GIẺ đặc vụ hoạt động như thế nào?
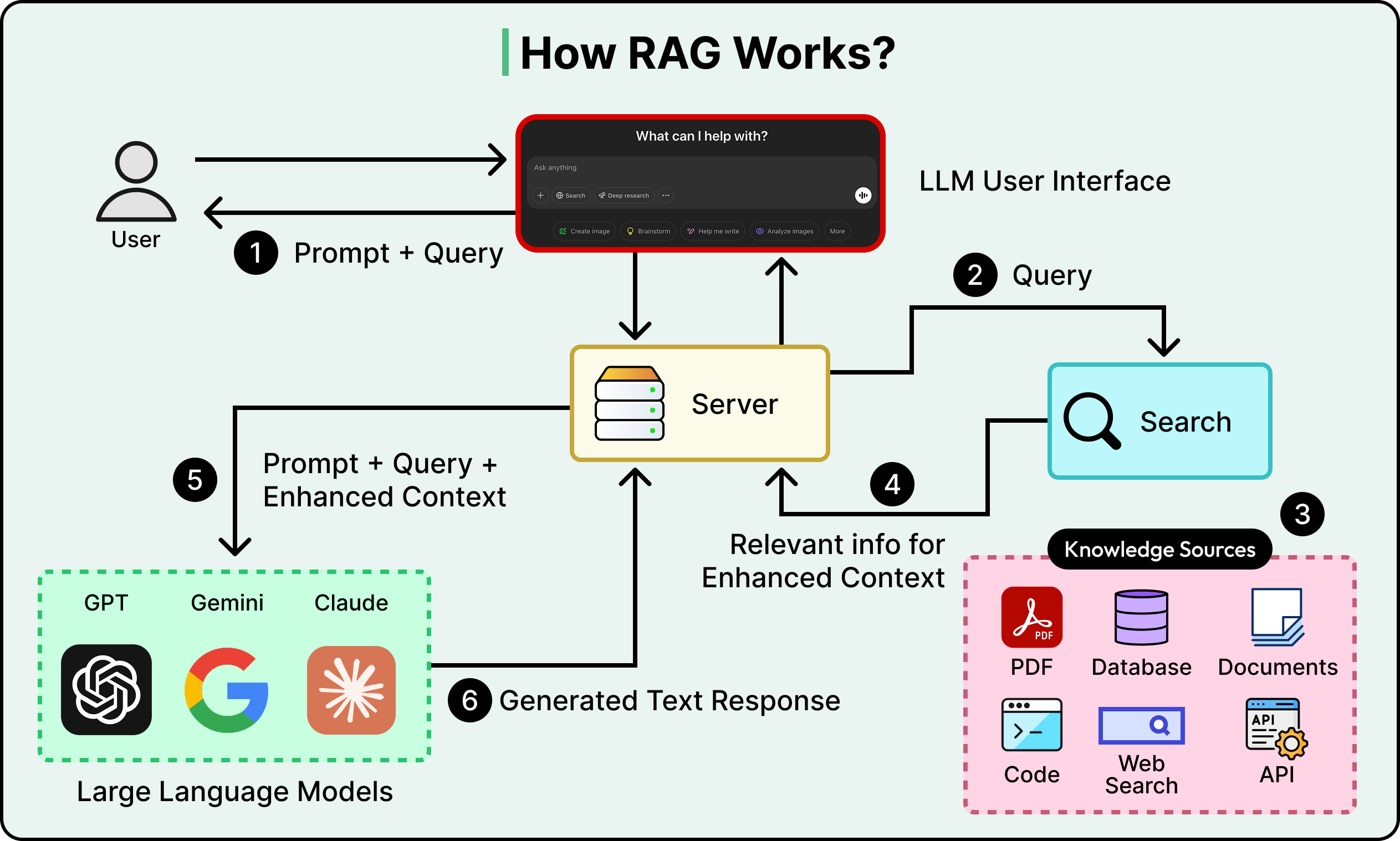
How Agentic RAG Works?
