Điểm nổi từ đầu: Chế độ cứng
Floating point from scratch: Hard Mode
Tác giả chia sẻ hành trình "vượt ngưỡng" nỗi sợ đối với phép toán nhị phân, chuyển từ cảm giác e dè sang việc thấu hiểu tường tận tiêu chuẩn IEEE 754. Quá trình này phơi bày những phức tạp đầy nghịch lý của số thực dấu phẩy động (floating-point), như sự tồn tại của cả số 0 dương và 0 âm, cùng những yêu cầu khắt khe về tính di động ở cấp độ phần cứng. Đối với giới lập trình viên, thông điệp cốt lõi ở đây là: cách sử dụng kiểu dữ liệu floating-point phổ thông thường che lấp đi một nền tảng mong manh với đầy rẫy các trường hợp ngoại lệ và quy tắc về độ chính xác. Việc nắm vững cách vận hành bên dưới không chỉ giúp chúng ta xử lý triệt để các hành vi phi định nghĩa (non-deterministic behavior) mà còn đảm bảo sự đồng nhất về kết quả tính toán trên nhiều nền tảng khác nhau.
Tôi có một lời thú nhận: dấu phẩy động làm tôi sợ. Nửa thập kỷ trước, tôi đã quyết định rằng tôi sẽ thực hiện một số phép toán dấu phẩy động. Sau đó, nó có vẻ đủ gần, sau khi tất cả, trôi nổi...
Tôi có một lời thú nhận: số dấu phẩy động (floating point) làm tôi sợ.
Nửa thập kỷ trước, tôi đã quyết định rằng mình sẽ tự triển khai một số phép toán dấu phẩy động. Hồi đó, việc này có vẻ đủ khả thi, rốt cuộc thì số dấu phẩy động ở khắp mọi nơi. Nó có thể khó đến mức nào chứ? Kinh nghiệm của tôi cho đến lúc đó là: nếu dành đủ thời gian và công sức để vắt óc suy nghĩ về một vấn đề, tôi thường có thể tìm ra lời giải.
Đây là cách tôi phải đối mặt với thất bại kỹ thuật hoàn toàn nhất trong đời mình. Chính từ sự hủy diệt hoàn toàn đó đã nảy sinh nỗi sợ hãi hiện tại của tôi về số dấu phẩy động.
Sau nửa thập kỷ, tôi quyết định đã đến lúc cho một trận tái đấu, thời điểm để đối mặt với những con rồng của mình!
Nhưng lần này, tôi sẽ không chỉ nhắm đến sự hiểu biết ở mức bề mặt, lần này tôi sẽ nhắm đến việc nắm bắt sâu sắc cách biểu diễn số dấu phẩy động.
Khi bắt đầu cuộc thập tự chinh này, tôi tin rằng chỉ có 3 kiểu người thực sự hiểu về số dấu phẩy động:
- Những người viết đặc tả
- Các tiến sĩ toán học đang nghiên cứu về biểu diễn số dấu phẩy động
- Những người xây dựng phần cứng xử lý số dấu phẩy động
Chào mừng đến với hiệp 2!
Chương 1: Chìm sâu vào điên rồ#
Nhìn lại, một trong những lý do chính đằng sau thất bại trước đây của tôi là tôi đã nhầm lẫn khả năng sử dụng số dấu phẩy động với sự hiểu biết về chúng. Và điều đó khiến tôi nghĩ mình không cần phải dành thời gian nghiên cứu về số dấu phẩy động, như thể tôi sẽ tự học được nó trong quá trình làm việc vậy.
Vì vậy, bây giờ là lúc tạm cất máy tính sang một bên và dành 10 ngày đồng hành cùng giấy bút. (bạn còn nhớ chứ, những thứ trắng tinh ấy)
Cách số dấu phẩy động hoạt động#
Tôi cho rằng độc giả đã có một số kiến thức cơ bản về số dấu phẩy động là gì, vì vậy tôi sẽ bỏ qua phần giới thiệu cơ bản.
Hãy để tôi đặt ra một vài định nghĩa, trong ngữ cảnh của cuộc thảo luận này, các số dấu phẩy động thông thường (normal) sẽ được định nghĩa là:
$$ (-1)^{S} × 2^{E−b} × (1 + T \cdot 2^{1−p}) $$
Với các giá trị của \(S\), \(E\) và \(T\) là các giá trị được lưu trữ trong các trường của số dấu phẩy động:
- \(S\) bit dấu
- \(E\) số mũ có độ lệch (biased exponent)
- \(T\) trường phần định trị (trailing significant field)

Kích thước của các trường này, cũng như các giá trị của \(b\) (độ lệch số mũ) và \(p\) (độ chính xác) phụ thuộc vào định dạng dấu phẩy động.
Ví dụ, đối với chuẩn IEEE 754 độ chính xác đơn (float32_t) chúng ta có:
- \(b = 127\)
- \(p = 24\)
Dẫn đến kết quả:
$$ (-1)^{S} \times 2^{E−127} \times (1 + T \cdot 2^{-23}) $$
Trong cuộc thảo luận này, chúng ta sẽ gọi:
- sign (dấu), bit dấu \(S\)
- exponent (số mũ), giá trị được lưu trữ trong trường số mũ có độ lệch \(E\)
- significant/mantissa (phần định trị), giá trị được lưu trữ trong trường \(T\)
Những điều bạn chưa từng muốn biết#
Chúng ta không thực sự quan tâm đến số dấu phẩy động ở dạng trừu tượng, mà là những gì chúng ta thường gọi là "float" trong các chương trình của mình.
Trong thế giới của tất cả các kiểu dấu phẩy động có thể có, đây là những kiểu thông dụng nhất, ngoại trừ việc trong thế giới này, ai cũng muốn sử dụng kiểu thông dụng mọi lúc!
Định dạng float này được chuẩn hóa bởi IEEE trong đặc tả IEEE 754. Bên trong "chén thánh" này là nơi hành vi dự kiến được nêu chi tiết đến mức khó tin, giúp người dùng có thể kỳ vọng cùng một hành vi cho cùng các phép toán dấu phẩy động trên các nền tảng khác nhau. Một nền tảng quan trọng để tạo ra sự di động cho float.
Ngoài ra, đây cũng là nơi địa ngục bắt đầu!
+0/-0#
Hãy bắt đầu hành trình đi xuống của chúng ta một cách từ từ.
Như những độc giả tinh ý nhất có thể đã nhận thấy khi nhìn vào định dạng biểu diễn (hoan hô), chúng ta có một bit dấu thực sự. Điều này có nghĩa là chúng ta thực sự có 2 cách biểu diễn cho số không: \(+0.0\) và \(-0.0\).
Điều thú vị là chúng ta có các quy tắc về việc sử dụng số không nào. Ví dụ, hãy xem xét cách chúng ta xác định sự bằng nhau giữa hai số dấu phẩy động, giả sử X == Y?
Để thực hiện so sánh này, chúng ta thường sử dụng lại bộ cộng và thực hiện X - Y sau đó kiểm tra xem tất cả các bit của kết quả có bằng 0 hay không, vấn đề là \(-0.0\) được viết với một số 1 ở bit dấu.
Vì vậy, chúng ta có các quy tắc về việc khi nào kết quả nên sử dụng \(+0.0\) hoặc \(-0.0\), và việc trừ hai số dấu phẩy động bằng nhau là một ví dụ về quy tắc này:
$$ X - X = +0.0 $$
NaN#
NaN viết tắt của Not A Number (Không phải là một số).
Đối với tất cả các bạn từng nghĩ rằng chúng ta đang nói về các con số, đây là điểm mà bạn bắt đầu hiểu sự khác biệt giữa một con số và một định dạng biểu diễn.
Vì vậy, hãy bắt đầu với phần thú vị, thực tế có các loại NaN khác nhau:
quietNaNs (qNaNs) mà bạn thường gặp từ các phép tính toán sai của mình.signalingNaNs (sNaNs) là những loại mà các phép tính sai không tạo ra và cũng là những loại "gào thét" với bạn bằng cách báo hiệu một ngoại lệ thao tác không hợp lệ bất cứ khi nào chúng xuất hiện dưới dạng toán hạng. Hầu hết mọi người sẽ không gặp phải các loại này.
Vậy, ý tôi là gì khi nói “qNaNs được sử dụng để chỉ ra khi kết quả của một phép toán số học không thể biểu diễn được”?
Dưới đây là một vài ví dụ để làm rõ:
- \(\sqrt{-1.0}\) dẫn đến một
qNaNvì \(\sqrt{-1.0} = i\), và \(i\) là một số ảo không thể biểu diễn nếu không sử dụng ký hiệu phức. - \(\frac{0.0}{0.0}\) cũng sẽ dẫn đến một
qNaNvì: bạn đang làm cái gì vậy? - \(+\infty - \infty\) cũng sẽ dẫn đến một
qNaNvì \(\pm\infty\) thực chất là các giới hạn, không phải các con số. Và việc trừ một giới hạn này cho một giới hạn khác \(+\infty - \infty\) đơn giản là không có ý nghĩa.
Bạn muốn biết một sự thật thú vị khác về qNaNs không?
Chúng có tính lây nhiễm.
Các phép toán số học với qNaN là một toán hạng sẽ dẫn đến kết quả là qNaN.
Hãy nghĩ về điều đó: bạn nên đưa ra kết quả gì cho một phép toán mà kết quả của nó không thể biểu diễn được?
Trong bộ nhớ, NaNs được biểu diễn với tất cả các bit số mũ được đặt thành \(1\) và với ít nhất một trong các bit định trị được đặt thành \(1\). Sau đó, bạn có thể phân biệt các NaN khác nhau dựa trên việc bit định trị nào được đặt, việc mã hóa này tùy thuộc vào quyết định của người triển khai.
Các giá trị vô cùng (Infinitys)#
Vì vậy, chúng ta đã bắt đầu giới thiệu các giá trị này cùng với NaNs, nhưng biểu diễn dấu phẩy động có chỗ cho hai ký hiệu vô cùng: một cho \(+\infty\) và bản sao gương của nó \(-\infty\). Đây không phải là các con số, vô cùng không phải là một con số, nó là một giới hạn!
Theo tuân thủ IEEE, một số giá trị vô cùng cụ thể có thể được sử dụng trong các phép toán số học, được sử dụng làm đầu vào cho các phép toán logic (boolean) và được tạo ra như kết quả của một phép tính.
Trong bộ nhớ, các giá trị vô cùng có các bit số mũ được đặt thành tất cả là \(1\), và để phân biệt chúng với NaNs, các bit định trị của chúng đều là \(0\).
Denormal#
Hãy tạm gác các giá trị vô cực và NaN sang một bên và quay lại thảo luận về các con số thuần túy.
Trong phần giới thiệu, tôi đã định nghĩa một số dấu phẩy động bình thường (normal floating point number) là:
$$ (-1)^{S} × 2^{E−b} × (1 + T · 2^{1−p}) $$
Một cách viết phổ biến hơn là:
$$ (-1)^{S} × 2^{e} × m $$
Trong đó \(m\) là một số được biểu diễn bằng chuỗi có dạng \(d_0 . d_1 d_2 ... d_{p-1}\), và có độ dài \(p\) (với \(p\) là độ chính xác, hay số lượng bit trong phần định trị + 1).
Ví dụ: \(1.5\) sẽ được viết là:
$$ (-1)^0 × 2^{0} × 1.1000 $$
và \(3\) dưới dạng \(2 × 1.5\) là:
$$ (-1)^0 × 2^{1} × 1.1000 $$
Trong biểu diễn số dấu phẩy động bình thường của chúng ta, số \(1\) trong \((1 + T · 2^{1−p})\) chính là \(d_0\) và luôn được đặt là \(d_0 = 1\).
Điều thú vị là phần định trị của chúng ta thực tế chỉ có \(p-1\) bit, và \(d_0\) thực chất là một bit ngầm định, chúng ta gọi nó là hidden bit (bit ẩn).
Nghe có vẻ đơn giản phải không? Liệu cuối cùng thì có điều gì đó đơn giản về số dấu phẩy động không nhỉ?!
Đừng lo: số dấu phẩy động sẽ không làm bạn thất vọng theo cách đó đâu, vì chúng ta còn một loại số khác!
Chúng có một bit ẩn ngầm định được đặt là \(d_0 = 0\) và được gọi là subnormal numbers (số cận bình thường) hoặc denormal numbers (số không bình thường). Tuyệt vời 🥳
Các số này được dùng để mã hóa những số dấu phẩy động nhỏ nhất có thể biểu diễn được, và là phần gây tranh cãi nhất trong đặc tả IEEE 754 trong quá trình soạn thảo.
Chúng cũng là một "nỗi đau" cực lớn khi triển khai, đến mức rất nhiều bộ FPU đời đầu sẽ bị treo (trap) khi gặp số cận bình thường và phải xử lý chúng bằng phần mềm… rất chậm…
Vậy tại sao chúng ta phải chấp nhận chúng ngoài việc không muốn lãng phí một vài bit?
Thủ phạm chính là: gradual underflow (tràn số dần dần).
Gradual underflow#
Ý tưởng đằng sau gradual underflow là làm chậm quá trình mất độ chính xác thay vì nó xảy ra đột ngột sau số bình thường nhỏ nhất có thể biểu diễn được: \(2^{-(b+1)-p+1}\). Điều này giúp ích cho sự ổn định số học.
Để minh họa ý tôi, hãy tưởng tượng nếu chúng ta không có số cận bình thường, giả sử có \(x\) và \(y\) là các số dấu phẩy động sao cho \(x \neq y\). Nếu \(x - y\) rơi vào khoảng giữa \(0.0\) và số dấu phẩy động nhỏ nhất có thể biểu diễn được, thì nó sẽ bị tràn số (underflow) về \(0.0\) vì không có số nào biểu diễn được trong phạm vi đó.
