tiếp theo.
Lý thuyết địa phương phụ thuộc (DLT) Chi phí lưu trữ khi đọc một câu. Ý tưởng cốt lõi là chi phí xử lý của
đọc một câu xuất phát từ việc giữ các phần phụ thuộc không đầy đủ mở trong bộ nhớ làm việc - cụ thể là đếm số
của những tham chiếu diễn ngôn mới (đại khái là: danh từ/động từ) mà bạn bỏ qua trong khi chờ đóng phần phụ thuộc.
“Nếu trời mưa, tôi sẽ ở trong nhà” có hai từ giải quyết (“mưa”, “ở lại”) nên “I” và “will” cần được giữ trong
ký ức
cho đến khi một người đọc “ở lại” và quyết định bối cảnh hiện tại, trong khi “bên trong” chỉ gắn với “ở lại”.
Từ góc độ khoa học máy tính, việc “kết thúc” một ngữ cảnh sẽ phản ánh rõ nét sự sống động của một biến: làm thế nào
Trình biên dịch có cần nhiều dòng hoặc câu lệnh để theo dõi một biến cho đến khi nó vượt quá phạm vi không?
Đối với con người, tôi thấy việc so sánh nó với biểu đồ lệnh gọi của một hàm sẽ trực quan hơn - có bao nhiêu
Tôi phải ghi nhớ các lệnh gọi hàm chưa được giải quyết khi đọc một hàm? Một chức năng mà gọi n khác nhau
các hàm làm tăng độ phức tạp cho người đọc, những người có thể cần hiểu từng hàm đó và cũng giới thiệu
độ phức tạp của việc ghép nối, vì chức năng này yêu cầu kiến thức về hệ thống rộng hơn.
Tỷ lệ loại mã thông báo số lượng từ duy nhất chia cho tổng số từ, tương tự như từ vựng Halstead, vì Halstead được truyền cảm hứng từ những ý tưởng ngôn ngữ khi đang phát triển các số liệu về độ phức tạp của mình.
Entropy một từ hoặc âm thanh nhất định có trước đó bất ngờ đến mức nào? Một tuyên bố về nhận thức nói rằng việc đọc và hiểu quy mô thời gian một cách đáng ngạc nhiên. Nó đi kèm với khái niệm về sự bối rối - số lượng các khả năng xảy ra như nhau các lựa chọn thay thế để tiếp tục ở một vị trí nhất định trong văn bản hoặc mã. Theo kinh nghiệm, điều này được đo thông qua thời gian đọc của con người hoặc sử dụng LLM làm công cụ ước tính xác suất. Các nghiên cứu áp dụng điều này vào mã gặp khó khăn khi so sánh số liệu trên cả hai lĩnh vực - các lập trình viên không đọc theo cách tuyến tính mà chuyển từ hàm sang hàm gọi sang định nghĩa sang tham số cho hàm.
Độ phức tạp của ngôn ngữ tự nhiên Mô tả #
Vượt quá mức có thể đo lường cú pháp và cấu trúc, rất khó xác định độ phức tạp về mặt khái niệm của một văn bản hoặc hàm. một có thể cho rằng một chức năng cũng phức tạp như mô tả chức năng của chức năng đó bằng ngôn ngữ tự nhiên.
Điều này kết hợp bản đồ với lãnh thổ. Việc đo lường mô tả của một sự trừu tượng không nhất thiết phản ánh tải nhận thức của mã đối với nhà phát triển làm việc với nó. Một ví dụ nổi tiếng về điều gì đó mà các nhà phát triển có thể là có thể giải thích dễ dàng nhưng vẫn không thể dễ dàng hiểu được bằng mã là khái niệm về Đơn nguyên trong Haskell.
