
Tìm tất cả các kết quả khớp với biểu thức chính quy luôn là O(n²)
Finding all regex matches has always been O(n²)
Trong nhiều thập kỷ, hầu hết các công cụ xử lý regex, ngay cả những công cụ quảng cáo thời gian tuyến tính cho một lần khớp duy nhất, đều gặp phải độ phức tạp **O(n²)** khi tìm tất cả các lần xuất hiện. Nguyên nhân chính là do cách xử lý kém hiệu quả các phép **alternation** (toán tử `|`) và **greedy quantifiers** (như `*`, `+`, `?`, `{n,m}`). Hành vi **quadratic** này xảy ra vì các engine có thể quét lại các chuỗi con nhiều lần, dẫn đến suy giảm hiệu năng một cách trầm trọng hơn nhiều so với việc mở rộng tuyến tính. Các developer cần lưu ý rằng các thao tác `find_all` hoặc `find_iter` thông thường trên các thư viện phổ biến như `regex` của Rust hoàn toàn có thể thể hiện hành vi worst-case **quadratic** này, ngay cả khi engine đó vốn dĩ rất hiệu quả. Vấn đề này bắt nguồn từ các đơn giản hóa về mặt lý thuyết, thường chỉ tập trung vào việc "khớp hay không khớp" mà bỏ qua các khía cạnh thực tế như vị trí khớp và số lượng khớp. Do đó, việc kiểm thử hiệu năng của regex trên dữ liệu thực tế là cực kỳ quan trọng, và cần cân nhắc các phương pháp thay thế nếu hiệu năng khi tìm tất cả các khớp là yếu tố then chốt.
tìm kiếm một tài liệu cho một mẫu và phải mất một giây. tìm kiếm lớn hơn gấp trăm lần và không mất một trăm giây - có thể mất gần ba giờ. mọi công cụ biểu thức chính quy, trong mọi ngôn ngữ, đều có...
tìm kiếm một mẫu trong tài liệu và chỉ mất một giây. tìm kiếm lớn hơn gấp trăm lần và không mất một trăm giây - có thể mất gần ba giờ. mọi công cụ biểu thức chính quy, trong mọi ngôn ngữ, đều gặp phải vấn đề này từ những năm 1970 và không ai sửa được nó.
(đây là phần tiếp theo của RE#: cách chúng tôi xây dựng công cụ biểu thức chính quy nhanh nhất thế giới trong F# và đạo hàm biểu tượng và sự viết lại rỉ sét của RE#)
mọi công cụ biểu thức chính quy quảng cáo kết hợp thời gian tuyến tính - RE2, regexp, thùng regex của Rust, Chế độ NonBacktracking - nghĩa là thời gian tuyến tính cho một trận đấu. thời điểm bạn gọi find_iter hoặc FindAll, sự đảm bảo đó sẽ không còn nữa. thùng biểu thức chính quy rỉ sét tài liệu là những tài liệu duy nhất đủ trung thực để nói thẳng điều đó:
độ phức tạp về thời gian trong trường hợp xấu nhất đối với các trình vòng lặp là O(m * n²). […] Nếu cả hai mẫu và đống cỏ khô đều không đáng tin cậy và bạn đang lặp lại tất cả các kết quả khớp, bạn sẽ dễ gặp phải độ phức tạp thời gian bậc hai trong trường hợp xấu nhất. Không có cách nào để tránh điều này. Một cách có thể để giảm thiểu điều này là [...] dừng ngay lập tức ngay khi tìm thấy kết quả phù hợp. Do đó, việc bật chế độ này sẽ khôi phục giới hạn độ phức tạp về thời gian O(m * n) trong trường hợp xấu nhất, nhưng phải trả giá bằng ngữ nghĩa khác.
cơ chế rất đơn giản. lấy mẫu .*a|b và một đống cỏ khô của n b. tại mỗi vị trí, công cụ sẽ thử .*a trước: quét toàn bộ đống cỏ khô còn lại để tìm a, không tìm thấy, thất bại. thì nhánh b khớp với một ký tự đơn. tiến lên một vị trí, lặp lại. đó là n + (n-1) + (n-2) + ... = O(n²) có tác dụng báo cáo n kết quả trùng khớp một ký tự. một tổng tam giác trong sách giáo khoa. nhấn play để xem nhé:
so khớp .*a|b với "bbbbbbbbbb" - tìm tất cả kết quả khớp
Russ Cox đã mô tả vấn đề chính xác này vào năm 2009, lưu ý rằng ngay cả awk ban đầu của chính Aho cũng sử dụng phép toán bậc hai ngây thơ "vòng quanh DFA" để so khớp dài nhất ngoài cùng bên trái. Bộ điểm chuẩn rebar của BurntSushi xác nhận điều đó theo kinh nghiệm trên RE2, Go và rỉ sét. thông lượng giảm một nửa khi đầu vào tăng gấp đôi. như anh ấy nói: "ngay cả đối với các động cơ định hướng automata, nó sẽ gây ra một trường hợp không thể tránh khỏi là O(m * n²)".