Ví dụ, sử dụng float16 không có số cận bình thường:
$$ 0.000091552734375 - 0.0000762939453125 = 0.0 $$
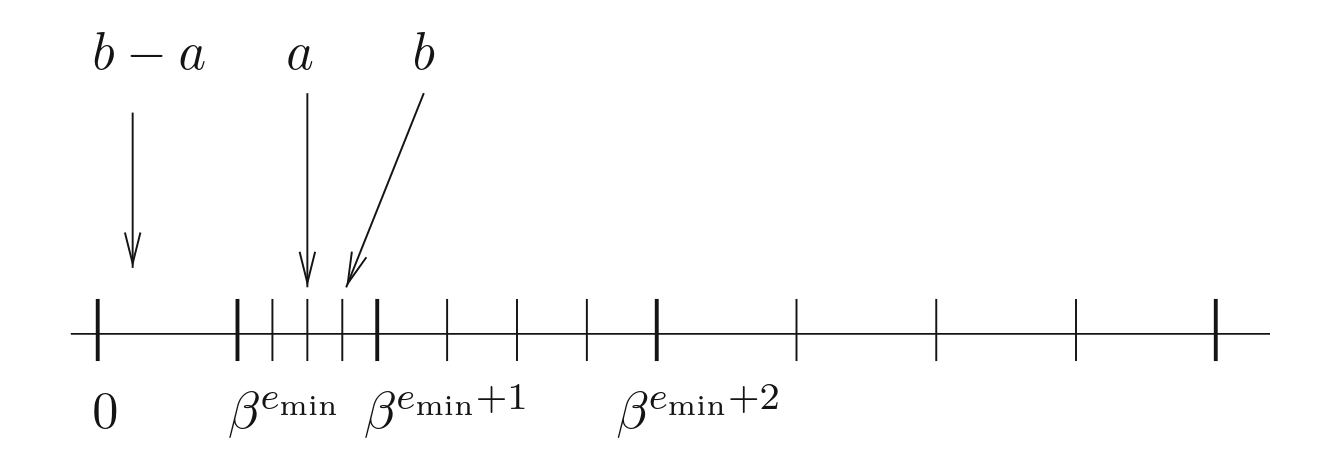
Bây giờ, khi thêm số cận bình thường, chúng ta thực sự đang lấp đầy khoảng trống này.
Ví dụ, sử dụng float16 với số cận bình thường:
$$ 0.000091552734375 - 0.0000762939453125 = 0.0000152587890625 $$
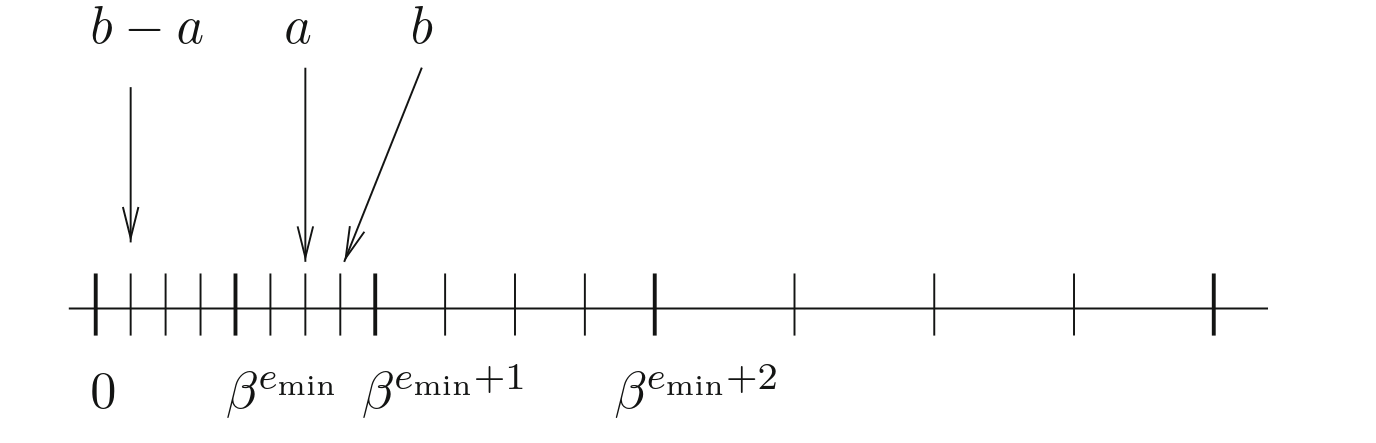
Bây giờ với các số cận bình thường trong hệ thống, chúng ta thừa hưởng một thuộc tính thú vị sau: với bất kỳ số dấu phẩy động \(x\) và \(y\) nào sao cho \(x \neq y\), thì \(x - y\) nhất định phải khác không.
Phần thưởng: chúng ta vừa có thêm lớp bảo vệ chống lại việc chia cho số không:
if ( x != y ) z = 1.0 / ( x - y );
Rounding modes#
Phạm vi những gì có thể và không thể biểu diễn phụ thuộc vào từng kiểu dữ liệu, nhiều bit hơn đồng nghĩa với không gian biểu diễn lớn hơn, ngược lại các kiểu dữ liệu nhỏ hơn đồng nghĩa với ít giá trị khả dĩ hơn.
Hãy xét kiểu số thực 16-bit nửa chính xác (half float) float16_t của IEEE, nó có 5 bit số mũ và 10 bit phần định trị, và đoán xem: nó không thể biểu diễn được 15359!
Vậy điều gì sẽ xảy ra khi chúng ta cố gắng gán giá trị cho nó là 15359?
float16_t e = 15359.0;
cout << e << endl;
Câu trả lời là 42.
Nghiêm túc hơn, điều đó phụ thuộc vào: chúng ta đang sử dụng chế độ làm tròn nào?
Đặc tả IEEE xác định 5 chế độ làm tròn mà phần cứng tương thích phải hỗ trợ:
RDlàm tròn xuống về phía \(-\infty\): kết quả là số dấu phẩy động biểu diễn được lớn nhất nhỏ hơn hoặc bằng kết quả chính xácRUlàm tròn về phía \(+\infty\): kết quả là số dấu phẩy động biểu diễn được nhỏ nhất lớn hơn hoặc bằng kết quả chính xácRZlàm tròn về phía \(0.0\) trong mọi trường hợpRN_even/RN_awaylàm tròn đến số gần nhất: kết quả là giá trị gần nhất có thể, với quy tắc giải quyết trường hợp bằng nhau nếu số đó nằm chính giữa hai giá trị:even(làm tròn số ở giữa về số chẵn) chọn số mà bit có trọng số thấp nhất của phần định trị là 0.away(làm tròn số ở giữa ra xa 0) chọn số dấu phẩy động kế tiếp.
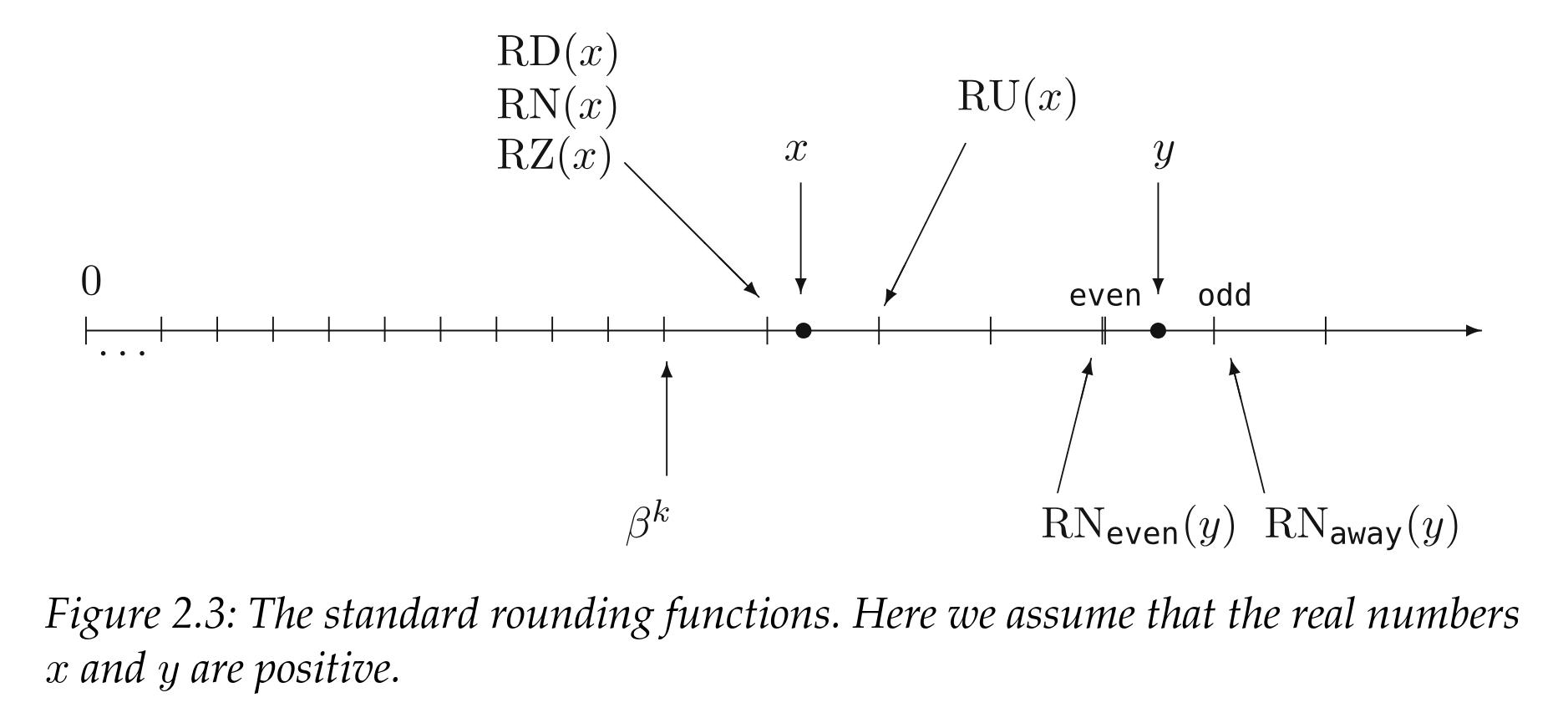
Quay lại ví dụ của chúng ta, 15359 không phải là một số có thể biểu diễn được với float16_t, và hai số gần nhất là 15352 và 15360.
Vì vậy, tùy thuộc vào chế độ làm tròn mà chúng ta đang sử dụng, chúng ta sẽ nhận được:
| chế độ làm tròn | kết quả |
|---|---|
| RD | 15352 |
| RZ | 15352 |
| RU | 15360 |
| RN (even) | 15360 |
RN_even là hành vi làm tròn mặc định của IEEE trên các hệ thống hiện đại và là những gì được xác định bởi chế độ làm tròn C++ FE_TONEAREST.
Rounding modes boundary behavior#
Hãy nhớ lại khi tôi mô tả hành vi của các chế độ làm tròn, tôi đã không sử dụng nhất quán thuật ngữ "số" cho kết quả làm tròn? Đó là vì một số chế độ làm tròn khiến kết quả làm tròn thành \(\pm\infty\).
Ví dụ trên float16_t sử dụng chế độ làm tròn RU:
float16_t x, y, z;
x = 65504;
y = 1;
fesetround(FE_UPWARD);
z = x + y;
cout << x << " + " << y << " = " << z << endl;
Sẽ cho kết quả là:
65504 + 1 = inf Tương tự như vậy:
float16_t x, y, z;
x = -65504;
y = 1;
fesetround(FE_DOWNWARD);
z = x - y;
cout << x << " - " << y << " = " << z << endl;
Sẽ làm tròn xuống \(-\infty\) :
-65504 - 1 = -inf Kết hợp lại, các định nghĩa này ngụ ý rằng các phép tính sử dụng RU sẽ không bao giờ đạt tới \(-\infty\) và các phép tính sử dụng RD sẽ không bao giờ đạt tới \(+\infty\).
float16_t x, y, zsub, zadd;
x = 65504;
y = 1;
fesetround(FE_UPWARD);
zsub = -x - y;
cout << -x << " - " << y << " = " << zsub << endl;
fesetround(FE_DOWNWARD);
zadd = x + y;
cout << x << " + " << y << " = " << zadd << endl;
Kết quả :
-65504 - 1 = -65504
65504 + 1 = 65504 Điểm thú vị ở đây nằm ở RZ, vì nó hoạt động giống như RD đối với các số dương và RU đối với các số âm, điều này có nghĩa là các phép tính sử dụng chế độ làm tròn này KHÔNG THỂ đạt tới \(\pm\infty\).
Tại thời điểm này trong bài viết, nỗi ám ảnh bất chợt của tôi về hành vi giới hạn của chế độ làm tròn có vẻ hơi ngẫu nhiên. Xin hãy kiên nhẫn và tin tôi, chúng ta sẽ khai thác hành vi này sau trong bài viết.
Không có thứ tự (Unordered)#
Việc so sánh các giá trị dấu phẩy động trong mã nguồn là một điều khá phổ biến, với các phép toán so sánh boolean cơ bản đã được quy định trong đặc tả IEEE 754. Hai số có thể nhỏ hơn, bằng hoặc lớn hơn so với nhau.
Nhưng điều gì sẽ xảy ra nếu một bên trong phép so sánh của bạn là NaN? Chúng ta có thể so sánh x > y nếu x là NaN không? Và nếu có, kết quả sẽ là gì?
Bốn mối quan hệ loại trừ lẫn nhau là có thể: nhỏ hơn, bằng, lớn hơn và không có thứ tự; trạng thái không có thứ tự xảy ra khi ít nhất một toán hạng là NaN. Mọi NaN đều sẽ được so sánh là không có thứ tự với mọi thứ, bao gồm cả chính nó.
Vì vậy, bất kỳ phép so sánh nào với NaN cũng sẽ là không có thứ tự, đây là một thuộc tính khá thú vị, có nghĩa là theo nghĩa đen thì không có mối quan hệ thứ tự nào khi có NaN tham gia.
Dưới đây là mối quan hệ này trong thực tế:
float16_t x, y;
x = NAN;
y = 1.0;
cout << "x =/= x: " << ((x=x) ? "true" : "false") << endl;
cout << "x > x: " << ((x>x) ? "true" : "false") << endl;
cout << "x <= x: " << ((x<=x) ? "true" : "false") << endl;
cout << "x > y: " << ((x>y) ? "true" : "false") << endl;
cout << "x <= y: " << ((x<=y) ? "true" : "false") << endl;
Kết quả:
x =/= x: true
x > x: false
x <= x: false
x > y: false
x <= y: false Một tác dụng phụ của điều này là một số giả định cơ bản của chúng ta về cách các mối quan hệ so sánh hoạt động bắt đầu sụp đổ, điển hình nhất là:
$$ not( x < y ) ⇔ ( x >= y ) $$
Các định luật về tính phân ba (trichotomy) đã bị phá vỡ, chúng ta không thể nào quên được điều này!

Ví dụ về bộ cộng#
Được rồi, vậy điều này thực sự hoạt động như thế nào? Vì một ví dụ còn hơn vạn lời nói (một thành ngữ mà bài viết này rõ ràng không tuân theo lắm), đây là một đoạn mã!