Bài viết bàn về "thuế vận tốc" trong phát triển AI, nơi các đội nhóm dành khoảng 25% thời gian để sửa lỗi và bảo mật code do AI tạo ra. Chi phí ẩn này cho thấy dù các công cụ AI giúp tăng tốc quá trình sinh code ban đầu, việc gỡ lỗi và kiểm tra bảo mật sau đó lại phát sinh chi phí đáng kể. Các developer cần nhận thức rằng việc code có sự hỗ trợ của AI đòi hỏi quá trình kiểm tra và tinh chỉnh cẩn thận sau khi code được tạo ra, và cần tính toán điều này vào tiến độ dự án cũng như phân bổ nguồn lực.
Trong bài viết này, chúng ta sẽ xem xét cách thức hoạt động của GIẺ đại lý, cách nó cải thiện so với GIẺ tiêu chuẩn và sự đánh đổi cần được xem xét.
Thực tế ẩn giấu của phát triển do AI thúc đẩy (Được tài trợ)

Có một khoản "thuế vận tốc" mới trong phát triển phần mềm. Khi việc áp dụng AI ngày càng tăng, nhóm của bạn không nhất thiết phải làm ít hơn - họ dành 25% thời gian trong tuần để sửa chữa và bảo mật mã được tạo bởi AI. Chi phí ẩn này tạo ra một nút thắt cổ chai xác minh làm đình trệ sự đổi mới. Sonar cung cấp khả năng phân tích đáng tin cậy, tự động cần thiết để thu hẹp khoảng cách giữa tốc độ của AI và chất lượng đạt chuẩn sản xuất.
Vấn đề chính với các hệ thống RAG tiêu chuẩn không nằm ở việc truy xuất hay tạo sinh. Vấn đề là không có gì ở giữa quyết định xem việc truy xuất có đủ tốt hay không trước khi quá trình tạo sinh diễn ra.
RAG tiêu chuẩn là một quy trình mà thông tin chảy theo một chiều, từ truy vấn đến truy xuất đến phản hồi, không có điểm kiểm tra và không có cơ hội thứ hai. Điều này hoạt động tốt cho các câu hỏi đơn giản với câu trả lời rõ ràng.
Tuy nhiên, ngay khi một truy vấn trở nên mơ hồ, hoặc câu trả lời được trải rộng trên nhiều tài liệu, hoặc truy xuất đầu tiên trả về thứ gì đó có vẻ tốt nhưng thực tế không phải vậy, RAG bắt đầu mất đi giá trị.
Agentic RAG cố gắng khắc phục vấn đề này. Nó dựa trên một câu hỏi duy nhất: điều gì sẽ xảy ra nếu hệ thống có thể tạm dừng và suy nghĩ trước khi trả lời?
Trong bài viết này, chúng ta sẽ xem xét cách agentic RAG hoạt động, cách nó cải thiện so với RAG tiêu chuẩn và những đánh đổi cần được xem xét.
Một truy vấn và một lần truy xuất
Để hiểu Agentic RAG khắc phục điều gì, chúng ta cần làm rõ cách RAG tiêu chuẩn hoạt động và những hạn chế của nó.
