EP210: Monolithic, Microservices và Serverless
EP210: Monolithic vs Microservices vs Serverless
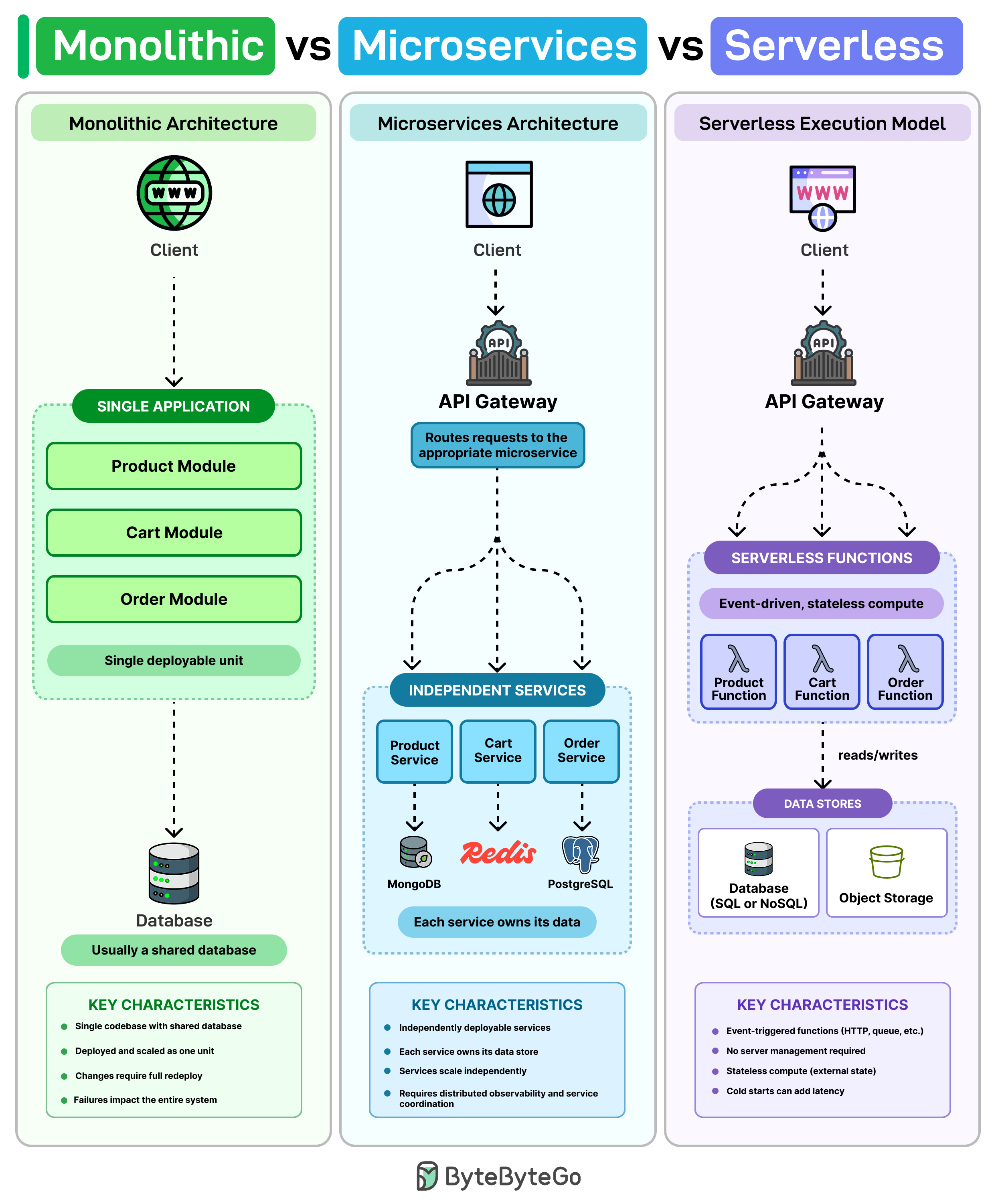
Bài viết phân tích các đánh đổi khi lựa chọn giữa kiến trúc Monolithic, Microservices và Serverless, đồng thời chỉ ra rằng mỗi mô hình đều đi kèm với những thách thức vận hành riêng, từ độ phức tạp trong khâu triển khai (deployment) cho đến vấn đề độ trễ khi khởi động (cold-start latency). Thay vì coi đây là những lựa chọn loại trừ lẫn nhau, tác giả nhấn mạnh rằng đa số các hệ thống thực tế đều vận hành theo hướng hybrid: giữ lại phần core logic trong một monolith vững chắc, trong khi tách các tác vụ cần khả năng scale linh hoạt hoặc xử lý bất đồng bộ sang các services hay functions riêng biệt. Các lập trình viên nên tránh việc áp dụng giáo điều một mô hình duy nhất mà hãy ưu tiên sự đơn giản ở giai đoạn đầu, chỉ chủ động gia tăng độ phức tạp cho kiến trúc khi nhu cầu thực tế về khả năng scale độc lập hoặc tính biệt lập trong triển khai trở nên cần thiết.