Đây là ví dụ bằng C về các bước cần thiết để thực hiện phép cộng số dấu phẩy động. Đoạn mã này chỉ được cung cấp cho mục đích minh họa, một số trường hợp đặc biệt đã bị lược bỏ.
bfloat16:
#include <stdint.h>
#include <stddef.h>
#include <stdfloat>
#include <stdbool.h>
#include <stdlib.h>
#include <stdio.h>
/*******
* Env *
*******/
/* Assert. */
#define assert(cdt) ({if (!(cdt)) {printf("%s:%s : assert(%s) failed.\n", __FILE__, __LINE__, #cdt); abort();}})
#ifdef DEBUG
#define check(cdt) ({if (!(cdt)) {printf("%s:%s : check(%s) failed.\n", __FILE__, __LINE__, #cdt); abort();}})
#else
#define check(cdt) ({;})
#endif
#define swap(a, b) ({auto _ = b; b = a; a = _;})
typedef bool u1;
typedef uint8_t u8;
typedef uint16_t u16;
typedef uint64_t u64;
typedef std::bfloat16_t bfloat16_t;
/*********
* Types *
*********/
typedef struct bf16 bf16;
/**************
* Structures *
**************/
/*
* Bfloat 16.
*/
struct bf16 {
union {
struct {
u16 frc:7;
u16 exp:8;
u16 sig:1;
};
u16 raw;
};
};
/*
* Special values.
*/
/* Special exponent. */
#define BF16_EXP_SPC 0xff
/* Special nummber : infinity frac. */
#define BF16_SPC_FRC_INF 0
/*************
* Utilities *
*************/
/*
* Nếu @val là giá trị đặc biệt, trả về 1.
* Ngược lại, trả về 0.
*/
static inline u1 bf16_is_spc(
bf16 val
)
{
return val.exp == BF16_EXP_SPC;
}
/*
* Nếu @val là vô cực (infinity), trả về 1.
* Ngược lại, trả về 0.
*/
static inline u1 bf16_is_inf(
bf16 val
)
{
return bf16_is_spc(val) && (val.frc == BF16_SPC_FRC_INF);
}
/*
* Nếu @val là NaN, trả về 1.
* Ngược lại, trả về 0.
*/
static inline u1 bf16_is_nan(
bf16 val
)
{
return bf16_is_spc(val) && (val.frc != BF16_SPC_FRC_INF);
}
/*
* Nếu @val là âm, trả về 1.
* Ngược lại, trả về 0.
*/
static inline u1 bf16_is_neg(
bf16 val
)
{
return val.sig;
}
/*
* Nếu @val là 0 hoặc số subnormal, trả về 1.
* Ngược lại, trả về 0.
*/
static inline u1 bf16_is_nul_or_sub(
bf16 val
)
{
return val.exp == 0;
}
/*
* Nếu @val là số subnormal, trả về 1.
* Ngược lại, trả về 0.
*/
static inline u1 bf16_is_sub(
bf16 val
)
{
return bf16_is_nul_or_sub(val) && val.frc != 0;
}
/*
* Nếu @val là số 0 (dương hoặc âm), trả về 1.
* Ngược lại, trả về 0.
*/
static inline u1 bf16_is_nul(
bf16 val
)
{
return (val.exp == 0) && (val.frc == 0);
}
/*
* Nếu @val là số thông thường (không phải inf, nan, subnormal), trả về 1.
* Ngược lại, trả về 0.
*/
static inline u1 bf16_is_reg(
bf16 val
)
{
return (!bf16_is_spc(val)) && (!bf16_is_sub(val));
}
/*
* Lấy mantissa hoàn chỉnh của @val với bit 1 đặt tại offset 31.
*/
static inline u64 bf16_frc_to_arr(
bf16 val
)
{
check((1 << 7) == 0x80);
check(bf16_is_reg(val));
const u64 arr = (1 << 31) | (((u64) val.frc) << 24);
check(((arr >> 24) & 0x7f) == val.frc);
check(((arr >> 24) & 0x80) == 0x80);
check((arr >> 32) == 0);
check(arr & 0xffffff == 0);
return arr;
}
/*
* Trả về giá trị đối của @val.
*/
static inline bf16 bf16_opp(
bf16 val
)
{
val.sig = val.sig ? 0 : 1;
return val;
}
/*******
* API *
*******/
/*
* Phép cộng.
*/
static inline bf16 bf16_add(
bf16 src0,
bf16 src1
)
{
/* Kiểm tra tính thông thường. */
assert(bf16_is_reg(src0));
assert(bf16_is_reg(src1));
/* Nếu cả hai là 0, trả về 0. Chúng ta có bảng tra cứu cho dấu.
* Nếu một trong hai là 0, trả về số còn lại. */
{
const u1 nul0 = bf16_is_nul(src0);
const u1 nul1 = bf16_is_nul(src1);
if (nul0 && nul1) {
return (bf16) {.frc = 0, .exp = 0, .sig = (u16) (src0.sig & src1.sig)};
} else if (nul0 || nul1) {
return (nul0) ? src1 : src0;
}
}
/* Đảm bảo abs(src0) >= abs(src1). */
const u1 swp = (
(src1.exp > src0.exp) ||
((src1.exp == src0.exp) && (src1.frc > src0.frc))
);
if (swp) {
swap(src0, src1);
}
/* Đảm bảo src0 dương. */
const u1 neg = bf16_is_neg(src0);
if (neg) {
src0 = bf16_opp(src0);
src1 = bf16_opp(src1);
}
check(src0.exp >= src1.exp);
check(src0.sig == 0);
/* Lấy số mũ. */
const u16 exp0 = src0.exp;
const u16 exp1 = src1.exp;
check(exp0 > 0);
check(exp1 > 0);
check(exp0 < 255);
check(exp1 < 255);
/* Lấy giá trị dịch chuyển mantissa. */
check(exp0 >= exp1);
const u16 shf = exp0 - exp1;
check(shf <= 253);
/* Tạo các mantissa với bit 1 ẩn đặt tại offset 31.
* Mọi thứ trong khoảng [32, 63] đều bằng 0.
* Mọi thứ trong khoảng [0, 23] đều bằng 0. */
const u64 mnt0 = bf16_frc_to_arr(src0);
u64 mnt1 = bf16_frc_to_arr(src1);
/* Dịch chuyển @mnt1 để khớp với số mũ của @src0.
* Chỉ có 32 bit có nghĩa.
* Nếu dịch phải lớn hơn hoặc bằng 32, @src0 về cơ bản là 0. */
mnt1 = (shf >= 32) ? 0 : (mnt1 >> shf);
/* Sau khi dịch, mnt0 nên lớn hơn hoặc bằng mnt1. */
check(mnt0 >= mnt1);
/* Thực hiện phép tính. */
const u1 sub = (bf16_is_neg(src1));
const u64 mntr = sub ? mnt0 - mnt1 : mnt0 + mnt1;
/* Khởi tạo phần dấu của kết quả. */
bf16 res;
res.sig = neg;
/* Nếu có bit trong khoảng [32, 63] (tràn), dịch phải và cập nhật số mũ. */
if (mntr >> 32) {
/* Chỉ một bit tràn đơn là có nghĩa. */
check(!(mntr >> 33));
/* Chỉ xảy ra sau phép trừ. */
check(!sub);
/* Sử dụng số mũ của src0 và tăng dần. */
check(exp0 < 255);
u16 expr = exp0 + 1;
check(expr > exp0);
/* Nếu là vô cực, làm tròn xuống. */
if (expr == 255) {
res.frc = 0x7f;
res.exp = 254;
}
/* Ngược lại, chỉ cần sử dụng số mũ này và dịch phải mantissa 1. */
else {
res.frc = ((mntr >> 1) >> 24) & 0x7f;
res.exp = expr;
}
}
/* Nếu không có bit nào trong khoảng [32, 63], dịch trái và cập nhật số mũ. */
else {
/* Nếu bit 31 không được thiết lập, kiểm tra xem phép trừ đã thực hiện chưa. */
check((mntr & (1 << 31)) || sub);
/* Xác định chỉ số của bit được thiết lập đầu tiên và số lượng dịch chuyển.
* Chúng ta dịch tối đa là 31. */
u64 mnt_shf = 0;
u8 shf_cnt = 0;
for (shf_cnt = 0; shf_cnt <= 31; shf_cnt++) {
const u64 mnt_shf = mntr << shf_cnt;
if (mnt_shf & (1 << 31)) {
goto found;
}
}
/* Nếu không tìm thấy, mặc định là 0. */
goto zero;
found:;
/* Nếu số lượng dịch chuyển để lại số mũ > 0,
* tính toán kết quả. */
if (exp0 > shf_cnt) {
check(mnt_shf & (1 << 31));
res.frc = (mnt_shf >> 24) & 0x7f;
res.exp = exp0 - shf_cnt;
}
/* Trường hợp bằng 0.
* Gặp nếu không tìm thấy bit được thiết lập hoặc nếu số lượng dịch chuyển
* lớn hơn số mũ. */
else {
zero:;
res.frc = 0;
res.exp = 0;
}
}
/* Swap không quan trọng vì chúng ta đang thực hiện tổng.
* Dấu (neg) đã được xử lý khi khởi tạo. */
/* Hoàn tất. */
return res;
}
int main() {
bf16 f0 = {.frc = 0, .exp = 1, .sig = 0};
bf16 r = bf16_add(f0, f0);
return 0;
}
Chương 2#
Tôi biết bạn đang nghĩ gì: Chúng ta đã có một bản triển khai bằng C, nó hoạt động tốt, vậy tại sao bài viết này vẫn dài như vậy? Có phải phần bình luận đang rất sôi nổi không?
Tôi có thể về nhà được chưa?
Bạn còn nhớ chúng ta đã nói về việc thực hiện số thực dấu phẩy động (floating point) từ con số 0 chứ?
ĐÚNG VẬY ĐÓ!?
Chỉ dùng code là không đủ, chúng ta cần đi sâu hơn nữa!
Xây dựng phần khó#
Vậy cái gì mang tính "từ con số 0" hơn cả code C?
Không, chúng ta sẽ tự xây dựng phần cứng FPU của riêng mình từ các bóng bán dẫn, tối ưu hóa nó hết mức có thể, và sau đó, chúng ta sẽ đưa nó lên chip và sản xuất thử nghiệm (tape out)!
Các quy tắc triển khai ASIC#
Phần tiếp theo đây là một cái nhìn tổng quan đơn giản hóa, nhằm cung cấp cho những độc giả chưa quen với thiết kế phần cứng các kiến thức nền tảng để hiểu về những hạn chế trong thiết kế phần cứng.
Nếu bạn đã từng tìm hiểu về lĩnh vực này rồi, bạn có thể bỏ qua phần này.
Phần cứng kỹ thuật số được xây dựng bằng cách kết nối các nhóm bóng bán dẫn được sắp xếp sẵn gọi là các "cell". Các cell này có thể tương ứng với các thao tác logic cơ bản. Đây là ví dụ về một cổng logic: 2 đầu vào OR mà kết quả của nó sau đó được AND với một đầu vào khác.
Logic này có thể được viết là:
X = ((A1 | A2) & B1) Hoặc được biểu diễn bằng sơ đồ sau:

Vì các cổng này được xây dựng từ các bóng bán dẫn, chúng đặc thù cho một quy trình chế tạo được gọi là "node". Đây là hình ảnh hàm này trông như thế nào đối với node Skywater 130nm A:

Các cell này chiếm một diện tích trên chip tỷ lệ thuận với số lượng bóng bán dẫn cần thiết để xây dựng chúng; càng nhiều bóng bán dẫn thì diện tích càng lớn. Khi chế tạo chip, diện tích càng lớn thì chi phí chế tạo càng cao. Ngoài ra, diện tích của một chức năng càng lớn, các logic càng nằm xa nhau, dây dẫn càng dài, độ trễ dây càng cao, điều này ảnh hưởng đến timing (thời gian thực thi).
Timing là gì?
Hãy tưởng tượng một thế giới nơi các hạt mang điện lan truyền như nước: cần có thời gian để hạt truyền qua các cổng logic và dây dẫn. Bạn càng có nhiều cổng logic trên đường đi, bạn càng cần nhiều độ dài dây, thời gian càng lâu. Mật độ của các hạt này biểu thị trạng thái nhị phân của bạn: 0 hoặc 1, và để chip của bạn hoạt động ổn định, bạn cần để đủ thời gian cho dòng hạt truyền hoàn toàn qua con đường dài nhất của mình.
Thời gian bạn để lại ảnh hưởng trực tiếp đến tốc độ xung nhịp (clock) của phần cứng và do đó ảnh hưởng đến hiệu suất mà bạn có thể đạt được từ thiết kế của mình.
Tối ưu hóa#
Được rồi, chúng ta không chỉ ở đây để xây dựng một bộ FPU, chúng ta ở đây để xây dựng một phiên bản được tối ưu hóa.
Bây giờ bạn có thể tự hỏi tại sao tôi lại thêm ràng buộc bổ sung về tối ưu hóa. Đó là vì việc xây dựng một phiên bản tối ưu của thứ gì đó đòi hỏi sự hiểu biết sâu sắc và tinh tế hơn nhiều so với việc chỉ xây dựng một thứ gì đó hoạt động được. Vì có nhiều khía cạnh mà chúng ta có thể tối ưu hóa, trong dự án này, tôi sẽ định nghĩa "tối ưu hóa" là đạt được diện tích nhỏ nhất có thể, cho tần suất hoạt động cao nhất có thể với chức năng nhất định. Đây là giá trị tốt nhất cho công sức bỏ ra.
Tóm lại, chúng ta đang xây dựng phần cứng và trong phần cứng, mọi logic đều tốn kém cả về diện tích lẫn timing, và chúng ta muốn xây dựng phiên bản tối ưu nhất theo đúng các thước đo này.
Tuyệt thật… Mình lại vừa dấn thân vào cái gì thế này?
Chúng ta cần những gì#
Vì vậy, do mọi logic chúng ta thêm vào đều có cái giá của nó, bước 1 là hãy lùi lại một chút và suy nghĩ xem chúng ta thực sự cần xây dựng cái gì.
Có rất nhiều định dạng số thực dấu phẩy động khác nhau, từ các kiểu IEEE tiêu chuẩn cho đến những định dạng kỳ lạ tùy chỉnh theo ứng dụng như số float của Pixar.
