Phương trình Hamilton-Jacobi-Bellman: Mô hình học tập tăng cường và phổ biến
Hamilton-Jacobi-Bellman Equation: Reinforcement Learning and Diffusion Models
Bài viết này đi sâu vào mối liên hệ mật thiết giữa phương trình Hamilton-Jacobi-Bellman (HJB) và các kỹ thuật machine learning hiện đại, đặc biệt là reinforcement learning (RL) và diffusion models. Điểm nhấn là khung toán học cốt lõi cho optimal control và RL, có nguồn gốc từ công trình của Bellman những năm 1950, về mặt toán học lại tương đương với phương trình HJB được hình thành từ một thế kỷ trước trong lĩnh vực vật lý. Sự tương đương này cho thấy cách mà continuous-time RL, stochastic control và quá trình huấn luyện diffusion models đều có thể được xem như những trường hợp cụ thể của bài toán stochastic optimal control. Các developer có thể tận dụng sự thấu hiểu này để tìm ra những điểm song song giữa các thuật toán continuous-time RL và các nguyên lý nền tảng của diffusion models, từ đó mở ra những hướng tiếp cận mới cho cả hai lĩnh vực.
Học máy có vẻ mới mẻ, nhưng một trong những ý tưởng toán học cốt lõi của nó đã có từ năm 1952, khi Richard Bellman xuất bản một bài báo chuyên đề có tựa đề “Về lý thuyết lập trình động” [6, 7], đặt ra...

Học máy có vẻ mới xuất hiện, nhưng một trong những ý tưởng toán học cốt lõi của nó đã có từ năm 1952, khi Richard Bellman xuất bản một bài báo chuyên đề có tiêu đề “Về lý thuyết lập trình động” [6, 7] , đặt nền tảng cho khả năng kiểm soát tối ưu và cái mà ngày nay chúng ta gọi là học tăng cường.
Sau đó vào những năm 50, Bellman mở rộng công việc của mình sang các hệ thống thời gian liên tục, biến điều kiện tối ưu thành PDE. Sau này ông phát hiện ra rằng kết quả này giống hệt với một kết quả trong vật lý được công bố một thế kỷ trước (những năm 1840), được gọi là phương trình Hamilton-Jacobi.
Khi cấu trúc đó được nhìn thấy rõ ràng, một số chủ đề sẽ được sắp xếp một cách tự nhiên:
- học tăng cường theo thời gian liên tục
- điều khiển ngẫu nhiên
- mô hình khuếch tán
- vận chuyển tối ưu
Trong bài đăng này, tôi muốn hướng sự chú ý của chúng ta đến hai ứng dụng trong công việc của Bellman: học tăng cường theo thời gian liên tục và cách đào tạo các mô hình tổng quát (mô hình khuếch tán) có thể được diễn giải thông qua điều khiển tối ưu ngẫu nhiên
1. Giới thiệu
Bellman ban đầu xây dựng công thức lập trình động theo thời gian rời rạc vào đầu những năm 1950 [6, 7]. Hãy xem xét quy trình quyết định Markov với không gian trạng thái $\mathcal X$, không gian hành động $\mathcal A$, hạt nhân chuyển tiếp $P(\cdot\mid x,a)$, hàm thưởng $r(x,a)$ và hệ số chiết khấu $\gamma\in(0,1)$. Chính sách $\pi$ ánh xạ từng trạng thái tới một phân phối theo hành động. Nếu trạng thái phát triển thành chuỗi Markov được kiểm soát
$$ X_{n+1}\sim P(\cdot\mid X_n,a_n), $$
với phần thưởng một bước $r(x,a)$ và hệ số chiết khấu $\gamma\in(0,1)$, thì mục tiêu là
$$ J(\pi):=\mathbb E\left[\sum_{n=0}^\infty \gamma^n r(X_n,a_n)\right],\qquad a_n\sim \pi(\cdot\mid X_n), $$
và hàm giá trị được định nghĩa là:
$$ V(x):=\sup_\pi \mathbb E\left[\sum_{n=0}^\infty \gamma^n r(X_n,a_n)\,\middle|\,X_0=x\right]. $$
Trong điều kiện nhẹ, $V$ thỏa mãn phương trình Bellman
$$ V(x)=\max_{a\in\mathcal A}\left\{r(x,a)+\gamma\,\mathbb E \left[V(X_{n+1})\mid X_n=x,a_n=a\right]\right\}.\tag{Phương trình Bellman} $$
Điều này nói lên rằng: hãy chọn hành động tối đa hóa phần thưởng ngay lập tức cộng với giá trị tiếp theo. Thời gian liên tục giữ nguyên logic cục bộ, nhưng bây giờ bước thời gian có độ dài $h$ và chúng tôi gửi $h\downarrow 0$.
Để tách biệt ý chính, trước tiên hãy bỏ qua nhiễu và xem xét hệ thống kiểm soát xác định không tự trị
$$ \dot X_s = f(s,X_s,a_s),\qquad X_t=x, $$
với hàm giá trị chân trời hữu hạn
$$ V(t,x):=\sup_{a_\cdot}\left[\int_t^T r(s,X_s,a_s)\,ds+g(X_T)\,\middle|\,X_t=x\right]. $$
Định lý (HJB, tất định không tự trị). Với $V\in C^1$, hàm giá trị thỏa mãn
$$ > -\partial_t V(t,x) = H\bigl(t,x,\nabla_x V(t,x)\bigr), \tag{HJB} > $$trong đó Hamiltonian là $H(t,x,p):=\sup_{a\in\mathcal A}\left\{r(t,x,a)+p^\top f(t,x,a)\right\}$.
Bằng chứng. Sửa $(t,x)$ và $h>0$. Nguyên lý quy hoạch động mang lại
$$ V(t,x)=\sup_{a_\cdot}\left[\int_t^{t+h} r(s,X_s,a_s)\,ds + V(t+h,X_{t+h})\right]. $$
Để đặt hàng đầu tiên trong $h$, việc tối ưu hóa các hành động liên tục $a$ trên $[t,t+h]$ là đủ. Để có $V$ trơn tru và động lực xác định:
$$ V(t+h,X_{t+h})=V(t,x)+h\,\partial_t V(t,x)+h\,\nabla_x V(t,x)^\top f(t,x,a)+o(h), $$
$$ \int_t^{t+h} r(s,X_s,a)\,ds = h\,r(t,x,a)+o(h). $$
Thay thế vào DPP, hủy $V(t,x)$, chia cho $h$ và cho $h\downarrow 0$:
$$ 0=\sup_{a\in\mathcal A}\left\{r(t,x,a)+\nabla_x V(t,x)^\top f(t,x,a)+\partial_t V(t,x)\right\}, $$
sắp xếp lại thành $-\partial_t V(t,x) = H(t,x,\nabla_x V(t,x))$. $\quad\blacksquare$
Kết nối với Hamilton–Jacobi. Điều Bellman nhận ra vào những năm 1950 là phương trình vi phân từng phần do lập trình động tạo ra có cấu trúc giống hệt như phương trình Hamilton–Jacobi thế kỷ 19 trong cơ học cổ điển. Viết phần thưởng đang chạy dưới dạng trừ Lagrangian, $r(t,x,a)=-L(t,x,a)$, xác định
$$ H(t,x,p):=\sup_{a\in\mathcal A}\{p^\top f(t,x,a)-L(t,x,a)\}. $$
Khi đó, phương trình HJB trở nên giống với phương trình Hamilton cho tác dụng $S(t,q)$,
$$ \frac{\partial S}{\partial t}+H\!\left(q,\frac{\partial S}{\partial q}\right)=0. $$
Theo sự tương ứng $S\leftrightarrow V$ và $q\leftrightarrow x$, hai phương trình giống nhau ở cấp độ cấu trúc PDE.