Thuật toán được mô tả dành cho đối tượng nào? Các quyết định kinh doanh được giải thích chi tiết như thế nào? Bằng biện pháp này,
là mô tả thuật toán cho công thức E = mc² đơn giản như “Năng lượng bằng khối lượng nhân với tốc độ ánh sáng
bình phương”, hoặc làm như vậy yêu cầu mô tả ngôn ngữ tự nhiên phức tạp hơn? Lượng kiến thức miền được mong đợi
của nhà phát triển việc đọc? Nếu có thể giả định được kiến thức sâu rộng về một chủ đề thì ngay cả mã “chất lượng thấp” cũng có thể có hiệu suất thấp.
nhận thấy sự phức tạp. Tôi đã từng có cơ hội đọc qua mật mã của một học giả địa vật lý trong đó một chữ cái
các biến và các hàm phức tạp, không được mô tả là đủ, giả sử người đọc đã quen với các yêu cầu
các công thức và định nghĩa địa vật lý (vốn được xác định bằng hằng số một ký tự).
Độ phức tạp về mặt nhận thức của một hàm chỉ có thể được xác định bởi người đọc và chỉ quan tâm đến người đọc có thể giúp người viết cải thiện trải nghiệm học tập.
Làm việc với Số liệu về độ phức tạp #
Tôi đã thử nghiệm các số liệu về độ phức tạp trên mã trong Sổ tay Jupyter này. Hãy thoải mái sử dụng mã cho các dự án của riêng bạn, nhưng xin lưu ý rằng đây là lần đầu tiên tôi làm việc với các cực và khung dữ liệu.
Có một số câu hỏi bạn có thể đặt ra khi diễn giải các chỉ số:
Tập hợp là độ phức tạp của mô-đun nó…
- tổng độ phức tạp của tất cả các chức năng, để hiểu được độ phức tạp tổng thể của một dự án? Rốt cuộc, một lớn hơn dự án phức tạp hơn một dự án nhỏ.
- độ phức tạp trung bình của tất cả các hàm, để hiểu được tình trạng tổng thể của dự án, bỏ qua các giá trị ngoại lệ?
- độ phức tạp tối đa của tất cả các hàm, để xác định các giá trị ngoại lệ cần được đơn giản hóa nhất?
An ví dụ về độ phức tạp được tổng hợp theo tối đa của khung công tác django codebase:
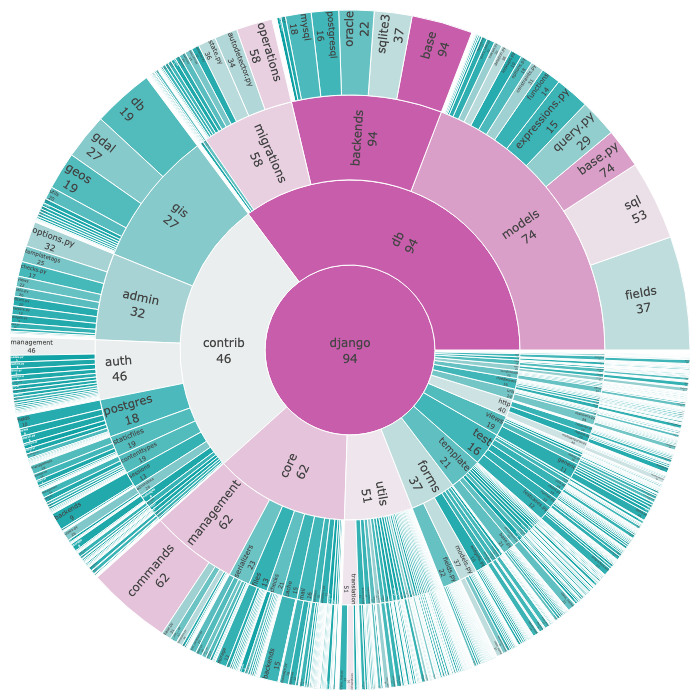
Kết hợp các số liệu có lẽ bản thân sự phức tạp không phải là vấn đề, nhưng đúng hơn là:
- Coupling là một tệp phức tạp, dễ tái cấu trúc vì tệp này không bao giờ được nhập và có thể thay đổi một cách an toàn không? Hoặc là nó được nhập rất thường xuyên và do đó phải ổn định và không có lỗi?