Sao chuyện này lại không được chú ý lâu đến vậy? hầu như tất cả các bài viết về biểu thức chính quy học thuật đều tập trung hoàn toàn vào vấn đề đối sánh đơn và sau đó loại bỏ phần còn lại bằng cách "chỉ lặp lại". một phần lý do là lý thuyết về biểu thức chính quy tóm gọn mọi thứ thành một câu hỏi có/không: chuỗi này có khớp hay không? điều đó rõ ràng và tuyệt vời để chứng minh các định lý, nhưng nó vứt bỏ gần như mọi thứ quan trọng trong thực tế: các trận đấu diễn ra ở đâu, kéo dài bao lâu và có bao nhiêu trận đấu. khi bạn giảm biểu thức chính quy thành "khớp hoặc không khớp", vấn đề về tất cả các biểu thức khớp chỉ đơn giản là biến mất khỏi chế độ xem, được xếp vào một khung không liên quan gì đến mục đích thực sự mà mọi người sử dụng biểu thức chính quy.
việc quay lại tệ hơn và vẫn là mặc định
trước khi bắt đầu khắc phục, bạn nên đặt bài toán bậc hai vào ngữ cảnh. với tính năng quay lui, mẫu do người dùng cung cấp và dữ liệu nhập 50 ký tự có thể mất lâu hơn cái chết nhiệt của vũ trụ. nó theo cấp số nhân. Thompson đã xuất bản cấu trúc NFA để tránh nó quay trở lại vào 1968. đó là gần 60 năm một vấn đề đã được giải