
Claude Opus 4.7
Claude Opus 4.7
Anthropic vừa chính thức ra mắt Claude Opus 4.7, một bản nâng cấp mạnh mẽ với những cải tiến đáng kể trong các tác vụ software engineering phức tạp, khả năng tự sửa lỗi (self-correction) và xử lý hình ảnh độ phân giải cao. Model này được tối ưu hóa để xử lý các luồng công việc nhiều bước, kéo dài với độ chính xác cao hơn, đồng thời tích hợp sẵn các cơ chế bảo mật để chủ động chặn các yêu cầu có rủi ro về an ninh mạng. Đối với các lập trình viên, đây là một công cụ đáng tin cậy hơn cho việc viết code phức tạp và xây dựng các pipeline tự động hóa, trong khi mức giá vẫn được giữ nguyên như phiên bản 4.6. Bạn có thể tích hợp model này vào hệ thống ngay hôm nay thông qua Claude API, Amazon Bedrock, Vertex AI hoặc Microsoft Foundry bằng cách sử dụng identifier `claude-opus-4-7`.
Mẫu mới nhất của chúng tôi, Claude Opus 4.7, hiện đã có sẵn rộng rãi. Opus 4.7 là một cải tiến đáng chú ý trên Opus 4.6 trong công nghệ phần mềm nâng cao, với những lợi ích đặc biệt đối với những nhiệm vụ khó khăn nhất. Người dùng báo cáo...