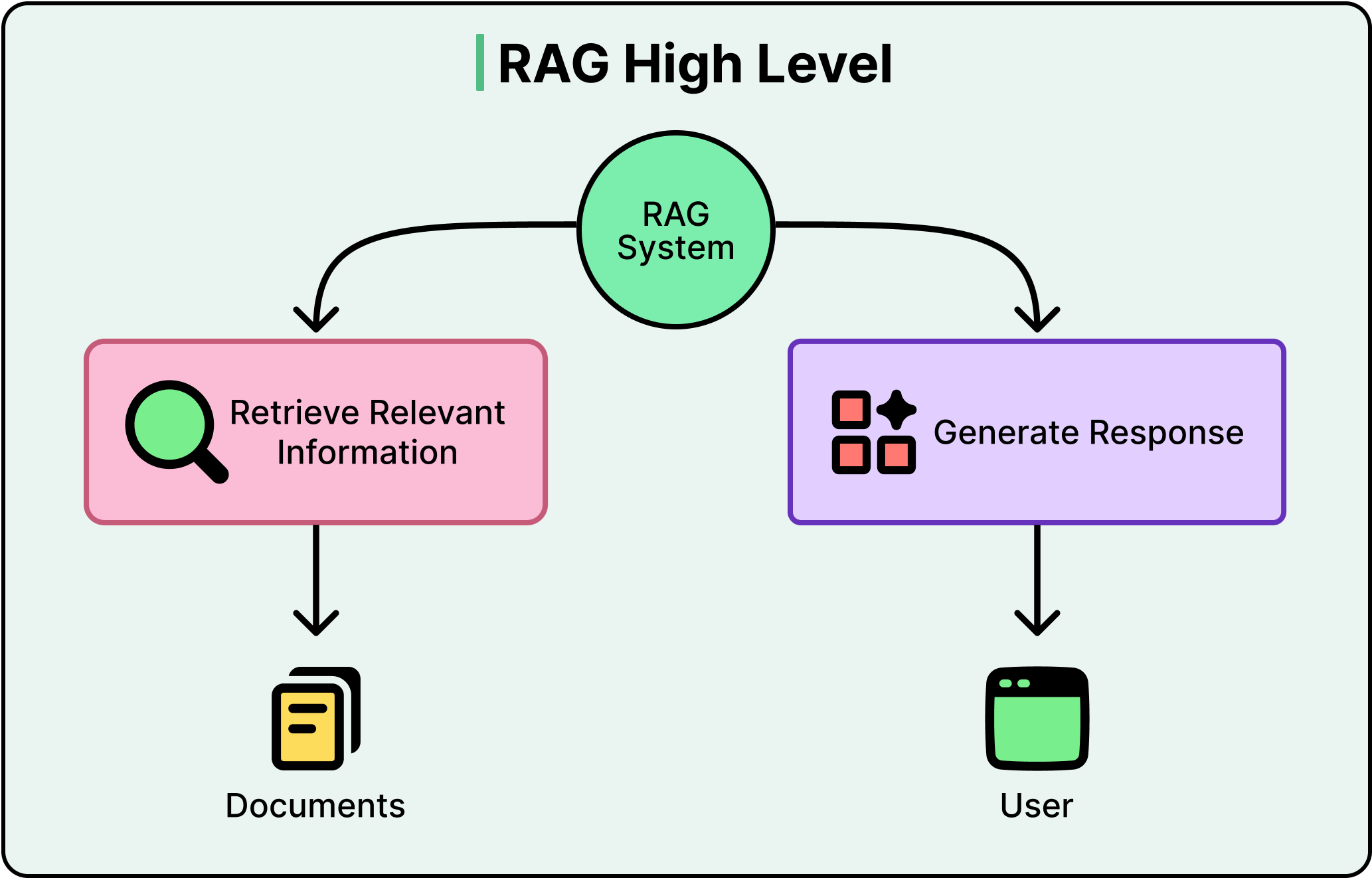
Một quy trình RAG tiêu chuẩn có luồng công việc đơn giản:
Người dùng đặt một câu hỏi.
Hệ thống chuyển đổi câu hỏi đó thành một biểu diễn số được gọi là embedding, nó nắm bắt ý nghĩa ngữ nghĩa của truy vấn.
Sau đó, nó tìm kiếm trong cơ sở dữ liệu vector, một cơ sở dữ liệu được tối ưu hóa để tìm nội dung có ý nghĩa tương tự, và truy xuất các đoạn văn bản khớp nhất.
Các đoạn văn bản đó được chuyển đến một mô hình ngôn ngữ lớn cùng với câu hỏi ban đầu, và LLM tạo ra câu trả lời dựa trên ngữ cảnh được truy xuất.