Một khối nguyên khối thường là một cơ sở mã, một cơ sở dữ liệu và một lần triển khai.
Thiết kế hệ thống của tuần này’ ôn lại:
Monolithic vs Microservices và Serverless
CLI vs MCP
So sánh 5 loại mã hóa chính Đại lý
Các dịch vụ AWS thiết yếu mà mọi kỹ sư nên biết
JWT Trực quan hóa
Nguyên khối vs Microservices vs Không có máy chủ
Một khối nguyên khối thường là một cơ sở mã, một cơ sở dữ liệu và một lần triển khai. Đối với một nhóm nhỏ, đó’thường là cách đơn giản nhất để xây dựng và vận chuyển nhanh chóng. Vấn đề phát sinh khi cơ sở mã phát triển. Một bản sửa lỗi nhỏ trong mã giỏ hàng yêu cầu triển khai lại toàn bộ ứng dụng và một bản phát hành lỗi có thể phá hủy mọi thứ liên quan đến ứng dụng đó.
Microservices cố gắng giải quyết vấn đề đó bằng cách chia hệ thống thành các dịch vụ riêng biệt. Sản phẩm, Giỏ hàng và Đơn hàng tự chạy, mở rộng quy mô riêng và thường quản lý dữ liệu của riêng chúng. Điều đó có nghĩa là bạn có thể gửi các thay đổi tới Giỏ hàng mà không ảnh hưởng đến phần còn lại của hệ thống.
Nhưng hiện tại bạn đang xử lý nhiều bộ phận chuyển động. Nhìn chung, bạn cần khám phá dịch vụ, theo dõi phân tán và định tuyến yêu cầu giữa các dịch vụ.
Serverless là một mô hình khác. Thay vì quản lý máy chủ, bạn viết các hàm chạy khi có thứ gì đó kích hoạt chúng và nhà cung cấp đám mây sẽ xử lý việc mở rộng quy mô. Trong nhiều trường hợp, bạn chỉ thanh toán khi các hàm đó thực sự chạy.
Tuy nhiên, trong serverless, khởi động nguội có thể tăng thêm độ trễ, việc gỡ lỗi trên nhiều hàm không trạng thái có thể trở nên lộn xộn và bạn càng xây dựng nhiều thời gian chạy xung quanh một đám mây’ thì càng khó chuyển đổi sau.
Hầu hết các hệ thống sản xuất không chỉ sử dụng một phương pháp. Cốt lõi thường có một khối nguyên khối và theo thời gian, các nhóm sẽ phát triển một số dịch vụ mà họ cần mở rộng quy mô độc lập hoặc triển khai nhanh hơn. Serverless có xu hướng hiển thị sau này với những nội dung như thông báo hoặc tác vụ trong nền.
CLI vs MCP
Nhân viên AI cần trao đổi với các công cụ bên ngoài, nhưng họ nên sử dụng CLI hoặc MCP?

Cả hai gọi các API tương tự dưới mui xe. Sự khác biệt là cách tác nhân gọi chúng.
Dưới đây là so sánh song song giữa 6 thứ nguyên:
Chi phí mã thông báo: MCP tải lược đồ JSON đầy đủ (tên công cụ, mô tả, loại trường) vào cửa sổ ngữ cảnh trước khi bất kỳ công việc nào bắt đầu. CLI không cần lược đồ nên tiết kiệm được nhiều cửa sổ ngữ cảnh hơn.
Kiến thức bản địa: LLM đã được đào tạo về hàng tỷ ví dụ CLI. Lược đồ MCP là JSON tùy chỉnh mà mô hình gặp lần đầu tiên trong thời gian chạy.
Khả năng kết hợp: Chuỗi công cụ CLI với hệ điều hành Unix. Một cái gì đó như gh | jq | grep chạy trong một cuộc gọi LLM duy nhất. MCP không có chuỗi gốc. Tác nhân phải sắp xếp từng lệnh gọi công cụ riêng biệt.
Xác thực nhiều người dùng: Tác nhân CLI kế thừa một mã thông báo chung duy nhất. Bạn không thể thu hồi một người dùng mà không xoay khóa của mọi người. MCP hỗ trợ OAuth cho mỗi người dùng.
Phiên có trạng thái: CLI tạo ra một quy trình mới và kết nối TCP cho mỗi lệnh. MCP duy trì một máy chủ ổn định với tính năng tổng hợp kết nối.