Khuếch tán có kiểm soát (quy trình Itô)
Bây giờ chúng ta chuyển sang cài đặt ngẫu nhiên: thời gian liên tục, trạng thái liên tục và không gian hành động, và động lực học Itô. Giả sử hệ thống phát triển theo SDE
$$ dX_t = f(X_t,a_t)\,dt + \Sigma(X_t,a_t)\,dW_t $$
trong đó $X_t$ là trạng thái, $a_t$ là điều khiển, $W_t$ là quy trình Wiener tiêu chuẩn, còn $f$ và $\Sigma$ mô tả sự trôi dạt và khuếch tán. Phần thưởng được trao bởi $r(x,a)$ và mục tiêu là tối đa hóa phần thưởng chiết khấu dự kiến trong một khoảng thời gian vô hạn:
$$ J(\pi):=\mathbb{E}\Big[\int_0^\infty e^{-\rho t}r(X_t,a_t)\,dt\Big],\qquad a_t\sim \pi(\cdot\mid X_t) $$
trong đó $\rho>0$ là tỷ lệ chiết khấu. Hàm giá trị liên quan là
$$ V(x):=\sup_\pi \mathbb{E}\Big[\int_0^\infty e^{-\rho t}r(X_t,a_t)\,dt \Big| X_0=x\Lớn] $$
Định lý (phương trình Hamilton-Jacobi-Bellman cho sự khuếch tán có kiểm soát). Trong các điều kiện chính quy thích hợp:
- $f(\cdot,a)$, $\Sigma(\cdot,a)$, $r(\cdot,a)$ là liên tục trong $(x,a)$; Lipschitz trong $x$ đồng đều trong $a$.
- $\Sigma\Sigma^\top(x,a)$ bị giới hạn và không suy biến đồng đều (đối với lý thuyết $C^2$ cổ điển; nếu bạn bỏ điều này, bạn thường làm việc ở dạng nhớt).
- $r$ bị giới hạn (hoặc có mức tăng trưởng tuyến tính nhiều nhất với đủ khả năng tích hợp).
- $V\in C^2(\mathbb R^d)$ và bị chặn (hoặc tăng trưởng đa thức, với các sửa đổi kỹ thuật thông thường).
Sau đó hàm giá trị thỏa mãn Hamilton-Jacobi-Bellman (HJB) PDE
$$ \rho V(x)=\max_{a\in \mathcal{A}}\Big\{ r(x,a)+\mathcal{L}^a V(x)\Big\}.\tag{1} $$trong đó $\mathcal{L}^a$ là trình tạo vô hạn đang hoạt động $a$:
$$ \mathcal{L}^a \varphi(x):=\nabla \varphi(x)^\top f(x,a) +\tfrac12 \mathrm{Tr}\big(\Sigma\Sigma^\top \nabla^2 \varphi(x)\big) $$
Proof. Cấu trúc giống như trong trường hợp xác định. Thành phần mới duy nhất là sự mở rộng trong thời gian ngắn của $\mathbb E_x[V(X_h)]$: theo công thức của Itô,
$$ \mathbb E_x[V(X_h)] = V(x) + h\,\mathcal L^a V(x) + o(h), $$
trong đó trình tạo $\mathcal{L}^a$ thay thế đạo hàm có hướng $\nabla V^\top f$, thêm số hạng độ cong $\tfrac{1}{2}\mathrm{Tr}(\Sigma\Sigma^\top\nabla^2 V)$ đến từ biến thể bậc hai của $W$. Phần còn lại không thay đổi: thay thế vào DPP, hủy $V(x)$, chia cho $h$ và đặt $h\downarrow 0$ để thu được (1). $\quad\blacksquare$
Lập luận tương tự cũng dẫn đến HJB không tự trị khi $f$, $\Sigma$, và $r$ phụ thuộc rõ ràng vào thời gian; xem Phụ lục C.
Ghi chú lịch sử: Năm 1960, Rudolf E. Kalman đã xuất bản bài báo chuyên đề của mình về bài toán điều chỉnh tuyến tính bậc hai (LQR) [8], đây là bài toán điều khiển tối ưu theo thời gian liên tục với động lực học tuyến tính và chi phí bậc hai. Lời giải của bài toán LQR được đưa ra bằng phương trình đại số Riccati, có thể rút ra từ phương trình Hamilton-Jacobi-Bellman (HJB) cho các bài toán điều khiển thời gian liên tục.
2. Học tăng cường theo thời gian liên tục
Xác định dạng tương tự theo thời gian liên tục của hàm Q bằng
$$ Q(x,a):=\frac{1}{\rho}\Big(r(x,a)+\mathcal{L}^a V(x)\Big).\tag{2} $$
Từ HJB (1), suy ra ngay $V(x)=\max_{a} Q(x,a)$. Nhận dạng này là cơ sở của cải thiện chính sách: khi chúng tôi ước tính $V$, hành động tham lam là $a^*(x) = \arg\max_a Q(x,a)$.
Dạng cố định, chiết khấu này là quy ước RL được sử dụng trong hai phần tiếp theo.
2.1 Lặp lại chính sách
Chúng tôi giải quyết HJB bằng số bằng phép lặp chính sách (PI), xen kẽ giữa đánh giá chính sách hiện tại và cải thiện thông qua hàm Q. Cả giá trị $V_\theta$ và chính sách $\alpha_\phi$ đều được biểu thị bằng MLP.
Thuật toán này dựa trên mô hình: nó giả định động lực đã biết thông qua $f(x,a)$ và $\Sigma(x,a)$ (tương đương, quyền truy cập vào trình tạo $\mathcal L^a$). Mô hình này được dùng để mô phỏng các quỹ đạo khép kín trong đánh giá chính sách và tính toán $\mathcal L^aV$ trong cải tiến chính sách.
Chúng tôi lặp lại các bước sau cho đến khi hội tụ:
Đánh giá chính sách (giá trị theo chính sách hiện tại $\alpha_k$):
$$ \rho V_k(x)=r\big(x,\alpha_k(x)\big)+\mathcal{L}^{\alpha_k(x)}V_k(x). $$Trong thực tế, chúng tôi ước tính $V_k\approx V^{\alpha_k}$ theo số lần triển khai SDE vòng kín ở Monte Carlo và điều chỉnh $V_\theta$ bằng hồi quy.
Cải thiện chính sách (tham lam đối với $V_k$):
$$ \alpha_{k+1}(x)\in\arg\max_{a\in\mathcal A}\{r(x,a)+\mathcal L^aV_k(x)\} =\arg\max_{a\in\mathcal A} Q_k(x,a), $$ở đâu
$$ Q_k(x,a):=\frac{1}{\rho}\big(r(x,a)+\mathcal L^aV_k(x)\big). $$Với tác nhân có thể phân biệt $\alpha_\phi$, điều này sẽ trở thành độ dốc tăng dần trên
$$ \max_\phi\;\mathbb E_x\big[Q_k\big(x,\alpha_\phi(x)\big)\big]. $$Chẩn đoán / dừng:
$$ \mathcal R_{\mathrm{HJB}}(x)=\rho V(x)-\max_a\{r(x,a)+\mathcal L^aV(x)\}, $$và dừng khi định mức lấy mẫu của $\mathcal R_{\mathrm{HJB}}$ và tham số thay đổi ổn định.
Trực giác: đánh giá ước tính bối cảnh giá trị do chính sách hiện tại tạo ra và việc cải tiến sẽ đưa chính sách đi lên trên bối cảnh đó. Việc lặp lại hai bước sẽ đẩy $(V,\alpha)$ tới một điểm cố định của HJB.
