
Chroma Context-1: Đào tạo tác nhân tìm kiếm tự chỉnh sửa
Chroma Context-1: Training a Self-Editing Search Agent
Bài viết giới thiệu Chroma Context-1, một mô hình search agentic với 20 tỷ tham số, được thiết kế cho multi-hop retrieval. Chroma Context-1 khắc phục hạn chế của RAG truyền thống chỉ một giai đoạn, bằng cách cho phép tìm kiếm lặp đi lặp lại, được điều khiển bởi LLM. Mô hình này có khả năng phân tách truy vấn và tinh chỉnh chiến lược qua nhiều lượt tương tác. Điểm đổi mới quan trọng là cơ chế "self-editing context", nơi agent tự động loại bỏ thông tin không liên quan để quản lý tình trạng "context window bloat", từ đó cải thiện hiệu quả và độ chính xác. Các developer nên lưu ý rằng các mô hình nhỏ hơn, được huấn luyện chuyên biệt (purpose-trained) hoàn toàn có thể đạt được hiệu suất retrieval "state-of-the-art" với chi phí và độ trễ thấp hơn đáng kể. Điều này đặc biệt hữu ích cho các tác vụ search phức tạp, yêu cầu nhiều lượt tương tác (multi-turn search).
Quy trình truy xuất thường hoạt động theo một lượt duy nhất, điều này gây ra vấn đề khi thông tin cần thiết để trả lời một câu hỏi được trải rộng trên nhiều tài liệu hoặc yêu cầu lý luận trung gian để xác định vị trí. Trong thực tế, nhiều truy vấn trong thế giới thực yêu cầu truy xuất nhiều bước nhảy, trong đó kết quả của một tìm kiếm sẽ thông báo cho tìm kiếm tiếp theo. Công việc gần đây đã chỉ ra rằng các LLM biên giới thực hiện tìm kiếm nhiều bước này một cách hiệu quả thông qua một quy trình được gọi là tìm kiếm tác nhân, được định nghĩa đơn giản là một vòng lặp các cuộc gọi LLM với các công cụ tìm kiếm. Chế độ tìm kiếm này thường đi kèm với chi phí và độ trễ đáng kể do họ sử dụng LLM quy mô biên giới. Chúng tôi giới thiệu Chroma Context-1, một mô hình tìm kiếm tác nhân tham số 20B có nguồn gốc từ gpt-oss-20B, đạt được hiệu suất truy xuất tương đương với LLM quy mô biên giới với chi phí thấp và tốc độ suy luận nhanh hơn tới 10 lần. Bối cảnh-1 được thiết kế để sử dụng như một tác nhân phụ kết hợp với mô hình lý luận biên giới. Đưa ra một truy vấn, nó tạo ra một danh sách được xếp hạng các tài liệu có liên quan đến việc đáp ứng truy vấn. Mô hình này được đào tạo để phân tách các truy vấn thành các truy vấn phụ, tìm kiếm lặp đi lặp lại một kho văn bản và chỉnh sửa có chọn lọc bối cảnh của chính nó để giải phóng khả năng khám phá thêm.
Giới thiệu#
Sử dụng hệ thống tìm kiếm kết hợp với mô hình ngôn ngữ lớn (LLM) là mô hình phổ biến để cho phép các mô hình ngôn ngữ truy cập dữ liệu ngoài kho dữ liệu đào tạo của chúng. Cách tiếp cận này, thường được gọi là retrieval-augmented-Generation (RAG), theo truyền thống dựa vào quy trình truy xuất một giai đoạn bao gồm tìm kiếm vectơ, tìm kiếm từ vựng hoặc đối sánh biểu thức chính quy, theo sau là một trình xếp hạng lại đã học, tùy chọn. Mặc dù hiệu quả đối với các truy vấn tra cứu đơn giản, nhưng về cơ bản, các quy trình này bị hạn chế: chúng cho rằng thông tin cần thiết để trả lời một câu hỏi có thể được truy xuất chỉ trong một lần chuyển.
Trong thực tế, nhiều truy vấn trong thế giới thực không thể đáp ứng được chỉ trong một giai đoạn. Việc trả lời một câu hỏi thường đòi hỏi một chuỗi tìm kiếm trung gian trong đó kết quả của một tìm kiếm sẽ thông báo cho tìm kiếm tiếp theo, một quy trình được gọi là truy xuất nhiều bước nhảy.
Để giải quyết vấn đề này, việc tận dụng LLM cho tìm kiếm tác nhân nhiều lượt đã trở thành một phương pháp khả thi để trả lời các truy vấn truy xuất nhiều bước nhảy. Thay vì đưa ra một truy vấn duy nhất, tác nhân LLM lặp đi lặp lại phân tách một câu hỏi cấp cao thành các truy vấn phụ, truy xuất bằng chứng và tinh chỉnh chiến lược tìm kiếm của nó qua nhiều lượt. Đồng thời, người ta đã chứng minh rằng các mô hình ngôn ngữ tham số nhỏ hơn, được đào tạo trên ngữ liệu quy mô vừa phải, có thể đóng vai trò là tác nhân tìm kiếm hiệu quả với hiệu suất tương đương với các mô hình lớn hơn đáng kể. Việc chạy các mô hình quy mô biên giới cho tìm kiếm nhiều lượt phải chịu chi phí và độ trễ cao, điều này thúc đẩy việc chuyển nhiệm vụ này sang một mô hình nhỏ hơn, được đào tạo có mục đích.
Yếu tố chính thúc đẩy chi phí và độ trễ của tìm kiếm tác nhân là sự phát triển của cửa sổ ngữ cảnh. Khi tác nhân thu thập thông tin qua nhiều lượt, cửa sổ ngữ cảnh của nó sẽ nhanh chóng lấp đầy các tài liệu được truy xuất, nhiều tài liệu trong số đó có thể là tiếp tuyến hoặc dư thừa. Bối cảnh cồng kềnh này không chỉ làm tăng chi phí tính toán mà còn có thể làm giảm hiệu suất ở hạ lưu do sự hiện diện của thông tin gây mất tập trung ngày càng tăng. Một hướng đầy hứa hẹn để giải quyết vấn đề này là ngữ cảnh tự chỉnh sửa, trong đó tác nhân chủ động quyết định thông tin nào đã truy xuất sẽ giữ lại và thông tin nào cần loại bỏ, cho phép tác nhân tiếp tục các tác vụ tìm kiếm trong phạm vi dài hiệu quả hơn và chính xác hơn trong cửa sổ ngữ cảnh giới hạn.
Dựa trên những hiểu biết sâu sắc này, chúng tôi đã đào tạo Chroma Context-1, một mô hình tìm kiếm tác nhân tham số 20B trên hơn tám nghìn tác vụ được tạo tổng hợp. Context-1 đạt được hiệu suất truy xuất tương đương với LLM biên giới với chi phí thấp và tốc độ suy luận lên tới 10 lần. Context-1 hoạt động như một tác nhân phụ truy xuất: thay vì trả lời trực tiếp các câu hỏi, nó trả về một tập hợp tài liệu hỗ trợ được xếp hạng cho mô hình trả lời xuôi dòng, tách biệt rõ ràng tìm kiếm khỏi quá trình tạo. Mô hình này được đào tạo để phân tách một truy vấn cấp cao thành các truy vấn phụ và tìm kiếm lặp đi lặp lại một kho văn bản qua nhiều lượt. Khi cửa sổ ngữ cảnh của tác nhân lấp đầy, nó sẽ loại bỏ có chọn lọc các kết quả không liên quan để giải phóng dung lượng và giảm tiếng ồn để khám phá thêm.
Trong công việc này, chúng tôi trình bày quy trình tạo dữ liệu tổng hợp, khai thác tác nhân và phương pháp đào tạo cùng với đánh giá toàn diện về Ngữ cảnh-1 trên một loạt các tiêu chuẩn truy xuất. Kết quả của chúng tôi chứng minh rằng mô hình 20B được huấn luyện có mục đích có thể đạt đến giới hạn Pareto về hiệu suất truy xuất xét về chi phí và độ trễ, khớp hoặc vượt các mô hình biên giới có cấp độ lớn hơn ở một phần nhỏ của điện toán.
Các kỹ thuật chính#
Chúng tôi trình bày như sau:
- Một chương trình đào tạo theo giai đoạn nhằm tối ưu hóa việc thu hồi trước tiên trước khi chuyển sang độ chính xác, huấn luyện tác nhân thu hẹp dần từ truy xuất rộng rãi đến lưu giữ có chọn lọc. Chúng tôi phát hành trọng lượng của mô hình này ra công chúng theo giấy phép Apache 2.0 dễ dãi.
- Một chiến lược quản lý ngữ cảnh trong đó tác nhân chỉnh sửa có chọn lọc ngữ cảnh của chính nó trong quá trình tìm kiếm, loại bỏ các đoạn không liên quan để giải phóng dung lượng ngữ cảnh nhằm khám phá thêm và giảm tác động của việc làm hỏng ngữ cảnh.
- Một quy trình tạo nhiệm vụ tổng hợp có thể mở rộng sử dụng đánh giá LLM phù hợp với con người để giảm thiểu nhu cầu chú thích của con người trong khi vẫn duy trì chất lượng nhiệm vụ. Chúng tôi phát hành cơ sở mã đầy đủ cho quy trình này để hỗ trợ khả năng tái tạo và nghiên cứu sâu hơn.
Công việc liên quan#
Những hạn chế của truy xuất một lần đã thúc đẩy việc khám phá đáng kể các hệ thống tìm kiếm tác nhân, trong đó lý luận được xen kẽ với truy xuất để giải quyết các truy vấn yêu cầu thỏa mãn nhiều ràng buộc cùng nhau hoặc tuân theo một chuỗi manh mối phụ thuộc trên các tài liệu. Các hệ thống này khác nhau về chiến lược chấm dứt: một số chạy trong một số lượt cố định, trong khi một số khác chấm dứt động dựa trên tín hiệu đủ đã học. Bằng cách chuyển quyền kiểm soát chiến lược truy xuất sang chính mô hình, các hệ thống này có thể định dạng lại các truy vấn dựa trên kết quả trung gian, quyết định thời điểm khám phá hay khai thác và chấm dứt tìm kiếm dựa trên đánh giá độ tin cậy. Các hệ thống này mô hình hóa tìm kiếm như một nhiệm vụ suy luận tuần tự, trong đó truy vấn tiếp theo phụ thuộc vào những gì đã được tìm thấy cho đến nay. Các điểm chuẩn như InfoDeepSeek, đánh giá hoạt động tìm kiếm thông tin tác nhân trong môi trường web động, cung cấp các thử nghiệm có kiểm soát để đo lường chất lượng truy xuất nhiều lượt. Tuy nhiên, hầu hết các hệ thống tìm kiếm tác nhân hiện tại đều dựa vào các mô hình có quy mô biên giới để điều khiển vòng lặp truy xuất, khiến chúng tốn kém và tốn nhiều thời gian để triển khai trên quy mô lớn.
Để khắc phục những hạn chế của việc sử dụng một mô hình duy nhất cho cả truy xuất và tạo, công việc gần đây đã khám phá việc tách các vai trò này thông qua kiến trúc tác nhân phụ. hệ thống nghiên cứu đa tác nhân của Anthropic sử dụng một bộ điều phối tạo ra các tác nhân phụ song song để khám phá các khía cạnh khác nhau của truy vấn; các đánh giá nội bộ của họ cho thấy phương pháp tiếp cận đa tác nhân vượt trội hơn 90% tác nhân đơn lẻ Claude Opus 4 trong các nhiệm vụ nghiên cứu, chỉ riêng việc sử dụng mã thông báo đã giải thích 80% phương sai hiệu suất. Điều này cho thấy rằng việc phân tách tìm kiếm thành các tác nhân phụ chuyên biệt là một hướng kiến trúc đầy hứa hẹn, mặc dù chi phí liên quan đến việc chạy các mô hình biên giới như các tác nhân phụ vẫn là một rào cản thực tế.
Thách thức thực tế quan trọng đối với bất kỳ tác nhân tìm kiếm nhiều lượt nào là quản lý bối cảnh tích lũy qua các bước truy xuất liên tiếp. Khi tác nhân thu thập tài liệu, cửa sổ ngữ cảnh của nó sẽ lấp đầy những tài liệu có thể tiếp tuyến hoặc dư thừa, làm tăng chi phí tính toán và làm giảm hiệu suất xuôi dòng - một hiện tượng được gọi là xuống ngữ cảnh. Trong MemGPT, tác nhân sử dụng các công cụ để phân trang thông tin giữa ngữ cảnh chính nhanh và bộ nhớ ngoài chậm hơn, đọc lại dữ liệu khi cần. Các tác nhân được cảnh báo về áp lực bộ nhớ và sau đó được phép đọc và ghi từ bộ nhớ ngoài. SWE-Pruner sử dụng cách tiếp cận có mục tiêu hơn, huấn luyện bộ lọc thần kinh 0,6B nhẹ để thực hiện lựa chọn dòng nhận biết nhiệm vụ từ ngữ cảnh mã nguồn. Các phương pháp như ReSum tóm tắt định kỳ bối cảnh tích lũy, tránh nhu cầu về bộ nhớ ngoài nhưng có nguy cơ loại bỏ bằng chứng chi tiết có thể chứng minh có liên quan trong các lần truy xuất sau này. Mô hình ngôn ngữ đệ quy (RLM) giải quyết vấn đề từ một góc độ khác hoàn toàn, xử lý lời nhắc không phải là đầu vào cố định mà là một biến trong môi trường REPL bên ngoài mà mô hình có thể kiểm tra, phân tách và truy vấn đệ quy theo chương trình. Opus-4.5 của Anthropic tận dụng nhận thức về bối cảnh - giúp các đại lý nhận thức được việc sử dụng mã thông báo của riêng họ cũng như xóa các kết quả lệnh gọi công cụ cũ dựa trên thời gian gần đây.