- Churn là một tệp phức tạp thay đổi thường xuyên, giới thiệu các lỗi, như vậy việc đơn giản hóa nó sẽ mang lại một trải nghiệm tuyệt vời đạt được? Hay nó không quan trọng vì nó không bao giờ được chạm vào? Hoặc nó phức tạp đến mức không ai dám chạm vào nó?
Một ví dụ về độ phức tạp kết hợp với sự rời rạc và sự ghép nối hướng tâm của cơ sở mã khung django:
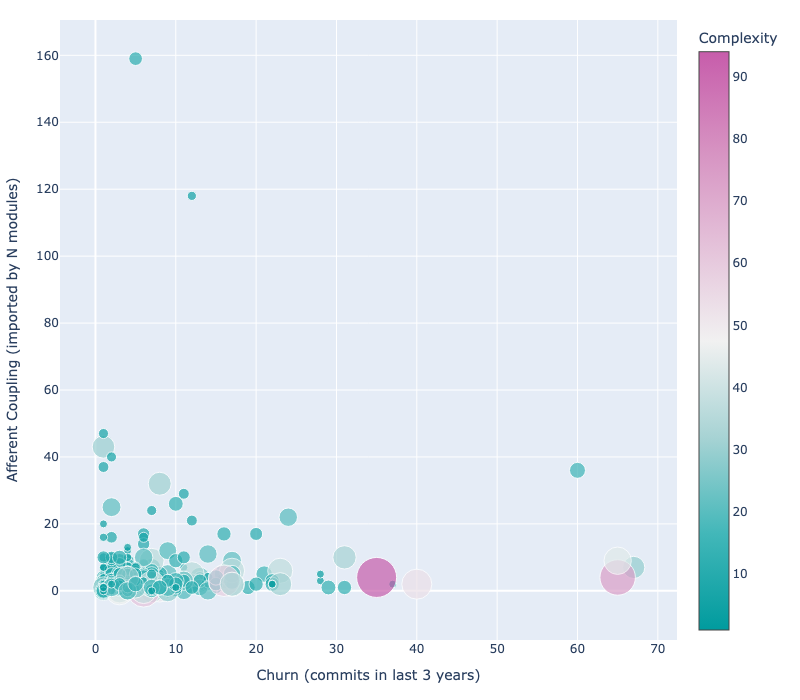
Giống như tất cả các biểu đồ (như đã thảo luận) trong bài đăng này về Giao tiếp Mẫu), một biểu đồ nên kể một câu chuyện. Việc xem xét các số liệu rất thú vị nhưng nó phụ thuộc rất nhiều vào dự án của bạn. mà, sự phức tạp thực sự là một vấn đề. Những gì các biểu đồ như vậy có thể làm một cách đáng tin cậy là cung cấp hình ảnh trực quan cho các vấn đề phi kỹ thuật. các bên liên quan và làm cơ sở cho các cuộc trò chuyện về nhu cầu tái cấu trúc hoặc nợ kỹ thuật, cho phép các bên khác xác định khu vực có vấn đề của cơ sở mã hoặc để chứng minh sự thành công của bộ tái cấu trúc với phần trước và sau phân tích.
Các số liệu phức tạp, giống như tất cả các số liệu khác, đều là một công cụ. Nếu các nhà phát triển buộc phải cải thiện chúng, điều đó sẽ không giúp ích gì cho cơ sở mã. Nhưng nếu chúng được sử dụng để thúc đẩy việc ra quyết định dựa trên dữ liệu và thuyết phục các nhà quản lý bằng hình ảnh trực quan rõ ràng việc tái cấu trúc đó có tác động có thể đo lường được nên chúng có thể trợ giúp rất nhiều.
Happy Coding :)
Tác giả: speckx