Mô hình mới nhất của chúng tôi, Claude Opus 4.7, hiện đã có sẵn.
Opus 4.7 là một cải tiến đáng chú ý so với Opus 4.6 trong công nghệ phần mềm tiên tiến, với những lợi ích đặc biệt trong các nhiệm vụ khó khăn nhất. Người dùng báo cáo rằng họ có thể tự tin hoàn thành công việc mã hóa khó khăn nhất của mình - loại công việc trước đây cần được giám sát chặt chẽ - đối với Opus 4.7. Opus 4.7 xử lý các nhiệm vụ phức tạp, dài hạn với sự nghiêm ngặt và nhất quán, chú ý chính xác đến các hướng dẫn và đưa ra các cách để xác minh kết quả đầu ra của chính nó trước khi báo cáo lại.
Mô hình cũng có tầm nhìn tốt hơn đáng kể: nó có thể nhìn thấy hình ảnh ở độ phân giải cao hơn. Nó trang nhã và sáng tạo hơn khi hoàn thành các nhiệm vụ chuyên môn, tạo ra các giao diện, trang trình bày và tài liệu chất lượng cao hơn. Và - mặc dù nó ít có khả năng rộng hơn so với mô hình mạnh nhất của chúng tôi, Claude Mythos Preview - nó cho thấy kết quả tốt hơn Opus 4.6 trên một loạt các tiêu chuẩn:
[[tag_15]]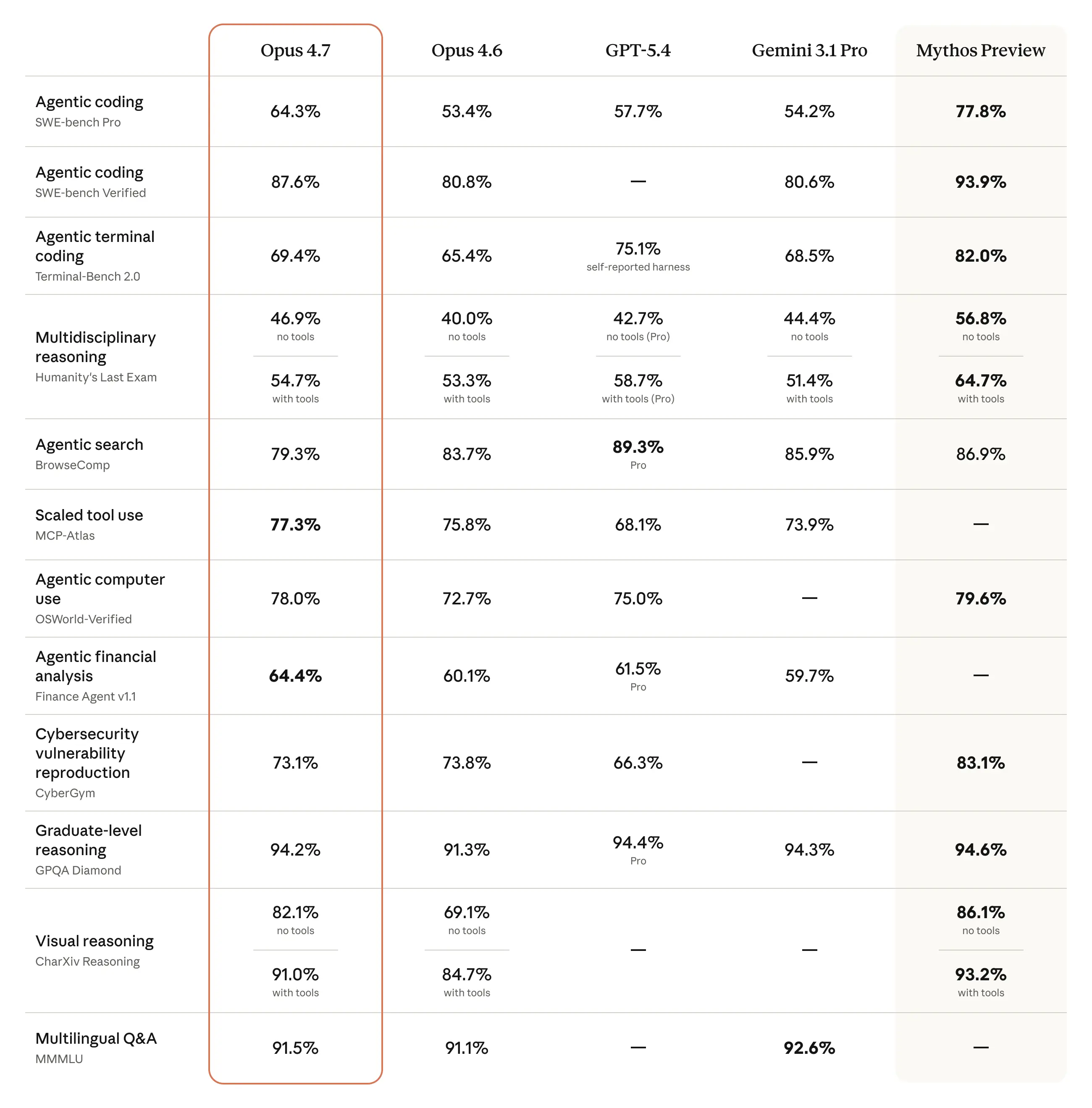
Tuần trước, chúng tôi đã công bố [TAG_21]] Project Glasswing , nêu bật những rủi ro và lợi ích của các mô hình AI đối với an ninh mạng. Chúng tôi đã tuyên bố rằng chúng tôi sẽ giới hạn việc phát hành Claude Mythos Preview và thử nghiệm các biện pháp bảo vệ mạng mới trên các mô hình kém hiệu quả hơn trước tiên. Opus 4.7 là mô hình đầu tiên như vậy: khả năng không gian mạng của nó không tiên tiến như Mythos Preview (thực sự, trong quá trình đào tạo, chúng tôi đã thử nghiệm các nỗ lực để giảm thiểu các khả năng này một cách khác biệt). Chúng tôi đang phát hành Opus 4.7 với các biện pháp bảo vệ tự động phát hiện và chặn các yêu cầu cho thấy việc sử dụng an ninh mạng bị cấm hoặc có nguy cơ cao. Những gì chúng ta học được từ việc triển khai các biện pháp bảo vệ này trong thế giới thực sẽ giúp chúng ta hướng tới mục tiêu cuối cùng là phát hành rộng rãi các mô hình lớp Mythos.
Các chuyên gia bảo mật muốn sử dụng Opus 4.7 cho các mục đích an ninh mạng hợp pháp (như nghiên cứu lỗ hổng, kiểm tra thâm nhập và nhóm đỏ) được mời tham gia Chương trình xác minh mạng mới của chúng tôi .
Opus 4.7 có sẵn hôm nay trên tất cả các sản phẩm Claude và API của chúng tôi, Amazon Bedrock, Vertex AI của Google Cloud và Microsoft Foundry. Giá vẫn giữ nguyên như Opus 4.6: 5 $ cho mỗi triệu token đầu vào và 25 $ cho mỗi triệu token đầu ra. Các nhà phát triển có thể sử dụng claude-opus-4-7 thông qua Claude API.
Thử nghiệm Claude Opus 4.7
Claude Opus 4.7 đã thu thập được phản hồi mạnh mẽ từ những người thử nghiệm truy cập sớm của chúng tôi:
[
Trong thử nghiệm ban đầu, chúng tôi nhận thấy tiềm năng cho một bước nhảy vọt đáng kể cho các nhà phát triển của chúng tôi với Claude Opus 4.7. Nó bắt lỗi logic của chính nó trong giai đoạn lập kế hoạch và tăng tốc thực hiện, vượt xa các mô hình Claude trước đó. Là một nền tảng công nghệ tài chính phục vụ hàng triệu người tiêu dùng và doanh nghiệp ở quy mô đáng kể, sự kết hợp giữa tốc độ và độ chính xác này có thể thay đổi cuộc chơi: đẩy nhanh tốc độ phát triển để cung cấp nhanh hơn các giải pháp tài chính đáng tin cậy mà khách hàng của chúng tôi dựa vào mỗi ngày.
[[tag_51]]
Anthropic đã đặt ra tiêu chuẩn cho các mô hình mã hóa và Claude Opus 4.7 thúc đẩy điều đó hơn nữa một cách có ý nghĩa như là mô hình tiên tiến nhất trên thị trường. Trong các bằng chứng nội bộ của chúng tôi, nó nổi bật không chỉ về khả năng thô, mà còn về khả năng xử lý tốt các quy trình công việc không đồng bộ trong thế giới thực - tự động hóa, CI/CD và các tác vụ dài hạn. Nó cũng suy nghĩ sâu sắc hơn về các vấn đề và mang lại một quan điểm có ý kiến hơn, thay vì chỉ đơn giản là đồng ý với người dùng.