Các cách tiếp cận này chứng tỏ sự cần thiết và tầm quan trọng của việc quản lý bối cảnh tích cực, nhưng không giải quyết được vấn đề cụ thể mà tác nhân truy xuất nhiều lượt gặp phải: giữ lại hoặc loại bỏ có chọn lọc các tài liệu được truy xuất dựa trên các phán đoán liên quan đang phát triển, mà không nén bằng chứng thành các bản tóm tắt bị mất, dựa vào cơ sở hạ tầng bộ nhớ ngoài hoặc yêu cầu giàn giáo thời gian suy luận có thể bù đắp cho mức tăng hiệu quả của một hệ thống nhỏ hơn. mô hình.
Một hướng đầy hứa hẹn để giảm chi phí và độ trễ là thay thế các mô hình tiên phong bằng các mô hình thay thế nhỏ hơn, phù hợp với mục đích hơn. WebExplorer đào tạo tác nhân web 8B thông qua tinh chỉnh có giám sát, sau đó là RL tìm kiếm trên 16 lượt trở lên, vượt trội đáng kể so với các mô hình lớn hơn trên DuyệtComp. SWE-grep của Cognition huấn luyện các mô hình nhỏ với RL để thực hiện tìm kiếm mã tác nhân song song ở mức độ cao, đưa ra tối đa tám lệnh gọi công cụ song song mỗi lượt chỉ trong bốn lượt và khớp với các mô hình biên giới ở mức độ trễ thấp hơn. Search-R1 chứng minh rằng chỉ riêng RL có thể dạy mô hình ngôn ngữ thực hiện tìm kiếm nhiều lượt mà không cần khởi động tinh chỉnh có giám sát, trong khi s3 cho thấy rằng RL có phần thưởng phản ánh chất lượng tìm kiếm mang lại kết quả tìm kiếm mạnh mẽ hơn đại lý ngay cả trong chế độ dữ liệu thấp. Tuy nhiên, không có phương pháp tiếp cận mô hình nhỏ nào kết hợp quản lý ngữ cảnh vào chính chính sách tìm kiếm và các phương pháp quản lý ngữ cảnh hiện có hoạt động trong quá trình tìm kiếm nhiều lượt dựa vào tính năng nén có mất dữ liệu thay vì lưu giữ ở cấp độ tài liệu có chọn lọc.
Việc đào tạo các mô hình chuyên biệt như vậy đòi hỏi khối lượng lớn dữ liệu nhiệm vụ chất lượng cao, điều này thúc đẩy nhu cầu tạo dữ liệu tổng hợp cho tìm kiếm tác nhân. BrowseComp đã trở thành một tiêu chuẩn được sử dụng rộng rãi để đánh giá những khả năng như vậy, bao gồm các nhiệm vụ nghiên cứu sâu đầy thử thách nhưng có thể kiểm chứng dễ dàng. Tuy nhiên, sự phụ thuộc vào nội dung web động khiến việc đánh giá không thể lặp lại theo thời gian. BrowseComp-Plus giải quyết vấn đề này bằng cách ghép từng tác vụ với một kho tài liệu tĩnh gồm các tài liệu tích cực và yếu tố phân tâm, cho phép đánh giá có thể lặp lại, mặc dù quy trình quản lý thủ công hạn chế khả năng mở rộng. Quy trình “khám phá và phát triển” của WebExplorer cung cấp một giải pháp thay thế dễ mở rộng hơn: nhân viên thám hiểm thu thập thông tin thực tế về một chủ đề ban đầu cho đến khi có thể xây dựng một câu hỏi đầy thách thức, sau đó một bước tiến hóa sẽ làm xáo trộn truy vấn để tăng độ khó. Mặc dù hoàn toàn tự động nhưng quy trình này thiếu cơ chế xác minh để đảm bảo tính chính xác của các cặp tài liệu được tạo. Điều này rất quan trọng đối với dữ liệu huấn luyện, trong đó nhiễu nhãn trực tiếp làm giảm chất lượng mô hình. Ngoài ra, các phương pháp tạo tác vụ tổng hợp hiện có hầu hết đã được áp dụng trong miền tìm kiếm trên web, vẫn còn bỏ ngỏ liệu chúng có thể mở rộng trên phạm vi miền đa dạng nơi triển khai tìm kiếm tác nhân hay không.
Tạo tác vụ tổng hợp#
Tìm kiếm toàn diện được xây dựng trên hai khả năng cốt lõi:
- Lập kế hoạch - tìm kiếm hiệu quả đòi hỏi phải phân tách mục tiêu cấp cao thành một chuỗi truy vấn, thường bắt đầu mở rộng và thu hẹp dựa trên các kết quả trung gian.
- Đánh giá - về cốt lõi, tìm kiếm là xác định nội dung quan trọng cho mục tiêu và thông tin đã thấy cho đến nay. Việc tìm kiếm chính xác đòi hỏi phải xác định được thông tin liên quan trong số những thông tin nhiễu, phân biệt chúng với những thông tin gây phân tâm.
Nhiệm vụ do chúng tôi tạo ra nhắm vào hai khả năng cơ bản này. Chúng tôi thừa nhận rằng chúng không toàn diện và không thể hiện các nhiệm vụ tìm kiếm từ đầu đến cuối thực tế; Cách tiếp cận đơn giản ở đây là có chủ ý, cho phép chúng tôi tách biệt và rèn luyện những kỹ năng cốt lõi này.
Chúng tôi tạo câu hỏi theo kiểu BrowseComp, một điểm chuẩn của OpenAI tập trung vào các nhiệm vụ nghiên cứu sâu được thiết kế khó giải nhưng dễ xác minh.
Một cuốn sách từng là ứng cử viên cho một giải thưởng, được sáng tác lần đầu vào những năm 2000 (chính là giải thưởng), đã được dịch sang hơn 25 thứ tiếng. Vào những năm 2010, năm cuốn sách này được xuất bản, một cuốn sách khác, được phát hành vào năm trước, đã giành được giải thưởng nêu trên mà cuốn sách đầu tiên sau đó đã tranh giành. Tác giả của cuốn sách đoạt giải này sinh ra ở cùng thành phố nơi tác giả của cuốn sách được đề cập ban đầu lớn lên. Dựa trên mối liên hệ này, tác giả cuốn sách đầu tiên ra đời ở thành phố nào?
Những câu hỏi này yêu cầu lập kế hoạch bằng cách phân tách: việc tìm kiếm tất cả các tiêu chí cùng một lúc khó có thể thành công, do đó, một tác nhân hiệu quả phải chia vấn đề thành các truy vấn phụ, tìm kiếm rộng rãi các tiêu chí riêng lẻ và tinh chỉnh dưới dạng thông tin xuất hiện.
Quá trình này cũng đòi hỏi sự đánh giá mức độ liên quan cẩn thận. Mỗi truy vấn sẽ hiển thị nhiều kết quả và ngữ cảnh sẽ được tích lũy nhanh chóng. Một số tài liệu có thể có vẻ phù hợp nhưng không đáp ứng được tất cả các tiêu chí, chẳng hạn như một cuốn sách được dịch sang hơn 25 ngôn ngữ nhưng lại tranh giải thưởng vào những năm 1980 thay vì những năm 2010. Việc phân biệt những yếu tố gây phân tâm này với các tài liệu thực sự có liên quan là điều cần thiết.
Quy trình tạo nhiệm vụ chuẩn của chúng tôi tạo ra các câu hỏi đa ràng buộc trên bốn lĩnh vực: web, tài chính, pháp lý và email. Mặc dù quy trình tạo khác nhau tùy theo miền nhưng tất cả đều tuân theo một cấu trúc chung.
- Thu thập tài liệu hỗ trợ — chứa các dữ kiện độc đáo, sử dụng các công cụ tìm kiếm phù hợp với miền.
- Tạo ra manh mối (tham chiếu đến dữ kiện bị xáo trộn) — một câu hỏi kết hợp các manh mối này và câu trả lời tương ứng.
- Xác minh rằng nhiệm vụ là hợp lệ — các tài liệu hỗ trợ có thực sự hỗ trợ các manh mối và dẫn đến câu trả lời cuối cùng không?
- Tùy chọn, thu thập các yếu tố phân tâm — tài liệu đáp ứng một số tiêu chí nhưng trỏ đến một câu trả lời khác.
- Tùy chọn, xâu chuỗi đệ quy — kết nối câu trả lời của một nhiệm vụ hiện có với một nhiệm vụ mới bằng một câu trả lời cuối cùng mới, kiểm soát số bước nhảy cần thiết.
Đường dẫn tạo nhiệm vụví dụ về miền web
Đưa ra một chủ đề hạt giống, một nhân viên sẽ khám phá trang web và thu thập các tài liệu chứa các dữ kiện độc đáo, có thể kiểm chứng.
SeedGiáo đường Do Thái ở Brussels(tiêu đề Wikipedia ngẫu nhiên)
Grande Synagogue de Bruxellesjguideeurope.org
“
Brussels, thủ đô của Châu Âu tổ chức
”
“
Giáo đường Do Thái theo phong cách La Mã-Byzantine
”
“
Khánh thành vào ngày 20 tháng 9 năm 1878
”
Cộng đồng Do Thái Bỉwikipedia.org
“
Sự độc lập của Bỉ trong 1830
”
“
1831 Hiến pháp đảm bảo quyền tự do tín ngưỡng
”
SS Vaderland (1874) wikipedia.org
“
Tàu viễn dương của Bỉ hạ thủy từ một xưởng đóng tàu ở Anh
”
“
Ra mắt vào đêm trước ngày đông chí năm 1878
”
1 / 5
Hướng dẫn ở trên sử dụng tên miền web làm ví dụ cụ thể. Đưa ra một chủ đề gốc được lấy mẫu từ các tiêu đề Wikipedia ngẫu nhiên, chúng tôi cung cấp cho nhân viên các công cụ tìm kiếm và tìm kiếm trên web để khám phá và thu thập tài liệu chứa các thông tin thực tế độc đáo. Sử dụng các tài liệu được thu thập, đặc vụ tạo ra manh mối, câu hỏi và câu trả lời trong một vòng lặp duy nhất. Chúng tôi nhận thấy rằng với một vài ví dụ ngắn gọn về các truy vấn và hướng dẫn lý tưởng để làm rối mã nguồn, một lượt tác nhân duy nhất sẽ tạo ra các nhiệm vụ đầy thử thách mà không có bước tiến hóa riêng biệt được sử dụng trong WebExplorer. Chi tiết đầy đủ cho tất cả bốn miền, cùng với các chỉ số liên kết đánh giá LLM, được cung cấp trong phụ lục.
Xác minh nhiệm vụ và Căn chỉnh đánh giá LLM#
Mối quan tâm chính trong việc tạo dữ liệu tổng hợp là chất lượng nhãn: nếu tài liệu hỗ trợ không thực sự hỗ trợ các manh mối hoặc yếu tố gây phân tâm vô tình chứa câu trả lời thì tín hiệu đào tạo sẽ giảm. Việc chỉ yêu cầu một mô hình chấm điểm một tài liệu là có liên quan có thể không đáng tin cậy và việc ghi nhãn của con người sẽ rất tốn kém vì nó đòi hỏi phải đọc kỹ từng tài liệu. Chúng tôi vượt qua những thách thức này bằng quy trình xác minh dựa trên trích xuất.
Đối với mỗi tài liệu hỗ trợ, chúng tôi nhắc LLM trích xuất hai bộ dấu ngoặc kép: trích dẫn tài liệu (nguyên văn kéo dài từ văn bản nguồn) và trích dẫn đầu mối (các khoảng tương ứng từ manh mối được tạo). Chúng tôi bình thường hóa (tức là viết thường, loại bỏ khoảng trắng thừa, v.v.) cả hai và xác nhận rằng các trích dẫn tài liệu thực sự xuất hiện trong tài liệu nguồn, đưa ra đánh giá về mức độ liên quan dựa trên bằng chứng văn bản thay vì quan điểm mẫu. Nếu bất kỳ tài liệu hỗ trợ nào thiếu dấu ngoặc kép phù hợp hoặc nếu không có tài liệu nào chứa câu trả lời, chúng tôi sẽ lọc ra nhiệm vụ.