quyết vẫn chưa được giải quyết tích cực trên quy mô lớn, bởi vì việc quay lui vẫn là mặc định trong hầu hết các công cụ biểu thức chính quy. Cảnh báo bảo mật GitHub của tôi vào tháng 3 năm 2026 kể câu chuyện:
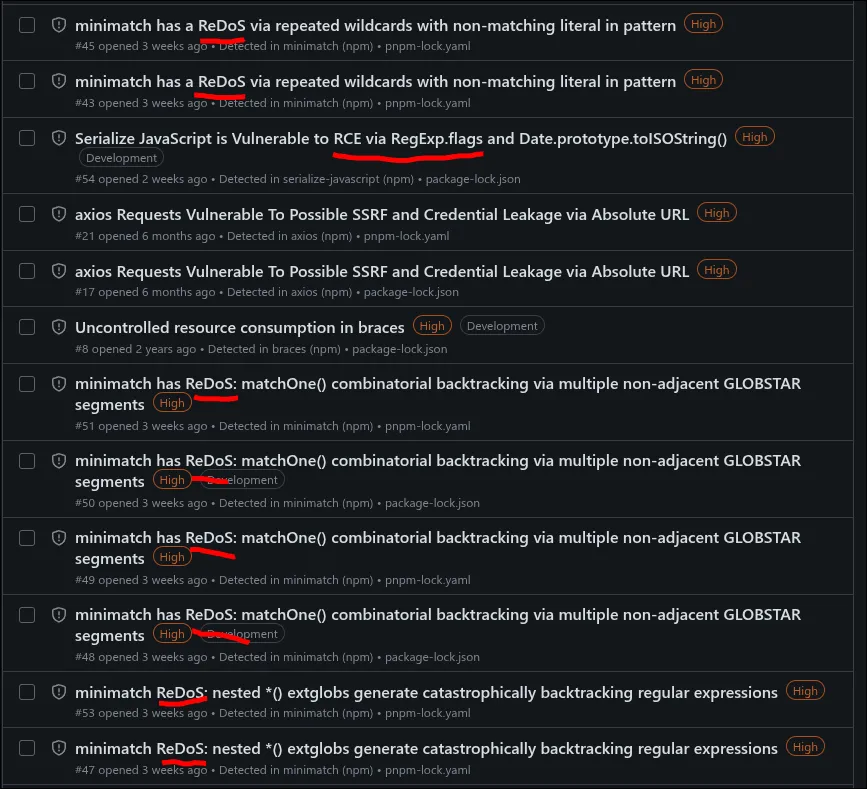
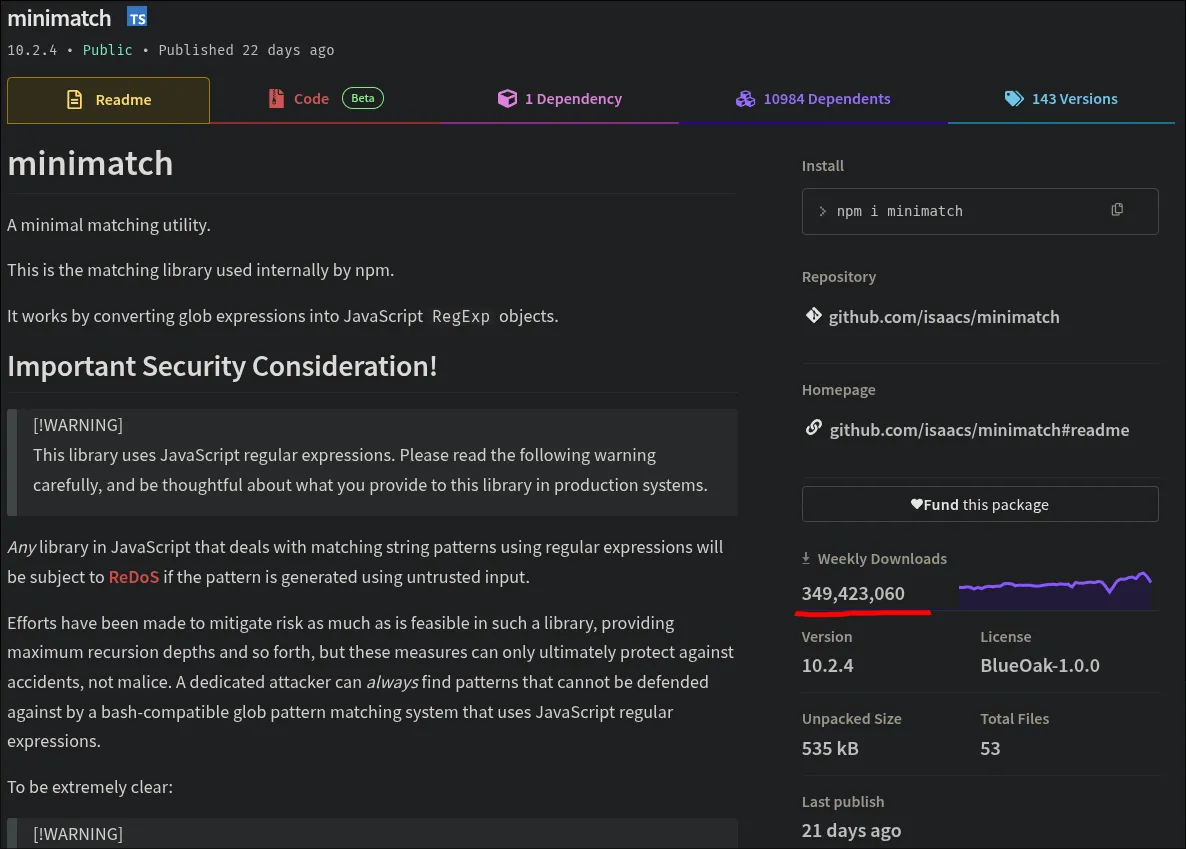
minimatch là thư viện so khớp toàn cầu của riêng npm, được viết bởi người tạo ra npm. nó chuyển đổi các khối thành biểu thức chính quy JavaScript và đã bị tấn công bởi năm CVE ReDoS riêng biệt, tất cả đều do cùng một vấn đề gốc: quay lui. nó nhận được 350 triệu lượt tải xuống mỗi tuần. readme của thư viện hiện cảnh báo in đậm rằng "nếu bạn tạo một hệ thống nơi bạn lấy dữ liệu đầu vào của người dùng và sử dụng dữ liệu đầu vào đó làm nguồn của mẫu Biểu thức chính quy […] thì bạn sẽ bị xử lý" và tuyên bố rằng các báo cáo ReDoS trong tương lai sẽ được coi là "hoạt động như dự định".
bài toán so khớp toàn phương phức tạp hơn. nó ảnh hưởng đến cả những động cơ được chế tạo đặc biệt để tránh bị quay ngược. nó sẽ không tắt trình duyệt của bạn nhưng vẫn sẽ âm thầm biến một lượt tìm kiếm kéo dài một giây thành một lượt tìm kiếm kéo dài ba giờ.