Tính toán trình tạo $\mathcal{L}^a V$
Trình tạo yêu cầu $\nabla V$ và $\nabla^2 V$, thu được từ $V_\theta$ thông qua autograd. Sự phổ biến $\Sigma(x,a)$ được đưa ra theo vấn đề (cài đặt dựa trên mô hình).
def compute_generator(V_net, x, f_xa, Sigma_xa):
"""L^a V(x) = ∇V · f + ½ Tr(ΣΣᵀ ∇²V)."""
V = V_net(x) # (đợt, 1)
grad_V = autograd.grad(V.sum(), x, create_graph=Đúng)[0] # (đợt, d)
trôi = (grad_V * f_xa).tổng(-1, keepdim=Đúng) # ∇V · f
d = x. hình dạng[1]
H = ngọn đuốc.ngăn xếp([autograd.grad(grad_V[:,i].sum(), x,
create_graph=True)[0] cho i trong phạm vi(d)], dim=1)
A = Sigma_xa @ Sigma_xa.transpose(- 1,-2) # ΣΣᵀ
diff = 0,5 * (A * H).tổng(dim=(-2,-1)) .bỏ nén(-1) # ½Tr(AH)
trở lại trôi + diff
Trong quá trình cải tiến chính sách, $\nabla V$ và $\nabla^2 V$ tách rời khỏi $\theta$ nên độ dốc chỉ chảy qua $\phi$.
Đánh giá chính sách (Feynman–Kac MC)
Đối với chính sách cố định $\alpha$, $V^\alpha$ giải quyết PDE tuyến tính
$$ \rho V^\alpha(x)=r\big(x,\alpha(x)\big)+\mathcal L^{\alpha(x)}V^\alpha(x). $$
Theo biểu diễn Feynman-Kac, đối với mọi chân trời cắt cụt $T>0$,
$$ V^\alpha(x)= \mathbb E_x\!\left[\int_0^\infty e^{-\rho s}\,r\big(X_s,\alpha(X_s)\big)\,ds\right]=\mathbb E_x\!\left[\int_0^T e^{-\rho s}\,r\big(X_s,\alpha(X_s)\big)\,ds + e^{-\rho T}V^\alpha(X_T)\right] $$
Trong quá trình đánh giá chính sách ở Monte Carlo, chúng tôi ước chừng kỳ vọng này bằng các quỹ đạo mô phỏng và sử dụng giá trị phê bình để khởi tạo giá trị cuối cùng tại thời điểm $T$.
Cải thiện chính sách
Tại các điểm sắp xếp thứ tự, hãy tính $Q_k(x,\alpha_\phi(x))$ bằng cách sử dụng $\nabla V_k$, $\nabla^2 V_k$ và tối đa hóa $\mathbb{E[Q_k]$ w.r.t. $\phi$:
grad_V, H = compute_generator_detached(V_net, x) # V cố định
a = policy_net(x) # khả vi trong φ
f_xa, S_xa = vấn đề.trôi(x, a), vấn đề.sự khuếch tán(x, a)
L_V = generator_from_precomputed( cấp độ_V, H, f_xa, S_xa)
Q = (vấn đề.phần thưởng(x, a) + L_V) / ro
tổn thất = -Q.trung bình() # độ dốc tăng dần trên Q
tổn thất.lùi()
opt_pi.bước()
2.2 Không có mô hình: Q-learning theo thời gian liên tục
Việc lặp lại chính sách dựa trên mô hình. Một lộ trình bổ sung là Q-learning, có thể được triển khai không cần mô hình từ các chuyển đổi được lấy mẫu.
Trong thời gian liên tục, hàm Q đáp ứng PDE
$$ \rho Q(x,a)=r(x,a)+\mathcal L^a\big(\max_{a'\in\mathcal A}Q(x,a')\big).\tag{4} $$
Với mạng lưới thần kinh, hãy thiết lập
$$ Q_\psi(x,a)\khoảng Q(x,a),\qquad a_\omega(x)\khoảng \arg\max_{a}Q_\psi(x,a), $$
trong đó $Q_\psi$ (critic) và $a_\omega$ (actor) là MLP.
Sử dụng các chuyển đổi ngắn $(X_t,a_t,r_t,X_{t+\Delta t})$ và kích thước bước nhỏ $\Delta t$, mục tiêu TD thực tế là
$$ y_t = r_t\,\Delta t + e^{-\rho\Delta t}\,\bar V(X_{t+\Delta t}), \qquad \bar V(x):=Q_{\bar\psi}(x,a_\omega(x))\ \text{(or }\max_a Q_{\bar\psi}(x,a)\text{)}. $$