Claude Opus 4.7 là mô hình mạnh nhất mà Hex đã đánh giá. Nó báo cáo chính xác khi dữ liệu bị thiếu thay vì cung cấp các dự phòng hợp lý nhưng không chính xác và nó chống lại các bẫy dữ liệu bất đồng mà ngay cả Opus 4.6 cũng rơi vào. Đó là một Opus 4.6 thông minh hơn, hiệu quả hơn: Opus 4.7 hiệu quả thấp tương đương với Opus 4.6 hiệu quả trung bình.

Trên tiêu chuẩn mã hóa 93 nhiệm vụ của chúng tôi, Claude Opus 4.7 đã nâng độ phân giải lên 13% so với Opus 4.6, bao gồm bốn nhiệm vụ mà cả Opus 4.6 và Sonnet 4.6 đều không thể giải quyết được. Kết hợp với độ trễ trung bình nhanh hơn và tuân theo hướng dẫn nghiêm ngặt, nó đặc biệt có ý nghĩa đối với các quy trình mã hóa phức tạp, dài hạn. Nó cắt giảm ma sát từ những nhiệm vụ nhiều bước đó để các nhà phát triển có thể ở trong dòng chảy và tập trung vào việc xây dựng.

Dựa trên điểm chuẩn đại lý nghiên cứu nội bộ của chúng tôi, Claude Opus 4.7 có đường cơ sở hiệu quả mạnh nhất mà chúng tôi đã thấy cho công việc nhiều bước. Nó gắn liền với điểm tổng thể cao nhất trong sáu mô-đun của chúng tôi ở mức 0,715 và mang lại hiệu suất bối cảnh dài nhất quán của bất kỳ mô hình nào chúng tôi đã thử nghiệm. Về Tài chính Tổng quát - mô-đun lớn nhất của chúng tôi - nó đã được cải thiện một cách có ý nghĩa trên Opus 4.6, đạt 0,813 so với 0,767, đồng thời thể hiện tính tiết lộ và kỷ luật dữ liệu tốt nhất trong nhóm. Và về logic suy luận, một lĩnh vực mà Opus 4.6 gặp khó khăn, Opus 4.7 là vững chắc.

Claude Opus 4.7 mở rộng giới hạn về những gì mô hình có thể làm để điều tra và hoàn thành nhiệm vụ. Anthropic rõ ràng đã được tối ưu hóa cho lý luận bền vững trong thời gian dài, và nó cho thấy hiệu suất dẫn đầu thị trường. Khi các kỹ sư chuyển từ làm việc 1:1 với các đại lý sang quản lý chúng song song, đây chính xác là loại khả năng biên giới mở ra quy trình công việc mới.

Chúng ta đang thấy những cải tiến lớn trong sự hiểu biết đa phương thức của Claude Opus 4.7, từ việc đọc các cấu trúc hóa học đến việc diễn giải các sơ đồ kỹ thuật phức tạp. Hỗ trợ độ phân giải cao hơn đang giúp Solve Intelligence xây dựng các công cụ tốt nhất cho quy trình cấp bằng sáng chế khoa học đời sống, từ soạn thảo và truy tố đến phát hiện vi phạm và lập biểu đồ vô hiệu.

Claude Opus 4.7 đưa quyền tự chủ lâu dài lên một tầm cao mới ở Devin. Nó hoạt động mạch lạc trong nhiều giờ, vượt qua các vấn đề khó khăn thay vì bỏ cuộc và mở ra một lớp công việc điều tra sâu sắc mà trước đây chúng ta không thể thực hiện một cách đáng tin cậy.

Đối với Replit, Claude Opus 4.7 là một quyết định nâng cấp dễ dàng. Đối với công việc mà người dùng của chúng tôi làm hàng ngày, chúng tôi đã quan sát thấy nó đạt được chất lượng tương tự với chi phí thấp hơn - hiệu quả và chính xác hơn trong các tác vụ như phân tích nhật ký và dấu vết, tìm lỗi và đề xuất các bản sửa lỗi. Cá nhân, tôi thích cách nó đẩy lùi trong các cuộc thảo luận kỹ thuật để giúp tôi đưa ra quyết định tốt hơn. Nó thực sự mang lại cảm giác như một đồng nghiệp tốt hơn.

Claude Opus 4.7 thể hiện độ chính xác thực chất mạnh mẽ trên BigLaw Bench cho Harvey, đạt 90,9% với nỗ lực cao với hiệu chuẩn lý luận tốt hơn trên các bảng đánh giá và xử lý thông minh hơn các tác vụ chỉnh sửa tài liệu mơ hồ. Nó phân biệt chính xác các điều khoản phân công với các điều khoản thay đổi kiểm soát, một nhiệm vụ đã thách thức các mô hình biên giới trong lịch sử. Chất luôn được đánh giá là một điểm mạnh trong các đánh giá của chúng tôi: chính xác, kỹ lưỡng và được trích dẫn tốt.

Claude Opus 4.7 là một mô hình mã hóa rất ấn tượng, đặc biệt là về tính tự chủ và lý luận sáng tạo hơn. Trên CursorBench, Opus 4.7 là một bước nhảy có ý nghĩa về khả năng, xóa 70% so với Opus 4.6 ở mức 58%.

[[tag_147]]Đối với quy trình làm việc nhiều bước phức tạp, Claude Opus 4.7 là một bước tiến rõ ràng: cộng thêm 14% so với Opus 4.6 với ít mã thông báo hơn và một phần ba lỗi công cụ. Đây là mô hình đầu tiên vượt qua các bài kiểm tra cần thiết ngầm của chúng tôi và nó tiếp tục thực hiện thông qua các lỗi công cụ được sử dụng để ngăn chặn Opus lạnh. Đây là bước nhảy vọt về độ tin cậy khiến Notion Agent cảm thấy như một đồng đội thực sự.