Sẽ thật tuyệt nếu chúng ta sống trong một chiều không gian nơi có thể ném tất cả chúng vào một đấu trường và để chúng chiến đấu đến chết. Nhưng bi kịch thay, chúng ta không thể làm điều đó với các khái niệm trừu tượng. Vậy nên giờ chúng ta buộc phải ngồi xuống và suy nghĩ về nó… uh
Vâng, bạn đọc đúng rồi đấy, đây không phải là ảo giác AI, và tôi cũng không nói về bộ phim ngắn năm 2019.
Bạn có biết Pixar có kiểu số thực dấu phẩy động 24-bit riêng được điều chỉnh cho trường hợp sử dụng của họ không? Pixar có lẽ là một trong những công ty công nghệ bị đánh giá thấp nhất: hầu hết mọi người không biết phần cứng kết xuất (rendering) của họ đã được tùy chỉnh đến mức nào trong quá khứ. Ngoài ra, bạn đã bao giờ nghe nói về Pixar Image Computer chưa?
Hãy cẩn thận, hố thỏ này rất sâu đấy.
Một mặt, chúng ta có các kiểu float IEEE, đây là các kiểu float tiêu chuẩn công nghiệp. Việc tuân thủ đảm bảo rằng cùng một phép toán dấu phẩy động sẽ có cùng hành vi bất kể phần cứng chạy nó là gì, điều mà khách hàng của bạn thực sự muốn. (Trừ khi phần cứng của bạn có lỗi, trong trường hợp đó bạn đã cố gắng tuân thủ. Chào Intel 👋: internet vẫn chưa quên đâu). Nhưng việc tuân thủ đòi hỏi phải hỗ trợ các số subnormal, NaN, \(\pm\infty\) và 5 chế độ làm tròn khác nhau.
Sau đó là vấn đề kích thước: dung lượng bộ nhớ của bạn lớn đến mức nào, và sau đó, bạn phân bổ các bit của mình như thế nào trên các trường số mũ (exponent) và phần định trị (significant)?
Một số tùy chọn là:
float16, IEEE 754 độ chính xác một nửa: 5 bit số mũ, 10 bit định trịfloat32, IEEE 754 độ chính xác đơn: 8 bit số mũ, 23 bit định trịfloat64, IEEE 754 độ chính xác kép: 11 bit số mũ, 52 bit định trị- Định dạng PXR24 của Pixar, 8 bit số mũ, 15 bit định trị
tf32, TensorFloat-32 của Nvidia là định dạng 19 bit. Tôi biết mà, tại sao họ lại để bộ phận marketing đặt tên như thế này chứ? 8 bit số mũ, 10 bit định trịbfloat16, định dạng brain float của Google: 8 bit số mũ, 7 bit định trị
Kích thước chúng ta chọn cuối cùng phụ thuộc vào nhu cầu khối lượng công việc của chúng ta. Một số công việc cần độ chính xác cao hơn, đòi hỏi nhiều bit định trị hơn, những công việc khác lại được hưởng lợi từ các định dạng nhỏ hơn cho phép chúng vượt qua giới hạn băng thông bộ nhớ.
Vì vậy, một lần nữa, câu trả lời là: tùy trường hợp! Cảm ơn bạn đã đọc!
Nghiêm túc hơn một chút, hãy làm rõ những gì chúng ta thực sự đang xây dựng, bởi vì phép tính dấu phẩy động này sẽ là một phần của một dự án lớn hơn, nếu không thì chẳng có gì thú vị cả. Nhưng để tối đa hóa yếu tố thú vị, chúng ta cần một dự án đòi hỏi RẤT NHIỀU phép toán dấu phẩy động.
Thật may mắn là tôi lại biết đúng kiến trúc tăng tốc cho tác vụ này: một mảng tâm thu (systolic array) nhân ma trận với ma trận! Các loại bộ tăng tốc này được sử dụng rộng rãi trong các bộ tăng tốc học máy nhắm vào cả tác vụ huấn luyện và suy luận (khi việc lượng tử hóa làm giảm độ chính xác quá nhiều). Bây giờ, tôi không định xây dựng một bộ tăng tốc AI, đây chỉ là một cái cớ thuận tiện để nhồi nhét quá nhiều phép tính dấu phẩy động vào con chip của mình mà thôi.
Tuyệt vời, bây giờ chúng ta đã có cái cớ và biết ứng dụng mà chúng ta đang nhắm tới, hãy xem xét các ràng buộc của khối lượng công việc này.
Thứ nhất, chúng ta không xây dựng một đơn vị FPU cho CPU với các client bên ngoài. Chúng ta có thể tùy chỉnh, điều này cho phép chúng ta vứt bỏ sự tương thích IEEE 754 và 5 chế độ làm tròn của nó trở lại hố sâu địa ngục nơi nó chui ra. Mặc dù vậy, để tạo ra các vector kiểm thử cho việc thực thi số học dấu phẩy động, tôi muốn chọn một định dạng bớt bí mật hơn. Ngoài ra, bất kỳ định dạng nào dễ dàng chuyển đổi qua lại với các kiểu IEEE được hỗ trợ rộng rãi đều được cộng thêm điểm. Điều này sẽ đơn giản hóa khả năng tương tác giữa bộ tăng tốc và firmware điều khiển nó.
Thứ hai, chip của tôi sẽ bị nghẽn IO (đối với những ai đã theo dõi blog này: vâng, lại là nó 🔥) nên lựa chọn của tôi sẽ là một trong các minifloat, thuật ngữ này chỉ các số thực có độ rộng nhỏ hơn 32 bit. Bạn thấy đấy, tôi không chọn cái này chỉ vì cái tên nghe dễ thương đâu, còn có những lý do kỹ thuật đằng sau nữa.
Vì chúng ta đang nhắm tới một định dạng nhỏ hơn, chúng ta cần phải cân nhắc kỹ lưỡng hơn về cách phân chia giữa số mũ (exponent) và phần định trị (significant). Việc hy sinh các bit số mũ sẽ làm giảm phạm vi biểu diễn, nhưng nếu cắt giảm phần định trị sẽ làm giảm độ chính xác của các số mà chúng ta có thể biểu diễn. Bây giờ, chúng ta cũng có thể tiếp cận câu hỏi về việc phân chia này từ góc độ phần cứng bằng cách xem xét nó sẽ tác động như thế nào đến việc thực thi phép nhân và phép cộng.
Hãy xem xét phép nhân, thao tác tốn kém nhất trong phép nhân dấu phẩy động là nhân các phần định trị. Việc này bao gồm một phép nhân không dấu có độ rộng <significant bits> + 1, và chi phí phần cứng của một phép nhân không hề tăng tuyến tính: chi phí phần cứng cho việc nhân phần định trị 8 bit của bfloat16 chỉ bằng khoảng một nửa so với phép nhân phần định trị 11 bit của float16.
Các phần định trị nhỏ bắt đầu nghe có vẻ rất hấp dẫn.
Quay lại nhu cầu ứng dụng của chúng ta, các khối lượng công việc AI có đặc tính thú vị là tương đối không nhạy cảm với việc mất độ chính xác, điều này được minh chứng qua việc lượng tử hóa thậm chí còn khả thi. Mặt khác, chúng được hưởng lợi từ việc có phạm vi biểu diễn rộng hơn.
- chỉ rộng 16 bit
- mantissa nhỏ: 7 bit
- định dạng phổ biến: đây không phải là một phát minh tùy chỉnh và thậm chí còn có hỗ trợ từ thư viện chuẩn C++
- dễ dàng chuyển đổi sang
float32: chỉ cần cắt bớt các bit mantissa (với một vài lưu ý mà chúng ta sẽ đề cập sau) - không phải là kiểu IEEE 754
Một điều tuyệt vời về bfloat16 là nó không có quy chuẩn, vì vậy chúng ta có thể thực thi nó theo bất kỳ cách nào chúng ta muốn!
Một điều khủng khiếp về bfloat16 là nó không có quy chuẩn, vì vậy chúng ta có thể thực thi nó theo bất kỳ cách nào chúng ta muốn!
Dự án này là một bài học tuyệt vời về lý do tại sao chúng ta cần IEEE duy trì truyền thống lâu đời là thu hút các kỹ sư bằng lời hứa về bánh donut miễn phí và nhốt họ trong phòng cho đến khi một quy chuẩn được tạo ra!
Hóa ra, khi bạn không có quy chuẩn, bạn có thể thực thi thứ gì đó theo bất kỳ cách nào bạn muốn, nên đương nhiên mỗi người làm một kiểu khác nhau!
Bây giờ, chúng ta đang xây dựng một bộ tăng tốc tùy chỉnh, nên khả năng tương thích với hoạt động bfloat16 không phải là vấn đề quá lớn, vấn đề là chúng ta cần tự chọn xem mình muốn "topping" nào cho hương vị toán học dấu phẩy động của mình.
Câu hỏi đầu tiên cần giải quyết là các chế độ làm tròn.
Chúng ta cần chọn ít nhất một, và để kiểm thử với các vector kiểm thử đã biết, nó cần phải là một trong các chế độ của IEEE. Trong số 5 chế độ trong quy chuẩn, làm tròn về 0 (round towards zero) là cách thuận tiện nhất và rẻ nhất để thực thi trên phần cứng. Không giống như những chế độ khác, bạn không bao giờ cần phải làm tròn lên giá trị dấu phẩy động tiếp theo, cho phép tôi bỏ qua nhu cầu về một phép cộng 16 bit ở phần cuối (được đặt hoàn hảo ngay trên đường găng - critical path để gây áp lực tối đa cho timing) của phép cộng.
Nhưng, RZ (làm tròn về 0) có một ưu điểm to lớn khác, đó là hành vi của nó khi xảy ra tràn số:RZ không tràn đến \(\pm\infty\) mà nó kẹp giá trị (clamp)!
Điều này có nghĩa là, miễn là không có \(\infty\) nào được cung cấp làm đầu vào cho các phép cộng và phép nhân của tôi, chúng sẽ không bao giờ tạo ra \(\infty\). Vì vậy, bằng cách không cho phép sử dụng \(\infty\) làm đầu vào, tôi có thể loại bỏ hoàn toàn việc hỗ trợ \(\infty\) và tiết kiệm tài nguyên phần cứng.
Nhưng, còn tuyệt hơn thế: các thao tác duy nhất tạo ra NaN một cách tự nhiên trong các phép cộng và nhân là khi thực hiện với \(\infty\). Vì vậy, nếu tôi cũng không cho phép NaN làm giá trị đầu vào, tôi cũng có thể loại bỏ chi phí phần cứng để hỗ trợ chúng.
Cuối cùng, chúng ta có câu hỏi về việc hỗ trợ số phi chuẩn (denormal), có lẽ là câu hỏi ít gây tranh cãi nhất trong thiết kế bfloat16: 126 giá trị phi chuẩn bổ sung không đáng để ta phải phiền lòng về phần cứng, loại bỏ.
Tóm lại, đơn đặt hàng kem của chúng ta là 🍨:
bfloat16: 1 bit dấu, 8 bit số mũ, 7 bit định trị- chỉ làm tròn về 0
- không hỗ trợ số subnormal, tất cả các số subnormal sẽ được kẹp về \(\pm0.0\)
- không hỗ trợ \(\pm\infty\) hoặc
NaN
Kiến trúc#
Bây giờ chúng ta đã hoàn thành phần khó đầu tiên là quyết định xem mình muốn xây dựng cái gì, chúng ta cần làm phần khó thứ hai: thiết kế kiến trúc cho nó.
Đối với các thao tác ma trận, chúng ta sẽ cần cả bộ cộng và bộ nhân.
Vì bài viết này đang khá dài và bộ nhân thực sự khá dễ xây dựng khi bạn đã biết cách thiết kế phép nhân mantissa hiệu quả (gợi ý: bộ nhân không dấu booth radix-4), tôi sẽ tập trung vào thiết kế bộ cộng phức tạp và tinh vi hơn.
Cách tiếp cận ngây thơ khi thiết kế bộ cộng là thực hiện bộ cộng một đường dẫn (single path adder): nơi tất cả các bước được thực hiện trên cùng một đường dẫn, tương tự như ví dụ mã C. Mặc dù đơn giản về mặt khái niệm và hiệu quả về mặt diện tích do không trùng lặp logic, nhưng do độ sâu của đường dẫn đơn này, kiến trúc này rất đắt đỏ về mặt hiệu năng.
Đây không phải là thiết kế tồi và nếu chúng ta tập trung hoàn toàn vào việc tối ưu hóa diện tích, đây có thể là một ứng cử viên khả thi, nhưng chúng ta có yêu cầu kép về cả diện tích và hiệu năng, vì vậy chúng ta phải làm tốt hơn.