Sau đó, hãy đào tạo nhà phê bình bằng
$$ \mathcal L_Q(\psi)=\mathbb E\big[(Q_\psi(X_t,a_t)-y_t)^2\big]. $$
Diễn viên được cập nhật khi đi lên trên
$$ \max_\omega\;\mathbb E\big[Q_\psi(X_t,a_\omega(X_t))\big]. $$
Điều này phản ánh sự phân chia tác nhân-nhà phê bình thông thường: một mạng phù hợp với các giá trị hành động trạng thái, trong khi mạng kia đưa ra các hành động tối đa hóa chúng.
Ví dụ 1 — LQR ngẫu nhiên
Bộ điều chỉnh tuyến tính bậc hai là tiêu chuẩn kiểm soát thời gian liên tục chính tắc: động lực tuyến tính, chi phí bậc hai và giải pháp dạng đóng. Điều đó lý tưởng cho việc xác thực một bộ giải số.
Thiết lập bài toán
Động lực (nhiễu cộng, vô hướng 1-D):
$$dX_t = (\alpha\,X_t + \beta\,a_t)\,dt + \sigma\,dW_t$$
Phần thưởng (chi phí bậc hai âm):
$$r(x,a) = -\tfrac{1}{2}(q\,x^2 + r_a\,a^2)$$
| Biểu tượng | Ý nghĩa | Giá trị |
|---|---|---|
| $\alpha$ | trôi dạt vòng lặp mở (ổn định nếu $<0$) | $-0,5$ |
| $\beta$ | hiệu quả kiểm soát | $1,0$ |
| $q$ | chi phí trạng thái trọng lượng | $1,0$ |
| $r_a$ | chi phí hành động trọng lượng | $0,1$ |
| $\sigma$ | khuếch tán (tiếng ồn cường độ) | $0,3$ |
| $\rho$ | tỷ lệ chiết khấu | $0,1$ |
Giải pháp phân tích
Thay thế ansatz bậc hai $V(x) = -\tfrac{1}{2}Px^2 - c$ vào HJB và tối ưu hóa lợi nhuận $a$ (xem Phụ lục A để biết đầy đủ đạo hàm):
Các đối tượng dạng đóng là:
$$ a^*(x)=-\frac{\beta P}{r_a}x=: -Kx, $$
$$ \rho P = q + 2\alpha P - \frac{\beta^2}{r_a}P^2, $$
$$ c = \frac{\sigma^2 P}{2\rho}. $$
Mã
lớp StochasticLQR(ControlProblem):
def drift(self, x, a): return x @ A. T + a @ B.T
def khuếch tán(self, x, a): trở lại D.dỡ bỏ(0).mở rộng(x .hình dạng[0], -1, -1)
def phần thưởng(bản thân, x, a):
trở lại -0,5*(( x@Q*x).sum(-1,keepdim=True) + (a@R*a).sum(-1,keepdim= Đúng))
P, c, K = solve_are(A, B, Q, R, D, rho=0,1) # giải pháp Riccati chính xác người giải quyết = PolicyIteration(vấn đề, cfg)
lịch sử = bộ giải.giải() # PI thần kinh
Kết quả
Đã học $V_\theta$ và $\alpha_\phi$ rất khớp với $V^*(x) = -\tfrac{1}{2}Px^2 - c$ và $a^*(x) = -Kx$:
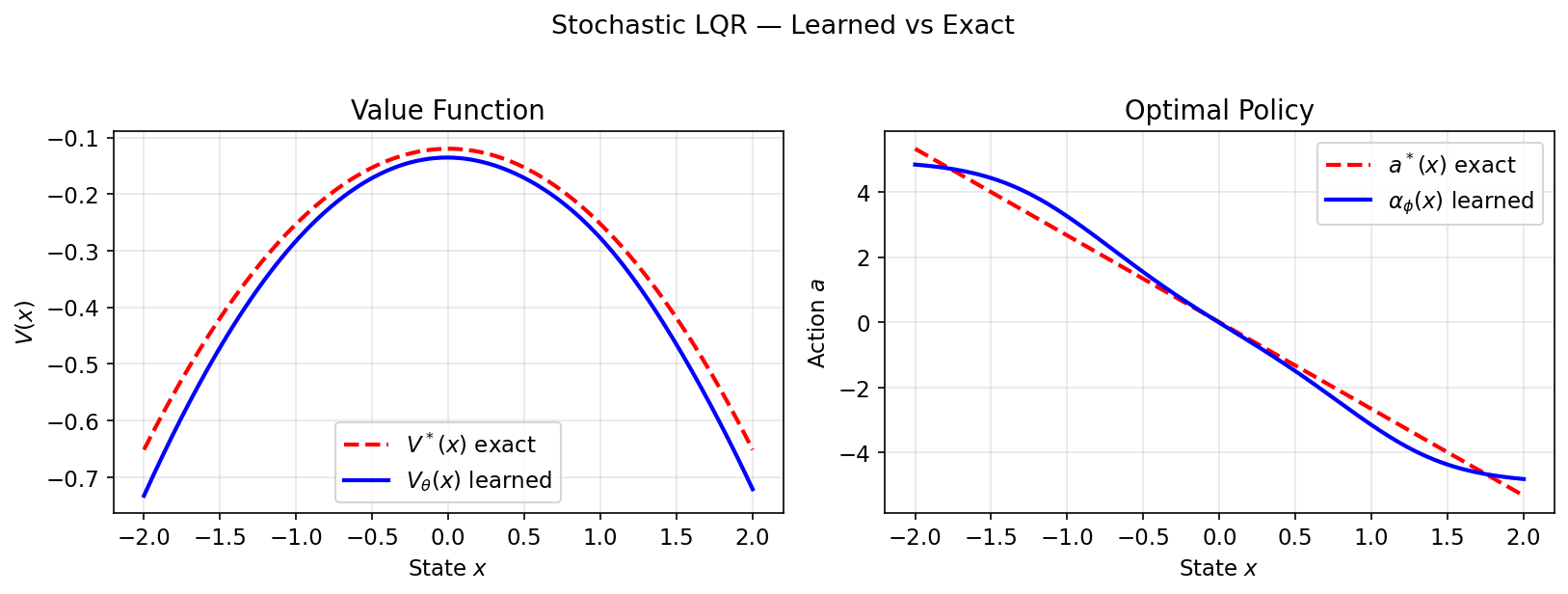
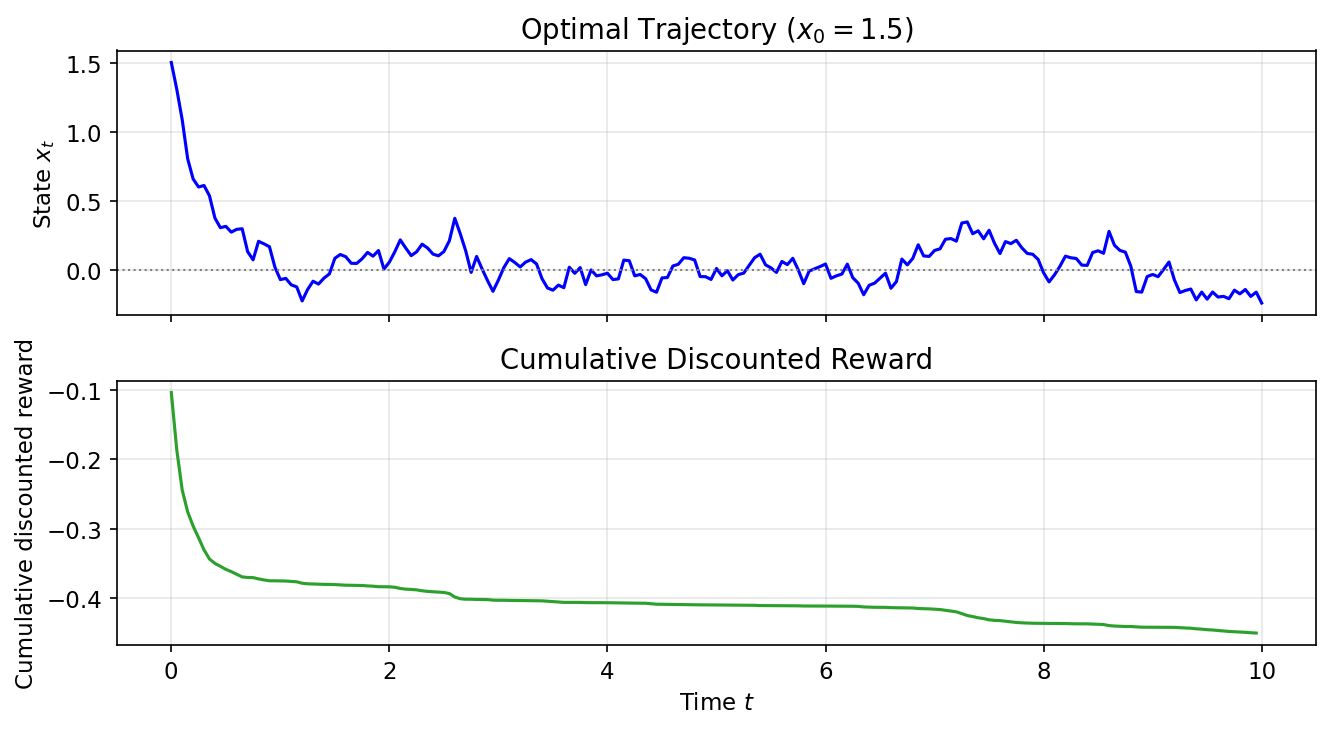
Quỹ đạo mẫu theo chính sách đã học ($x_0=1,5$) và phần thưởng chiết khấu tích lũy:
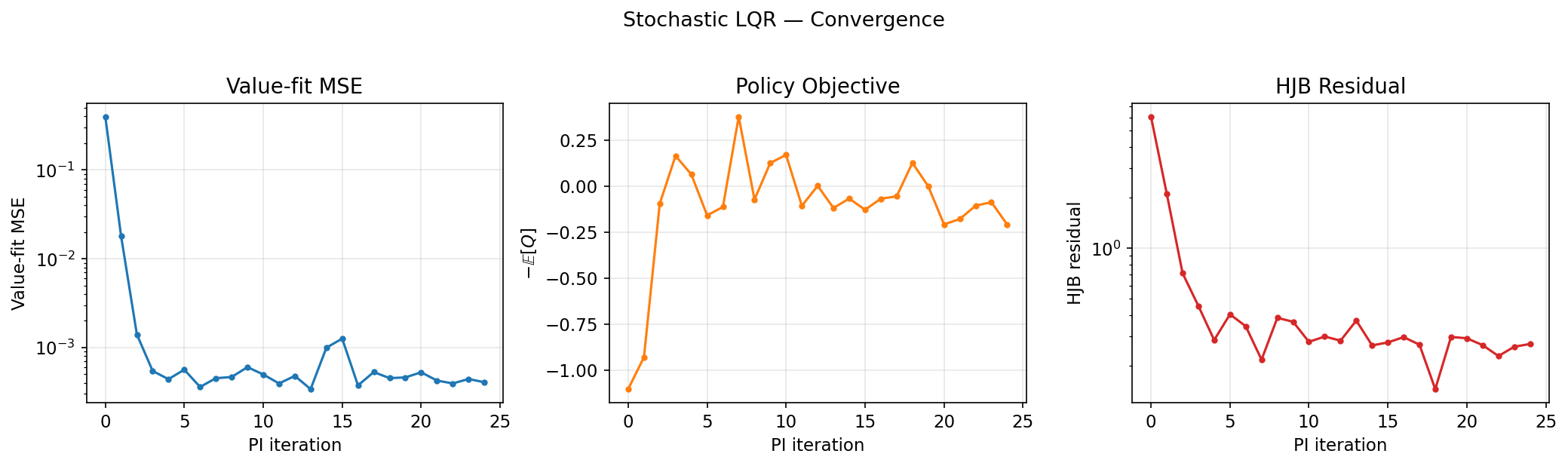
Chẩn đoán hội tụ (MSE phù hợp với giá trị, mục tiêu chính sách, phần dư HJB):
Ví dụ 2 — Danh mục Merton
Vấn đề danh mục đầu tư của Merton (1969) hỏi nhà đầu tư nên phân bổ tài sản giữa trái phiếu không rủi ro và tài sản rủi ro như thế nào đồng thời lựa chọn tỷ lệ tiêu dùng. Mục tiêu là tối đa hóa tiện ích tiêu dùng CRRA (ngăn ngừa rủi ro tương đối không đổi) trong suốt thời gian dự kiến. Nó cũng thừa nhận một giải pháp dạng đóng, khiến giải pháp này trở thành điểm chuẩn thứ hai hữu ích với nhiễu nhân thay vì nhiễu cộng của LQR.