Điều này làm giảm khả năng xác minh của con người để kiểm tra xem mỗi trích dẫn tài liệu có hỗ trợ trích dẫn đầu mối được ghép nối của nó hay không, thay vì đọc toàn bộ tài liệu. Đối với các yếu tố gây phân tâm, chúng tôi thực hiện kiểm tra bổ sung: đưa ra một tài liệu và câu trả lời, chúng tôi trích xuất bất kỳ sự xuất hiện nào của câu trả lời dưới bất kỳ hình thức nào, lọc ra các yếu tố gây phân tâm vô tình chứa nó. Trên tất cả các miền, chúng tôi đạt được độ chính xác căn chỉnh >80%, nghĩa là người gắn nhãn và giám khảo LLM đồng ý về các đánh giá trong hơn 80% thời gian.
Định nghĩa và đánh giá nhiệm vụ#
Cụ thể, mỗi nhiệm vụ bao gồm một tập hợp manh mối, một câu hỏi, một câu trả lời và một tập hợp tài liệu hỗ trợ.
Trong nhiệm vụ này, nhân viên hỗ trợ phải trả về một bộ tài liệu mà họ xác định là phù hợp nhất. Bằng cách sử dụng bộ tài liệu có liên quan đến mục tiêu, chúng tôi đánh giá thành công chủ yếu bằng 4 chỉ số cấp độ đầu ra và một chỉ số cấp độ quỹ đạo.
Chỉ số cấp độ đầu ra
- Đã tìm thấy câu trả lời cuối cùng: một tài liệu (hoặc các tài liệu nếu cần) chứa câu trả lời cuối cùng đã xuất hiện trong tập hợp đầu ra của tổng đài viên.
- Nhớ lại: tỷ lệ tài liệu tích cực mà nhân viên xuất ra trong tổng số bộ tài liệu tích cực.
- Độ chính xác: tỷ lệ tài liệu được trả lại thực sự có liên quan.
- F1: phương tiện hài hòa giữa việc thu hồi và độ chính xác, cung cấp thước đo chi tiết hơn cân bằng cả hai.
Số liệu cấp quỹ đạo
- Thu hồi quỹ đạo: tỷ lệ tài liệu mục tiêu gặp phải tại bất kỳ thời điểm nào trong quá trình tìm kiếm của tác nhân, bất kể chúng có xuất hiện trong kết quả cuối cùng hay không.
Mong muốn có khả năng thu hồi cao, nhưng tác nhân tìm kiếm có thể tối đa hóa nó một cách tầm thường bằng cách xuất ra mọi tài liệu mà nó gặp. Độ chính xác đo lường điều ngược lại: tỷ lệ tài liệu được trả lại có liên quan. Có thể đạt được độ chính xác hoàn hảo bằng cách trả lại một tài liệu chính xác duy nhất, nhưng phải trả giá bằng việc thiếu mọi thứ khác. Đánh giá điểm F1 mang lại sự cân bằng.
Hai chỉ số này đánh giá chất lượng đầu ra cuối cùng của tác nhân nhưng không tiết lộ nguồn gốc của lỗi. Để tách chất lượng tìm kiếm khỏi chất lượng lựa chọn cuối cùng, chúng tôi cũng đo lường khả năng thu hồi quỹ đạo. So sánh việc thu hồi quỹ đạo với thu hồi đầu ra cho biết liệu tác nhân có gặp phải các tài liệu liên quan trong quá trình tìm kiếm nhưng không đưa chúng vào đầu ra cuối cùng hay liệu nó hoàn toàn bỏ sót chúng hay không.
Câu trả lời cuối cùng được tìm thấy là điểm nhị phân được xác định bằng việc liệu câu trả lời cuối cùng có tồn tại trong tập hợp tài liệu đầu ra hay không. Bộ tài liệu chứa đáp án cuối cùng là tập con của tổng bộ tài liệu hỗ trợ. Như vậy, có thể đại lý tìm được câu trả lời cuối cùng mà không tìm thấy tất cả tài liệu chứng minh. Chúng tôi coi việc tìm ra câu trả lời cuối cùng là một kết luận thành công cho quá trình triển khai vì nhân viên hỗ trợ có thể tìm ra câu trả lời cuối cùng mà không cần phải xác minh toàn bộ manh mối. Việc tiếp tục tìm kiếm có thể mang lại kết quả có giá trị, nhưng do đã tìm thấy câu trả lời cuối cùng nên việc tiếp tục tìm kiếm chỉ nhằm mục đích xác minh thêm. Mặc dù tính toàn diện rất hữu ích trong một số trường hợp nhất định nhưng nhiều tình huống lại không yêu cầu điều đó. Do đó, chúng tôi đã cố tình không tối ưu hóa hành vi này.
Một phương pháp đánh giá thay thế sẽ là cung cấp các tài liệu được truy xuất vào một mô hình suy luận và kiểm tra xem liệu mô hình đó có tạo ra câu trả lời chính xác từ đầu đến cuối hay không. Chúng tôi cố tình tránh điều này vì hai lý do. Đầu tiên, nó nhầm lẫn chất lượng tìm kiếm với chất lượng lý luận: nếu mô hình xuôi dòng không trả lời chính xác thì sẽ không rõ liệu tác nhân tìm kiếm đã thu thập đủ bằng chứng hay mô hình lý luận không sử dụng những gì được cung cấp. Câu trả lời cuối cùng được tìm thấy tách biệt sự đóng góp của tác nhân tìm kiếm — nếu một tài liệu chứa câu trả lời xuất hiện trong tập hợp đầu ra thì việc truy xuất đã thành công bất kể hiệu suất của mô hình xuôi dòng. Sự tách biệt này được chứng minh rõ ràng hơn bằng các điểm chuẩn như DuyệtComp-Plus, trong đó hiệu suất oracle cho tất cả các tài liệu hỗ trợ ở mức cao, cho thấy nút thắt về độ chính xác đối với kiểu nhiệm vụ này là tìm kiếm chứ không phải lý luận. Thứ hai, việc loại bỏ mô hình lý luận khỏi vòng lặp là điều thiết thực: trong quá trình đào tạo RL, mỗi lần triển khai sẽ yêu cầu một lệnh gọi LLM bổ sung cho mỗi tập, làm tăng thêm chi phí và độ trễ tùy theo số lượng quỹ đạo mỗi bước.
Agent Harness#
Context-1 hoạt động như một tác nhân phụ tìm kiếm tập trung vào việc truy xuất các tài liệu hỗ trợ cho mô hình lý luận biên giới xuôi tuyến. Tác nhân tương tác với cơ sở hạ tầng tìm kiếm cơ bản thông qua lệnh gọi công cụ có cấu trúc trong vòng lặp observe-reason-act, trong đó mỗi chu trình bao gồm mô hình tạo ra lệnh gọi công cụ (hoặc câu trả lời cuối cùng), khai thác thực hiện lệnh gọi dựa trên cơ sở dữ liệu và kết quả được thêm vào quỹ đạo dưới dạng quan sát tiếp theo.
Công cụ
Nhân viên hỗ trợ có quyền truy cập vào bốn công cụ
| Công cụ | Mô tả |
|---|---|
| search_corpus(query) | Hybrid BM25 + tìm kiếm vectơ dày đặc thông qua phản ứng tổng hợp thứ hạng đối ứng (RRF) trên bộ sưu tập Chroma. 50 ứng cử viên được lấy ra và sau đó được xếp hạng lại. Các kết quả hàng đầu được trả về trong phạm vi ngân sách mã thông báo. |
| grep_corpus(pattern) | Tìm kiếm Regex trên kho văn bản. Trả về tối đa 5 đoạn phù hợp. |
| read_document(doc_id) | Đọc toàn bộ nội dung của tài liệu theo ID. Các đoạn được sắp xếp lại và cắt bớt để phù hợp với ngân sách mã thông báo còn lại |
| prune_chunks(chunk_ids) | Xóa các đoạn được chỉ định khỏi ngữ cảnh hội thoại |
Công cụ search_corpus truy vấn cả vectơ thưa thớt và các phần nhúng dày đặc trong mỗi bộ sưu tập Chroma. Một tìm kiếm sẽ đưa ra cả hai truy vấn song song và kết quả được hợp nhất thông qua phản ứng tổng hợp xếp hạng đối ứng (RRF) để kết hợp các điểm mạnh của kết hợp từ khóa và ngữ nghĩa. 50 kết quả hợp nhất hàng đầu được một công cụ xếp hạng lại chấm điểm. Công cụ này sẽ chọn ra những kết quả hàng đầu trong ngân sách mã thông báo cho mỗi cuộc gọi.
Loại bỏ trùng lặp
Một dạng lỗi phổ biến trong tìm kiếm nhiều lượt là truy xuất lại cùng một tài liệu. Điều này là do các đại lý thường đưa ra các từ khóa giống nhau trong quỹ đạo tìm kiếm của họ. Để chống lại điều này, khai thác tác nhân của chúng tôi theo dõi mọi ID đoạn gặp phải trong tất cả các lệnh gọi tìm kiếm trước đó và chuyển chúng dưới dạng bộ lọc loại trừ trong các tìm kiếm tiếp theo. Điều này buộc mỗi tìm kiếm phải hiển thị thông tin mới và cải thiện hiệu quả khám phá.
Quản lý ngân sách mã thông báo Để giảm thiểu tác động của sự thay đổi ngữ cảnh, chúng tôi đã ràng buộc cửa sổ ngữ cảnh với ngân sách mã thông báo cố định . Một lệnh gọi tìm kiếm có thể trả về tối đa mã thông báo của nội dung đoạn. Sau khi tìm kiếm , cửa sổ ngữ cảnh sẽ hết. Điều này thể hiện một sự cân bằng: tác nhân phải tích lũy bằng chứng để trả lời các truy vấn phức tạp, nhưng nó không thể giữ được mọi thứ. Khai thác của Context-1 tận dụng một số cơ chế để giúp tác nhân nhận biết và có thể chủ động quản lý bối cảnh của mình.
- Khả năng hiển thị liên tục — Sau mỗi lượt, mức sử dụng mã thông báo hiện tại sẽ được thêm vào quan sát (ví dụ:
[Mức sử dụng mã thông báo: 14.203/32.768]), đảm bảo mô hình luôn biết lượng dung lượng còn lại. - Ngưỡng mềm — Khi mức sử dụng vượt quá mã thông báo, bộ khai thác sẽ đưa ra một thông báo phản hồi gợi ý mô hình bắt đầu cắt bớt các phần để giải phóng không gian ngữ cảnh hoặc đưa ra câu trả lời cuối cùng sau khi đánh giá trạng thái của nó. Kết quả tìm kiếm và đọc được cắt bớt để phù hợp với ngân sách còn lại và khoản dự trữ được duy trì cho phản hồi tiếp theo của mô hình. Thông báo này chỉ hiển thị trong quá trình triển khai đào tạo.
- Cắt cứng — Ngoài giới hạn có thể định cấu hình ở giữa các mã thông báo và , tất cả lệnh gọi công cụ ngoại trừ prune_chunk đều bị từ chối hoàn toàn, trả về thông báo lỗi hướng dẫn mô hình cắt tỉa hoặc kết thúc.
Cắt tỉa
Khi mô hình gọi prune_chunks, bộ khai thác sẽ loại bỏ các khối được chỉ định khỏi chế độ xem của mô hình nhưng vẫn giữ nguyên toàn bộ quỹ đạo chưa được cắt xén để tính toán phần thưởng. Điều này rất quan trọng đối với phần thưởng được mô tả bên dưới, phần thưởng này ghi nhận tác nhân đối với các tài liệu mà nó gặp phải trong quá trình tìm kiếm ngay cả khi chúng đã bị cắt bớt sau đó.
Khi ngân sách mã thông báo lấp đầy, không gian hành động của tác nhân sẽ thu hẹp: lượt đầu cho phép tìm kiếm không hạn chế, ngưỡng mềm tạo ra áp lực cắt tỉa và giới hạn cứng sẽ hạn chế tác nhân cắt tỉa hoặc kết luận. Điều này tạo ra áp lực phải chọn lọc: vượt qua ngưỡng mềm, việc truy xuất bằng chứng mới đòi hỏi phải giải phóng không gian bằng cách loại bỏ các kết quả hiện có.