Xem sơ đồ bên dưới:
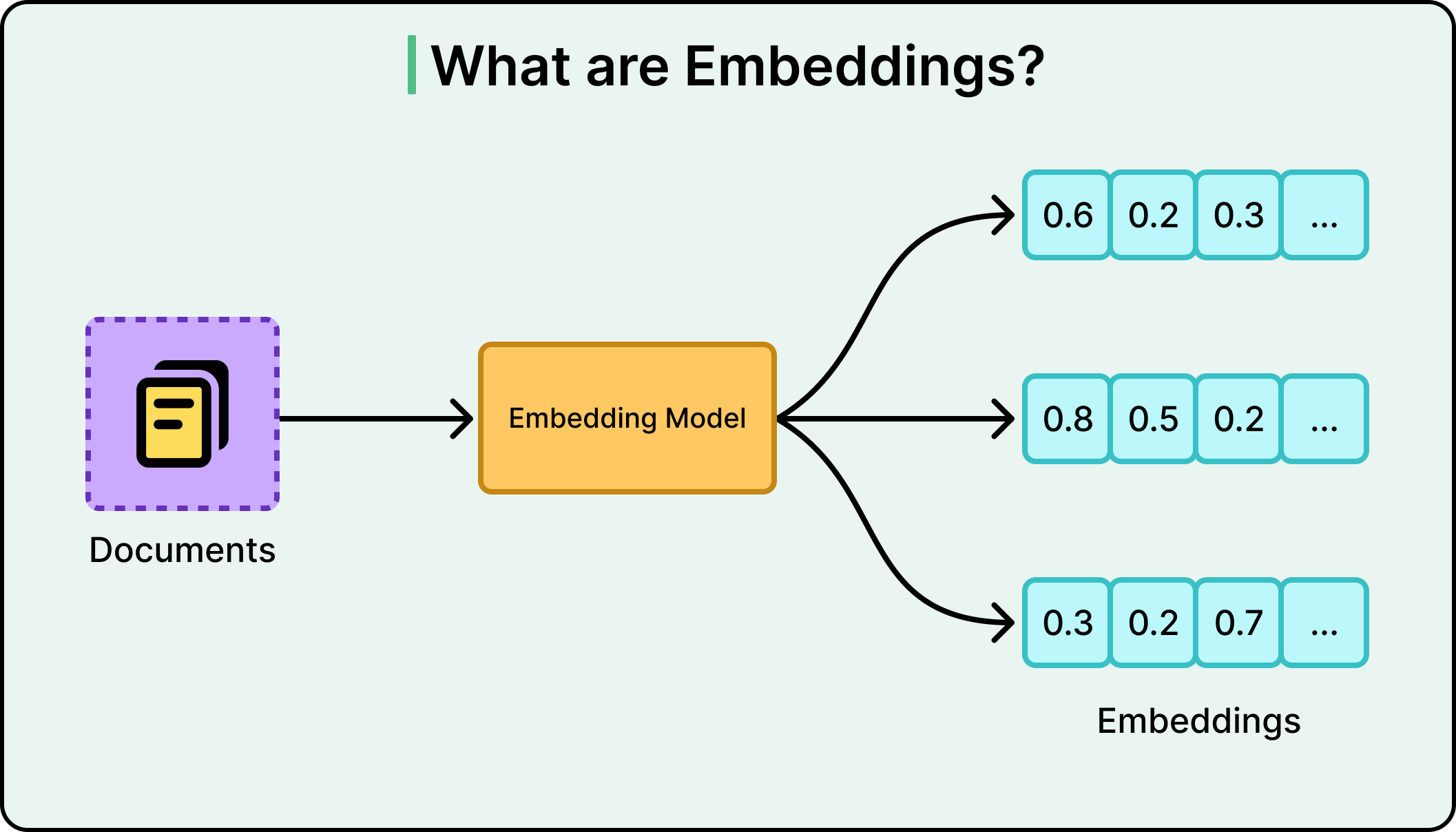
Sơ đồ dưới đây cho thấy các embedding thường trông như thế nào:
Điều này hoạt động cực kỳ tốt cho các câu hỏi trực tiếp và rõ ràng đối với cơ sở kiến thức được tổ chức tốt. Hãy nghĩ đến các câu hỏi như "Chính sách hoàn trả của chúng tôi là gì?" Một kho tài liệu sạch sẽ gần như luôn nhận được câu trả lời chắc chắn.