Thiết lập vấn đề
Trạng thái: sự giàu có $X_t > 0$. Kiểm soát: $a_t = (\pi_t, k_t)$ — tỷ lệ tài sản rủi ro và tỷ lệ tiêu dùng trên tài sản $k = c/X$.
Động lực (nhiễu hình học / nhân):
$$dX_t = \big[r_f + \pi_t(\mu - r_f) - k_t\big] X_t dt + \pi_t \sigma X_t dW_t$$
Phần thưởng (Tiện ích CRRA của luồng tiêu dùng, $\gamma \neq 1$):
$$r(x,a) = \frac{(k\,x)^{1-\gamma}}{1-\gamma}$$
| Ký hiệu | Nghĩa là | Giá trị |
|---|---|---|
| $r_f$ | lãi suất phi rủi ro | $0,03$ |
| $\mu$ | lợi nhuận kỳ vọng của tài sản rủi ro | $0,08$ |
| $\sigma$ | rủi ro biến động tài sản | $0,20$ |
| $\gamma$ | ngăn ngừa rủi ro tương đối (CRRA) | $2,0$ |
| $\rho$ | tỷ lệ chiết khấu chủ quan | $0,05$ |
Giải pháp phân tích
Thay thế định luật lũy thừa ansatz $V(x) = \frac{A}{1-\gamma}x^{1-\gamma}$ vào HJB và tối ưu hóa trên $(\pi, k)$ mang lại kết quả (xem Phụ lục B đối với đạo hàm đầy đủ):
Các điều khiển và giá trị dạng đóng là:
$$ \pi^*=\frac{\mu-r_f}{\gamma\sigma^2}=0,625, $$
$$ k^*=\frac{\rho-(1-\gamma)M}{\gamma},\qquad M:=r_f+\frac{(\mu-r_f)^2}{2\gamma\sigma^2},\qquad k^*\khoảng 0,0478, $$
$$ V^*(x)=\frac{A}{1-\gamma}x^{1-\gamma},\qquad A=\left(\frac{\gamma}{\rho-(1-\gamma)M}\right)^\gamma. $$
Cả hai biện pháp kiểm soát tối ưu đều không đổi — không phụ thuộc vào tài sản và thời gian.
Mã
loại MertonProblem( Vấn đề kiểm soát):
def drift(self, x, a): # a = (π, c_rate)
pi, cr = a[:, 0:1], a[:, 1:2]
trở lại (self.r_f + pi*(self.mu - bản thân.r_f) - cr) * x
def khuếch tán(self, x, a):
trở lại (a[:, 0:1] * self.sigma * x ).bỏ nén(-1)
def phần thưởng(bản thân, x, a):
c = (a[:, 1:2] * x).kẹp(phút=1e-8)