CONTEXT CỬA SỔ
[< khoảng>██████████████████ ███████████████████████ ███████████████████████ ███████████████████████ █████████████████████████████████ ░░░░░░░░░░░░░░░░░░░░ ░░░░░░░░░░░░░░░░░░░░░ ░░░░░░░░░░░░░░░░░░░░░ ░░░░░░░░░░░░░░░░░░░░░ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░]11,6k / 32,8k toks
↑ giới hạn mềm
bước 1/8
>tìm kiếm("nền chủ đề A")+3 tài liệu11,6k
có liên quan
answer
nhiễu
Đào tạo mô hình#
Sự trừu tượng hóa tác nhân
Việc khai thác tác nhân được triển khai như một cỗ máy trạng thái bất khả tri của nhà cung cấp với ba thao tác: quan sát, suy luận và hành động. Tác nhân duy trì một quỹ đạo, một chuỗi quan sát và hành động có trật tự, phát triển trong suốt một tập phim. Ở mỗi bước, quan sát sẽ thêm một quan sát mới (kết quả công cụ hoặc dấu nhắc ban đầu) vào quỹ đạo. Suy luận chuyển quỹ đạo thông qua mô hình suy luận có thể cắm được và trả về hành động tiếp theo (một hoặc nhiều lệnh gọi công cụ hoặc phản hồi văn bản cuối cùng). hành động ghi lại hành động trong quỹ đạo, thực hiện bất kỳ lệnh gọi công cụ nào và trả về kết quả quan sát. Vòng lặp kết thúc khi mô hình tạo ra phản hồi chỉ bằng văn bản mà không có lệnh gọi công cụ nào hoặc khi quỹ đạo vượt quá mức tối đa length.
tác nhân.đặt lại()
tác nhân.quan sát(initial_observation)
trong khi không đại lý. is_done:
hành động = tác nhân.suy luận()
quan sát = đại lý.hành động(hành động)
nếu quan sát là không Không:
đại lý.quan sát(quan sát)
quỹ đạo = tác nhân.quỹ đạo
Phần phụ trợ suy luận là một giao diện trừu tượng: với quỹ đạo và bộ công cụ hiện tại, nó trả về một hoặc hành động hoặc phản hồi cuối cùng. Chúng tôi triển khai giao diện này cho nhiều mô hình và định dạng phản hồi, cho phép tái sử dụng cùng một vòng lặp tác nhân, công cụ và logic quản lý bối cảnh trong quá trình tạo dữ liệu SFT, đào tạo và đánh giá RL mà không cần sửa đổi. Hệ thống phân cấp lớp tác nhân hỗ trợ thành phần hành vi, cho phép thử nghiệm nhanh chóng với các chiến lược tìm kiếm khác nhau. Việc đầu tư vào mức độ trừu tượng trả trước này sẽ nhanh chóng mang lại kết quả: các chiến lược tìm kiếm mới, phần phụ trợ mô hình hoặc cấu hình công cụ có thể được lặp lại và thử nghiệm nhanh chóng.
SFT#
Trước khi học tăng cường, chúng tôi thực hiện quá trình khởi động tinh chỉnh có giám sát để tạo ra các lệnh gọi công cụ được định dạng phù hợp, tuân theo định dạng lời nhắc tác nhân phụ truy xuất và tìm hiểu các ưu tiên hành vi mạnh mẽ như gọi công cụ song song và phân tách truy vấn. Chúng tôi tạo ra các quỹ đạo SFT bằng cách chạy vòng lặp tác nhân đầy đủ với các mô hình lớn như Kimi K2.5 làm phụ trợ suy luận. Mỗi lần triển khai tạo ra một quỹ đạo hoàn chỉnh: lời nhắc ban đầu, lý do của mô hình và lệnh gọi công cụ ở mỗi lượt, kết quả công cụ và bộ tài liệu cuối cùng.
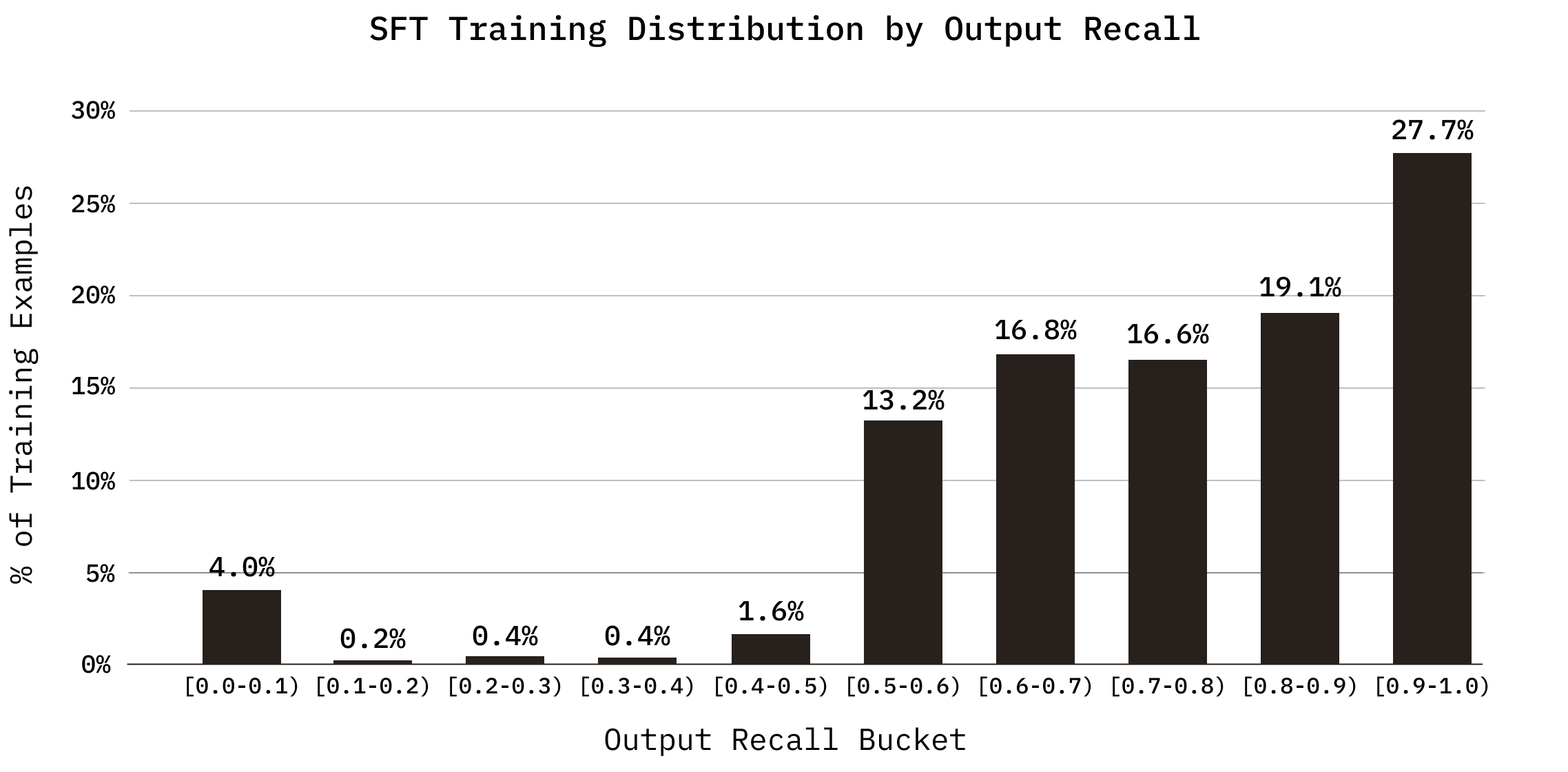
Các quỹ đạo này được lọc trước khi huấn luyện dựa trên hai số liệu thu hồi: thu hồi quỹ đạo (tỷ lệ các khối mục tiêu gặp phải tại bất kỳ thời điểm nào trong quá trình tìm kiếm) và thu hồi đầu ra (tỷ lệ các khối mục tiêu có trong bộ tài liệu cuối cùng). Chúng tôi đưa cả các lần triển khai thành công và không thành công vào tập dữ liệu SFT. Điều này được thúc đẩy bởi Shape of Thought, chứng minh rằng việc đào tạo về dấu vết tổng hợp từ các mô hình có năng lực hơn sẽ cải thiện hiệu suất ngay cả khi tất cả dấu vết đều dẫn đến câu trả lời cuối cùng không chính xác, vì đặc tính phân phối của dấu vết quan trọng hơn tính chính xác của từng bước riêng lẻ. Trong cài đặt của chúng tôi, các quỹ đạo có khả năng thu hồi thấp vẫn chứa các lệnh gọi công cụ được định dạng hợp lý, các phân tách truy vấn và các quyết định cắt bớt cung cấp các tín hiệu hành vi hữu ích.
Việc triển khai được lọc theo chất lượng thu hồi. Các quỹ đạo có khả năng thu hồi cao (thu hồi quỹ đạo trên 50% và thu hồi đầu ra 40%) được giữ lại đầy đủ. Những người có khả năng thu hồi thấp hơn được đưa vào với tỷ lệ giảm dần. Một phần nhỏ (tối đa 5%) quỹ đạo không thu hồi được đưa vào làm ví dụ tiêu cực, được loại bỏ trùng lặp bằng truy vấn, để đưa mô hình vào các chế độ lỗi, triển khai kéo dài và có khả năng bỏ phiếu trắng hợp lệ mà không để chúng chi phối tín hiệu đào tạo. Các quỹ đạo mà mô hình đã khám phá tốt nhưng kết luận kém (trong đó việc thu hồi quỹ đạo vượt quá đáng kể việc thu hồi đầu ra) bị loại trừ hoàn toàn, vì việc đào tạo về chúng sẽ củng cố sự mất kết nối giữa khám phá và lựa chọn. Khi nhiều lần triển khai cho cùng một truy vấn đạt được mức thu hồi đầu ra cao, thì chỉ một lần triển khai được giữ lại để ngăn chặn việc trình bày quá mức các truy vấn dễ dàng. Các kết quả đầu ra không đúng định dạng sẽ bị loại bỏ.
RL#
Sau SFT, chúng tôi tận dụng phương pháp học tăng cường bằng các phần thưởng có thể xác minh được (RLVR). Mô hình cơ sở là gpt-oss-20b, được điều chỉnh thông qua LoRA. Chúng tôi đã chọn gpt-oss-20b vì khả năng suy luận nhanh theo lượng tử hóa MXFP4, hiệu suất truy xuất oracle mạnh mẽ dựa trên các điểm chuẩn chung và khả năng hỗ trợ hệ sinh thái mạnh mẽ.
Đào tạo
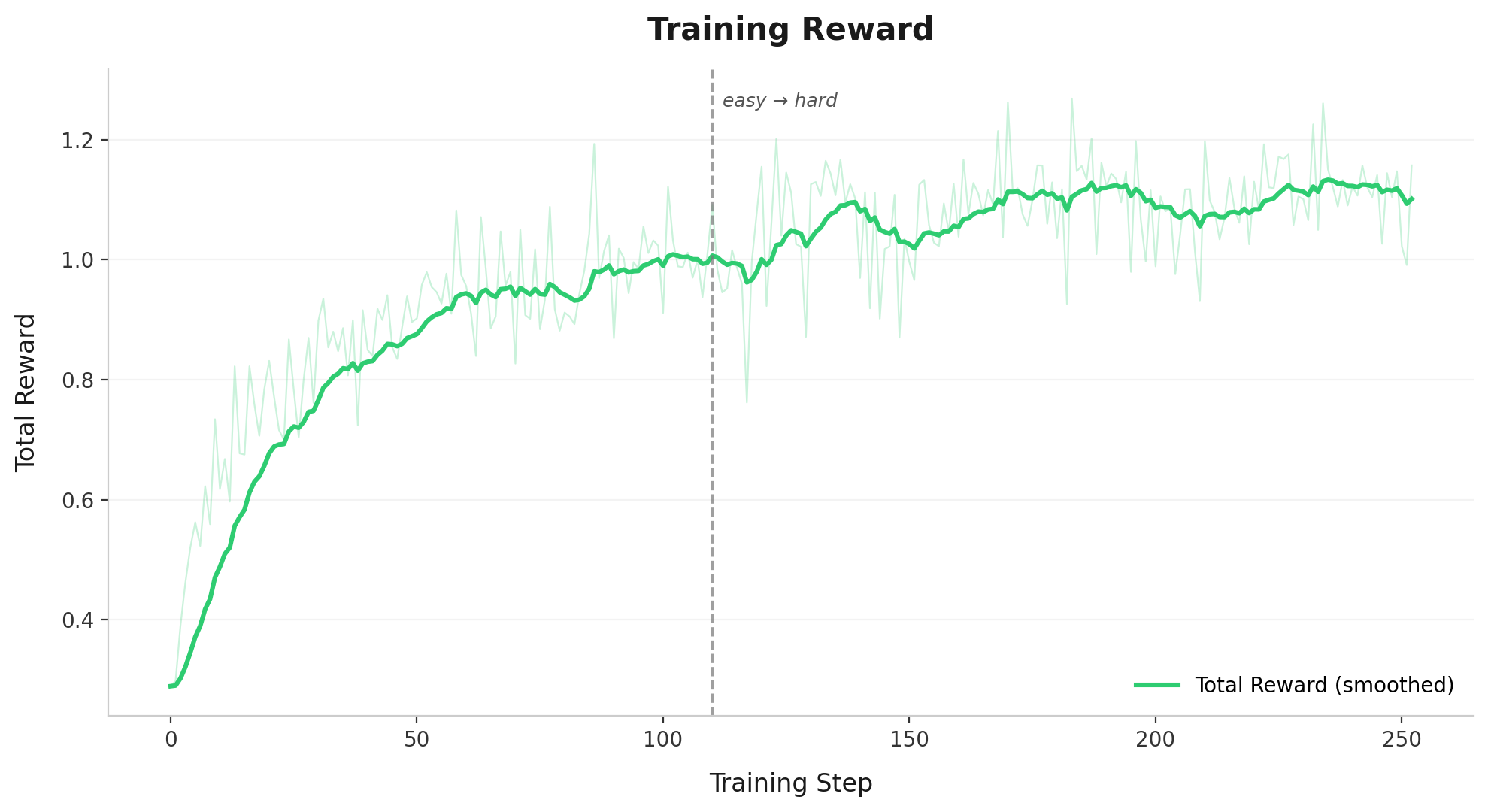
Chúng tôi đào tạo Context-1 hoàn toàn theo chính sách bằng cách sử dụng CISPO, một biến thể của GRPO. Ở mỗi bước đào tạo, 128 truy vấn được rút ra từ một hỗn hợp được xáo trộn, xen kẽ từ các phần đào tạo chỉ dành cho các truy vấn pháp lý, bằng sáng chế và truy vấn được tạo trên web của chúng tôi. Đối với mỗi truy vấn, 8 phiên bản môi trường độc lập được tạo để triển khai, mang lại 1.024 quỹ đạo tác nhân mỗi bước.