Đây là cách luồng truy vấn điển hình:
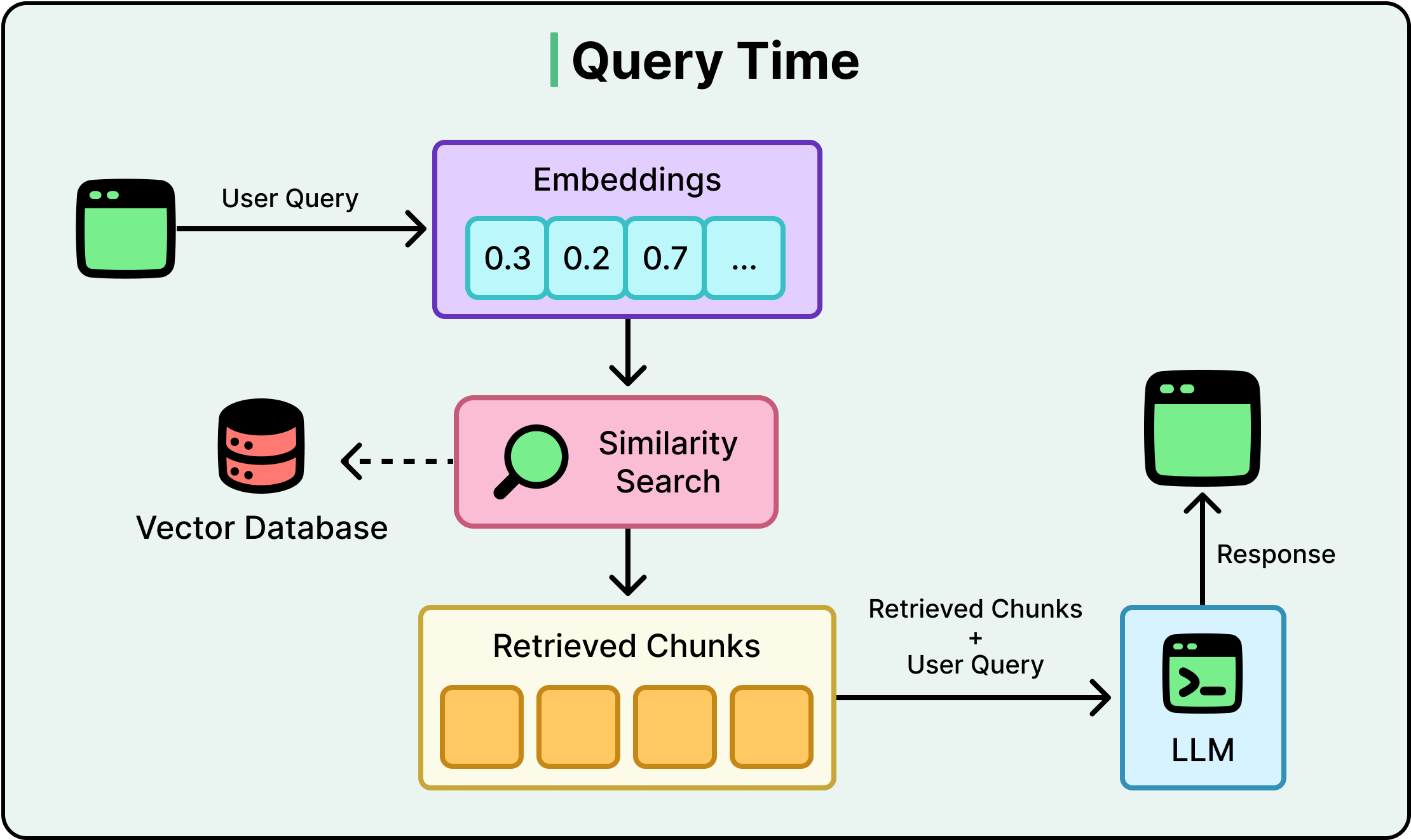
Các vấn đề phát sinh khi các truy vấn trở nên phức tạp hơn. Dưới đây là một vài kịch bản:
Truy vấn không rõ ràng: Khi người dùng hỏi "Tôi nên xử lý thuế như thế nào?", họ có thể có ý nói về thuế thu nhập cá nhân, thuế doanh nghiệp hay tình trạng miễn thuế cho một tổ chức phi lợi nhuận. RAG tiêu chuẩn không thể làm rõ hoặc viết lại. Nó lấy truy vấn như hiện tại, truy xuất bất cứ thứ gì có điểm tương đồng cao nhất và hy vọng vào điều tốt nhất.