trở lại c.pow(1 - self.gamma) / (1 - bản thân. gamma)
Kết quả
Hàm giá trị đã học khớp với định luật lũy thừa chính xác $V^*\propto x^{1-\gamma}$; cả hai điều khiển đều hội tụ về các hằng số phân tích:
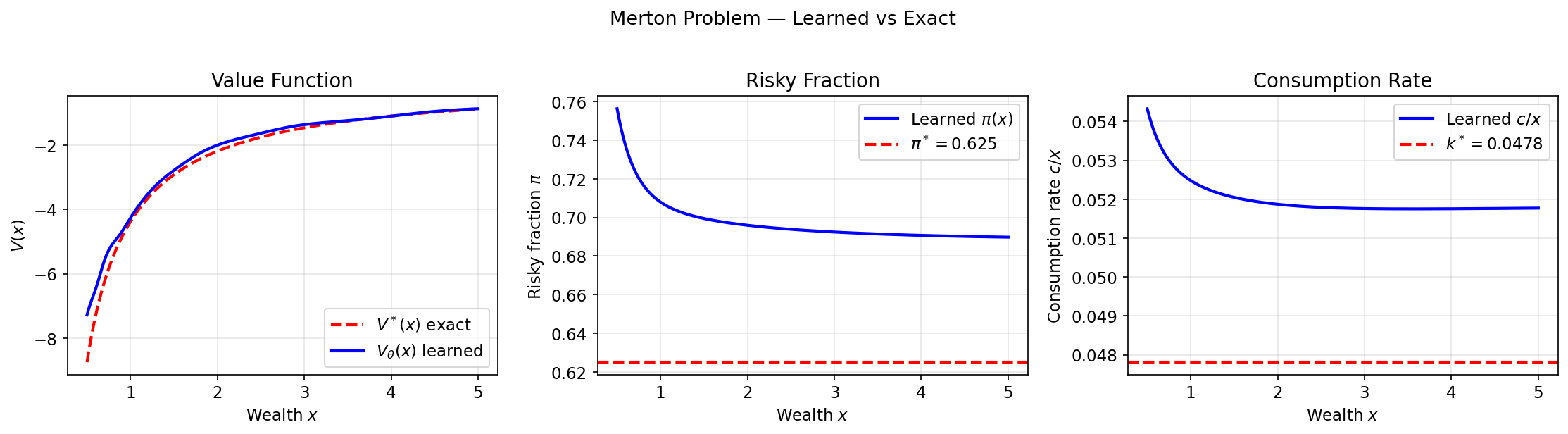
Quỹ đạo giàu có mẫu theo chính sách đã học ($X_0 = 1$) và phần thưởng chiết khấu tích lũy:
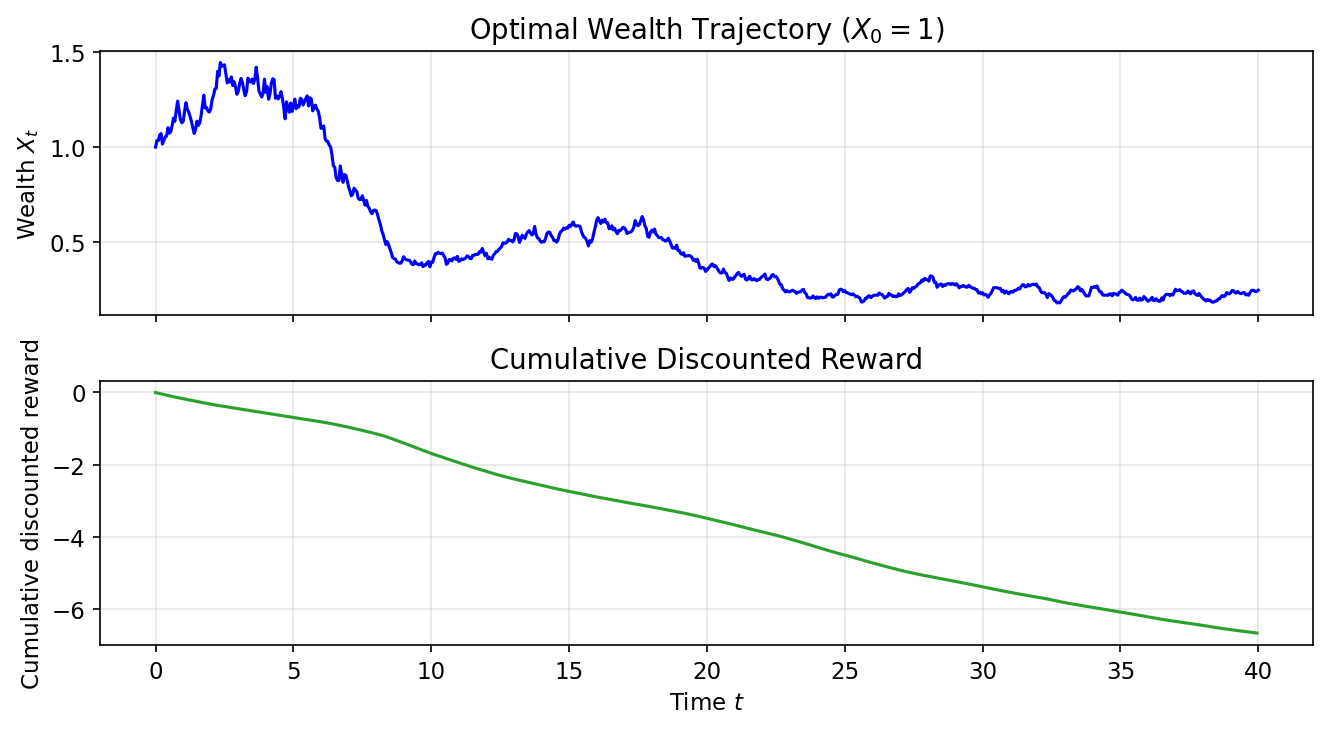
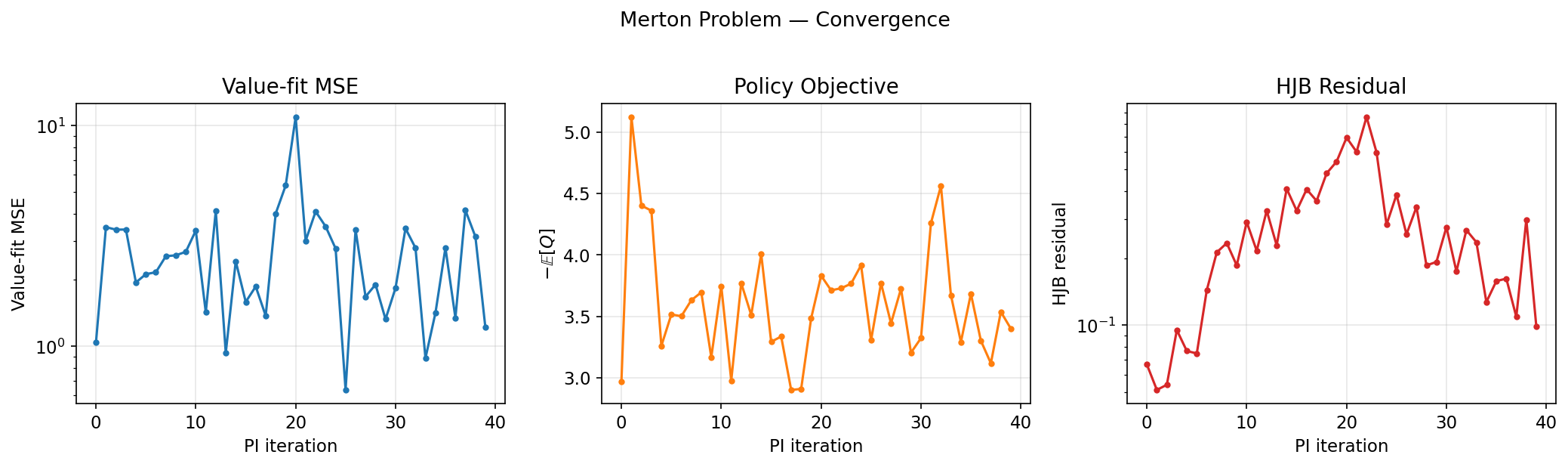
Chẩn đoán hội tụ:
Bộ máy HJB tương tự cũng xuất hiện trong các mô hình khuếch tán khi lấy mẫu thời gian ngược được viết dưới dạng bài toán điều khiển. Đặt $p_{\text{data}}(x)$ là phân phối dữ liệu mục tiêu. Để đơn giản, hãy xem xét khuếch tán thuận có hệ số nhiễu chỉ phụ thuộc vào thời gian, như trong các công thức SDE dựa trên điểm tiêu chuẩn:
$$ dY_t = f(Y_t, t)\,dt + \sigma(t)\,dB_t, \qquad Y_0 \sim p_{\text{data}}. $$
Hãy để $p_t(x)$ biểu thị mật độ biên của $Y_t$. Theo giả định về tính đều đặn tiêu chuẩn, sự đảo ngược thời gian của quá trình này lại là sự khuếch tán. Thay vì viết ngược thời gian từ $T$ xuống $0$, hãy xác định
$$ X_t := Y_{T-t}, \qquad t\in[0,T]. $$
Sau đó, $X_0\sim p_T$, $X_T\sim p_{\text{data}}$ và $X_t$ có biên $p_{T-t}$.
Để hiển thị cấu trúc điều khiển [9], hãy xác định độ lệch và khuếch tán thời gian ngược hệ số
$$ \mu(x, t) := -f(x, T-t), \qquad \Sigma(t) := \sigma(T-t). $$
Bây giờ hãy xem xét một họ khuếch tán được kiểm soát $X_t^u$ được điều khiển bởi một trường điều khiển tùy ý $u(x, t)$:
$$ dX_t^u = \big(\mu(X_t^u, t) + \Sigma(t) u(X_t^u, t)\big)\,dt + \Sigma(t)\,dW_t, \qquad X_0^u \sim p_T. $$
Mục tiêu là chọn $u$ sao cho luật đầu cuối của $X_T^u$ khớp với $p_{\text{data}}$.