Khi kết thúc tập, mỗi môi trường sẽ tính toán phần thưởng của mình. Các nhóm trong đó tất cả 8 lần triển khai đều nhận được phần thưởng giống nhau sẽ bị loại bỏ vì chúng không cung cấp tín hiệu gradient khi chuẩn hóa trong nhóm. Sau đó, tổn thất CISPO được tính toán trên các nhóm còn lại và 4 bước phụ của quá trình giảm độ dốc được áp dụng cho các tham số LoRA. Chúng tôi đào tạo tập dữ liệu của mình trong 5 kỷ nguyên, với tổng số ~300 bước có thể và quan sát sự hội tụ khoảng 230 bước như chi tiết trong hình bên dưới.
Mất chính sách
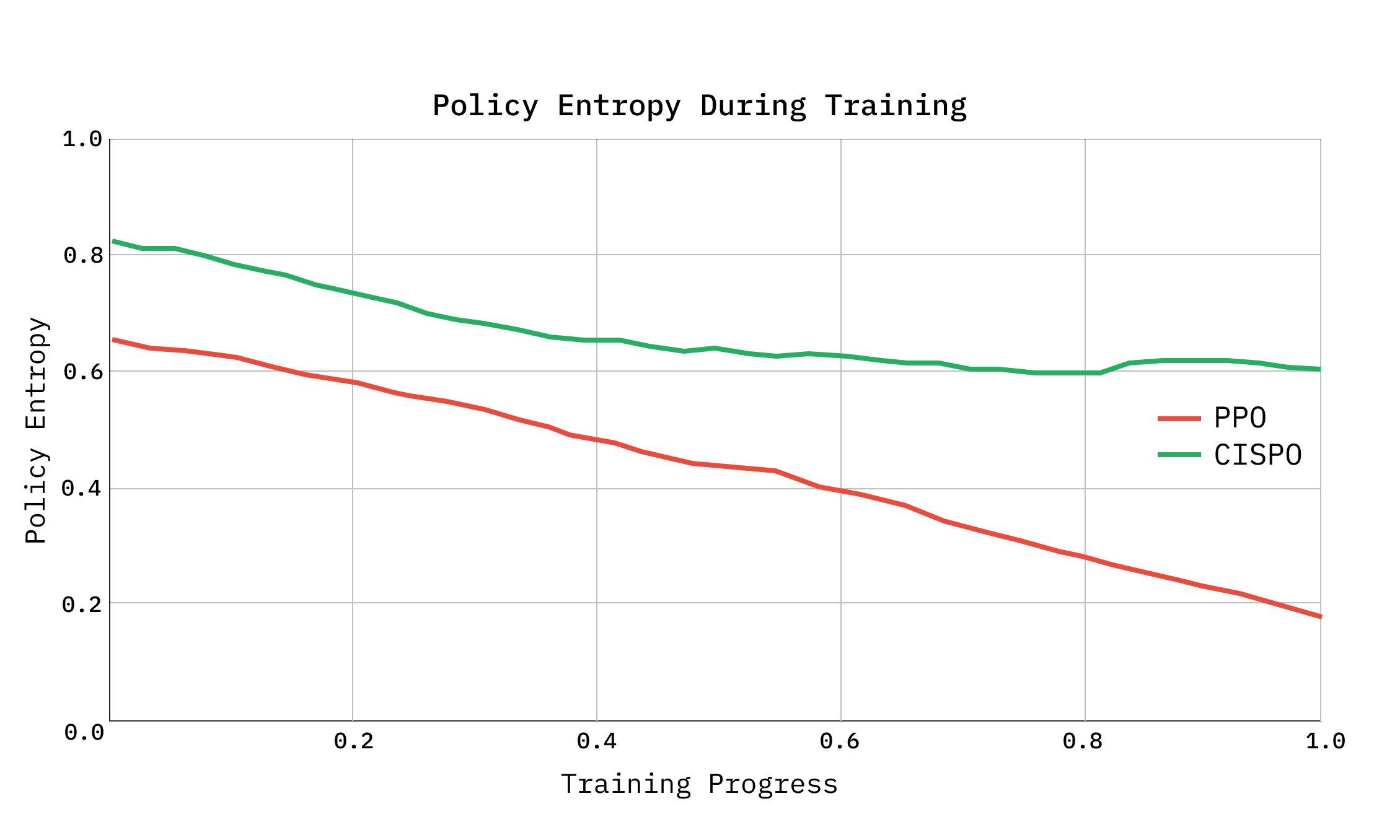
Chúng tôi sử dụng CISPO (Clipped Importance-Sampled Tối ưu hóa chính sách) theo đề xuất của ScaleRL , một biến thể của GRPO cắt bớt các trọng số lấy mẫu quan trọng thay vì mục tiêu thay thế.
Trong GRPO tiêu chuẩn, các mã thông báo có tỷ lệ quan trọng nằm ngoài phạm vi clip sẽ nhận được độ dốc bằng 0; Thay vào đó, CISPO tách các trọng số đã cắt bớt và sử dụng chúng làm hệ số chia tỷ lệ trên gradient xác suất nhật ký, đảm bảo tất cả các mã thông báo đều đóng góp cho việc học, bao gồm các mã thông báo hiếm nhưng quan trọng như quyết định cắt bớt và cải cách truy vấn. Các lợi thế được tính toán thông qua quá trình chuẩn hóa trong nhóm, trong đó 8 lần triển khai của mỗi truy vấn cạnh tranh nhau và chỉ phần thưởng tương đối của chúng mới xác định độ dốc.
Chúng tôi nhận thấy việc sử dụng CISPO là rất quan trọng để ngăn chặn sự sụp đổ entropy khi chúng tôi tăng số bước đào tạo. Ban đầu, chúng tôi đã thử nghiệm tổn thất không thiên vị được đề xuất trong Dr GRPO cũng như áp dụng mức giảm clip cao hơn từ DAPO. Phù hợp với những phát hiện trong ScalRL, chúng tôi nhận thấy CISPO là giải pháp mạnh mẽ nhất để chống lại sự sụp đổ entropy và dẫn đến hiệu suất mẫu cao nhất.
Thiết kế phần thưởng
Phần thưởng kết hợp tín hiệu kết quả, thành phần quy trình, phần thưởng nhị phân và hình phạt đối với suy biến hành vi.
Thành phần kết quả là một ghi điểm với khi khởi tạo, thu hồi trọng số gấp mười sáu lần so với độ chính xác. Sự thiên vị này phản ánh vai trò của Context-1 với tư cách là tác nhân phụ truy xuất cung cấp mô hình trả lời xuôi dòng: việc thiếu một tài liệu quan trọng thường tệ hơn việc đưa vào một tài liệu không liên quan vì mô hình xuôi dòng vẫn có thể lọc nhưng không thể khôi phục thông tin chưa bao giờ được truy xuất.
Đối với một số tập dữ liệu, việc đánh giá hoạt động ở mức độ chi tiết thực tế hơn là mức độ chi tiết của tài liệu; một thực tế được tính là đã tìm thấy nếu bất kỳ khối liên quan nào của nó xuất hiện trong tập hợp được truy xuất, vì tại thời điểm xây dựng tập dữ liệu, thực tế tương tự có thể được tìm thấy trong nhiều tài liệu. Điều này được trình bày chi tiết hơn trong phương pháp tạo tập dữ liệu của chúng tôi.
Thu hồi quỹ đạo của thành phần quy trình , cho phép tác nhân gặp phải các tài liệu có liên quan trong quá trình tìm kiếm bất kể chúng có xuất hiện ở kết quả cuối cùng hay không.
Nếu không có thuật ngữ này, tác nhân có thể hội tụ đến một chiến lược suy thoái là đưa ra một hoặc hai tìm kiếm rộng rãi và kết thúc sớm với bất kỳ nội dung nào được trả về. Tín hiệu thu hồi quỹ đạo đảm bảo rằng việc khám phá được khen thưởng ngay cả khi các tài liệu đã khám phá sau đó được cắt bớt, điều này đặc biệt quan trọng vì các quyết định cắt bớt không hoàn hảo, đặc biệt là ở giai đoạn đầu trong quá trình đào tạo.
Phần thưởng cho câu trả lời cuối cùng, là +1.0 nhị phân để truy xuất một đoạn chứa trực tiếp câu trả lời thay vì bằng chứng hỗ trợ. Nếu không có phần thưởng này, chỉ riêng việc đào tạo về có thể khuyến khích nhân viên truy xuất các tài liệu liên quan đến chủ đề mà không cần tìm ra câu trả lời.
Hai hình phạt bổ sung giải quyết các hành vi suy đồi. Hình phạt cắt tỉa lặp đi lặp lại, , là 0,1 cho mỗi lệnh gọi vượt quá được áp dụng cho các vệt cắt tỉa liên tiếp dài hơn 3 (giới hạn ở mức 0,5), không khuyến khích tác nhân cắt tỉa từng đoạn một trong nhiều lượt thay vì theo đợt. Hình phạt về số lượt, , tăng tuyến tính từ 0 ở 64 lượt lên 0,5 ở 128 lượt, không khuyến khích các quỹ đạo có tìm kiếm lợi nhuận giảm dần. Phần thưởng cuối cùng được đặt ở mức cho bất kỳ quỹ đạo nào hoàn thành không có lỗi và đạt giới hạn ở giá trị trước khi bị phạt, , đảm bảo rằng các quỹ đạo thành công luôn chiếm ưu thế so với các quỹ đạo thất bại, đồng thời ngăn không cho sàn tăng cao các phần thưởng bị phạt.
Chương trình giảng dạy
Chúng tôi cấu trúc hai chương trình giảng dạy trong suốt quá trình đào tạo.
Đầu tiên, một chương trình giảng dạy có độ khó trong các giai đoạn triển khai. Bộ dữ liệu tổng hợp của chúng tôi gắn nhãn cho từng mốc thời gian theo độ khó theo số bước nhảy cần thiết. Quá trình đào tạo của chúng tôi được chia thành hai giai đoạn với các cấp độ khó này như được minh họa trong Beyond Ten Turns. Trong giai đoạn đầu tiên, việc phân phối truy vấn nghiêng về các câu hỏi có độ khó thấp hơn. Trong giai đoạn thứ hai, quá trình phân phối chuyển sang các nhiệm vụ nhiều bước nhảy có độ khó cao hơn đòi hỏi quỹ đạo tìm kiếm và chu kỳ cắt tỉa mở rộng. Giai đoạn này cho phép học một chính sách hợp lý trước khi đưa mô hình vào các vấn đề có khả năng xảy ra phần thưởng gần như bằng 0 nếu không có chính sách tìm kiếm vốn đã hiệu quả.
Thứ hai, chương trình giảng dạy phần thưởng thông qua . Giữa các kỷ nguyên, thông số trong phần thưởng được giảm bớt từ việc tập trung vào thu hồi, thu hồi theo trọng số cao hơn 16 lần so với độ chính xác đối với thu hồi theo trọng số gấp 4 lần. Trong giai đoạn đầu đào tạo, thiên hướng nhớ lại khuyến khích việc khám phá rộng rãi: mô hình được khen thưởng khi tìm thấy các tài liệu liên quan bất kể nó tích lũy bao nhiêu tiếng ồn. Khi quá trình đào tạo tiến triển và mô hình trở nên thành thạo trong việc tìm kiếm và cắt tỉa, sẽ chuyển sang hướng chính xác, khuyến khích mô hình chọn lọc hơn những gì nó giữ lại trong kết quả cuối cùng.