Aho-Corasick đã giải quyết vấn đề này cho các chuỗi cố định vào năm 1975
vấn đề chúng ta đang nói đến trong bài đăng này (tìm tất cả các kết quả trùng khớp không chồng chéo dài nhất bên trái mà không có hiện tượng bậc hai) thực ra đã được giải quyết từ nhiều thập kỷ trước, nhưng chỉ đối với các chuỗi cố định. Aho-Corasick (1975) là một thuật toán cổ điển và rất hữu ích giúp tìm tất cả các lần xuất hiện của nhiều chuỗi cố định trong một lượt O(n) duy nhất và tuyến tính ngay từ đầu. bạn xây dựng một bản thử nghiệm từ tập hợp các mẫu của mình, thêm các liên kết lỗi giữa các nút và quét đầu vào một lần. ở mỗi ký tự, mọi ứng cử viên tích cực đều tiến bộ qua lần thử hoặc quay lại theo liên kết thất bại. không có sự bùng nổ bậc hai, bất kể có bao nhiêu mẫu hoặc kết quả phù hợp.
đây là máy tự động Aho-Corasick cho các mẫu {"anh ấy", "cô ấy"} hoặc ít nhất là nỗ lực tốt nhất của LLM để tạo ra một mẫu. mũi tên liền là chuyển tiếp trie, mũi tên nét đứt là liên kết lỗi:

quét "ushers": u ở gốc, s nhập S, h nhập SH, e nhập SHE, khớp "she". thì liên kết lỗi nhảy tới HE, khớp với "he". tìm thấy hai kết quả trùng nhau trong một lượt.
Lý do Aho-Corasick tránh được sự bùng nổ bậc hai rất đơn giản: mọi mẫu đều có độ dài đã biết, được đưa vào trie. khi bạn tìm thấy một kết quả phù hợp, bạn đã biết chính xác nó dài bao nhiêu. không có sự mơ hồ về nơi nó kết thúc, không có gì để quét lại. nhưng nó chỉ hoạt động với danh sách các chuỗi ký tự chứ không phải biểu thức chính quy.
Siêu quét/Quét vectơ
Hyperscan (và nhánh của nó Vectorscan) là một công cụ biểu thức chính quy phù hợp với mọi thời gian tuyến tính thực sự. nó đạt được điều này bằng cách sử dụng ngữ nghĩa "kết quả phù hợp sớm nhất": báo cáo kết quả phù hợp vào thời điểm DFA chuyển sang trạng thái phù hợp, thay vì tiếp tục tìm trạng thái dài nhất. điều này thay đổi kết quả. ví dụ: với mẫu a+ và đầu vào aaaa:
ngoài cùng bên trái-(tham lam|dài nhất): aaaa - một trận
sớm nhất: a a a a - bốn trận đấu, mỗi trận đấu càng ngắn càng tốt
đối với trường hợp sử dụng của Hyperscan - phát hiện xâm nhập mạng, trong đó bạn chỉ cần biết rằng mẫu phù hợp - đây là sự cân bằng phù hợp. nhưng đối với grep, trình soạn thảo và tìm kiếm và thay thế, nơi người dùng mong đợi a+ khớp với toàn bộ hoạt động của a, ngữ nghĩa sớm nhất sẽ đưa ra câu trả lời sai.
REmatch (VLDB 2023) sử dụng một cách tiếp cận khác: nó liệt kê mọi khoảng thời gian hợp lệ (bắt đầu, kết thúc) cho một mẫu, bao gồm tất cả các khoảng chồng chéo và lồng nhau. đối với a+ trên aaaa đó là 10 nhịp: (0,1), (0,2), ..., (2,4), (3,4). bản thân kết quả đầu ra có thể là O(n²), do đó, nó đang giải quyết một vấn đề khác.
hai lượt thay vì n
lý do tôi viết về vấn đề này là vì tôi đang nghiên cứu RE# và tôi muốn chứng minh rằng vấn đề này thực sự có thể giải quyết được. theo hiểu biết tốt nhất của tôi, RE# là công cụ biểu thức chính quy đầu tiên có thể tìm tất cả các kết quả phù hợp trong hai lần chuyển, bất kể mẫu hay dữ liệu đầu vào, mà không làm thay đổi ngữ nghĩa.
thuật toán không tìm thấy kết quả phù hợp tại một thời điểm. thay vào đó, nó thực hiện hai lần chuyển qua toàn bộ đầu vào: một dấu DFA đảo ngược nơi các kết quả khớp có thể bắt đầu, sau đó một DFA chuyển tiếp sẽ giải quyết kết quả khớp dài nhất tại mỗi vị trí được đánh dấu. vào thời điểm chúng tôi xác nhận sự trùng khớp, cả hai hướng đều đã được quét. các trận đấu được báo cáo từ hồi tố thay vì bắt đầu lại từ mỗi vị trí. Phần thuật toán llmatch trong bài đăng đầu tiên sẽ hướng dẫn chi tiết về vấn đề này.