Bằng chứng phân tán: Đôi khi câu trả lời nằm rải rác trên nhiều tài liệu. Một nhân viên hỏi "Chính sách làm việc từ xa đối với nhà thầu là gì?" cần thông tin từ cả chính sách làm việc từ xa và thỏa thuận nhà thầu. RAG tiêu chuẩn thường truy xuất từ một nhóm các đoạn văn và không có khái niệm kiểm tra nguồn thứ hai nếu nguồn đầu tiên thiếu sót.
Sự tự tin sai lầm: Quá trình truy xuất trả về một cái gì đó có vẻ liên quan dựa trên điểm số tương đồng, nhưng thực sự không trả lời được câu hỏi. Có thể nó đúng về chủ đề, nhưng lại từ một phiên bản lỗi thời của tài liệu. Hệ thống không có cơ chế để phân biệt giữa "liên quan" và "thực sự đúng". Nó sẽ tạo ra một phản hồi tự tin trong cả hai trường hợp.
Ba chế độ lỗi này có chung nguyên nhân gốc rễ. Hệ thống không phản ánh những gì nó đã truy xuất. Nó không thể tự hỏi liệu kết quả có đủ tốt hay không.
Các công ty AI không cào dữ liệu Google (Tài trợ)

Họ đang sử dụng SerpApi: API Tìm kiếm Web tiêu chuẩn ngành, chia sẻ quyền truy cập vào các công cụ tìm kiếm với một API đơn giản. Được tin dùng bởi Uber, NVIDIA và nhiều hơn nữa. Bắt đầu với 250 tín dụng miễn phí/tháng.
Từ Pipeline đến Vòng lặp Điều khiển
Agentic RAG thay thế pipeline tuyến tính đó bằng một vòng lặp bằng cách đưa các khả năng của tác tử AI vào cuộc.