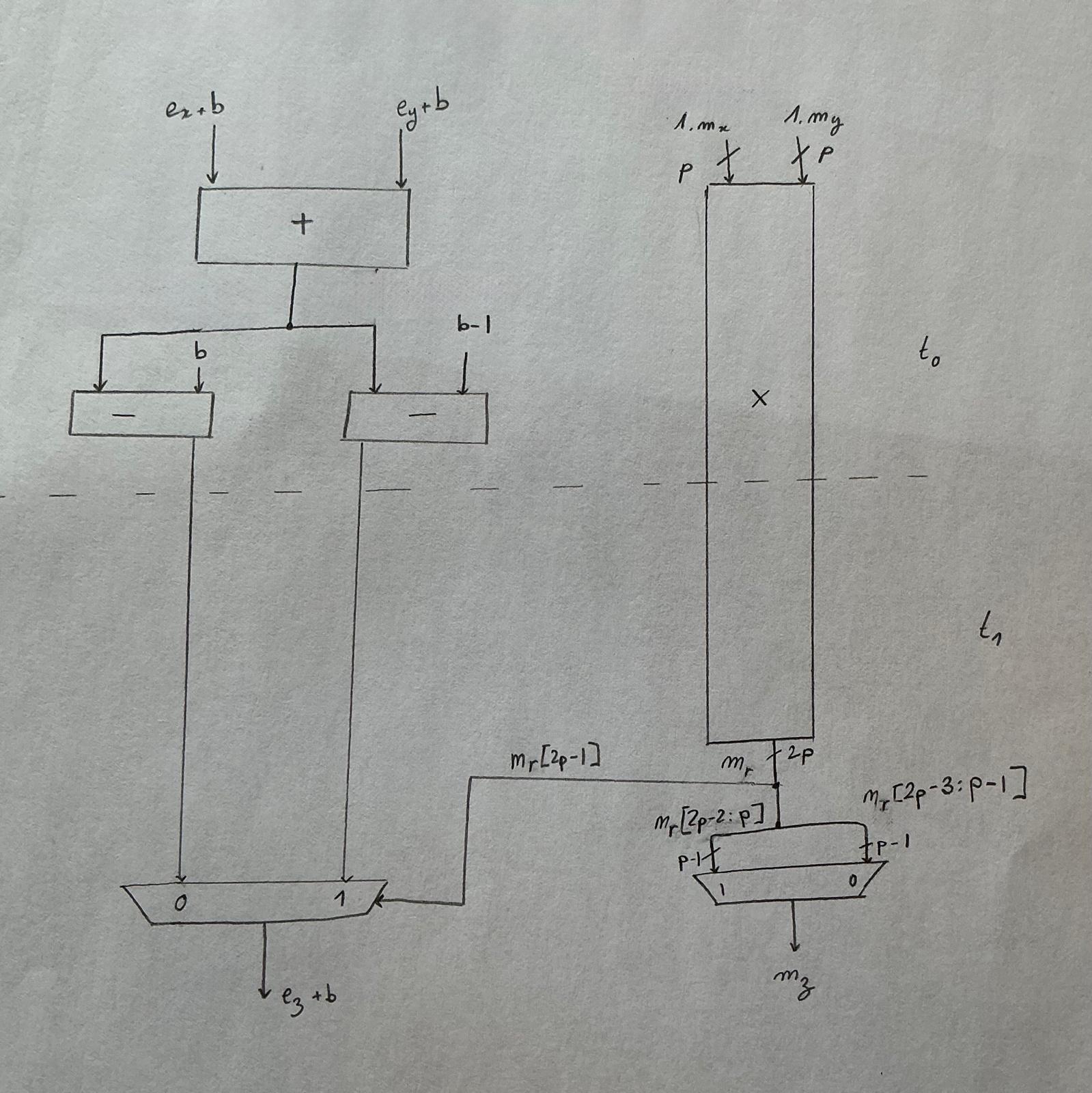
Nhìn lại thuật toán cộng, chúng ta nhận thấy rằng các phép triệt tiêu lớn và dịch chuyển mantissa thực tế loại trừ lẫn nhau. Những phép triệt tiêu mà chúng ta cần đếm các số 0 đứng trước (leading zeros) của phần hiệu mantissa và trừ nhiều hơn 1 từ số mũ trước khi chuẩn hóa chỉ xảy ra khi hiệu số mũ của hai toán hạng nhỏ hơn 2 VÀ chúng ta đang thực hiện một phép trừ thực sự.
Dựa trên điều này, và với cái giá là một chút trùng lặp chức năng nhỏ, chúng ta có thể chia bộ cộng của mình thành 2 đường dẫn:
- đường dẫn gần (close path): hiệu số mũ < 2 và trừ thực sự
- đường dẫn xa (far path): hiệu số mũ < 2 và cộng thực sự hoặc hiệu số mũ >= 2
Kiến trúc phân chia này được gọi là kiến trúc đường dẫn kép (dual path architecture) và là kiến trúc bộ cộng thực tế (de facto) cho FPU hiệu năng cao kể từ những năm 80.
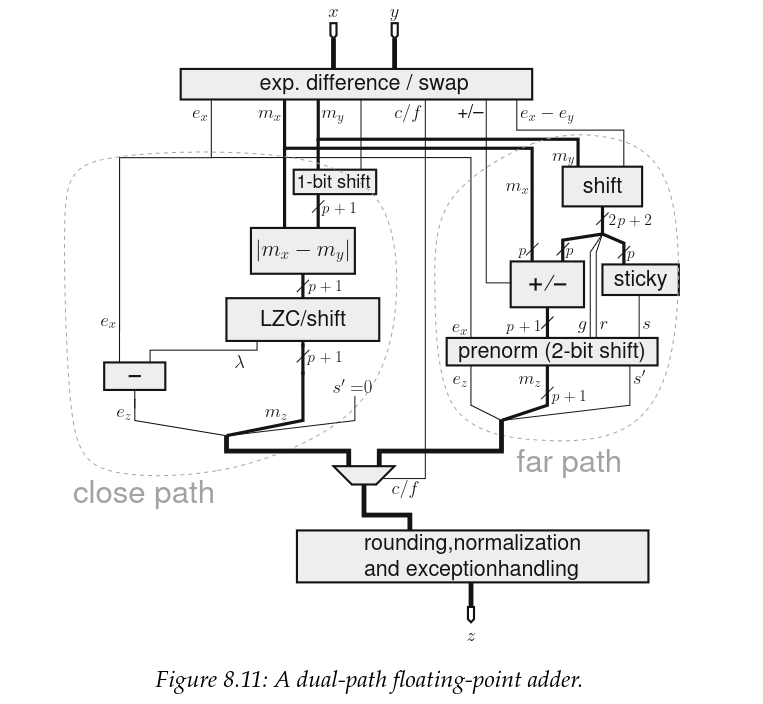
Nguồn: Handbook of Floating-Point Arithmetic, ấn bản lần thứ hai
Giờ thì, sơ đồ này thực tế dành cho số thực dấu phẩy động tuân thủ chuẩn IEEE, và chúng ta không thiết kế cho trường hợp tổng quát. Vậy điều này thay đổi thế nào đối với chúng ta?
Hãy nhớ lại cách chúng ta chỉ thực hiện làm tròn RZ (Round to Zero)? RZ là một cách kẹp (clamping) phần định trị hiệu quả bất cứ khi nào có liên quan đến việc làm tròn, điều này có nghĩa là chúng ta sẽ không bao giờ cần làm tròn lên, và đồng nghĩa với việc chúng ta có thể loại bỏ tất cả các logic phục vụ cho mục đích này.
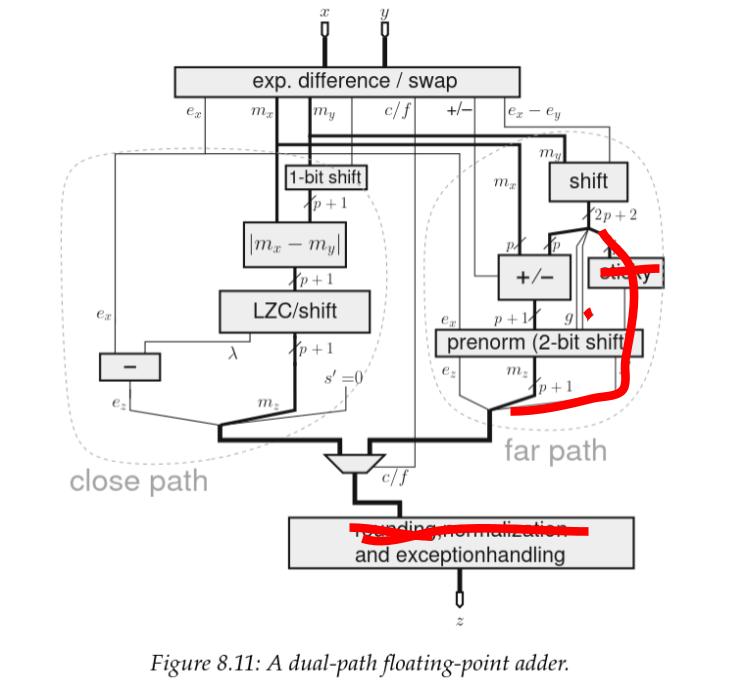
Tiếp theo, vì chúng ta áp đặt rằng không có NaN hay \(\infty\) nào được sử dụng làm toán hạng, nên chúng ta không có cách nào để kích hoạt ngoại lệ, vì vậy phần này cũng bị loại bỏ.
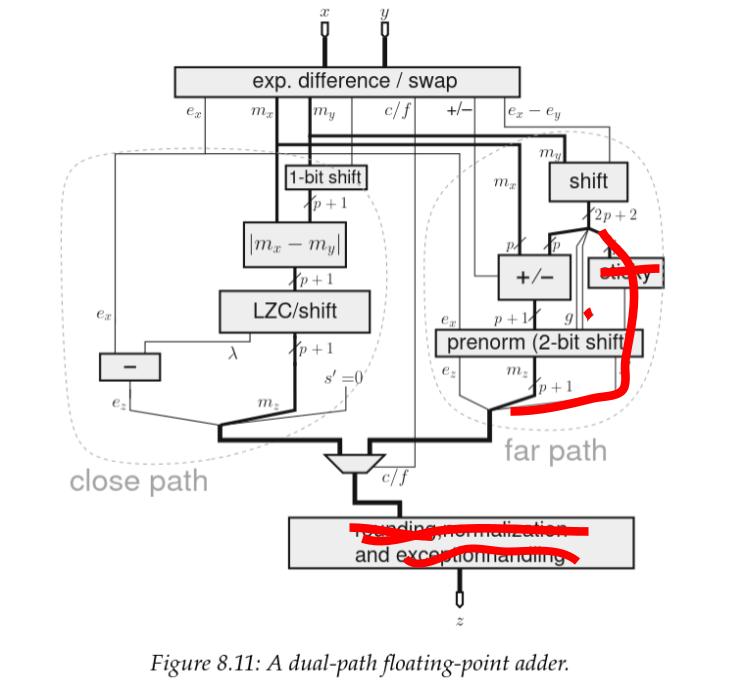
Sơ đồ này không minh họa cách xử lý các số subnormal, nhưng việc triển khai của chúng ta cũng tiết kiệm logic ở đó. Mặc dù vậy, chúng ta vẫn cần một số logic để phát hiện khi chúng xuất hiện và kẹp chúng về \(0\). Trên đường dẫn đóng (close path), chức năng này được gộp vào một khối mà tôi sẽ dán nhãn là "normalize" nằm trên đường dẫn tới hạn (critical path) của chúng ta, ngay sau phần dịch chuyển significant đa bit và phép trừ số mũ.
Thiết kế cuối cùng trông đại loại như thế này:
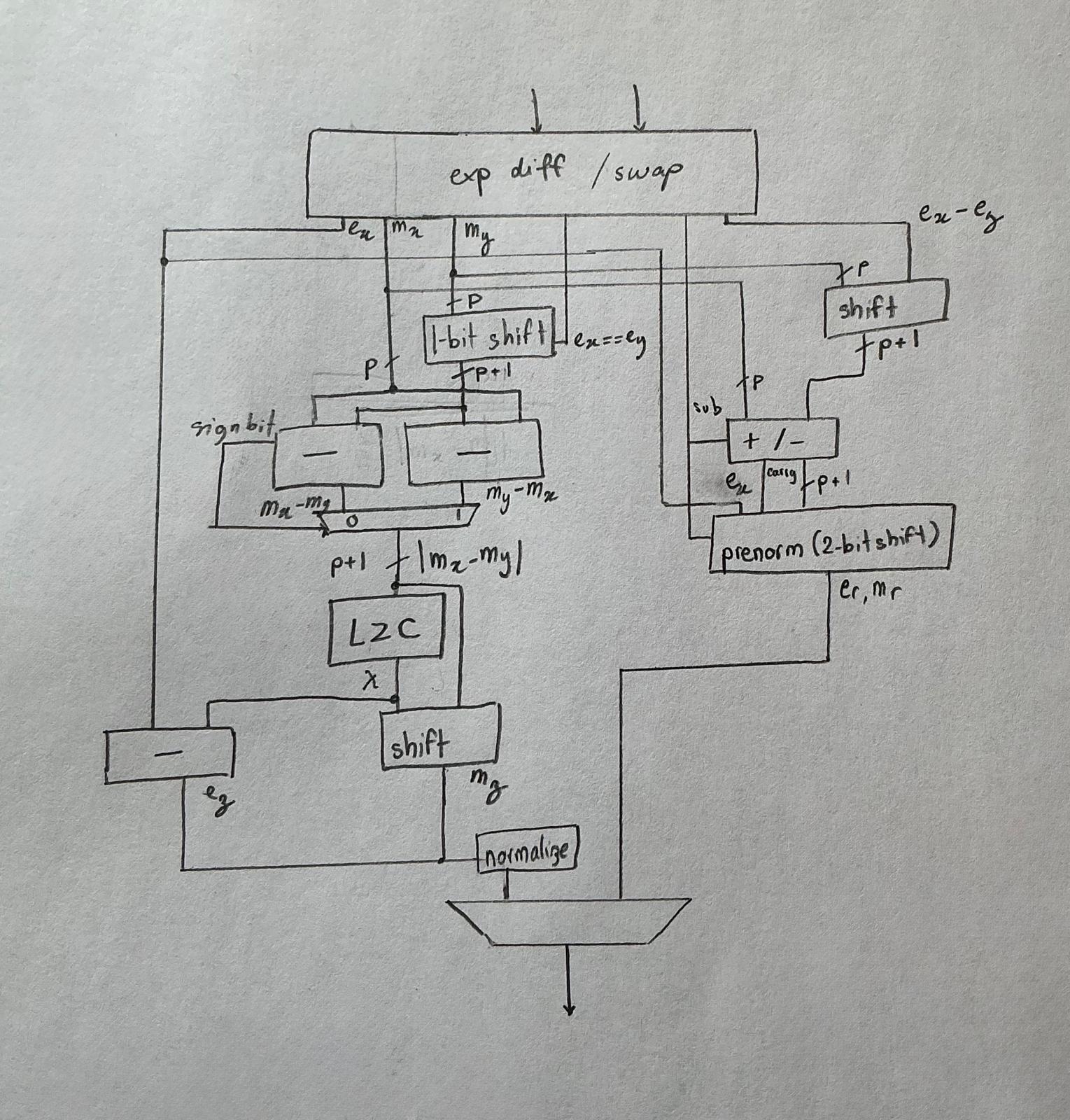
Chương 3: Lý thuyết gặp thực tế#
Xác minh#
Lý thuyết thì thú vị nhưng trừ khi nó chứng minh được rằng nó có thể đứng vững trước thực tế, còn không thì chẳng có gì chứng minh nó đúng cả. Vì vậy, không có cách nào tốt hơn để kiểm chứng sự hiểu biết của một người bằng việc quăng nó vào thực tế khắc nghiệt.
Ngoài ra, đây không chỉ là một thí nghiệm tư duy, chúng ta thực sự đang hiện thực hóa nó trên silicon thật, và nếu những tổn thương trong quá khứ của tôi với phần cứng đã khắc ghi vào tâm trí tôi một bài học, thì đó là: cho đến khi bạn chứng minh được nó hoạt động, thì nó vẫn đang bị hỏng!
Đã đến lúc chạy một vài bài kiểm thử!
Kiểm thử phần cứng số học dấu phẩy động thực sự là một thách thức thú vị vì nó chứa đầy các trường hợp biên (corner cases): bạn không thể chỉ kiểm thử 100 giá trị ngẫu nhiên rồi xong chuyện. Không, bạn cần bao phủ toàn diện cho tất cả các góc cạnh này, phần lớn trong số đó bạn thậm chí còn không biết là nó tồn tại. Đây thực sự là vấn đề “bạn không biết là bạn không biết”. Vậy, kế hoạch cho việc này là gì?