Mở rộng cơ sở hạ tầng tìm kiếm để triển khai RL
Một bước đào tạo duy nhất tạo ra hàng chục nghìn yêu cầu tìm kiếm trên 1.024 quỹ đạo thực thi lệnh gọi công cụ song song, với tốc độ đồng thời cao nhất ở hơn 3.000 truy vấn mỗi giây khi môi trường xoay vòng giữa suy luận mô hình và thực thi công cụ. Để xử lý tải này, mỗi bộ sưu tập Chroma được sao chép nội bộ trên Chroma Cloud, trong đó mỗi lệnh gọi công cụ sẽ chọn ngẫu nhiên một bản sao. Hệ số sao chép được chọn theo kinh nghiệm để duy trì độ trễ truy vấn có thể quản lý được trong điều kiện tải triển khai cao điểm. Không có lỗi nào xảy ra từ cơ sở hạ tầng tìm kiếm của chúng tôi trong quá trình đào tạo, loại bỏ điều đó như một nguồn bất ổn tiềm tàng trong quá trình triển khai song song trên quy mô lớn.
Hành vi mẫu#
Việc đào tạo làm phát sinh một số hành vi trong Context-1 có lợi cho tìm kiếm hiệu quả.
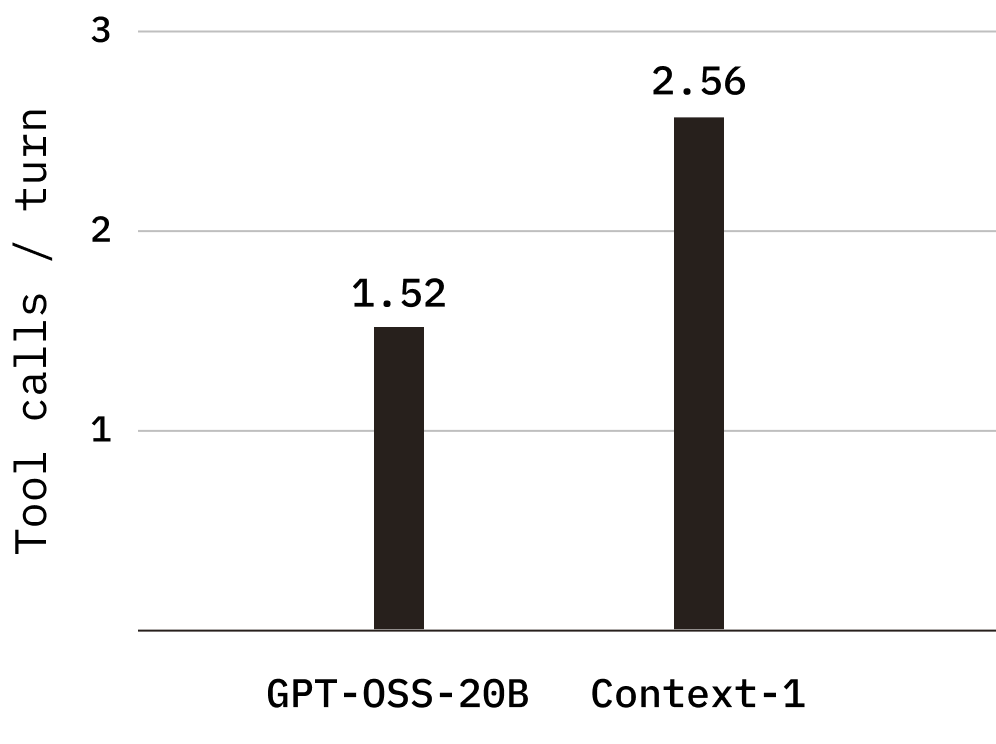
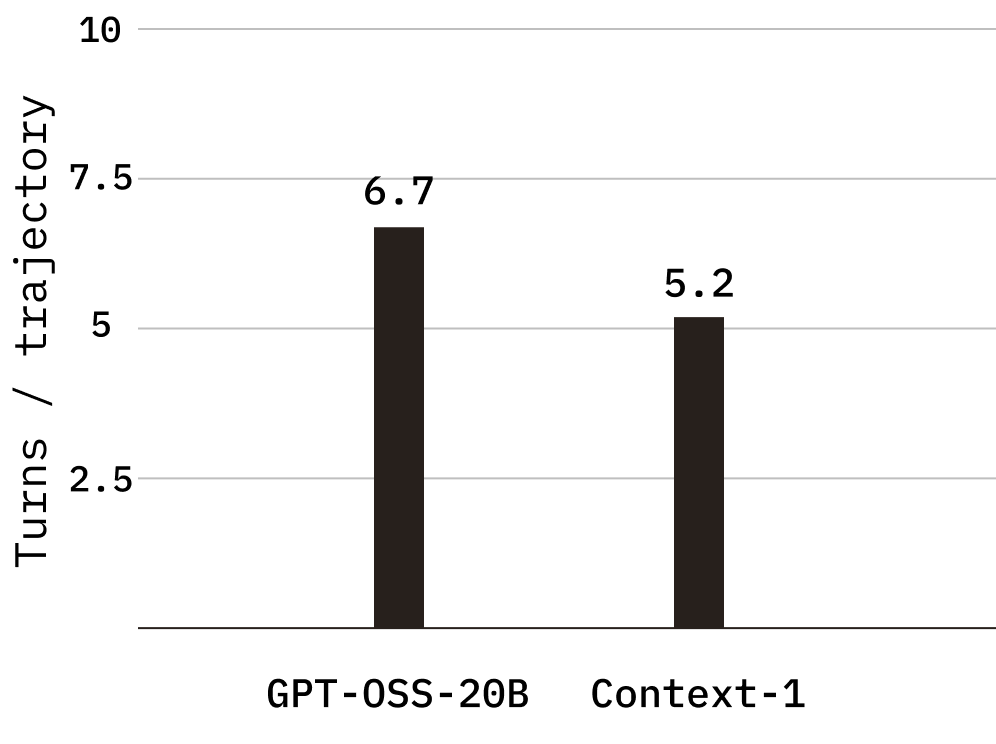
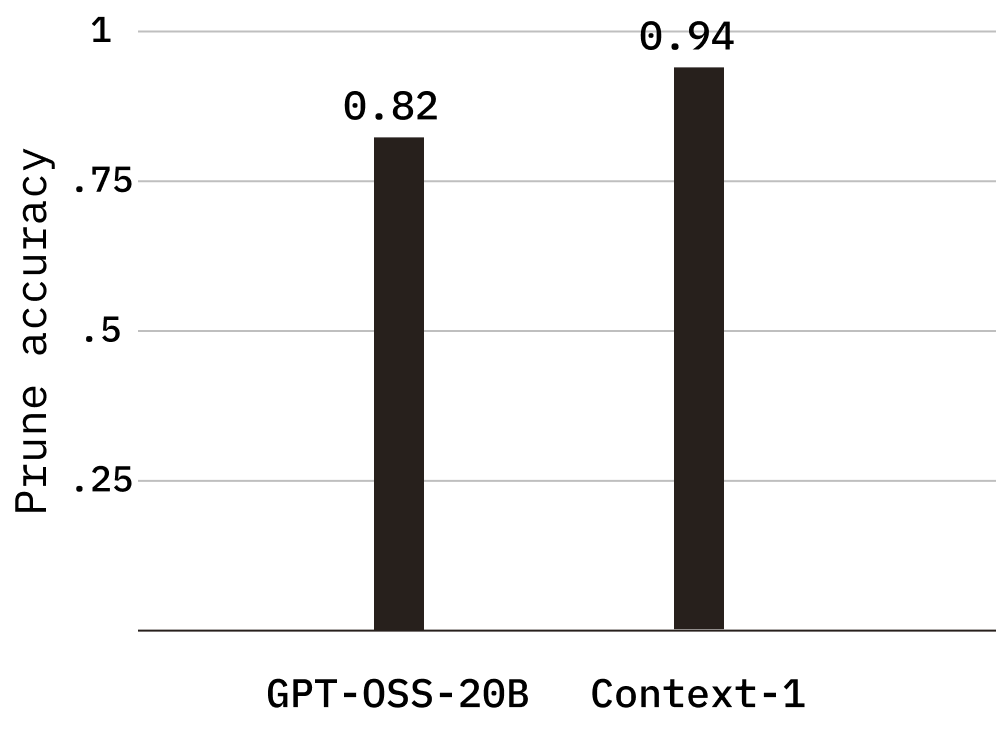
Gọi công cụ song song
Context-1 sử dụng nhiều hơn đáng kể các lệnh gọi công cụ song song, trung bình 2,56 lệnh gọi công cụ mỗi lượt so với 1,52 đối với mô hình cơ sở đối với các nhiệm vụ mà mô hình cơ sở có thể hoàn thành. Sự gia tăng thông lượng mỗi lượt này giúp giảm số lượt cần thiết để hoàn thành một nhiệm vụ, từ mức trung bình 6,7 lượt trên mỗi quỹ đạo trong mô hình cơ sở xuống 5,2 trong Ngữ cảnh-1, trực tiếp góp phần giảm độ trễ và chi phí từ đầu đến cuối.
Cắt bớt độ chính xác
Chúng tôi cũng quan sát thấy sự cải thiện đáng kể về độ chính xác của việc cắt bớt, đo lường xem liệu tác nhân có xác định chính xác các tài liệu không liên quan để xóa hay không. Context-1 đạt được độ chính xác tinh chỉnh 0,941, tăng từ 0,824 trong mô hình cơ sở, cho thấy khả năng loại bỏ tiếng ồn và giữ lại tín hiệu rõ ràng hơn một cách có ý nghĩa.
Lập kế hoạch
Cuối cùng, Context-1 thể hiện khả năng lập kế hoạch được cải thiện đáng kể. Dấu vết lý luận của mô hình cho thấy chuỗi suy nghĩ của mô hình có tính rõ ràng và cấu trúc cao hơn, cho phép mô hình phân tách các truy vấn phức tạp hiệu quả hơn trước khi hành động.
Trước (gpt-oss-20b)
Chúng ta cần truy xuất các tài liệu có chứa câu trả lời cho câu hỏi: “Giải thưởng này tên là gì?” Giải thưởng này là sự công nhận cao đối với lòng dũng cảm trên chiến trường, được thành lập vào cuối thế kỷ 18, và một buổi lễ diễn ra tại một cảng phía nam, nơi một sĩ quan cấp cao từng chỉ huy một con tàu bị tấn công trong chiến dịch đó đã đích thân trao tặng danh hiệu cho một trong những kẻ tấn công. Bối cảnh: một sĩ quan hải quân tham gia một chiến dịch dưới nước ở phía đông Địa Trung Hải vào mùa đông đầu những năm 1940. Điều đó gợi ý các hoạt động của Thế chiến thứ hai. Hoạt động dưới nước ở phía đông Địa Trung Hải: có khả năng là hoạt động của tàu ngầm Đức? Nhưng cụm từ "sĩ quan hải quân tham gia vào một hoạt động dưới nước" có thể ám chỉ một hoạt động dưới nước như của Ý hoặc Anh, hoặc có lẽ là một cuộc tấn công bằng tàu ngầm. "Đông Địa Trung Hải trong mùa đông đầu những năm 1940" có thể là Chiến dịch Kittiwake? Trên thực tế, chúng ta hãy nghĩ: "Chiến dịch dưới nước" có thể là một chiến dịch giống như Chiến dịch Bernhard? Không, đó là một cuộc chiến khác…
Sau (Context-1)
Hãy để tôi chia nhỏ truy vấn này để hiểu những gì tôi cần tìm:
Truy vấn hỏi tên của một giải thưởng. Hãy để tôi phân tích các manh mối:
1. Một sĩ quan hải quân đã tham gia vào một hoạt động dưới nước ở phía đông Địa Trung Hải vào mùa đông đầu những năm 1940.
- Điều này xảy ra trong Thế chiến thứ hai, vì vậy đầu những năm 1940 = 1940-1943 hoặc lâu hơn.
- Đông Địa Trung Hải = có thể ở xung quanh Hy Lạp, Thổ Nhĩ Kỳ, Lebanon, Syria, Síp, Crete, v.v.
- Hoạt động dưới nước = có thể là chiến tranh tàu ngầm hoặc rải mìn hải quân, v.v.
2. Nhiều năm sau khi chiến sự kết thúc (sau Thế chiến thứ hai, tức là sau năm 1945), một buổi lễ đã diễn ra tại một cảng phía nam.
- Cảng phía Nam - có thể ở Mỹ, Nam Âu, hoặc một nơi nào khác.
3. Tại buổi lễ này, một sĩ quan cấp cao, người từng chỉ huy một con tàu bị tấn công trong chiến dịch đó, đã đích thân trao tặng danh hiệu cho một trong những kẻ tấn công.
- Vì vậy, đã có một con tàu bị tấn công trong chiến dịch dưới nước vào đầu những năm 1940.
- Người chỉ huy con tàu đó, nhiều năm sau đó, đã trao tặng danh hiệu cho ai đó (kẻ tấn công).