Trong các bằng chứng của chúng tôi, chúng tôi đã thấy một bước nhảy hai chữ số về độ chính xác của các lệnh gọi công cụ và lập kế hoạch trong các tác nhân điều phối cốt lõi của chúng tôi. Khi người dùng tận dụng Hebbia để lập kế hoạch và thực hiện các trường hợp sử dụng như truy xuất, tạo trang trình bày hoặc tạo tài liệu, Claude Opus 4.7 cho thấy tiềm năng cải thiện việc ra quyết định của nhân viên chăm sóc khách hàng trong các quy trình công việc này.

Trên Rakuten-SWE-Bench, Claude Opus giải quyết nhiều tác vụ sản xuất hơn gấp 3 lần so với Opus 4.6, với mức tăng hai chữ số về Chất lượng mã và Chất lượng kiểm tra. Đây là một sự nâng cấp có ý nghĩa và rõ ràng cho công việc kỹ thuật mà đội ngũ của chúng tôi đang vận chuyển mỗi ngày.

Đối với khối lượng công việc đánh giá mã của CodeRabbit, Claude Opus 4.7 là mô hình sắc nét nhất mà chúng tôi đã thử nghiệm. Khả năng nhớ lại được cải thiện hơn 10%, hiển thị một số lỗi khó phát hiện nhất trong các PR phức tạp nhất của chúng tôi, trong khi độ chính xác vẫn ổn định mặc dù độ bao phủ tăng lên. Nó nhanh hơn một chút so với GPT-5.4 xhigh trên dây nịt của chúng tôi và chúng tôi đang xếp hàng cho công việc đánh giá nặng nhất của chúng tôi khi ra mắt.

Đối với Super Agent của Genspark, Claude Opus 4.7 đóng đinh ba yếu tố khác biệt sản xuất quan trọng nhất: khả năng chống vòng lặp, tính nhất quán và khôi phục lỗi dễ dàng. Kháng vòng lặp là quan trọng nhất. Một mô hình lặp vô thời hạn trên 1 trong 18 truy vấn đã làm lãng phí tính toán và chặn người dùng. Phương sai thấp hơn có nghĩa là ít bất ngờ hơn về sản phẩm. Và Opus 4.7 đạt được tỷ lệ chất lượng trên mỗi cuộc gọi cao nhất mà chúng tôi đã đo được.

Claude Opus 4.7 là một bước tiến có ý nghĩa đối với Warp. Opus 4.6 là một trong những mô hình tốt nhất hiện có cho các nhà phát triển và mô hình này được đo lường kỹ lưỡng hơn. Nó đã vượt qua các nhiệm vụ Terminal Bench mà các mô hình Claude trước đó đã thất bại và làm việc thông qua một lỗi đồng thời khó khăn Opus 4.6 không thể crack. Đối với chúng tôi, đó là tín hiệu.
 [[tag_196]]
[[tag_196]]
Claude Opus 4.7 là mô hình tốt nhất trên thế giới để xây dựng bảng điều khiển và giao diện giàu dữ liệu. Hương vị thiết kế thực sự đáng ngạc nhiên - nó đưa ra những lựa chọn mà tôi thực sự muốn đưa ra. Bây giờ nó là tài xế mặc định hàng ngày của tôi.

Claude Opus 4.7 là mô hình có khả năng nhất mà chúng tôi đã thử nghiệm tại Quantium. Được đánh giá dựa trên các mô hình AI hàng đầu thông qua giải pháp đo điểm chuẩn độc quyền của chúng tôi, lợi ích lớn nhất thể hiện ở nơi chúng quan trọng nhất: chiều sâu lý luận, khung vấn đề có cấu trúc và công việc kỹ thuật phức tạp. Sửa chữa ít hơn, lặp lại nhanh hơn và kết quả đầu ra mạnh mẽ hơn để giải quyết những vấn đề khó khăn nhất mà khách hàng của chúng tôi mang lại cho chúng tôi.

Claude Opus 4.7 cảm thấy như một bước tiến thực sự trong trí thông minh. Chất lượng mã được cải thiện đáng kể, nó cắt bỏ các chức năng bao bọc vô nghĩa và giàn giáo dự phòng từng được sử dụng để chồng chất và sửa mã riêng của nó khi nó hoạt động. Đó là bước nhảy sạch nhất mà chúng tôi từng thấy kể từ khi chuyển từ Sonnet 3.7 sang loạt Claude 4.

Đối với công việc sử dụng máy tính nằm ở trung tâm của thử nghiệm thâm nhập tự trị của XBOW, Claude Opus 4.7 mới là một bước thay đổi: 98,5% trên điểm chuẩn trực quan của chúng tôi so với 54,5% đối với Opus 4.6. Điểm đau Opus lớn nhất của chúng tôi đã biến mất một cách hiệu quả và điều đó mở ra việc sử dụng nó cho cả một lớp công việc mà trước đây chúng tôi không thể sử dụng nó.