Bây giờ hãy xác định hàm giá trị ứng cử viên
$$ V(x, t) := -\log p_{T-t}(x). $$
Đây là mật độ log âm của biên thời gian ngược, vì vậy giá trị cuối của nó là
$$ V(x, T) = -\log p_{\text{data}}(x). $$
Để xác định PDE được $V$ thỏa mãn, hãy nhớ rằng biên kỳ hạn $p_t$ giải phương trình Fokker-Planck cho $Y_t$. Do đó, $\rho_t(x) := p_{T-t}(x) = e^{-V(x, t)}$ thỏa mãn PDE Fokker-Planck thời gian ngược
$$ \partial_t \rho_t = -\operatorname{div}(\mu\,\rho_t) - \tfrac{1}{2}\operatorname{Tr}\big(\Sigma\Sigma^\top \nabla_x^2 \rho_t\big). $$
Thay thế $\rho_t = e^{-V}$, $\nabla_x \rho_t = -e^{-V}\nabla_x V$ và $\nabla_x^2 \rho_t = e^{-V}(\nabla_x V\nabla_x V^\top - \nabla_x^2 V)$ vào PDE đó và chia cho $-e^{-V}$ mang lại
$$ \partial_t V = \operatorname{div}\mu - \mu \cdot \nabla_x V + \tfrac{1}{2}\|\Sigma^\top \nabla_x V\|^2 - \tfrac{1}{2}\operatorname{Tr}\big(\Sigma\Sigma^\top \nabla_x^2 V\big). $$
Để viết lại bài toán này dưới dạng bài toán điều khiển, hãy đưa biến điều khiển $u$ thông qua đồng nhất thức liên hợp lồi cho hàm bậc hai $g(y) = \frac{1}{2}\|y\|^2$:
$$ \tfrac{1}{2}\|y\|^2 = \sup_{u\in\mathbb{R}^d} \left\{ u \cdot y - \tfrac{1}{2}\|u\|^2 \right\}. $$
Đặt $y = -\Sigma^\top \nabla_x V$ cho phép chúng ta viết lại số hạng gradient bậc hai dưới dạng
$$ \tfrac{1}{2}\|-\Sigma^\top \nabla_x V\|^2 = \sup_{u} \left\{ u^\top (-\Sigma^\top \nabla_x V) - \tfrac{1}{2}\|u\|^2 \right\} = -\inf_{u} \left\{ \tfrac{1}{2}\|u\|^2 + (\Sigma u) \cdot \nabla_x V \right\}. $$
Đây là bước quan trọng: nó thay thế một số hạng gradient bậc hai bằng một số hạng tuyến tính có thể được hiểu là độ lệch có kiểm soát.
Việc cắm số hạng này trở lại PDE cho $V$, nhân với $-1$ và thu thập các số hạng độc lập với $u$ bên trong phần vô cùng sẽ cho phương trình HJB chân trời hữu hạn
$$ -\partial_t V = \inf_u \left\{ \tfrac{1}{2}\|u\|^2 - \operatorname{div}\mu + (\mu + \Sigma u)\cdot \nabla_x V + \tfrac{1} \tag{3} $$
PDE này cho thấy $V(x,t) = -\log p_{T-t}(x)$ chính xác là hàm giá trị của bài toán điều khiển ngẫu nhiên với động lực $X_t^u$ và chi phí
$$ J(u; x, t) = \mathbb{E}\left[ \int_t^T \left( \tfrac{1}{2}\|u(X_s^u,s)\|^2 - \operatorname{div}\mu(X_s^u,s) \right) ds - \log p_{\text{data}}(X_T^u) \;\middle|\; X_t^u=x \right]. $$
Luật điều khiển tối ưu $u^*(x, t)$ là hàm cực tiểu trong phương trình HJB. Từ tối ưu hóa bậc hai ở trên, có thể thu được cực tiểu hóa của $\frac{1}{2}\|u\|^2 + u^\top (\Sigma^\top \nabla_x V)$ bằng cách đặt đạo hàm của nó đối với $u$ thành 0:
$$ u^* + \Sigma^\top \nabla_x V = 0 \implies u^*(x, t) = -\Sigma^\top(t)\nabla_x V(x,t). $$
Vì $V(x, t) = -\log p_{T-t}(x)$, nên ta có $\nabla_x V = -\nabla_x \log p_{T-t}(x)$. Việc thay thế đẳng thức này sẽ cho ra luật điều khiển tối ưu chính xác
$$ u^*(x, t) = \Sigma^\top(t)\nabla_x \log p_{T-t}(x) = \sigma(T-t)^\top \nabla_x \log p_{T-t}(x). $$
Do đó, sự trôi dạt được kiểm soát trở thành
$$ \mu(x,t)+\Sigma(t)u^*(x,t) =-f(x,T-t)+\Sigma(t)\Sigma(t)^\top \nabla_x \log p_{T-t}(x), $$
chính xác là hiệu chỉnh điểm số theo thời gian ngược.
Áp dụng công thức Itô cho $V(X_s^u, s)$ dọc theo một quỹ đạo được điều khiển tùy ý và sau đó sử dụng HJB sẽ mang lại nhận dạng xác minh
$$ J(u; x, t) = V(x, t) + \frac{1}{2} \mathbb{E}\left[ \int_t^T \| u(X_s^u,s) - u^*(X_s^u,s) \|^2 ds \;\middle|\; X_t^u = x \right]. $$
Nhận dạng này là xương sống lý thuyết điều khiển của các mô hình khuếch tán:
- Tùy thuộc vào tham số hóa, mạng có thể dự đoán điểm $s(x,t)=\nabla_x\log p_{T-t}(x)$ hoặc điều khiển tỷ lệ $u(x,t)=\Sigma^\top(t)s(x,t)$.
- Khoảng cách xác minh là bậc hai trong lỗi kiểm soát. Theo phương pháp tái tham số hóa mô hình khuếch tán tiêu chuẩn được sử dụng trong thực tế, ELBO thu được sẽ giảm xuống thành mục tiêu phù hợp với điểm số khử nhiễu có trọng số [9].
- Khi $u=u^*$, khoảng cách biến mất và luật đầu cuối của quy trình ngược lại khớp chính xác với phân phối dữ liệu.
Vì vậy, mô hình tổng quát dựa trên khuếch tán có thể được xem như một bài toán điều khiển tối ưu ngẫu nhiên theo chiều ngang hữu hạn với chính sách tối ưu chính xác là hiệu chỉnh độ lệch thời gian ngược do điểm gây ra.
Tài liệu tham khảo
[1] Jia, Yanwei và Xun Yu Zhou. “q-Học tập trong thời gian liên tục.” Tạp chí Nghiên cứu Máy học 24, không. 161 (2023): 1-61.
[2] Jia, Yanwei và Xun Yu Zhou. “Độ dốc chính sách và việc học tập của tác nhân-phê bình trong thời gian và không gian liên tục: Lý thuyết và thuật toán.” Tạp chí Nghiên cứu Máy học 23, không. 275 (2022): 1-50.
[3] Phương trình Hamilton-Jacobi-Bellman, Phương trình vi phân ngẫu nhiên của Benjamin Moll https://benjaminmoll.com/wp-content/uploads/2019/07/Lecture4_ECO521_web.pdf
[4] Fleming, Wendell H. và H. Mete Soner. Các quy trình Markov được kiểm soát và các giải pháp về độ nhớt. New York, NY: Springer New York, 2006.
[5] Yong, Jiongmin, và Xun Yu Zhou. Điều khiển ngẫu nhiên: Hệ thống Hamilton và phương trình HJB. Tập. 43. Khoa học & Truyền thông Kinh doanh Springer, 1999.
[6] Bellman, Richard. “Về lý thuyết lập trình động.” Kỷ yếu Viện Hàn lâm Khoa học Quốc gia số 38, số 1. 8 (1952): 716-719. https://doi.org/10.1073/pnas.38.8.716.
[7] Bellman, Richard Ernest. Giới thiệu về lý thuyết lập trình động. Santa Monica, CA: Tập đoàn RAND, 1953. https://www.rand.org/pubs/reports/R245.html.
[8] Kalman, Rudolf E. “Đóng góp cho lý thuyết kiểm soát tối ưu.” Boletin de la Sociedad Matematica Mexicana 5 (1960): 102-119. https://boletin.math.org.mx/pdf/2/5/BSMM%282%29.5.102-119.pdf.
[9] Berner, Julius, Lorenz Richter và Karen Ulrich. “Một góc nhìn điều khiển tối ưu về mô hình tổng hợp dựa trên khuếch tán.” Giao dịch về Nghiên cứu Học máy, 2024. https://arxiv.org/abs/2211.01364.