một trận hay vạn, hai đường chuyền cũng giống nhau. ví dụ tương tự như trước:
so khớp .*a|b với "bbbbbbbbbb" - tìm tất cả kết quả phù hợp
truyền thống (tìm, nâng cao, lặp lại):
phân chia lại (hai lượt):
trên các mẫu tạo ra nhiều kết quả trùng khớp - phân tích cú pháp nhật ký, trích xuất dữ liệu, tìm kiếm và thay thế trên các tệp lớn - sự khác biệt giữa O(n) và O(n²) là sự khác biệt giữa "tức thì" và "tại sao việc này lại mất nhiều thời gian như vậy".
các kết quả khớp vẫn dài nhất ngoài cùng bên trái (POSIX) - a|ab và ab|a cho kết quả giống nhau, đại số boolean hoạt động và bạn có thể cấu trúc lại các mẫu mà không thay đổi kết quả.
chế độ cứng
hai lượt sẽ loại bỏ n lần khởi động lại, nhưng bản thân lượt chuyển tiếp vẫn giải quyết từng trận đấu một. các mẫu bệnh lý có ranh giới khớp không rõ ràng có thể gây ra công thức bậc hai trong đường chuyền đó. tôi muốn một chế độ đảm bảo thời gian tuyến tính ngay cả trên đầu vào đối nghịch, không có ngoại lệ. vì vậy tôi đã thêm chế độ cứng rắn vào động cơ.
chế độ cứng hóa thay thế chuyển tiếp bằng quét O(n * S) (trong đó S là số trạng thái DFA hoạt động đồng thời) để giải quyết tất cả các kết thúc đối sánh trong một lần chuyển, trả về chính xác các kết quả trùng khớp dài nhất ngoài cùng bên trái mà không có sự cân bằng về ngữ nghĩa. trên đầu vào bệnh lý (.*a|b so với đống cỏ khô của b), sự khác biệt rất lớn:
| kích thước đầu vào | bình thường | được tăng cường | tăng tốc với cứng lại |
|---|---|---|---|
| 1.000 | 0,7ms | 28us | 25x |
| 5.000 | 18ms | 146us | 123x |
| 10.000 | 73 mili giây | 303us | 241x |
| 50.000 | 1,8 giây | 1,6 mili giây | 1.125x |
chế độ chuẩn tắc trở thành phương trình bậc hai; làm cứng vẫn giữ nguyên tuyến tính. vậy tại sao không đặt làm cứng thành mặc định? tôi đã đi đi lại lại về điều này.
sự cố bậc hai yêu cầu một mẫu bệnh lý và đầu vào có cấu trúc đủ dài để gây ra sự cố. bạn cần cả hai nửa. lấy mẫu như [A-Z][a-z]+: mọi kết quả khớp đều bắt đầu bằng một chữ cái viết hoa và kết thúc ngay khi động cơ nhìn thấy thứ gì đó không phải là chữ thường. không có sự mơ hồ về nơi kết thúc trận đấu, vì vậy công cụ không bao giờ quét lại cùng một đầu vào. đối với mẫu này, trường hợp bậc hai thực sự là không thể. hầu hết các mẫu trong thế giới thực đều có chung thuộc tính này.
vì vậy, việc áp dụng mức giảm tốc độ hệ số không đổi 3-20 lần cho mỗi truy vấn để bảo vệ khỏi trường hợp bạn khó có thể gặp phải do vô tình là sai lầm.
nhưng nếu mẫu do người dùng cung cấp thì không có mẫu nào đúng. kẻ tấn công kiểm soát một nửa phương trình và thời gian biên dịch. “Chắc chắn bạn sẽ không đánh trúng” chính là kiểu lý luận dẫn đến sự cố trong sản xuất. cuối cùng, tôi giữ đường dẫn nhanh làm mặc định, chủ yếu là do sự chậm lại là có thật và có thể đo lường được trên mỗi truy vấn, trong khi trường hợp bệnh lý yêu cầu một sự kết hợp thực sự thù địch.
cũng có một thực tế thực tế: tôi đang cố gắng chứng tỏ rằng RE# là công cụ biểu thức chính quy nhanh nhất cho khối lượng công việc thông thường. nếu đường dẫn mặc định chậm hơn 20% so với các điểm chuẩn thông thường thì đó là những gì mọi người nhìn thấy chứ không phải cách khắc phục bậc hai. tôi sẽ không có nó.