Claude Opus 4.7 là một bản nâng cấp vững chắc không có hồi quy cho Vercel. Nó là hiện tượng trên các tác vụ mã hóa một lần, chính xác và đầy đủ hơn Opus 4.6, và đáng chú ý là trung thực hơn về các giới hạn của chính nó. Nó thậm chí còn thực hiện các bằng chứng về mã hệ thống trước khi bắt đầu công việc, đó là hành vi mới mà chúng ta chưa từng thấy từ các mô hình Claude trước đó.
[[tag_240]]
Claude Opus 4.7 rất mạnh và vượt trội hơn Opus 4.6 với mức tăng thành công nhiệm vụ từ 10% đến 15% cho Factory Droids, với ít lỗi công cụ hơn và theo dõi đáng tin cậy hơn trong các bước xác thực. Nó thực hiện công việc thay vì dừng lại giữa chừng, đó chính xác là những gì các nhóm kỹ thuật doanh nghiệp cần.

Claude Opus đã tự động xây dựng một công cụ chuyển văn bản thành giọng nói Rust hoàn chỉnh từ mô hình thần kinh cào, nhân SIMD, bản trình duyệt demo - sau đó cung cấp đầu ra của chính nó thông qua trình nhận dạng giọng nói để xác minh nó khớp với tham chiếu Python. Nhiều tháng kỹ thuật cao cấp, được thực hiện một cách tự chủ. Bước tiến từ Opus 4.6 là rõ ràng, và cơ sở mã là công khai.

Claude Opus 4.7 đã vượt qua ba nhiệm vụ TBench mà các mô hình Claude trước đó không thể thực hiện, và nó đang sửa chữa các mô hình tốt nhất trước đây của chúng tôi bị bỏ lỡ, bao gồm cả điều kiện cuộc đua. Nó thể hiện độ chính xác cao trong việc xác định các vấn đề thực tế và đưa ra những phát hiện quan trọng mà các mô hình khác đã từ bỏ hoặc không giải quyết được. Trong tiêu chuẩn đánh giá mã trong thế giới thực của Qodo, chúng tôi đã quan sát thấy độ chính xác hàng đầu.
 [[tag_268]]
[[tag_268]]
Trên OfficeQA Pro của Databricks, Claude Opus 4.7 cho thấy lý luận tài liệu mạnh mẽ hơn, với ít lỗi hơn 21% so với Opus 4.6 khi làm việc với thông tin nguồn. Theo lý luận đại diện của chúng tôi về điểm chuẩn dữ liệu, đây là mô hình Claude hoạt động tốt nhất để phân tích tài liệu doanh nghiệp.

Đối với Ramp, Claude Opus 4.7 nổi bật trong quy trình làm việc của nhóm tác nhân. Chúng ta đang thấy vai trò trung thực mạnh mẽ hơn, tuân theo hướng dẫn, phối hợp và lý luận phức tạp, đặc biệt là về các nhiệm vụ kỹ thuật bao gồm các công cụ, cơ sở mã và bối cảnh gỡ lỗi. So với Opus 4.6, nó cần ít hướng dẫn từng bước hơn nhiều, giúp chúng tôi mở rộng quy trình làm việc của nhân viên nội bộ mà nhóm kỹ thuật của chúng tôi điều hành.