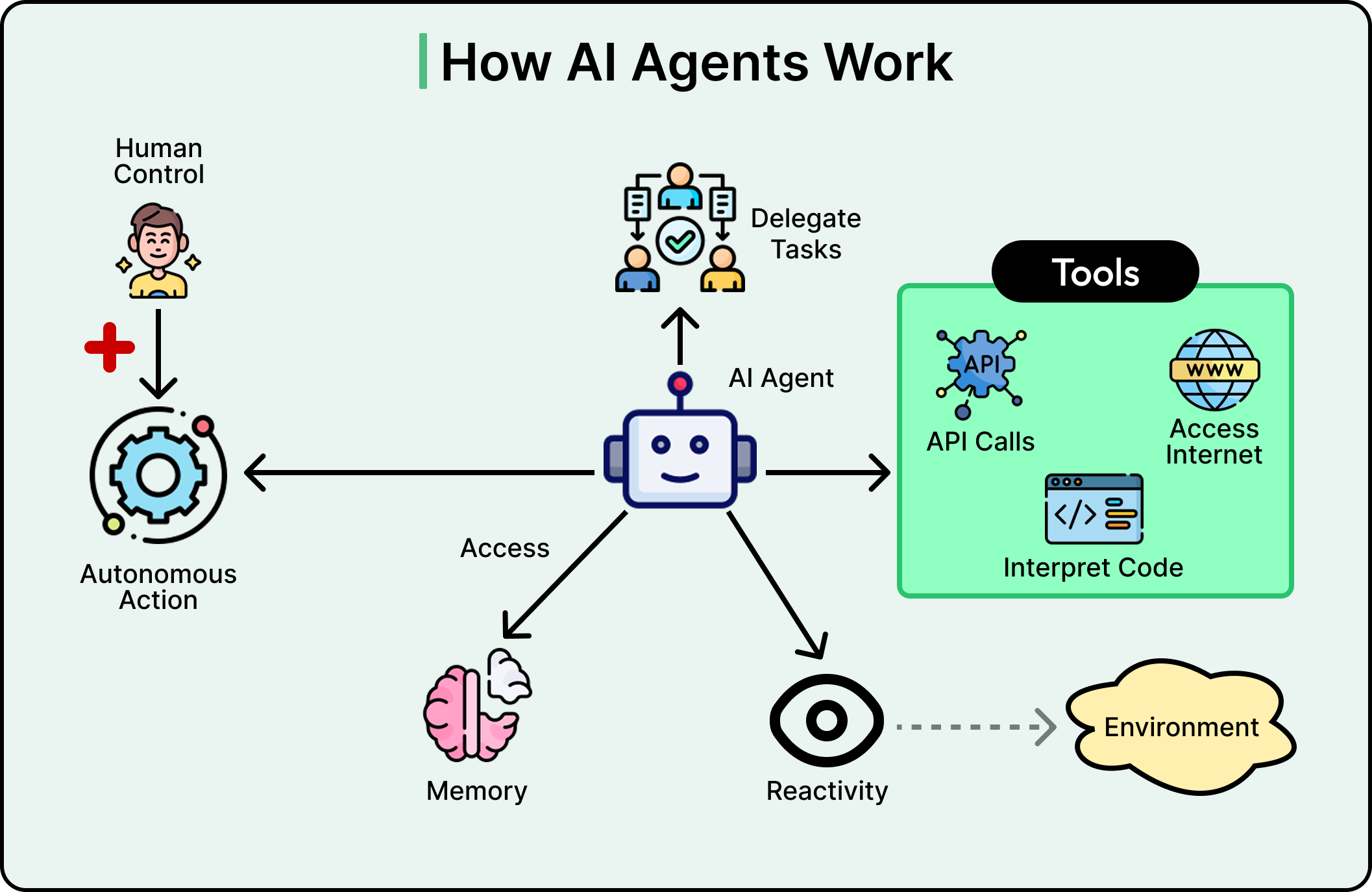
Cốt lõi, một tác tử AI là một hệ thống phần mềm có thể nhận biết môi trường của nó, đưa ra quyết định và thực hiện hành động để đạt được các mục tiêu cụ thể với mức độ độc lập nhất định. Từ "tác tử" là chìa khóa ở đây. Giống như một đại lý du lịch hành động thay mặt chúng ta để tìm chuyến bay và thương lượng các giao dịch, một tác tử AI hành động thay mặt người dùng hoặc hệ thống để hoàn thành nhiệm vụ mà không cần hướng dẫn liên tục cho từng bước.