chế độ tăng cường áp dụng khi bạn chấp nhận các mẫu từ Internet và không thể tin tưởng vào những gì bạn nhận được - một sự đồng ý tham gia rõ ràng thay vì đánh thuế thầm lặng đối với mọi người.
hãy lại = Regex::with_options(
mẫu ,
Tùy chọn động cơ:: mặc định().cứng rắn(true)
)?;chi phí trên văn bản thông thường:
| mẫu | bình thường | tỷ lệ cứng | |
|---|---|---|---|
[A-Z][a-z]+ | 2,2 mili giây | 6,5 mili giây | 3,0x chậm hơn |
[A-Za-z]{8,13 | 1,7 mili giây | 7,6 mili giây | Chậm hơn 4,4 lần |
\w{3,8 | 2,6 mili giây | 22 mili giây | 8,7 lần chậm hơn |
\d+ | 1,3 mili giây | 5,2 mili giây | Chậm hơn 3,9 lần |
[A-Z]{2, | 0,7 mili giây | 4,7 mili giây | 6,7 lần chậm hơn |
các mẫu có giao diện hiện bị từ chối ở chế độ cứng. không có rào cản về mặt lý thuyết, nhưng việc triển khai cần một số công việc.
vs Aho-Corasick
Chế độ cứng của RE# mở rộng cách tiếp cận của Aho-Corasick tới các biểu thức chính quy đầy đủ, trong đó độ dài khớp không được biết trước. thay vì một bộ ba, nó chứa một tập hợp các ứng cử viên phù hợp đang hoạt động, nâng cấp tất cả chúng trên mỗi ký tự đầu vào bằng cách sử dụng đạo hàm. các ứng cử viên mới chỉ được thêm vào các vị trí đã được xác nhận là bắt đầu trận đấu hợp lệ bằng vượt qua ngược, do đó, công cụ không bao giờ lãng phí công việc đối với các vị trí không thể bắt đầu trận đấu. kết quả là thuộc tính giống như Aho-Corasick luôn có, tất cả các kết quả khớp theo thời gian tuyến tính, nhưng dành cho các biểu thức chính quy.
vậy chế độ bình thường của RE# so với Aho-Corasick trên sân nhà của nó như thế nào? đây là điểm chuẩn với từ điển gồm 2663 từ dưới dạng word1|word2|...|wordN xen kẽ, phù hợp với ~900KB văn xuôi tiếng Anh - chính xác là loại khối lượng công việc mà Aho-Corasick được thiết kế cho. RE# chỉ biên dịch nó như một biểu thức chính quy thông thường:
| điểm chuẩn | resharp | resharp (hardened) | rust/regex | aho-corasick |
|---|---|---|---|---|
| từ điển 2663 từ (~15 kết quả phù hợp) | 627 MiB/s | 163 MiB/s (3,85x) | 535 MiB/s (1,17x) | 155 MiB/s (4,05x) |
làm sao điều này có thể xảy ra khi RE# đang thực hiện thêm công việc - hai lượt thay vì một? nó phụ thuộc vào hành vi của bộ đệm. Aho-Corasick xây dựng trả trước máy tự động đầy đủ - cho 2663 từ, đây là một DFA lớn với nhiều trạng thái và các bước nhảy không thể đoán trước giữa chúng, dẫn đến lỗi bộ nhớ đệm và dự đoán sai nhánh. Rust regex sử dụng một DFA được biên dịch một cách lười biếng, điều này có ích nhưng không gian trạng thái cho một sự thay thế lớn vẫn còn đáng kể. Các DFA dựa trên phái sinh của RE# được xây dựng một cách lười biếng và nhỏ gọn hơn - hai automata (tiến và lùi) mỗi loại có ít trạng thái hơn nhiều so với DFA đầy đủ tương đương hoặc DFA dựa trên NFA, do đó quá trình chuyển đổi chạm vào các dòng bộ đệm ấm thường xuyên hơn.