Đây là nơi tôi phạm tội ác đối với việc xác minh: kiểm thử dựa trên mô phỏng có hướng (directed simulation driven testing) tỉ lệ thuận với kích thước của không gian đầu vào, một cách nói hoa mỹ để chỉ việc nó không tỉ lệ tuyến tính. Đây là lý do tại sao các phương pháp hình thức (formal methods) ngày càng phổ biến cho việc xác minh dấu phẩy động. Nếu chúng ta muốn kiểm thử việc này bằng kiểm thử có hướng, chúng ta sẽ cần kiểm thử cho tất cả \(2^{32}\) tổ hợp đầu vào, nghe có vẻ là một ý tưởng tồi tệ…
… và chính xác là những gì tôi sẽ làm vì đó là cách duy nhất để kiểm thử toàn diện tất cả các trường hợp biên mà không cần có kiến thức trước về việc tất cả các góc cạnh nằm ở đâu.
Đây là vấn đề ở bậc thiếu hiểu biết thứ hai.
Điều này tạo ra vấn đề tiếp theo cho chúng ta: thời gian kiểm thử, mất bao lâu để kiểm thử hơn 4 tỷ tổ hợp? Bởi vì tôi tin rằng thời gian lặp lại ngắn là tối quan trọng để hoàn thành công việc, tôi cần testbench này chạy nhanh, vì vậy tôi cần một trình mô phỏng nhanh và một mô hình chuẩn (golden model).
Hãy đến với verilator, tương tự như Synopsis vcs, nó biên dịch mô phỏng của bạn thành một tệp thực thi có thể chạy trực tiếp trên máy của bạn, khiến nó trở thành trình mô phỏng mã nguồn mở nhanh nhất hiện nay.
Tiếp theo là mô hình chuẩn, và tình cờ là chúng ta đang sống trong năm 2026 và thư viện chuẩn C++23 đã giới thiệu kiểu bfloat16 trong stdfloat.
Cuối cùng, chúng ta có thể sử dụng giao diện DPI-C (chứ không phải giao diện VPI chậm chạp hơn) để gọi các mô hình chuẩn tùy chỉnh của chúng ta đã được viết bằng C++ và biên dịch vào testbench.
Nghe có vẻ là một kế hoạch hoàn hảo… cho đến khi C++ phản bội tôi.
bfloat16 của stdfloat thực sự hoạt động như thế nào ?#
Nhưng trước khi đi sâu vào việc tại sao mô hình chuẩn của tôi hóa ra lại không "chuẩn" đến thế, chúng ta cần hiểu cách kiểu bfloat16 trong stdfloat thực sự hoạt động bên dưới.
Quan trọng là máy tính của tôi thực sự không có phần cứng bfloat16 nguyên bản, vậy nó thực hiện tính toán bằng cách nào?
Hãy kiểm thử nó bằng một phép cộng đơn giản:
#include <stdfloat>
int main(){
bfloat16_t a,b,c;
a = 1.0;
b = 1.0;
c = a + b;
return 0;
}
Nhìn vào mã dịch ngược (disassembly) của chương trình kiểm thử này, chúng ta có thể thấy rằng gcc xử lý phép cộng bfloat16 bằng cách sử dụng các hàm thay thế dấu phẩy động mềm bfloat16 (__extendbfsf2, __truncsfbf2 + mã wrapper).
Điều này cho thấy rằng phần cứng hiện tại của tôi hoặc không hỗ trợ phần cứng cho bfloat16, hoặc là sự hỗ trợ đó không được thông báo cho trình biên dịch.
4 int main(){
0x0000000000001119 <+0>: push %rbp
0x000000000000111a <+1>: mov %rsp,%rbp
0x000000000000111d <+4>: sub $0x20,%rsp
5 bfloat16_t a, b, c;
6
7 a = 1.0;
0x0000000000001121 <+8>: movzwl 0xee4(%rip),%eax # 0x200c
0x0000000000001128 <+15>: mov %ax,-0x6(%rbp)
8 b = 1.0;
0x000000000000112c <+19>: movzwl 0xed9(%rip),%eax # 0x200c
0x0000000000001133 <+26>: mov %ax,-0x4(%rbp)
9 c = a+b;
0x0000000000001137 <+30>: pinsrw $0x0,-0x6(%rbp),%xmm0
0x000000000000113d <+36>: call 0x1180 <__extendbfsf2>
0x0000000000001142 <+41>: movss %xmm0,-0x14(%rbp)
0x0000000000001147 <+46>: pinsrw $0x0,-0x4(%rbp),%xmm0
0x000000000000114d <+52>: call 0x1180 <__extendbfsf2>
0x0000000000001152 <+57>: movaps %xmm0,%xmm1
0x0000000000001155 <+60>: addss -0x14(%rbp),%xmm1
0x000000000000115a <+65>: movd %xmm1,%eax
0x000000000000115e <+69>: movd %eax,%xmm0
0x0000000000001162 <+73>: call 0x1250 <__truncsfbf2>
0x0000000000001167 <+78>: movd %xmm0,%eax
0x000000000000116b <+82>: mov %ax,-0x2(%rbp)
10
11 return 0;
0x000000000000116f <+86>: mov $0x0,%eax
12 }
0x0000000000001174 <+91>: leave
0x0000000000001175 <+92>: ret Dựa trên mã assembly này, hành vi mong đợi đối với bfloat16_t sẽ tương tự như một float32_t được cắt bớt (clamped down).
Điều này hoàn toàn hợp lệ, vì hành vi của bfloat16 không được quy định đầy đủ bởi bất kỳ đặc tả nào, do đó nó được xác định tùy theo cách triển khai. 🌈
Thăm dò việc triển khai bfloat16_t phần mềm trong thư viện chuẩn#
Vì tôi không quá thông thạo về assembly x86, tôi đã quyết định viết một chương trình kiểm thử đơn giản để thăm dò hành vi của bfloat16_t phần mềm của mình.
Từ đó, tôi biết được rằng nó:
- có hỗ trợ subnormal
- có hỗ trợ
NaN - có hỗ trợ inf
Vì vậy, tôi đã ngây thơ nghĩ rằng để sử dụng nó như một mô hình chuẩn (golden model) cho phần cứng, tất cả những gì tôi cần làm là thủ công cắt các số subnormal về 0 và không xử lý các giá trị NaN và \(\infty\).
#define IS_SUBNORMAL(x) ((isnormal(x) | isnan(x) | isinf(x) | (x == 0e0bf16))) Bị C++ phản bội#
Thế là tôi đã cắt các số subnormal và tiếp tục công việc của mình.
Nhưng khi tôi đang hăng say kiểm tra tất cả các tổ hợp toán hạng có thể, thảm họa đã ập đến.
Tôi xin trích dẫn đề xuất được công bố năm 2022 của C++ về "Các kiểu số thực mở rộng và tên chuẩn" :
7.2. Các định dạng được hỗ trợ
Chúng tôi đề xuất các bí danh cho các bố cục sau:
- [IEEE-754-2008] binary16 - IEEE 16-bit.
- [IEEE-754-2008] binary32 - IEEE 32-bit.
- [IEEE-754-2008] binary64 - IEEE 64-bit.
- [IEEE-754-2008] binary128 - IEEE 128-bit.
- bfloat16, là binary32 với 16 bit độ chính xác bị cắt bớt; xem [bfloat16]. <–
Về cơ bản, điều này có nghĩa là bfloat16_t chính xác giống như cách chúng ta đọc từ mã nhị phân: một float32_t được cắt bớt (được gọi là binary32 trong đặc tả IEEE).
Vấn đề với cách tiếp cận này là float32_t có độ chính xác nội bộ \(p\) lớn hơn nhiều so với bfloat16_t :
float32_t\(p = 24\)bfloat16_t\(p = 8\)
Trong thực tế, điều này có nghĩa là nếu tôi muốn phần cứng của mình khớp chính xác với mô hình chuẩn theo quy định của thư viện chuẩn C++, tôi sẽ cần hỗ trợ \(p = 24\), điều này trực tiếp dẫn đến một đường dẫn tính toán (significant path) rộng hơn nhiều ở mọi nơi… và đó không phải là kết quả mà tôi mong muốn.
Trong phạm vi 1 ulp#
Do cách triển khai bfloat16_t của thư viện chuẩn C++ sử dụng float32_t bên dưới, tôi không thể khớp hoàn toàn kết quả từ mô hình chuẩn của mình với đầu ra RTL mong đợi.
Điều này là do float32_t có \(p=24\) bit độ chính xác bên trong, trong khi bloat16_t có 8 bit, vì vậy với cùng các giá trị đầu vào, nếu sự khác biệt về số mũ giữa các đầu vào này nằm trong phạm vi \(]p_{bfloat16}; p_{float32}[\)!
Tôi sẽ quan sát thấy sự khác biệt trong cách làm tròn ngay cả khi chúng ta sử dụng cùng một chế độ làm tròn và cùng các toán hạng.
Một đặc tính khác của điều này là sự khác biệt này sẽ nằm trong biên độ của số dấu phẩy động liên tiếp tiếp theo.
Để giúp đơn giản hóa phần tiếp theo, hãy để tôi định nghĩa \(ulp(x)\) là “unit of last place” (đơn vị của vị trí cuối cùng), hay chính thức hơn là:
\(ulp(x)\) là khoảng cách giữa hai số dấu phẩy động gần nhất với \(x\), ngay cả khi \(x\) là một trong số đó.
Như vậy, sai số tương đối giữa bfloat16_t của mô hình chuẩn (golden model) của tôi và phần thực thi của tôi sẽ tối đa là \(1 \times ulp(x)\).
\(ulp(x)\) được định nghĩa là:
$$ ulp(x) = 2^{-p+1} $$
Đối với việc thực thi bfloat16 của tôi với \(p=8\), chúng ta có \(ulp(x) = 2^{-7}\), và tôi sẽ tính toán sai số tương đối như sau:
$$ error(x) = \frac{x_{model} - x_{hw}}{x_{model}} $$
C++ không có lỗi#
Bây giờ khi đã phàn nàn xong và làm cho mô hình chuẩn của mình hoạt động ổn định, tôi muốn chỉ ra rằng tôi nhận thấy việc mô phỏng bfloat16 từ float32 là phương pháp ưu việt cho thư viện tiêu chuẩn. Nó cho phép chuyển phần lớn khối lượng tính toán sang FPU của CPU, mang lại hiệu suất tốt hơn nhiều bậc so với việc triển khai hoàn toàn bằng phần mềm.
Chắc chắn nó có thể mang lại kết quả khác biệt, nhưng đây là điều chúng ta đã chấp nhận khi bắt đầu sử dụng bfloat16.
Triển khai#
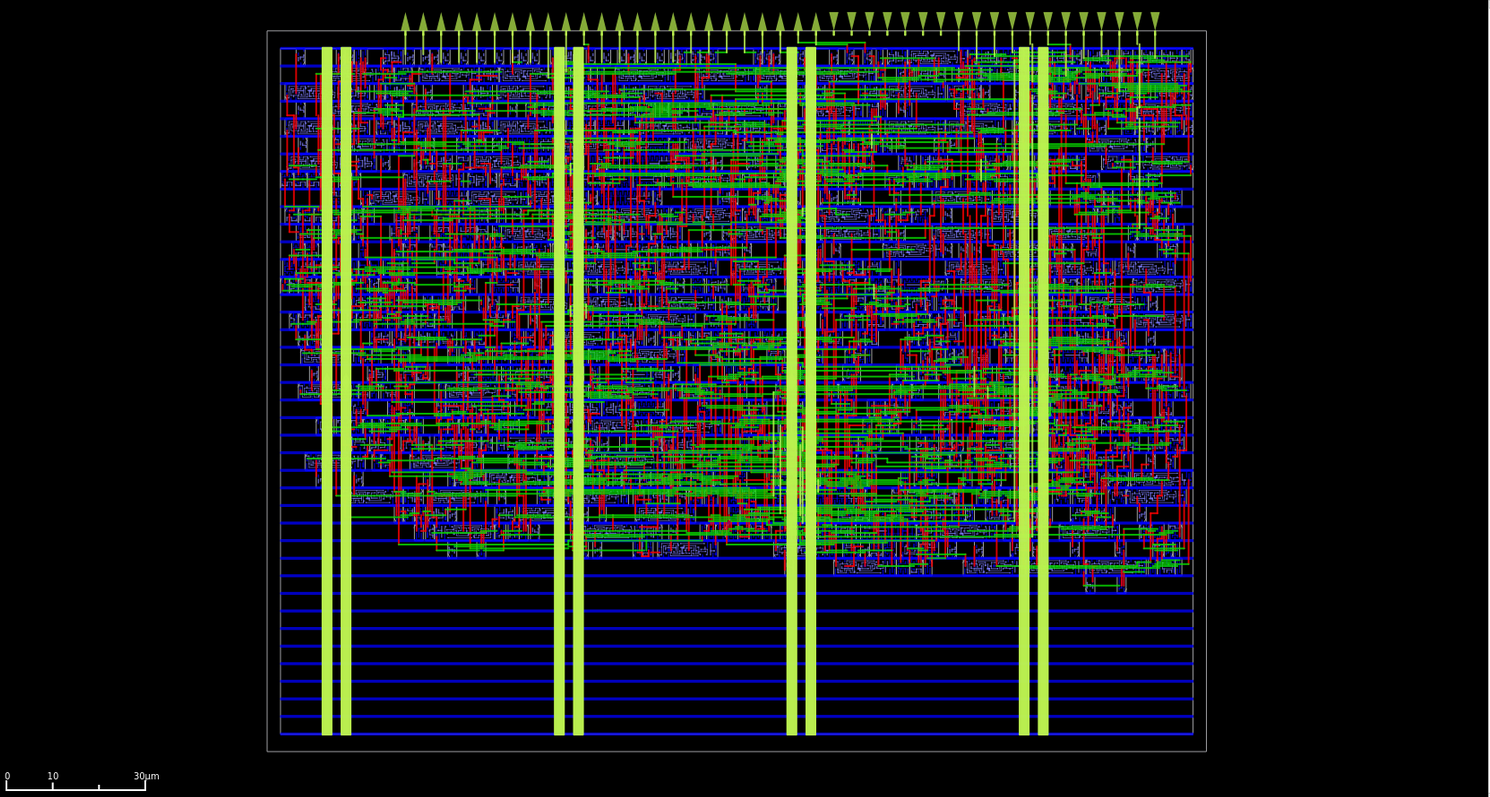
Bây giờ khi đã có một số phép tính bfloat16 hoạt động, đây là phần tôi yêu thích nhất: xây dựng nó từ những chất bán dẫn tinh thể đắt tiền.