Xem sơ đồ dưới đây minh họa khái niệm về tác tử AI:
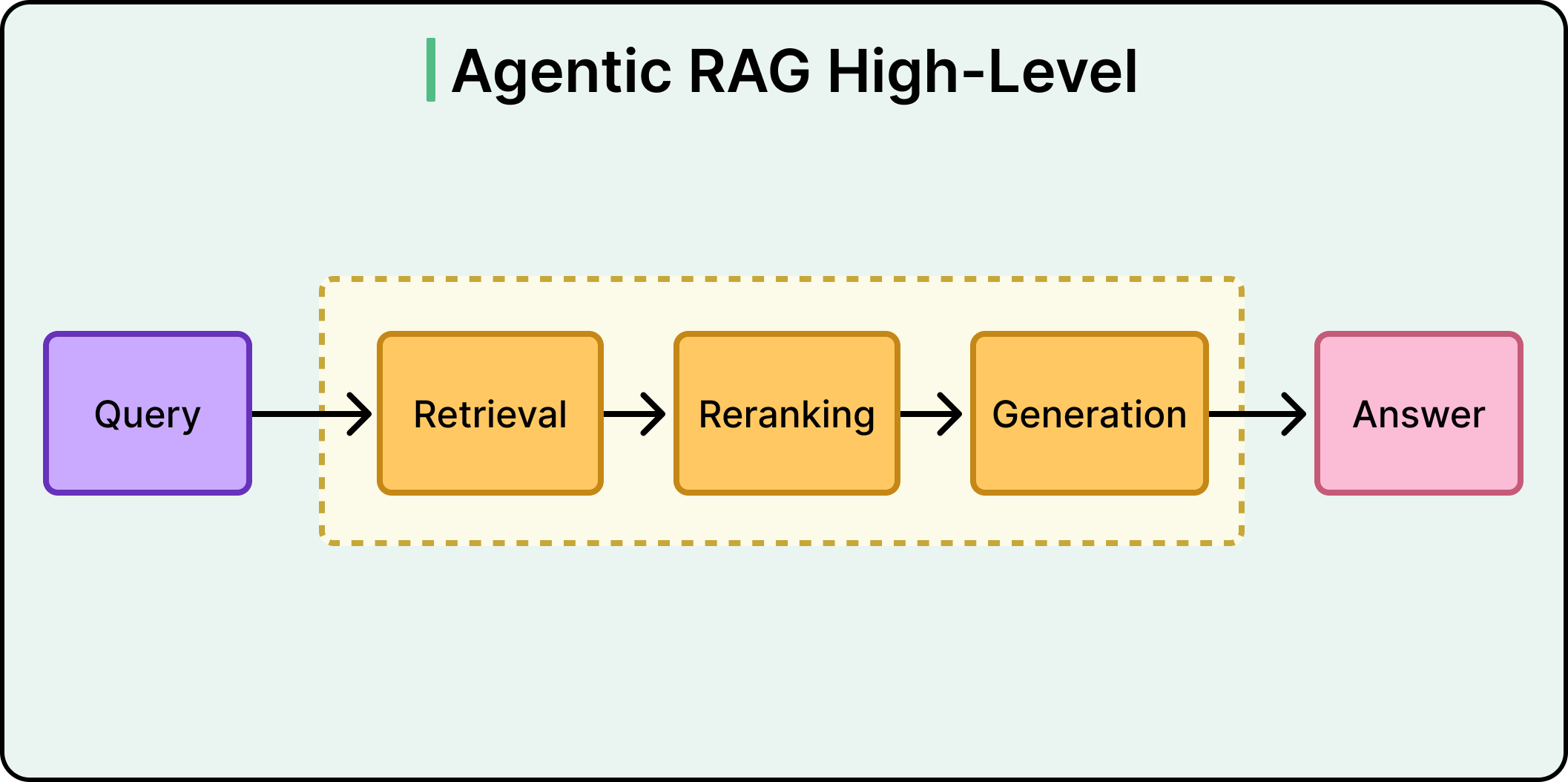
Trong Agentic RAG, thay vì truy xuất rồi mới sinh văn bản, quy trình trở thành: truy xuất, đánh giá kết quả, quyết định xem có nên trả lời hay thử lại, và nếu cần, truy xuất theo cách khác.
Xem sơ đồ bên dưới:
Tác giả: ByteByteGo