Phụ lục A: Đạo hàm LQR
Ansatz. Đoán $V(x) = -\tfrac{1}{2}Px^2 - c$ với $P > 0$. Khi đó $V'=-Px$, $V''=-P$.
Bộ tạo. Với độ lệch $f = \alpha x + \beta a$ và độ khuếch tán không đổi $\sigma$:
$$ \mathcal{L}^a V =V'(\alpha x+\beta a)+\tfrac{1}{2}\sigma^2V'' =-Px(\alpha x+\beta a)-\tfrac{1}{2}\sigma^2P =-\alpha P x^2-\beta P a x-\tfrac{1}{2}\sigma^2P. $$
HJB. Thay thế vào $\rho V = \max_a \{r + \mathcal{L}^a V\}$:
$$ -\tfrac{1}{2}\rho P x^2 - \rho c =\max_{a}\Big\{-\tfrac{1}{2}qx^2-\tfrac{1}{2}r_a a^2-\alpha P x^2-\beta P a x-\tfrac{1}{2}\sigma^2P\Big\}. $$
Sự tối ưu trong $a$. RHS lõm trong $a$; đặt $\partial_a(\cdot) = 0$:
$$ -r_a\,a-\beta P x=0 \ngụ ý a^*(x)=-\frac{\beta P}{r_a}\,x=: -Kx. $$
Phương trình Riccati. Thay $a^* = -Kx$ trở lại và khớp với hệ số $x^2$ và hằng số:
$$x^2:\quad \rho P = q + 2\alpha P - \frac{\beta^2}{r_a}P^2, \qquad \text{const:}\quad c = \frac{\sigma^2 P}{2\rho}$$
Đầu tiên là phương trình Riccati đại số chiết khấu. Trong trường hợp vô hướng, nó là bậc hai của $P$. $\quad\blacksquare$
Phụ lục B: Đạo hàm Merton
Ansatz. Giá trị lũy thừa: $V(x) = \frac{A}{1-\gamma}\,x^{1-\gamma}$, $A > 0$. Khi đó:
$$V'(x) = A\,x^{-\gamma},\qquad V''(x) = -\gamma A\,x^{-\gamma-1}$$
Generator. Sử dụng drift $\mu_X x = [r_f + \pi(\mu-r_f) - k]x$ và khuếch tán $\sigma_X x = \pi\sigma x$:
$$\mathcal{L}^a V = A\,x^{-\gamma}\cdot\mu_X x - \tfrac{1}{2}\gamma A\,x^{-\gamma-1}\cdot\sigma_X^2 x^2 = A\,x^{1-\gamma}\big[r_f + \pi(\mu-r_f) - k - \tfrac{1}{2}\gamma\pi^2\sigma^2\big]$$
HJB. Thay thế và chia cho $x^{1-\gamma} > 0$:
$$\frac{\rho A}{1-\gamma} = \max_{\pi,\,k}\left\{\frac{k^{1-\gamma}}{1-\gamma} + A\big[r_f + \pi(\mu-r_f) - k - \tfrac{1}{2}\gamma\pi^2\sigma^2\big]\right\}$$
Tối ưu trong $\pi$. FOC $\partial_\pi(\cdot) = 0$: $\;A[(\mu-r_f) - \gamma\pi\sigma^2] = 0$:
$$\pi^* = \frac{\mu - r_f}{\gamma\,\sigma^2}$$
Đây là cận thị quy tắc danh mục đầu tư - độc lập với sự giàu có và thời gian. Tâm lý ngại rủi ro cao hơn $\gamma$ hoặc biến động $\sigma$ làm giảm mức độ rủi ro.
Tính tối ưu trong $k$. FOC $\partial_k(\cdot) = 0$: $\;k^{-\gamma} - A = 0$, do đó $k^* = A^{-1/\gamma}$.
Giải $A$. Xác định tốc độ tăng trưởng tương đương với sự chắc chắn $M := r_f + \frac{(\mu-r_f)^2}{2\gamma\sigma^2}$. Thay thế lại bộ tối ưu hóa:
$$ \frac{\rho A}{1-\gamma} =\frac{(A^{-1/\gamma})^{1-\gamma}}{1-\gamma}+A\big[M-A^{-1/\gamma}\big] =\frac{A^{(\gamma-1)/\gamma}}{1-\gamma}+AM-A^{(\gamma-1)/\gamma}. $$
Nhân với $1-\gamma$ và thu thập các số hạng sẽ được
$$ \rho A=(1-\gamma)AM+\gamma A^{(\gamma-1)/\gamma}. $$
Vì $A>0$ nên chia cho $A^{(\gamma-1)/\gamma}$ để được
$$ A^{1/\gamma}=\frac{\gamma}{\rho-(1-\gamma)M}. $$
Do đó
$$ A = \left(\frac{\gamma}{\rho - (1-\gamma)M}\right)^\gamma, \qquad k^* = \frac{\rho - (1-\gamma)M}{\gamma} $$
Mẫu số $\rho - (1-\gamma)M$ phải dương — đây là điều kiện khả thi đảm bảo tiện ích trọn đời là hữu hạn. Với các tham số của chúng tôi: $M \approx 0,04563$, do đó $k^* \approx 0,0478$. $\quad\blacksquare$
Phụ lục C: Các trường hợp không tự trị và có đường chân trời hữu hạn
Hãy để động lực và phần thưởng phụ thuộc vào thời gian:
$$ dX_t=f(t,X_t,a_t)\,dt+\Sigma(t,X_t,a_t)\,dW_t,\qquad r=r(t,x,a). $$
Đối với bài toán chân trời vô hạn được chiết khấu, hãy xác định giá trị phụ thuộc thời gian
$$ V(t,x):=\sup_\pi \mathbb E\Big[\int_t^\infty e^{-\rho(s-t)} r(s,X_s,a_s)\,ds\ \Big|\ X_t=x\Big]. $$
Khi đó bộ tạo phụ thuộc thời gian là
$$ \mathcal L_t^a \varphi(x)=\nabla \varphi(x)^\top f(t,x,a)+\tfrac12\mathrm{Tr}\big(\Sigma\Sigma^\top(t,x,a)\nabla^2\varphi(x)\big), $$
và HJB trở thành
$$ \rho V(t,x)=\max_{a\in\mathcal A}\Big\{r(t,x,a)+\partial_t V(t,x)+\mathcal L_t^a V(t,x)\Big\}. $$
Tương tự,
$$ -\partial_t V(t,x)=\max_{a\in\mathcal A}\Big\{r(t,x,a)+\mathcal L_t^a V(t,x)\Big\}-\rho V(t,x). $$
Trong trường hợp tự trị, $V(t,x)$ không phụ thuộc vào thời gian, do đó $\partial_t V=0$ và bạn phục hồi (1).
Đối với trường hợp xác định chân trời hữu hạn, hãy đặt $\Sigma\equiv 0$ và xác định
$$ V(t,x):=\sup_{a_\cdot}\left[\int_t^T r(s,X_s,a_s)\,ds+g(X_T)\,\middle|\,X_t=x\right]. $$
Sau đó
$$ -\partial_t V(t,x)=\sup_{a\in\mathcal A}\left\{r(t,x,a)+\nabla_x V(t,x)^\top f(t,x,a)\right\}, \qquad V(T,x)=g(x). $$
Viết $r=-L$ và
$$ H(t,x,p):=\sup_{a\in\mathcal A}\{p^\top f(t,x,a)-L(t,x,a)\}, $$
điều này trở thành
$$ \partial_t V(t,x)+H\bigl(t,x,\nabla_x V(t,x)\bigr)=0, \qquad V(T,x)=g(x), $$
là dạng Hamilton-Jacobi cổ điển.
Tác giả: sebzuddas