Claude Opus 4.7 là tốt hơn đáng kể so với Opus 4.6 đối với công việc xây dựng ứng dụng chạy lâu hơn của Bolt, tốt hơn tới 10% trong những trường hợp tốt nhất mà không có sự hồi quy mà chúng tôi mong đợi từ các mô hình rất tác nhân. Nó đẩy mức trần về số lượng nội dung mà người dùng của chúng tôi có thể gửi trong một phiên duy nhất.
01 /
28
Dưới đây là một số điểm nổi bật và ghi chú từ quá trình thử nghiệm Opus 4.7 ban đầu của chúng tôi:
- Hướng dẫn sau. Opus 4.7 tốt hơn đáng kể khi làm theo hướng dẫn. Thật thú vị, điều này có nghĩa là các lời nhắc được viết cho các mô hình trước đó đôi khi có thể tạo ra các kết quả không mong muốn: trong đó các mô hình trước đó diễn giải các hướng dẫn một cách lỏng lẻo hoặc bỏ qua hoàn toàn các phần, thì Opus 4.7 thực hiện các hướng dẫn theo đúng nghĩa đen. Người dùng nên điều chỉnh lại lời nhắc và khai thác cho phù hợp.
- Hỗ trợ đa phương thức được cải thiện. Opus 4.7 có tầm nhìn tốt hơn đối với hình ảnh có độ phân giải cao: nó có thể chấp nhận hình ảnh lên tới 2.576 pixel ở cạnh dài (~3,75 megapixel), gấp hơn ba lần so với các mẫu Claude trước đây. Điều này mở ra vô số cách sử dụng đa phương thức phụ thuộc vào chi tiết hình ảnh đẹp: tác nhân sử dụng máy tính đọc ảnh chụp màn hình dày đặc, trích xuất dữ liệu từ các sơ đồ phức tạp và công việc cần tham chiếu pixel hoàn hảo.1
- Công việc trong thế giới thực. Cùng với điểm số cao nhất về đánh giá Đại lý Tài chính (xem bảng ở trên), thử nghiệm nội bộ của chúng tôi cho thấy Opus 4.7 là nhà phân tích tài chính hiệu quả hơn Opus 4.6, tạo ra các phân tích và mô hình nghiêm ngặt, trình bày chuyên nghiệp hơn và tích hợp chặt chẽ hơn giữa các nhiệm vụ. Opus 4.7 cũng là phiên bản tiên tiến nhất về GDPval-AA, một đánh giá của bên thứ ba về công việc kiến thức có giá trị kinh tế trên các lĩnh vực tài chính, pháp lý và các lĩnh vực khác.
- Bộ nhớ. Opus 4.7 sử dụng bộ nhớ dựa trên hệ thống tệp tốt hơn. Nó ghi nhớ các ghi chú quan trọng trong công việc kéo dài, nhiều phiên và sử dụng chúng để chuyển sang các nhiệm vụ mới, do đó cần ít bối cảnh ban đầu hơn.
Các biểu đồ bên dưới hiển thị nhiều kết quả đánh giá hơn từ thử nghiệm trước khi phát hành của chúng tôi, trên nhiều miền khác nhau:
An toàn và căn chỉnh
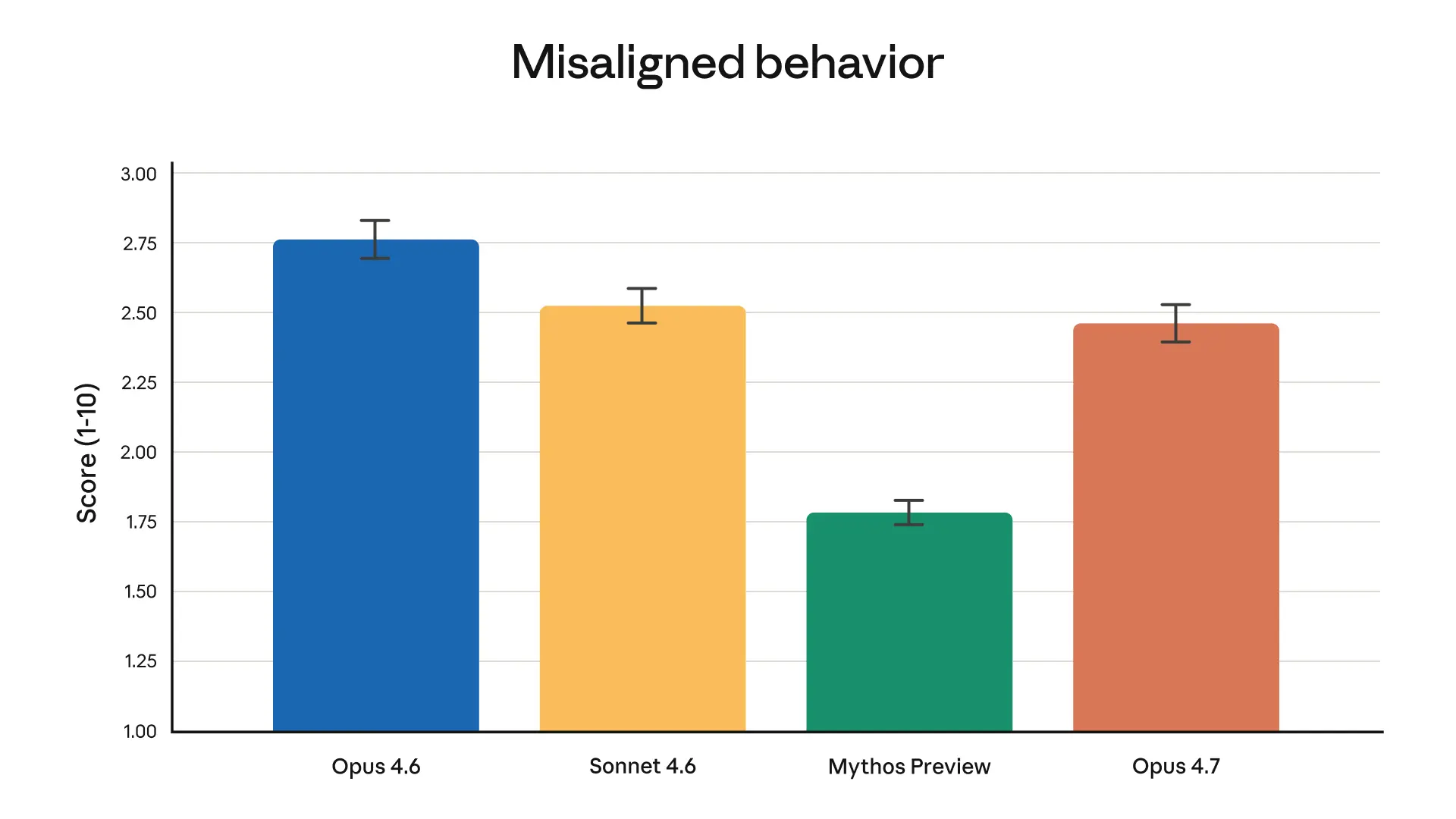