4. Vinh dự đặc biệt này được thiết lập vào cuối thế kỷ 18, đại diện cho sự công nhận cao nhất cho lòng dũng cảm trên chiến trường ở quốc gia xuất xứ của nó.
- Được thành lập vào cuối thế kỷ 18 = những năm 1700.
- Sự công nhận cao nhất cho lòng dũng cảm trên chiến trường = điều này nghe giống như một biểu tượng quân sự cho lòng dũng cảm.
- Đối với một quốc gia - có thể là Mỹ, Anh, Pháp, v.v.
…
Cả hai dấu vết từ cùng một nhiệm vụ (miền web, nhiệm vụ 1_0).
Khi so sánh với mô hình cơ sở, Context-1 nhận thấy sự cải thiện trên tất cả các chỉ số đánh giá chính.
| Traj thu hồi | Thu hồi đầu ra | F1 | Đã tìm thấy câu trả lời cuối cùng | |
|---|---|---|---|---|
| gpt-oss-20b (cơ sở) | 0,640 | 0,361 | 0,307 | 0,541 |
| Ngữ cảnh-1 | 0,739 | 0,641 | 0,487 | 0,798 |
Suy luận#
Chúng tôi thực hiện cả SFT và RL bằng cách sử dụng điểm kiểm tra BF16 của GPT-OSS 20B, sau đó thực hiện chưng cất nhận biết lượng tử hóa trên các dấu vết từ mô hình có độ chính xác cao hơn để lượng tử hóa thành MXFP4. Tại thời điểm suy luận, Ngữ cảnh-1 được cung cấp qua vLLM. Mô hình này chạy trên Nvidia B200 với khả năng lượng tử hóa MXFP4 cho các lớp MoE, cho phép suy luận nhanh mặc dù tổng số tham số là 20B. Lớp phục vụ hiển thị API phát trực tuyến thực thi vòng lặp quan sát-lý do-hành động đầy đủ và trả về các lệnh gọi công cụ, quan sát và tài liệu được truy xuất cuối cùng, cho phép các ứng dụng hạ nguồn hiển thị quy trình tìm kiếm của tác nhân trong thời gian thực. Theo thiết lập này, chúng tôi thu được 400-500 tok/s một cách đáng tin cậy từ đầu đến cuối.
Kết quả#
Chúng tôi đánh giá Context-1 cùng với 10 mô hình khác dựa trên các điểm chuẩn công khai và do chúng tôi tạo ra, đồng thời quan sát hiệu suất tương đương với các mô hình biên giới. So với mô hình cơ sở, gpt-oss-20b, Context-1 đạt được sự cải thiện đáng kể trên tất cả các miền.
Đối với một tập hợp con chọn lọc của các mô hình biên giới, chúng tôi cũng phân tích tác động của việc có ngân sách mã thông báo thấp và công cụ cắt tỉa. Cụ thể, chúng tôi cung cấp cho các mô hình này ngân sách mã thông báo là 200 nghìn mã thông báo (trái ngược với 24 nghìn mã thông báo) và xóa prune_chunks khỏi bộ công cụ của nó. Chúng tôi gọi các phiên bản này là [model] (bối cảnh 200k, không cắt tỉa). Hiệu suất của nhiều mô hình khác nhau với ngân sách ít ràng buộc hơn và việc loại bỏ công cụ cắt tỉa sẽ khác nhau tùy thuộc vào mô hình cơ sở.
Chúng tôi đưa vào đánh giá về Ngữ cảnh-1 (4x), là kết quả của việc chạy bốn lần triển khai Ngữ cảnh-1 và thực hiện kết hợp xếp hạng tương hỗ trên kết quả. Do chi phí thấp và thông lượng cao của Context-1 nên chạy nó trong cấu hình 4x vẫn rẻ hơn so với các mẫu lớn hơn và có thể chạy nhiều đợt triển khai theo kiểu song song đến mức đáng xấu hổ.
Điểm chuẩn được tạo#
Web#
Điểm chuẩn miền web này gần giống nhất với DuyệtComp, sử dụng các trang web làm kho dữ liệu. Chúng tôi xâu chuỗi các câu hỏi để thay đổi số bước nhảy cần thiết để đi đến câu trả lời cuối cùng, với số bước nhảy cao nhất là 4 bước nhảy.
manh mối: "Một công trình kiến trúc linh thiêng ở thủ đô Tây Âu được thiết kế theo phong cách kết hợp hai truyền thống kiến trúc cổ xưa, được lựa chọn thông qua một quá trình cạnh tranh bắt đầu vào cuối những năm 1860. Cộng đồng xây dựng tòa nhà này đã được nhà nước chính thức công nhận vào đầu những năm 1830, ngay sau khi quốc gia của họ giành được độc lập. Việc xây dựng dinh thự này được hoàn thành trong cùng năm một tàu viễn dương của Bỉ được hạ thủy từ một xưởng đóng tàu ở Anh vào đêm trước ngày đông chí."
câu hỏi: "Tòa nhà này chính thức được khánh thành vào ngày nào?"
sự thật: "20 tháng 9 năm 1878"
Tài chính#
Chúng tôi sử dụng hồ sơ SEC có sẵn công khai từ năm 2025 để tạo nhiệm vụ. Chúng tôi sử dụng dữ liệu gần đây này để giảm thiểu ô nhiễm vì hầu hết ngày giới hạn cho các mẫu được đánh giá của chúng tôi là vào năm 2025. Ở đây, chúng tôi cũng xâu chuỗi các câu hỏi với tổng số lên tới 3 bước nhảy.
manh mối: "Một công ty đã kết thúc một đợt ngừng việc lớn vào cuối năm 2024 sau khi các thành viên công đoàn đại diện cho khoảng 1/5 lực lượng lao động ở một bang phía tây bắc đã bỏ phiếu thông qua một thỏa thuận mới. Thỏa thuận này thay thế một thỏa thuận cũ đã hết hạn vào đầu mùa thu năm đó. Các cổ đông của một nhà cung cấp lớn đã thông qua các điều khoản sáp nhập vào cuối mùa đông năm sau."
câu hỏi: "Thỏa thuận thương lượng tập thể mới hết hạn vào tháng và năm nào?"
sự thật: "Tháng 9 năm 2028"
Pháp lý#
Việc kiểm tra bằng sáng chế đương nhiên tạo ra loại lý luận nhiều tài liệu mà chúng tôi muốn kiểm tra. Khi thẩm định viên cấp bằng sáng chế từ chối yêu cầu bảo hộ, họ phải trích dẫn tình trạng kỹ thuật cụ thể đã có trước đó, tức là các bằng sáng chế có trước đó dự kiến phát minh được yêu cầu bảo hộ. Những sự từ chối này kết nối các tài liệu một cách rõ ràng thông qua các mối quan hệ được tranh luận, cung cấp các liên kết có căn cứ xác thực giữa các bằng sáng chế.
Nhiệm vụ: [Yêu cầu bồi thường]... Tuyên bố này bị từ chối dựa trên Prior Art A. Prior Art A mô tả một hệ thống xác thực các hạng mục hữu hình bằng cách sử dụng phương pháp lưu trữ hồ sơ phi tập trung. Tài liệu này bao gồm việc thu thập dữ liệu phát xạ quang phổ từ vật liệu khi tiếp xúc với năng lượng, cùng với thông tin nhận dạng bổ sung. Ưu tiên A giải quyết yêu cầu bảo vệ mật mã thông qua mô tả bằng chứng xác minh bằng cách sử dụng thông tin xác thực mã hóa bất đối xứng được ghép nối, trong đó bằng chứng đó có thể được tạo và xác thực để xác nhận danh tính của các thực thể và nhận dạng duy nhất các mục vật lý. Tìm tác phẩm nghệ thuật phù hợp với những chi tiết này.
Email#
Email đưa ra những thách thức riêng biệt cho việc tìm kiếm: chúng thường chứa các tham chiếu trừu tượng đến ngữ cảnh chung, ngôn ngữ thân mật, lỗi ngữ pháp, chữ viết tắt và các câu rời rạc. Để nắm bắt điều này, chúng tôi sử dụng email từ các tệp Epstein đã phát hành để tạo nhiệm vụ. Các tệp này được phát hành vào tháng 11 năm 2025, sau khi ngừng đào tạo các mô hình được đánh giá của chúng tôi, đảm bảo nội dung không bị nhìn thấy.
Để điền vào kho dữ liệu của mình, chúng tôi sử dụng Bộ dữ liệu email của Enron: một tập hợp thư từ nội bộ được phát hành trong cuộc điều tra Enron năm 2001. Những email này có chung đặc điểm (giọng điệu không trang trọng, chữ viết tắt, ngữ cảnh ngầm) nhưng có sẵn rộng rãi và có khả năng xuất hiện trong dữ liệu đào tạo mô hình, khiến chúng không phù hợp để tạo nhiệm vụ. Thay vào đó, chúng tôi thay thế tên và ngày tháng của chúng, sau đó sử dụng chúng để điền vào kho dữ liệu, tăng độ khó truy xuất mà không làm ảnh hưởng đến mục tiêu đánh giá của chúng tôi.
manh mối: "Một cá nhân từng làm việc trong việc phát triển hệ điều hành đã chia sẻ một bài báo từ một phương tiện truyền thông về một loại tiền kỹ thuật số phi tập trung được chấp nhận ở thủ đô của quốc gia, lưu ý mức tăng tỷ lệ phần trăm cụ thể đối với số tiền nắm giữ của họ. Trong một chủ đề khác, một nhà báo của cùng cơ quan truyền thông này đã liên hệ với một chuyên gia pháp lý về một tuyên bố được đệ trình lên tòa án liên bang liên quan đến những cáo buộc về một cựu nguyên thủ quốc gia và thời gian ở trên một hòn đảo. Cơ quan truyền thông này cũng đã đăng tin về một cuốn sách kể lại mọi chuyện gây tranh cãi về một chính quyền, được đề cập đến khi một trợ lý đề cập đến việc không thể in một bài báo do thiếu lượt đăng ký."
câu hỏi: "Tổ chức truyền thông nào đã xuất bản cả ba cuốn sách?"
sự thật: "Washington Post"
Kết quả#
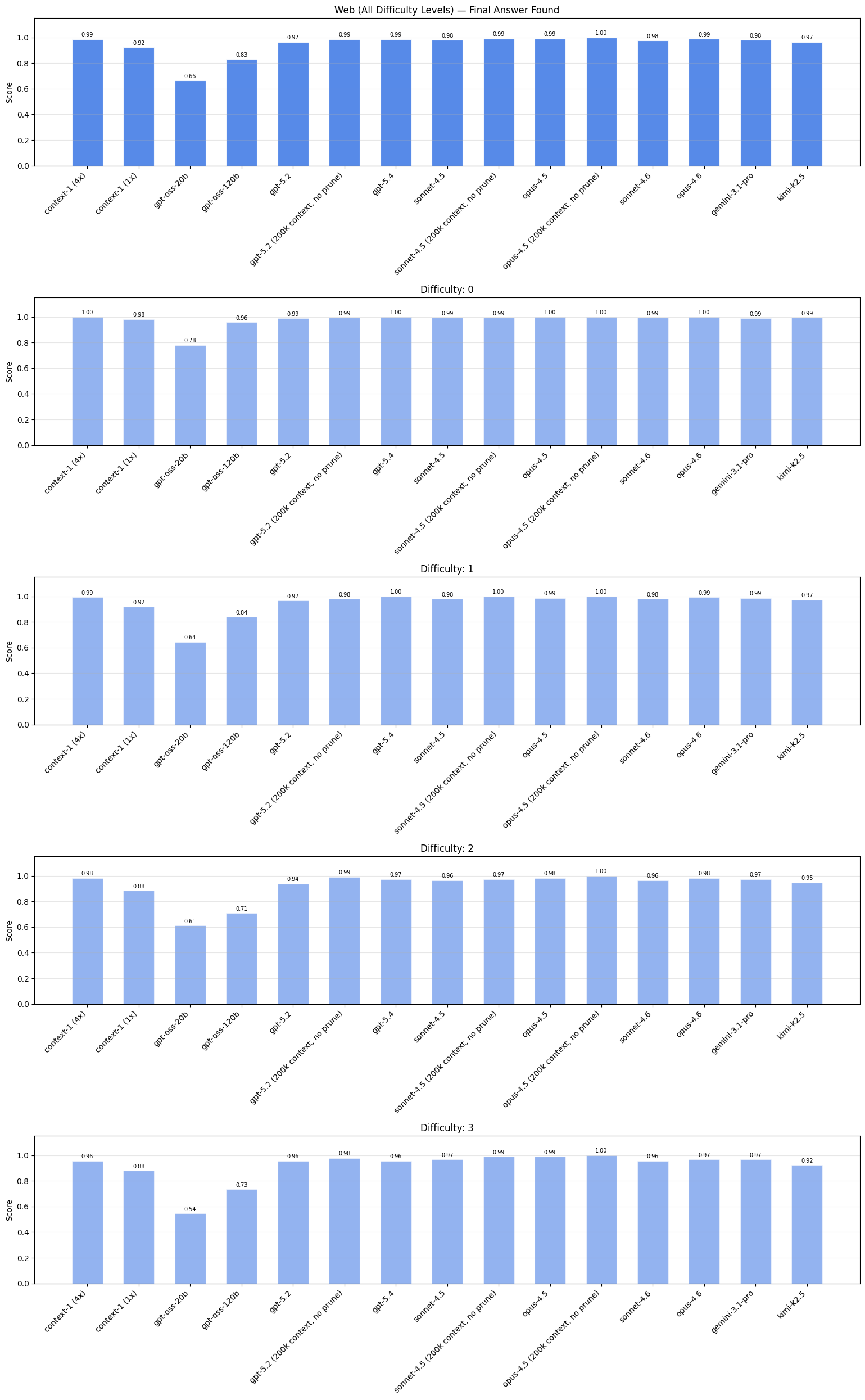
Context-1, đặc biệt khi xem xét phiên bản 4x, có hiệu suất tìm kiếm tương tự như các mô hình biên giới. Lưu ý: kết quả trang web và tài chính được lọc theo mức độ khó cụ thể do độ bão hòa ở các cấp độ thấp hơn; kết quả đầy đủ cho từng mức độ khó được trình bày chi tiết trong phần phụ lục.