RE# hard đang thực hiện những công việc không cần thiết ở đây - như với [A-Z][a-z]+ ở trên , mẫu này có ranh giới khớp rõ ràng, vì vậy việc tăng cường độ cứng không bổ sung thêm gì. sự mất mát này là không thể tránh khỏi. chúng tôi có thể suy ra tại thời điểm biên dịch rằng việc tăng cường độ cứng là không cần thiết đối với các mẫu như thế này, nhưng hiện tại có những mức độ ưu tiên cao hơn.
nói rõ hơn, đối với một bộ chuỗi nhỏ hơn và một máy tự động được xây dựng hoàn chỉnh vừa vặn thoải mái trong bộ nhớ đệm L1, Aho-Corasick sẽ là lựa chọn phù hợp - nó chỉ cần một lượt trong khi RE# quét hai lần. kết quả ở trên dành riêng cho các mẫu lớn trong đó áp lực bộ nhớ đệm đóng vai trò quan trọng.
bỏ qua khả năng tăng tốc
nói về mức độ ưu tiên cao hơn - trong bài trước tôi đã mô tả cách hoạt động của tính năng tăng tốc bỏ qua và RE# đang thua regex trên các mẫu chữ nặng. kể từ đó, tôi đã thu hẹp những khoảng trống đó bằng cách triển khai AVX2 và NEON viết tay - tìm kiếm byte hiếm, khớp nhiều vị trí gấu bông và quét lớp ký tự dựa trên phạm vi.
đây từng là những tổn thất đáng kể. đóng chúng lại là một trong những điều thú vị hơn khi bắt đầu làm việc. tôi cũng háo hức muốn xem RE# hoạt động như thế nào trên rebar, bộ điểm chuẩn của BurntSushi dành cho công cụ biểu thức chính quy:
| điểm chuẩn | resharp | rust/regex |
|---|---|---|
| nghĩa đen, tiếng Anh | 34,8 GB/giây | 33,7 GB/giây |
| nghĩa đen, tiếng Anh không phân biệt chữ hoa chữ thường | 17.1 GB/giây | 9,7 GB/giây |
| nghĩa đen, tiếng Nga | 40,2 GB/s | 33,5 GB/s |
| bằng chữ, tiếng Nga không phân biệt chữ hoa chữ thường | 10,3 GB/s | 7,7 GB/s |
| nghĩa đen, tiếng Trung | 22,4 GB/s | 44,0 GB/s |
| chuyển đổi theo nghĩa đen, tiếng Anh | 12,2 GB/s | 12,5 GB/s |
| chuyển đổi theo nghĩa đen, tiếng Anh không phân biệt chữ hoa chữ thường | 4,9 GB/s | 2,5 GB/s |
| theo nghĩa đen, tiếng Nga | 3,3 GB/s | 5,9 GB/s |
RE# hiện hoạt động rất tốt ở đây - hầu hết các số đều nằm trong ngưỡng nhiễu của regex. một số điểm khác biệt ở đây và ở đó thuộc về bảng tần số byte và các lựa chọn thuật toán trong vòng lặp bỏ qua. đối với ngữ cảnh, bản thân DFA sẽ đưa bạn đến mức gần 1 GB/s. Bản chất vectơ CPU có thể nhân cơ hội đẩy con số đó lên hơn 40 trên các mẫu mà hầu hết đầu vào có thể bị bỏ qua.
phát trực tuyến
vì RE# khớp ngược lại nên bạn có thể thắc mắc liệu nó có thể hoạt động trên luồng hay không:
- bất kỳ mẫu nào + ngữ nghĩa dài nhất bên trái = không. đây không phải là giới hạn công cụ - nó vốn có đối với ngữ nghĩa. nếu bạn yêu cầu trận đấu dài nhất trên luồng vô hạn, câu trả lời có thể là "tiếp tục mãi mãi". bạn có thể nghĩ rằng người tham lam ngoài cùng bên trái sẽ tránh điều này vì nó hoạt động từ trái sang phải, nhưng thực tế không phải vậy -
.*a|btrên luồng củabcó cùng một vấn đề, nhánh.*atiếp tục quét về phía trước để tìm kiếm cáiacuối cùng có thể không bao giờ đến. - mẫu có ranh giới cuối rõ ràng = có. một số mẫu đã có ranh giới rõ ràng và hoạt động tốt như hiện tại. đối với những cái không có, trong RE# bạn có thể giao nhau với một ranh giới -
^.*$cho các dòng,~(_*\n\n_*)cho các đoạn văn (trong đó~(...)là phần bù và_*khớp với bất kỳ chuỗi nào) hoặc bất kỳ dấu phân cách nào bạn muốn - và giờ đây mẫu này tương thích với tính năng phát trực tuyến. trong bài đăng trước tôi đã chỉ ra cách bạn có thể giao cắt một biểu thức chính quy với "utf-8 hợp lệ", ở đây, bạn có thể giao cắt với "lên đến dòng mới tiếp theo" hoặc "đến cuối phần", ngay cả khi mẫu ban đầu là do người dùng cung cấp và không có thuộc tính này. đó là một kỹ thuật hay và tổng quát. - bất kỳ mẫu nào + ngữ nghĩa sớm nhất = có. báo cáo kết quả khớp vào thời điểm DFA chuyển sang trạng thái khớp, không cần phải quét thêm. đây là những gì Hyperscan làm - nó hoạt động trên các luồng vì nó không bao giờ cần phải nhìn về phía trước.