Nhìn chung, Opus 4.7 hiển thị hồ sơ an toàn tương tự như Opus 4.6: đánh giá của chúng tôi cho thấy tỷ lệ thấp về các hành vi liên quan như lừa dối, nịnh bợ và hợp tác với việc lạm dụng. Về một số biện pháp, chẳng hạn như tính trung thực và khả năng chống lại các cuộc tấn công “nhanh chóng” độc hại, Opus 4.7 là một cải tiến trên Opus 4.6; ở những trường hợp khác (chẳng hạn như xu hướng đưa ra lời khuyên giảm thiểu tác hại quá chi tiết đối với các chất được kiểm soát), Opus 4.7 yếu hơn một cách khiêm tốn. Đánh giá liên kết của chúng tôi kết luận rằng mô hình này “phần lớn được liên kết tốt và đáng tin cậy, mặc dù không hoàn toàn lý tưởng trong hành vi của nó”. Lưu ý rằng Mythos Preview vẫn là mô hình phù hợp nhất mà chúng tôi đã đào tạo theo đánh giá của mình. Đánh giá về an toàn của chúng tôi được thảo luận đầy đủ trong Thẻ hệ thống Claude Opus 4.7.
Cũng ra mắt hôm nay
Ngoài Claude Opus 4.7, chúng tôi cũng sẽ ra mắt phiên bản này các bản cập nhật sau:
- Kiểm soát nỗ lực nhiều hơn: Opus 4.7 giới thiệu
xhighmới (“cực cao”) mức nỗ lực giữacaovàmax, giúp người dùng kiểm soát tốt hơn sự cân bằng giữa lý luận và độ trễ đối với các vấn đề khó. Trong Claude Code, chúng tôi đã tăng mức nỗ lực mặc định lênxhighcho tất cả các gói. Khi kiểm tra Opus 4.7 cho các trường hợp sử dụng mã hóa và tác nhân, chúng tôi khuyên bạn nên bắt đầu với nỗ lựchighhoặcxhigh. - Trên Nền tảng Claude (API): cũng như hỗ trợ cho hình ảnh có độ phân giải cao hơn, chúng tôi cũng đang triển khai ngân sách nhiệm vụ trong phiên bản beta công khai, mang đến cho các nhà phát triển một cách hướng dẫn việc chi tiêu mã thông báo của Claude để họ có thể ưu tiên công việc trong thời gian dài hơn chạy.
- Trong Claude Code: Lệnh gạch chéo
/ultrareviewslash mới tạo ra một phiên đánh giá chuyên biệt có chức năng đọc qua các thay đổi và gắn cờ các lỗi cũng như các vấn đề về thiết kế mà người đánh giá cẩn thận sẽ nắm bắt được. Chúng tôi đang cung cấp cho người dùng Pro và Max Claude Code ba bản siêu đánh giá miễn phí để dùng thử. Ngoài ra, chúng tôi đã mở rộng chế độ tự động cho người dùng Max. Chế độ tự động là tùy chọn quyền mới trong đó Claude thay mặt bạn đưa ra quyết định, nghĩa là bạn có thể thực hiện các tác vụ lâu hơn với ít gián đoạn hơn—và ít rủi ro hơn so với khi bạn chọn bỏ qua tất cả các quyền.
Di chuyển từ Opus 4.6 sang Opus 4.7
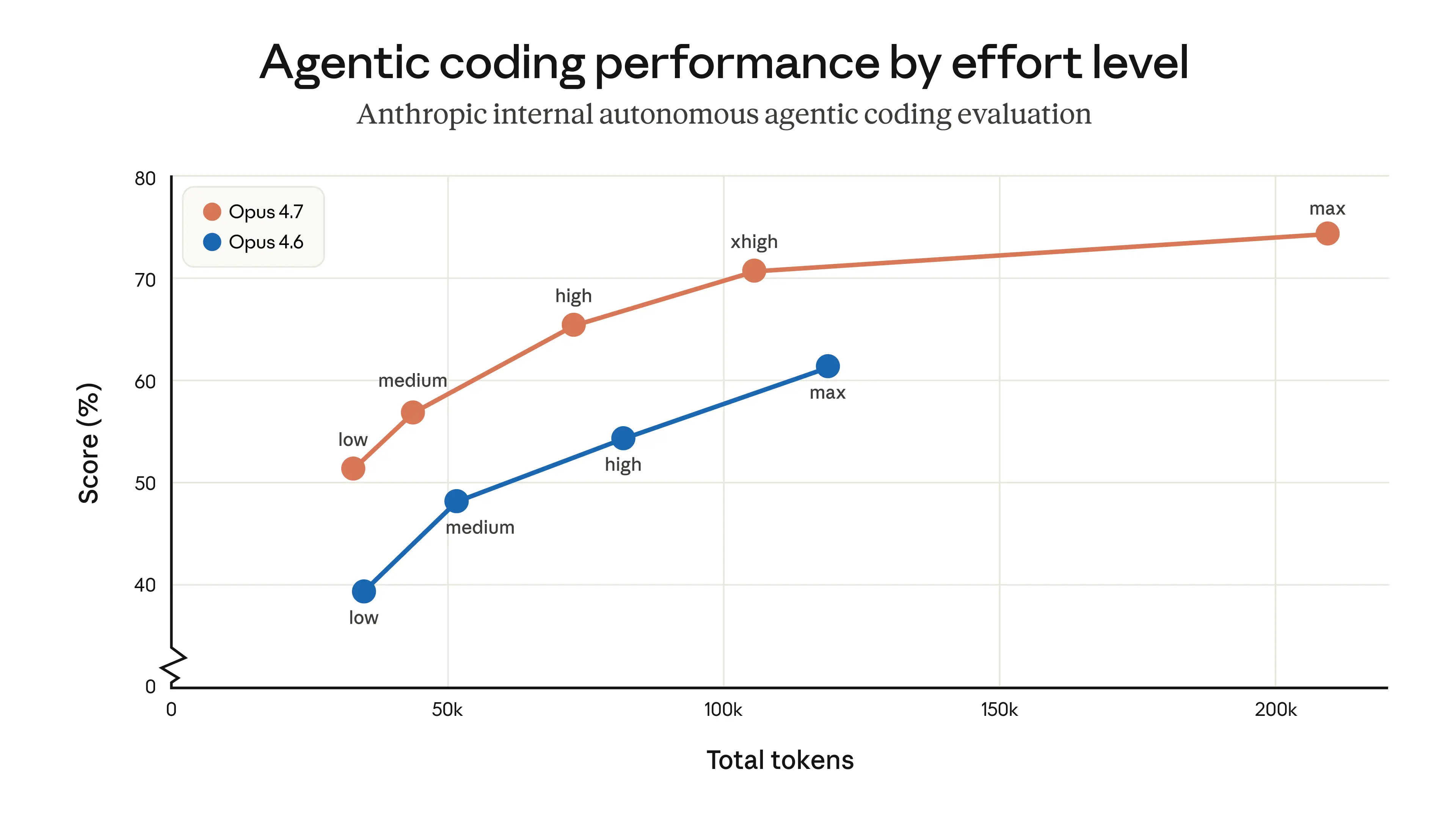