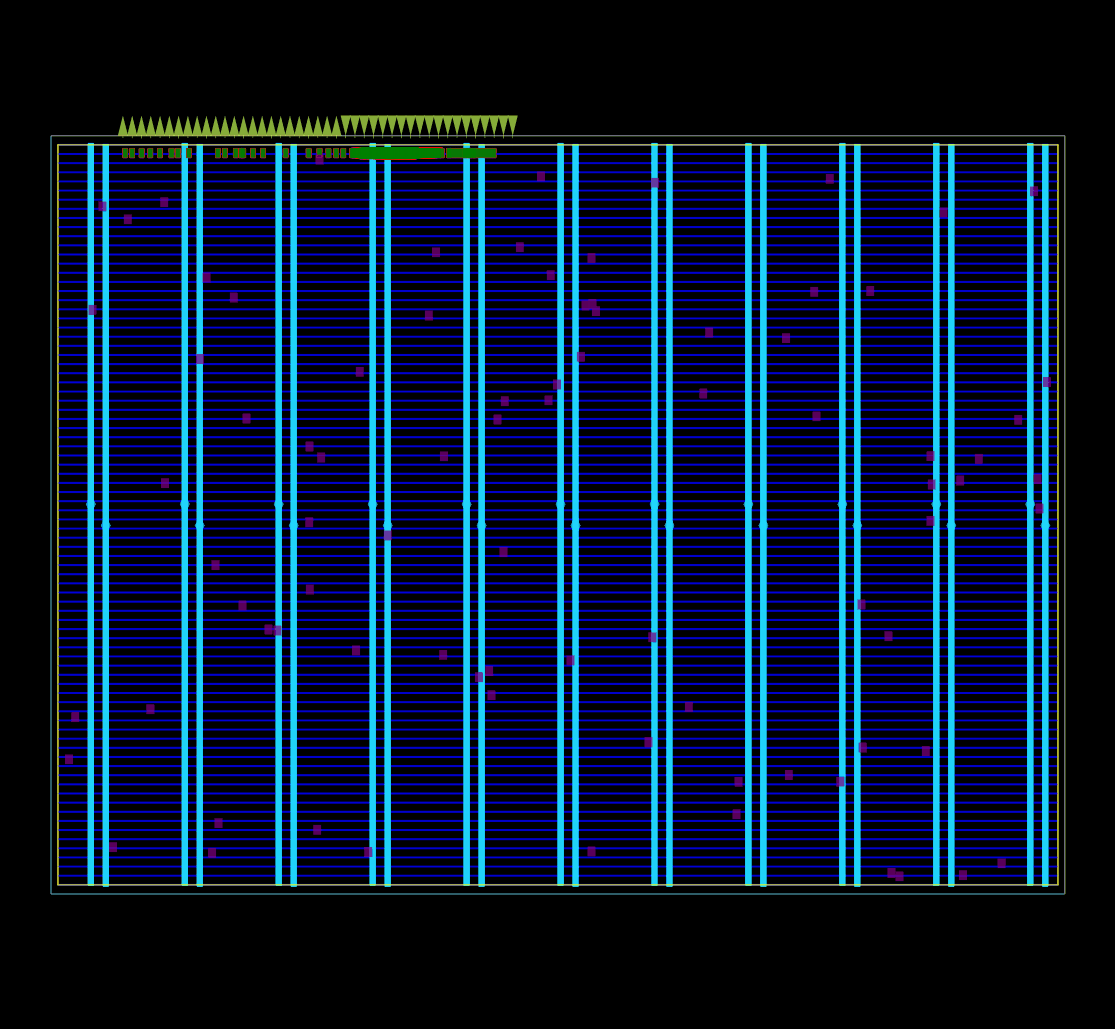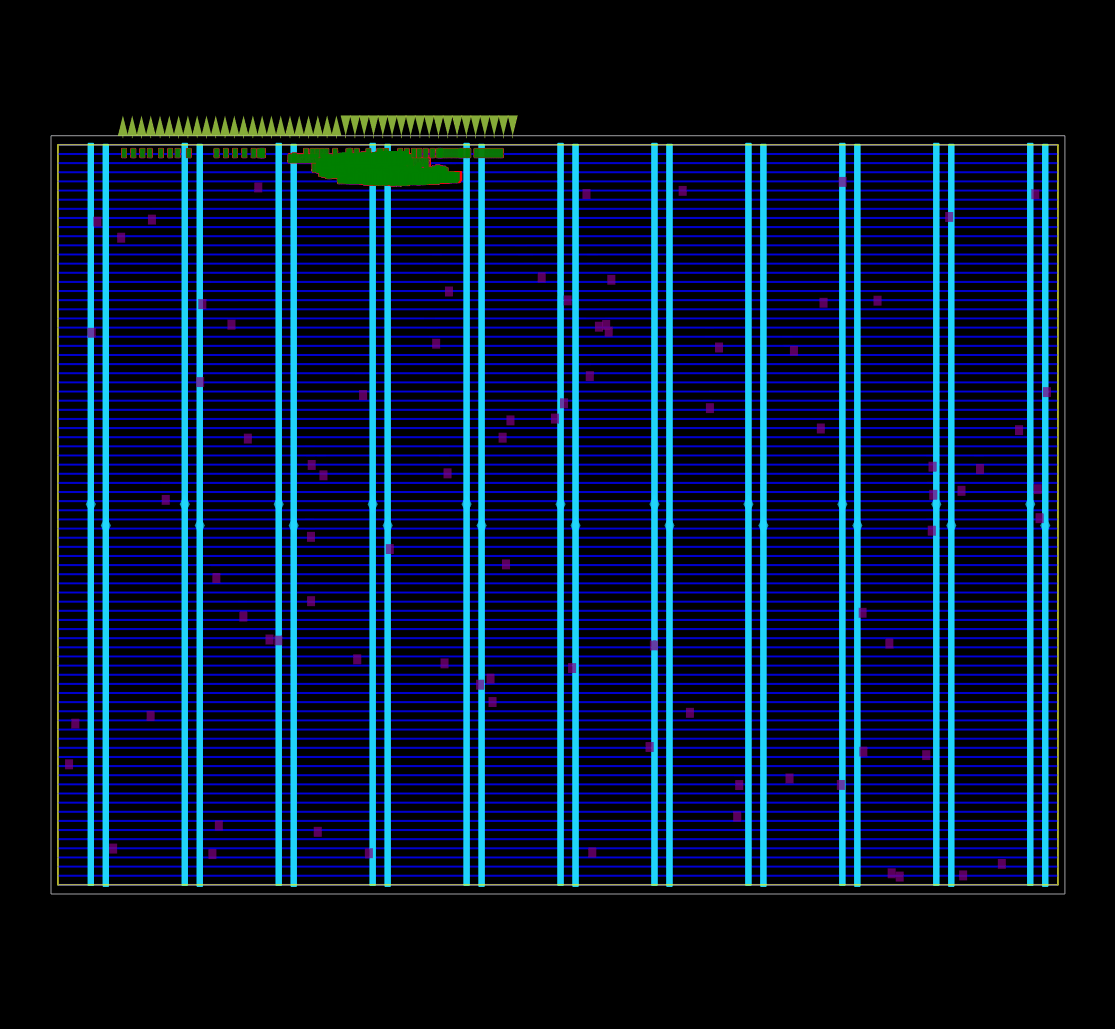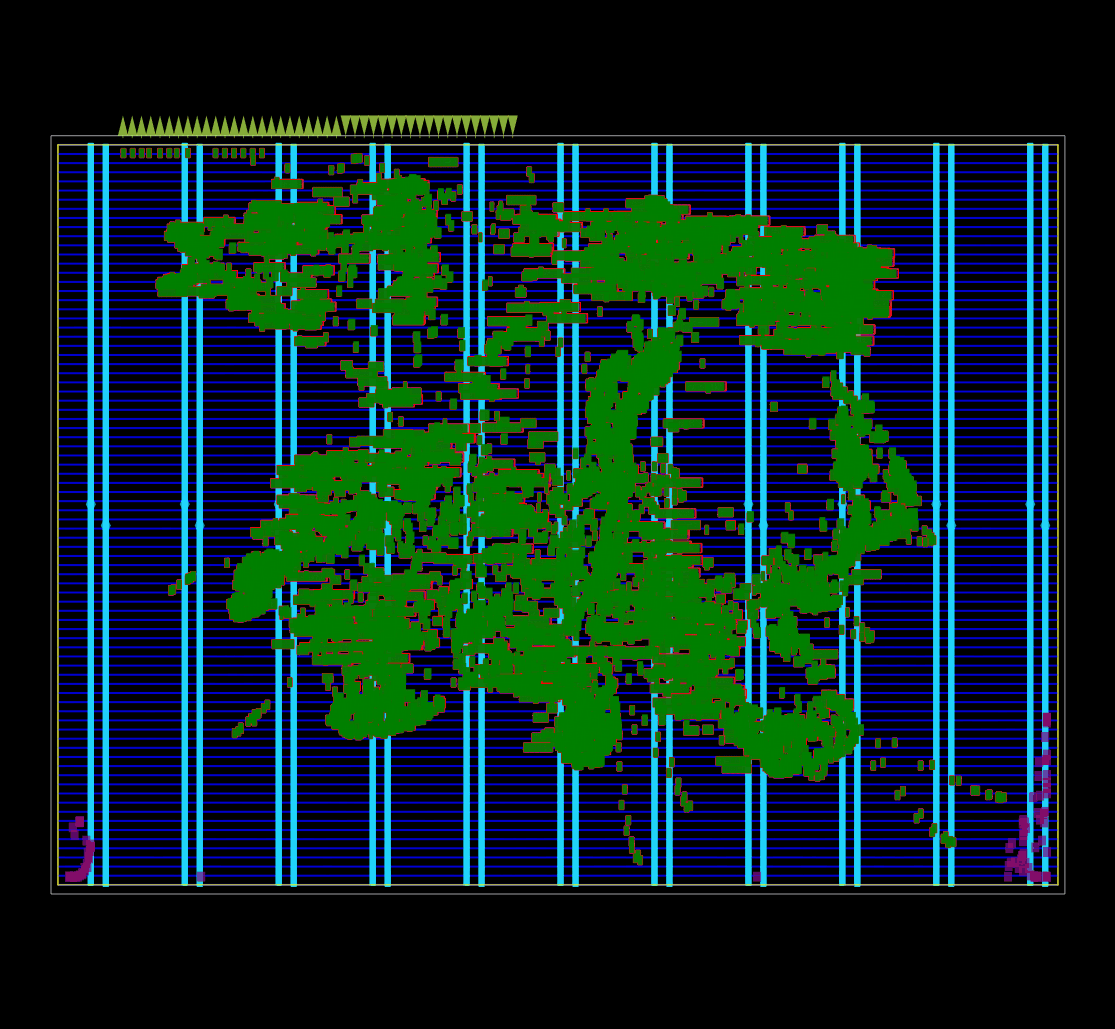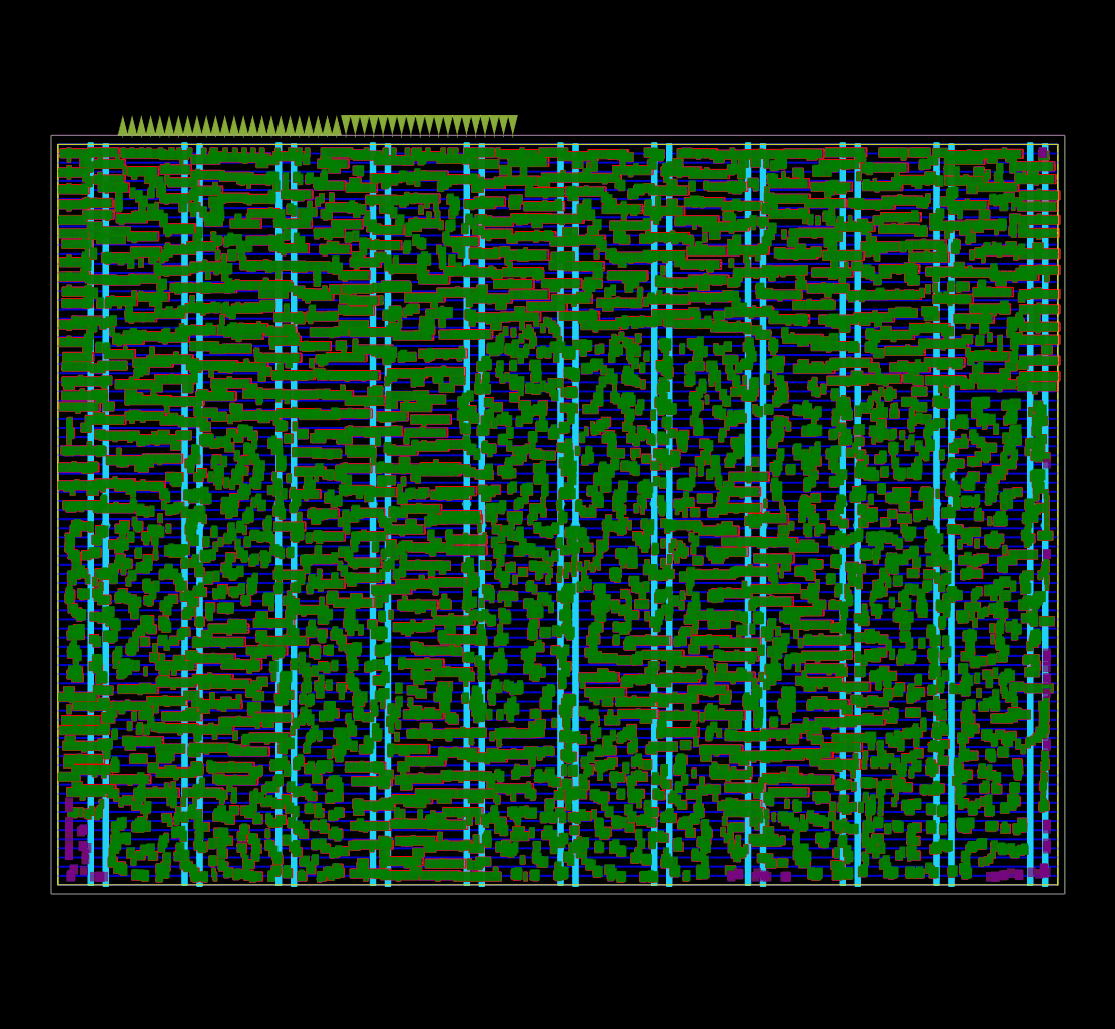
Được ghi lại bằng OpenROAD global placement ở chế độ gỡ lỗi.