Quản trị doanh nghiệp: Dấu vết kiểm tra duy nhất của CLI là ~/.bash_history. MCP cung cấp nhật ký kiểm tra có cấu trúc, thu hồi quyền truy cập và giám sát được tích hợp trong giao thức.
Đối với bạn: Bạn thích CLI hơn MCP trong trường hợp sử dụng nào hoặc ngược lại?
So sánh 5 tác nhân mã hóa chính
Sơ đồ bên dưới so sánh 5 tác nhân hàng đầu trên giao diện, mô hình, cửa sổ ngữ cảnh, quyền tự chủ, v.v.

Đây điều cảnh quan cho chúng ta biết:
Thiết bị đầu cuối là IDE mới. Hầu hết các tác nhân mã hóa hiện nằm trong thiết bị đầu cuối của bạn chứ không phải bên trong trình soạn thảo. Dòng lệnh đã hoạt động trở lại.
Cửa sổ ngữ cảnh ngày càng lớn. Chúng tôi đã tăng từ 8K token lên 1M chỉ trong hai năm. Giờ đây, tổng đài viên có thể suy luận về toàn bộ cơ sở mã chỉ bằng một dấu nhắc.
Quyền tự chủ là một phổ. Một số tác nhân chạy hoàn toàn không đồng bộ trong nền. Những người khác luôn cập nhật cho bạn về mọi chỉnh sửa. Các nhóm vẫn đang tìm hiểu xem nên ủy quyền bao nhiêu.
Nguồn mở đang có được chỗ đứng. Hệ sinh thái tác nhân mã hóa nguồn mở đang phát triển nhanh chóng, mang lại cho các nhóm toàn quyền kiểm soát chuỗi công cụ của họ.
Giá cả rất khác nhau. Từ hoàn toàn miễn phí (Gemini CLI, Deep Agents) đến 15 USD cho mỗi 1 triệu token đầu ra. Kiểm tra hàng chi phí trước khi bạn cam kết.
Không có người chiến thắng duy nhất. Tác nhân tốt nhất phụ thuộc vào quy trình làm việc, ngân sách của bạn và mức độ tự chủ mà bạn cảm thấy thoải mái.
Dành cho bạn: Tác nhân mã hóa nào là động lực hàng ngày của bạn vào năm 2026?
Các dịch vụ AWS thiết yếu mà mọi kỹ sư nên có Biết
AWS có hơn 200 dịch vụ nhưng hầu hết các hệ thống sản xuất chỉ sử dụng một tập hợp con nhỏ. Trong nhiều thiết lập, yêu cầu kết thúc bằng API Gateway, sau đó là ALB, thực thi trên Lambda hoặc ECS, đọc từ DynamoDB và được lưu vào bộ nhớ đệm ElastiCache.

EC2 và S3 thường là điểm khởi đầu đối với nhiều người. Nhưng khi mọi thứ đổ vỡ, trọng tâm sẽ chuyển sang các dịch vụ ban đầu’không được chú ý nhiều, như CloudWatch cho khả năng quan sát, IAM cho kiểm soát truy cập và KMS cho mã hóa.
Mạng có xu hướng khiến mọi thứ trở nên khó hiểu. VPC, mạng con, nhóm bảo mật, Route 53 và CloudFront chạy đằng sau mọi thứ. Khi có sự cố xảy ra, các lỗi’không phải lúc nào cũng giúp ích nhiều.
Các lựa chọn cơ sở dữ liệu không dễ dàng đảo ngược sau này. RDS, DynamoDB và Aurora giải quyết các vấn đề khác nhau và việc thay đổi hướng đi đồng nghĩa với việc thiết kế lại rất nhiều thứ bạn đã xây dựng. Nó’tương tự với lớp tích hợp. Mỗi SQS, SNS và EventBridge xử lý một mẫu khác nhau (xếp hàng, phân xuất và định tuyến sự kiện) và việc chọn sai mẫu sẽ gây ra sự cố mà bạn nhận thấy khi hệ thống đang tải.
SageMaker và Bedrock là các dịch vụ mới hơn nhưng chúng đã là một phần của nhiều công ty. SageMaker dùng để đào tạo và lưu trữ các mô hình, còn Bedrock dùng để gọi trực tiếp các mô hình nền tảng.
CloudFormation cho phép bạn xác định cơ sở hạ tầng dưới dạng mã và CodePipeline xử lý CI/CD. Sau khi thiết lập, quá trình triển khai sẽ diễn ra mà không cần các bước thủ công.
JWT Visualized
Hãy tưởng tượng bạn có một hộp đặc biệt tên là JWT. Bên trong hộp này có ba phần: tiêu đề, tải trọng và chữ ký.
 [[TAG _394]]
[[TAG _394]]