Opus 4.7 là bản nâng cấp trực tiếp lên Opus 4.6, nhưng có hai thay đổi đáng được lập kế hoạch vì chúng ảnh hưởng đến việc sử dụng mã thông báo. Đầu tiên, Opus 4.7 sử dụng mã thông báo được cập nhật để cải thiện cách mô hình xử lý văn bản. Sự cân bằng là cùng một đầu vào có thể ánh xạ tới nhiều mã thông báo hơn—khoảng 1,0–1,35× tùy thuộc vào loại nội dung. Thứ hai, Opus 4.7 suy nghĩ nhiều hơn ở mức độ nỗ lực cao hơn, đặc biệt là ở những lượt sau trong cài đặt tác nhân. Điều này cải thiện độ tin cậy của nó đối với các vấn đề khó khăn, nhưng nó không có nghĩa là nó tạo ra nhiều mã thông báo đầu ra hơn.
Người dùng có thể kiểm soát việc sử dụng mã thông báo theo nhiều cách khác nhau: bằng cách sử dụng tham số nỗ lực, điều chỉnh ngân sách nhiệm vụ của họ hoặc nhắc mô hình ngắn gọn hơn. Trong thử nghiệm của chúng tôi, hiệu quả thực sự là thuận lợi—việc sử dụng mã thông báo ở tất cả các cấp độ nỗ lực được cải thiện trong quá trình đánh giá mã hóa nội bộ, như minh họa bên dưới—nhưng chúng tôi khuyên bạn nên đo lường sự khác biệt trên lưu lượng truy cập thực. Chúng tôi đã viết hướng dẫn di chuyển cung cấp thêm lời khuyên về việc nâng cấp từ Opus 4.6 lên Opus 4.7.
Chú thích cuối trang
1 Đây là một thay đổi cấp độ mô hình thay vì tham số API, do đó hình ảnh người dùng gửi cho Claude sẽ đơn giản được xử lý ở độ trung thực cao hơn. Vì hình ảnh có độ phân giải cao hơn tiêu tốn nhiều mã thông báo hơn nên người dùng không yêu cầu thêm chi tiết có thể lấy mẫu hình ảnh xuống trước khi gửi chúng tới mô hình.
- Đối với GPT-5.4 và Gemini 3.1 Pro, chúng tôi đã so sánh với phiên bản mô hình được báo cáo tốt nhất hiện có thông qua API trong biểu đồ và bảng.
- MCP-Atlas: The Opus 4.6 điểm đã được cập nhật để phản ánh phương pháp chấm điểm được sửa đổi từ Thang điểm AI.
- SWE-bench Trusted, Pro và Multilingual: Màn hình ghi nhớ của chúng tôi gắn cờ một tập hợp con các vấn đề trong các bài đánh giá của SWE-bench này. Loại trừ mọi vấn đề có dấu hiệu ghi nhớ, biên độ cải thiện của Opus 4.7 so với Opus 4.6 vẫn giữ nguyên.
- Terminal-Bench 2.0: Chúng tôi đã sử dụng dây nịt Terminus-2 với người bị khuyết tật tư duy. Tất cả các thử nghiệm sử dụng mức phân bổ tài nguyên trần được đảm bảo 1×/3× đều đạt trung bình trong 5 lần thử cho mỗi nhiệm vụ.
- CyberGym: Điểm của Opus 4.6 đã được cập nhật từ 66,6 lên 73,8 được báo cáo ban đầu vì chúng tôi đã cập nhật các tham số khai thác của mình để phát huy khả năng mạng tốt hơn.
- SWE-bench Multimodal: Chúng tôi đã sử dụng cách triển khai nội bộ cho cả hai Opus 4.7 và Opus 4.6. Điểm không thể so sánh trực tiếp với điểm trên bảng xếp hạng công khai.
Tác giả: meetpateltech