Vì bài viết này tập trung vào các phép tính dấu phẩy động nên tôi sẽ kìm nén mong muốn kể cho các bạn nghe về phần còn lại của bộ tăng tốc và khóa nó lại trong repo của ASIC:
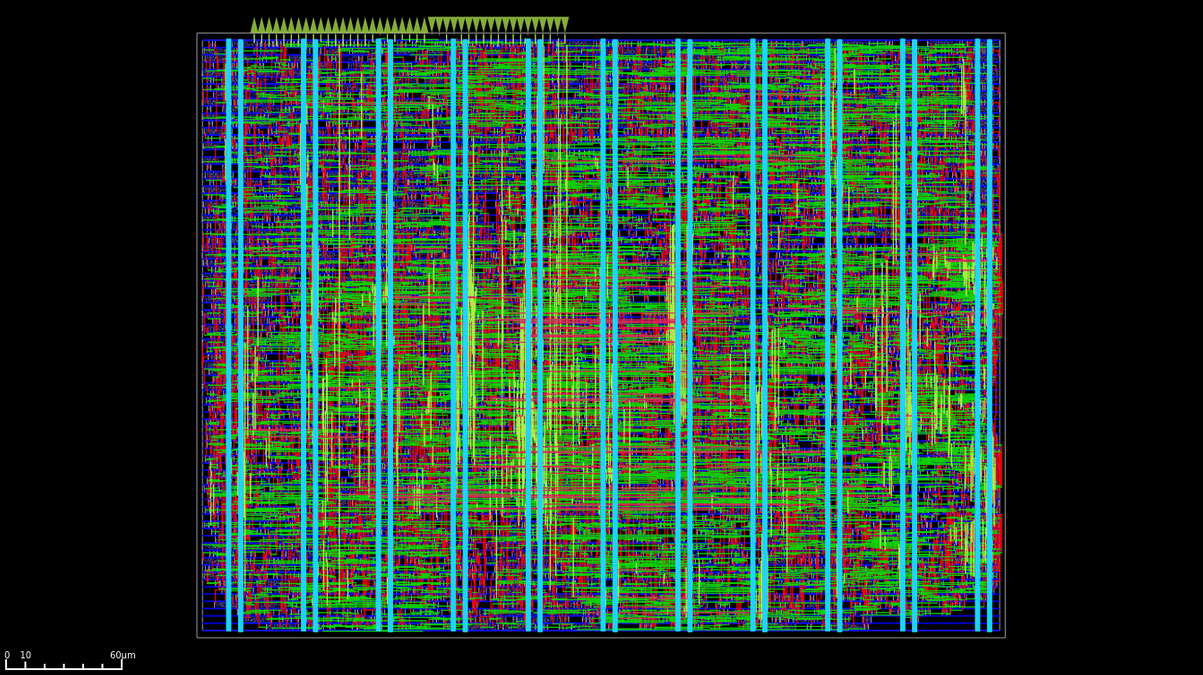
Thiết kế này có hai cây xung nhịp (clock tree), một cho MAC và một cho JTAG TAP. Xung nhịp MAC nhắm tới tần số hoạt động tối đa 100 MHz, nhưng các thử nghiệm tần số GPIO đầu ra hiện tại cho thấy tối đa là 75 MHz, và JTAG là 2 MHz.
Tiny Tapeout ihp26a#
Cảm ơn mọi người!
ihp26a.Nguồn: https://github.com/TinyTapeout/tinytapeout-chip-renders
Thư viện cell IHP 130nm mà chúng tôi đang sử dụng lần này rất đặc biệt: nó cực kỳ nhanh so với hai PDK mã nguồn mở khác, cho phép chúng tôi đạt được fmax thực sự ấn tượng. (Như đã minh họa bởi cuộc thi fmax của chúng tôi sử dụng node IHP sg13cmos5l chị em.)
Nhưng một lần nữa, chúng tôi gặp vấn đề về IO: tần số hoạt động ổn định tối đa của GPIO dự kiến vào khoảng 100MHz ở đầu vào và 75MHz ở đường đầu ra, nghĩa là systolic array này thực tế bị nghẽn ở 75MHz. Tuy nhiên, vì PDK sg13g2 rất nhanh và việc đạt được timing ở 75MHz là chưa đủ thách thức, tôi quyết định thử thách bản thân nhắm tới tần số bình thường là 100MHz. Ồ và tôi cũng sẽ thực hiện toàn bộ phép cộng và nhân bfloat16 trong một chu kỳ duy nhất.
Chắc chắn, tôi có thể pipeline các thao tác này, nhưng đó sẽ là lãng phí cơ hội để ép bản thân cải thiện hiệu suất của việc triển khai.
Yosys you pleb#
Để tôi kể cho bạn nghe một câu chuyện thú vị đã xảy ra trong quá trình triển khai.
Nhưng trước tiên hãy thiết lập bối cảnh: đường dẫn tới hạn (critical path) cắt chính xác nơi bạn mong đợi: đi qua phép nhân mantissa của phép nhân và tiếp tục qua đường dẫn đóng của bộ cộng ngay qua LZC (leading zero count - đếm số 0 dẫn đầu).
Tại thời điểm này trong câu chuyện, tôi đã sử dụng một vài thủ thuật tối ưu hóa timing RTL cổ điển và đang ngồi thoải mái ở mức +0.6ns slack trên corner chậm và +3.9ns trên corner danh nghĩa. Tôi tưởng công việc của mình đã xong thì một người bạn bắt đầu chất vấn tôi về lựa chọn thiết kế LZC.
Những con số này là từ timing trước khi làm lại toàn bộ logic điều khiển của systolic array và liên kết tất cả các flop như một phần của chuỗi quét DFT.
Tôi đã chọn triển khai một LZC dựa trên cây, cái giống như bạn thấy trong tài liệu, và mặc dù mã verilog rất khó đọc đến mức nó cần cả một testbench riêng, khái niệm cơ bản của nó quá thanh lịch để bỏ qua.
Vì timing của tôi đã khá ổn nên tôi quyết định giữ lại lựa chọn thêm một dự đoán số 0 dẫn đầu (leading zero anticipation) được tối ưu hóa hơn như một phương án dự phòng cho sau này.
Và thế là người bạn của tôi đến và đề nghị chúng ta làm điều gì đó khác biệt. Hãy quên LZC dựa trên cây đi, chỉ cần viết một bộ chọn ưu tiên (priority mux) và để bộ tổng hợp (synthesizer) tự giải quyết nó.
always @(*) begin
casez (in)
9'b1????????: shift_amt = 4'd0;
9'b01???????: shift_amt = 4'd1;
9'b001??????: shift_amt = 4'd2;
9'b0001?????: shift_amt = 4'd3;
9'b00001????: shift_amt = 4'd4;
9'b000001???: shift_amt = 4'd5;
9'b0000001??: shift_amt = 4'd6;
9'b00000001?: shift_amt = 4'd7;
9'b000000001: shift_amt = 4'd8;
default: shift_amt = 4'd0;
endcase
end
Thú thực, tôi ĐÃ KHÔNG nghĩ rằng điều này sẽ mang lại hiệu năng timing tốt hơn so với LZC dựa trên cây (tree-based). Tuy nhiên, giữa RTL và timing còn có yosys với 124 cấp độ tối ưu hóa, và yosys có khả năng nhận biết techmap.
Để tham khảo, đây là mã nguồn gốc của module, được tách riêng thành một module độc lập để tôi có thể theo dõi nó trong khi vẫn duy trì cấu trúc phân cấp (hierarchy) trong quá trình triển khai:
module pmux(
input wire [8:0] data_i,
output reg [3:0] zero_cnt
);
always @(*) begin
casez (data_i)
9'b1????????: zero_cnt = 4'd0;
9'b01???????: zero_cnt = 4'd1;
9'b001??????: zero_cnt = 4'd2;
9'b0001?????: zero_cnt = 4'd3;
9'b00001????: zero_cnt = 4'd4;
9'b000001???: zero_cnt = 4'd5;
9'b0000001??: zero_cnt = 4'd6;
9'b00000001?: zero_cnt = 4'd7;
9'b000000001: zero_cnt = 4'd8;
default: zero_cnt = 4'd0;
endcase
end
endmodule
Module này được triển khai thành kết quả 19 cell, chỉ sâu 3 tầng logic trên đường dẫn tới hạn (critical path), mang lại kết quả timing tốt hơn.
Trong phiên bản flattened cuối cùng, điều này giúp cải thiện +0.05 ns trên đường dẫn chậm (slow path). Một mặt, đây không phải là mức tăng lớn. Nhưng mặt khác, trải nghiệm này buộc tôi phải công nhận các công cụ này có thể đạt hiệu suất tốt đến mức nào.
Thiết kế LZC sử dụng casez này không chỉ nhanh hơn một chút, mà điểm mạnh lớn nhất của nó nằm ở sự đơn giản, dễ hiểu, từ đó giúp việc bảo trì dễ dàng hơn và trực tiếp giảm nguy cơ gây ra lỗi trong tương lai.
Đôi khi, một thiết kế tốt không chỉ dừng lại ở hiệu suất.
Combo!#
Nhưng khoan đã! Lại có thêm một đợt tapeout thứ hai ư?!
Khi tôi bắt đầu lên kế hoạch cho bài viết này, hy vọng của tôi là phần tính toán bfloat16 sẽ được tapeout như một phần trong mảng systolic thế hệ thứ hai của tôi trên quy trình IHP 130 nm.
Nhưng ngay khi đang viết bài này, cộng đồng Tiny Tapeout đã có cơ hội thực hiện đợt tapeout thứ hai trên IHP 130 nm, nhắm vào node sg13cmos5l mới hơn của IHP.
Cũng giống như cách chúng tôi có cơ hội thực hiện tapeout GF180 cho mảng systolic thế hệ đầu tiên, đây là một shuttle thử nghiệm tư nhân, đưa chúng tôi trở lại điểm khởi đầu.

ihp0p4.Nguồn: Luis Eduardo Ledoux Pardo
Hiện tôi có một quy tắc khá đặc biệt cho các đợt tapeout của mình: Tôi không bao giờ tapeout cùng một thiết kế hai lần.
Vì vậy, nếu muốn gửi bài tham gia shuttle chip ihp0p4, tôi không thể chỉ tái sử dụng IP hiện có. Không, tôi cần một thứ gì đó mới mẻ.
Chào mừng đến với thử thách fmax!
Bạn còn nhớ tôi đã nói các cell IHP chạy cực nhanh và tôi đang thực hiện phép cộng và nhân đầy đủ trong một chu kỳ chứ? Chà, một phần trong tôi rất nóng lòng muốn biết mình có thể đạt tới mức nào nếu bỏ qua giới hạn IO và hướng tới tần số tối đa!
May mắn thay cho tôi, một thành viên khác trong cộng đồng cũng đang thực hiện một thiết kế tương đương: và thế là chúng tôi cùng chạy đua!
Để tăng tần số, phép nhân bfloat16 đã được chia thành 2 chu kỳ. Đúng như dự đoán, đường dẫn tới hạn chính nằm ở phép nhân phần định trị (mantissa). Bây giờ, trong cách triển khai phép nhân ban đầu, tôi đã sử dụng chỉ thị triển khai của bộ tổng hợp để suy ra (infer) bộ nhân Booth radix-4 không dấu.
Như trải nghiệm LZC đã cho chúng ta thấy, yosys không phải là "hạng xoàng" khi nói đến việc tạo ra logic tối ưu. Thật không may, chúng ta phải đánh đổi điều này bằng việc mất quyền kiểm soát netlist, và trong trường hợp này là không thể chọn chính xác vị trí muốn tách phép nhân.
Do đó, để giúp pipeline đường dẫn này, tôi cần phải triển khai lại một bộ nhân Booth radix-4 không dấu 8-bit tùy chỉnh ngay từ đầu.
Bên trong giai đoạn nhân tùy chỉnh này, một flop được thêm vào sau giai đoạn mã hóa, ở giữa giai đoạn nén. Chúng ta lưu trữ quá trình nén một phần của hai tích riêng phần đầu tiên và 3 tích cuối cùng trước đó, rồi trong chu kỳ tiếp theo, chúng ta nén chúng lại với nhau để có được kết quả cuối cùng của phép nhân phần định trị này.
Một vài tối ưu hóa bổ sung như vậy đã được thực hiện xuyên suốt bộ nhân, cho phép thiết kế này đạt tần số hoạt động tối đa là 454.545 MHz.
Kết luận#
Sau hơn nửa thập kỷ, cuối cùng tôi cũng đã hạ gục được con rồng của mình và trả thù được phép toán dấu phẩy động!
Sau khi tự xây dựng phép toán dấu phẩy động từ con số không, tôi tin rằng những người duy nhất thực sự hiểu về dấu phẩy động là:
- Những người viết nên đặc tả IEEE 754
- Các tiến sĩ toán học nghiên cứu về biểu diễn dấu phẩy động
Sau khi triển khai lại các phép toán dấu phẩy động và thực hiện tapeout hai lần, tôi có thể tự tin khẳng định rằng mình không hiểu sâu sắc về phép toán dấu phẩy động, nhưng ít nhất bây giờ tôi biết chính xác "hang thỏ" này sâu đến mức nào và tôi phải làm gì nếu muốn thực sự làm chủ nó.
Nhưng với hai lần tapeout 130nm chứa IP dấu phẩy động của riêng mình, tôi có thể tự tin để lại việc khám phá các định dạng minifloat khác và triển khai các hoạt động phức tạp hơn cho một ngày nào đó.
Bởi vì bây giờ tôi còn có một việc quan trọng hơn nhiều phải làm!
Trước khi chúng ta có thể đi ngủ, trước khi chúng ta có thể viết xong tài liệu, có một truyền thống hậu tapeout không bao giờ được bỏ qua:

Tái bút#
Tôi thực sự khuyên bạn nên đọc cuốn sách xuất sắc “Handbook of Floating-Point Arithmetic, Second edition” nếu bạn đang tìm kiếm phiên bản 600 trang giải đáp cho các câu hỏi về dấu phẩy động.
Đặc biệt cảm ơn một nửa tuyệt vời của tôi, yg, Prawnzz và Erstfeld đã giúp xem xét bài viết này.
Tác giả: random__duck