API chưa hiển thị giao diện phát trực tuyến - find_all mất &[u8] - nhưng tính năng phát trực tuyến theo khối vẫn có trong danh sách.
điều RE# không làm được
đáng phải nói thẳng về những hạn chế:
-
không có nhóm bắt giữ - RE# chỉ trả về các ranh giới trùng khớp, không trả về các ảnh chụp nhóm phụ. điều này không phải là không thể - chụp là một thao tác sau trận đấu có thể được xếp lớp lên trên. lý do là chúng ta chưa tìm được cách làm phù hợp. với phần giao và phần bù, mọi biểu thức con sẽ trở thành một nhóm thu thập một cách ngây thơ -
(a.*&.*b)có hai nhóm ẩn và phần bù sẽ tạo ra nhiều nhóm hơn. trong biểu thức chính quy truyền thống,(?:...)tồn tại để từ chối thu thập, nhưng tôi càng nghĩ về điều đó thì?:càng cảm thấy giống như một sai lầm lịch sử - nó khiến hành vi mặc định (bắt) trở thành hành vi đưa bạn vào một thuật toán chậm hơn nhiều, ngay cả khi bạn không cần đến nó. tôi thà có được thiết kế phù hợp còn hơn là gửi thứ gì đó rắc rối.trong thời gian chờ đợi, bạn có thể sử dụng một công cụ khác để trích xuất các ảnh chụp sau trận đấu - với
\Aneo trên các ranh giới trận đấu đã biết, chi phí không quá tệ. -
không có bộ định lượng lười biếng -
.*?không được hỗ trợ. RE# sử dụng ngữ nghĩa dài nhất bên trái (POSIX), đây là cách diễn giải rõ ràng về mặt toán học. bộ định lượng lười biếng là một khái niệm quay lui không phù hợp với mô hình này.
Cuối cùng thì các nhóm thu thập có thể xuất hiện, nhưng các bộ định lượng lười biếng là một lựa chọn mang tính kiến trúc có chủ ý. nếu bạn cần ảnh chụp ngay hôm nay, hãy sử dụng regex. nếu bạn cần các thuộc tính mà RE# cung cấp (toán tử boolean, bảng xem xét, tất cả các kết quả khớp tuyến tính thực, ngữ nghĩa POSIX), thì những hạn chế này dường như không thành vấn đề.
re
lưu ý thêm - để sử dụng các toán tử boolean của RE# trong thực tế, tôi đã xây dựng một công cụ grep có tên là re. Điều chính mà nó bổ sung trên (rip)?grep là tìm kiếm boolean nhiều thuật ngữ có phạm vi - yêu cầu nhiều mẫu cùng xuất hiện trên cùng một dòng, đoạn hoặc trong N dòng của nhau:
# mã không an toàn với lệnh unwrap nằm cùng vị trí trong 5 dòng
re --near 5 -a không an toàn -a mở gói src/
# liệt kê tất cả các tệp chứa cả serde và async
re --scope tệp -a serde -a async src/ bạn cũng có thể sử dụng các mẫu RE# đầy đủ - re '([0-9a-f]+)&(_*[0-9]_*)&(_*[a-f]_*)' src/ tìm thấy các chuỗi hex chứa cả chữ số và chữ cái. bạn có thể thực hiện việc này bằng một hệ thống grep, nhưng đó là một lần chuyển với tất cả thông tin ngữ cảnh được giữ nguyên.
vẫn còn sớm nhưng tôi đã sử dụng nó hàng ngày và tôi nghĩ ở đây có rất nhiều tiềm năng.
kết thúc
tôi nghĩ tôi sẽ nghỉ ngơi một chút sau chuyện này. Tôi chỉ có thể làm việc 80 giờ mỗi tuần trong thời gian dài như vậy và mặc dù tôi còn rất nhiều điều muốn chia sẻ nhưng điều đó sẽ phải đợi. cũng có một bài báo đã được chấp nhận có điều kiện tại PLDI - tôi sẽ viết về nó một cách đàng hoàng khi nó được xuất bản. Bản thân RE# rỉ sét vẫn chưa hoàn toàn sẵn sàng cho thông báo chính thức về phiên bản 1.0 nhưng chúng ta đang tiến gần hơn.
Tác giả: lalitmaganti