| Mô hình ↕ | Web (Diff. 2+) ↕ | Tài chính (Diff. 1+) ↕ | Pháp lý ↕ | Email ↕ |
|---|---|---|---|---|
| Context-1 (4x) | 0,97 | 0,82 | 0,95 | 0,98 |
| Context-1 (1x) | 0,88 | 0,64 | 0,89 | 0,92 |
| gpt-oss-20b | 0,58 | 0,42 | 0,58 | 0,75 |
| gpt-oss-120b | 0,72 | 0,58 | 0,76 | 0,89 |
| gpt-5.2 | 0,95 | 0,65 | 0,92 | 0,93 |
| gpt-5,2 (200k, không mận) | 0,99 | 0,80 | 0,94 | 0,97 |
| gpt-5,4 | 0,97 | 0,67 | 0,9 5 | 0,97 |
| sonnet-4,5 | 0,97 | 0,76 | 0,92 | 0,98 |
| sonnet-4.5 (200k, không mận) | 0,98 | 0,82 | 0,96 | 0,98 |
| opus-4,5 | 0,99 | 0,82 | 0,90 | 0,98 |
| opus-4.5 (200k, không mận) | 0,99 | 0,90 | 0,98 | 0,98 |
| sonnet-4.6 | 0,96 | 0,72 | 0,91 | 0,97 |
| opus-4,6 | 0,98 | 0,84 | 0,94 | 0,98 |
| gemini-3.1-pro | 0,97 | 0,82 | 0,88 | 0,94 |
| kimi-k2.5 | 0,94 | 0,72 | 0,98 | 0,97 |
Mặc dù không được đào tạo rõ ràng về miền email, Context-1 vẫn cho thấy sự cải thiện đáng kể về hiệu suất. Điều này nêu bật cách các kỹ năng tìm kiếm của Ngữ cảnh-1 khái quát hóa ra ngoài các lĩnh vực và cách xây dựng nhiệm vụ cụ thể mà nó đã được đào tạo. Chúng tôi sẽ khám phá thêm điều này trong phần sau về điểm chuẩn công khai.
Bối cảnh 200 nghìn, không cắt tỉa các phiên bản của mô hình biên giới hoạt động tốt hơn các phiên bản bị ràng buộc bởi mã thông báo của chúng. Một lý do cho điều này là hạn chế về ngân sách token thường dẫn đến việc chấm dứt sớm. Khi mô hình liên tục được yêu cầu cắt bớt hoặc chấm dứt, nó có nhiều khả năng kết thúc sớm hơn so với khi nó không bao giờ được yêu cầu. Do đó, các biến thể không cắt tỉa tạo ra số lượng lệnh gọi công cụ và tài liệu được truy xuất lớn hơn, điều này làm tăng khả năng gặp phải các tài liệu hỗ trợ.
Điểm chuẩn công khai#
Chúng tôi cũng đánh giá Context-1 dựa trên một số điểm chuẩn công khai hiện có. Mặc dù các điểm chuẩn này không phản ánh đầy đủ các quy trình tìm kiếm tác nhân thực tế nhưng chúng hỗ trợ đánh giá các kỹ năng tìm kiếm cơ bản.
Lưu ý: Hầu hết các điểm chuẩn công khai sau đây không chứa kho văn bản cố định mà thay vào đó cung cấp các URL khẳng định và/hoặc câu trả lời trung thực. Để giúp tập trung nhiệm vụ vào tìm kiếm thay vì sao chép và theo dõi URL, chúng tôi sử dụng ánh xạ URL-to-id ngẫu nhiên, gán id tài liệu ảo cho các URL được phát hiện trong quá trình triển khai tìm kiếm.
BrowseComp-Plus#
BrowseComp-Plus là một điểm chuẩn bắt nguồn từ DuyệtComp, nhưng có các nhiệm vụ do con người xác minh và một kho văn bản cố định để có thể tái tạo.
Một cuốn sách từng là ứng cử viên cho một giải thưởng, ban đầu được tạo ra vào những năm 2000 (chính là giải thưởng), đã được dịch sang hơn 25 thứ tiếng. Vào những năm 2010, năm cuốn sách này được xuất bản, một cuốn sách khác, được phát hành vào năm trước, đã giành được giải thưởng nêu trên mà cuốn sách đầu tiên sau đó đã tranh giành. Tác giả của cuốn sách đoạt giải này sinh ra ở cùng thành phố nơi tác giả của cuốn sách được đề cập ban đầu lớn lên. Dựa trên mối liên hệ này, tác giả của cuốn sách đầu tiên ra đời ở thành phố nào?
SealQA#
Tương tự như Duyệtcomp, SealQA chứa các câu hỏi đầy thách thức với các câu trả lời thực tế có thể kiểm chứng dễ dàng. Chúng tôi đánh giá dựa trên hai biến thể:
- Seal-0 (111 câu hỏi): Các câu hỏi tuyển chọn được tinh chỉnh lặp đi lặp lại cho đến khi nhiều mô hình không thành công sau nhiều lần thử. Mỗi câu hỏi bao gồm các URL khẳng định chứa thông tin hỗ trợ.
- LongSeal (254 câu hỏi): Một biến thể mò mẫm trong đó mỗi câu hỏi kết hợp với một tập hợp lớn các tài liệu được truy xuất, chỉ một trong số đó chứa hoặc ngụ ý câu trả lời đúng, bị chôn vùi giữa những nội dung không liên quan hoặc gây hiểu lầm.
Ai giữ kỷ lục mọi thời đại tại giải Grammy với nhiều chiến thắng nhất trong hạng mục album của năm?
Đối với Seal-0, chúng tôi cung cấp cho tác nhân các công cụ tìm kiếm và duyệt web, sau đó đánh giá xem liệu tác nhân có xác định thành công các URL tích cực làm bằng chứng hỗ trợ hay không. Đối với LongSeal, chúng tôi chia các tài liệu được cung cấp thành các đoạn có 512 mã thông báo để tạo một kho văn bản cố định, hạn chế tìm kiếm trong bộ này.
Tuy nhiên, chúng tôi lưu ý rằng một số vấn đề về ghi nhãn tập dữ liệu có thể che khuất hiệu suất của tác nhân. Ví dụ: một số công cụ phân tâm LongSeal thực sự chứa thông tin chính xác và một số URL chứa thông tin hỗ trợ không được tính đến, dẫn đến điểm thu hồi thấp đến mức gây nhầm lẫn mặc dù việc truy xuất thông tin thành công.
FRAMES#
FRAMES là điểm chuẩn truy xuất nhiều bước bắt nguồn từ các bài viết trên Wikipedia. Chúng tôi cấp cho tác nhân tìm kiếm quyền truy cập đầy đủ vào Wikipedia thông qua Serper, thêm các truy vấn bằng bộ lọc site:[wikipedia.org], với nội dung trang được truy xuất thông qua API Wikipedia.
Các tác vụ này đi kèm với một tập hợp các URL Wikipedia tích cực mà chúng tôi sử dụng để đánh giá khả năng thu hồi. Chúng tôi cũng đảm bảo rằng tất cả các URL Wikipedia tích cực này đều có thể truy cập được thông qua API Wikipedia và lọc ra các tác vụ không có URL được đặt hoàn toàn trong API. Chúng tôi lưu ý rằng Wikipedia phần lớn được ghi nhớ bởi LLM, điều này đôi khi khiến các mô hình truy vấn sớm để tìm ra câu trả lời, thay vì tham gia vào tìm kiếm dựa trên khám phá thực sự.
Hãy tưởng tượng có một tòa nhà tên là Tháp Bronte có chiều cao tính bằng feet bằng với phân loại thập phân Dewey trong cuốn sách Charlotte Bronte xuất bản năm 1847. Tòa nhà này sẽ xếp hạng ở đâu trong số các tòa nhà cao nhất ở Thành phố New York tính đến tháng 8 năm 2024?
HotpotQA#
HotpotQA là điểm chuẩn truy xuất nhiều bước, đơn giản hơn so với các tiêu chuẩn đánh giá khác. Chúng tôi đưa điều này vào để chứng minh rằng mô hình của chúng tôi, cùng với các mô hình tiên phong, bão hòa hiệu suất cho nhiệm vụ này.
Kết quả#
| Mô hình ↕ | BrowseComp+ ↕ | LongSeal ↕ | Seal0 ↕ | FRAMES ↕ | HotpotQA ↕ |
|---|---|---|---|---|---|
| Bối cảnh-1 (4x) | 0,96 | 0,79 | 0,52 | 0,96 | 0,99 |
| Bối cảnh-1 (1x) | 0,87 | 0,65 | 0,32 | 0,87 | 0,97 |
| gpt-oss-20b | 0,66 | 0. 41 | 0,21 | 0,58 | 0,60 |
| gpt-oss-120b | 0,84 | 0,54 | 0,36 | 0,81 | 0,93 |
| gpt-5.2 | < td>0,820,85 | 0,48 | 0,95 | 0,98 | |
| gpt-5.2 (200k, không có mận) | 0,94 | 0,89 | 0,57 | 0,96 | 0,99 |
| gpt-5,4 | 0,84 | 0,85 | 0,56 | 0,96 | 0,98 |
| sonnet-4,5 | 0,87 | 0,82 | 0,48 | 0,96 | 0,99 |
| sonnet-4.5 (200k, không mận) | 0,86 | 0,88 | 0,66 | 0,96 | 0,99 |
| opus- 4,5 | 0,87 | 0,81 | 0,62 | 0,97 | 0,99 |
| opus-4.5 (200k, không có mận) | 0,92 | 0,88 | 0,72 | 0,97 | 0,99 |
| sonnet-4.6 | 0,83 | 0,75 | 0,47 | 0,96 | 0,98 |
| opus-4.6 | 0,91 | 0,83 | 0,53 | 0,97 | 0,99 |
| 0,94 | 0,74 | 0,49 | 0,92 | 0,99 | |
| kimi- k2,5 | 0,87 | 0,73 | 0,40 | 0,92 | 0,99 |
Chúng tôi nhận thấy xu hướng tương tự của Context-1 có hiệu suất tương đương với các mô hình tiên phong trong các điểm chuẩn công khai này.
Bài kiểm tra cuối cùng của loài người (HLE)#
Bài kiểm tra cuối cùng của loài người (HLE) chứa các câu hỏi cực kỳ thách thức trên hàng chục lĩnh vực chủ đề, được các học giả và chuyên gia miền thiết kế như một thước đo toàn diện về các kiến thức tổng quát năng lực học thuật. Từ tập dữ liệu đầy đủ, chúng tôi lọc các câu hỏi chỉ có văn bản trên các lĩnh vực Nhân văn/Khoa học xã hội, Sinh học/Y học, Hóa học và các lĩnh vực khác để tách riêng các kỹ năng tìm kiếm cụ thể (loại trừ các câu hỏi yêu cầu lý luận hoặc tính toán đa phương thức).
Điều kiện nào trong định lý bất khả thi thứ sáu của Arrhenius khiến các quan điểm ở cấp độ quan trọng vi phạm?
Lựa chọn trả lời: A. Sự thống trị theo chủ nghĩa quân bình B. Ưu tiên chung không cực đoan C. Chủ nghĩa không tinh hoa D. Chủ nghĩa không tàn bạo yếu E. Chất lượng bổ sung yếu
Vì HLE chỉ cung cấp câu trả lời trung thực cơ bản mà không có URL tích cực nên chúng tôi đánh giá hiệu quả tìm kiếm bằng cách so sánh hai điều kiện:
- Cơ sở: mô hình trình tạo (Opus-4.6 với ngân sách tư duy 5000 mã thông báo) trả lời trực tiếp mà không cần tìm kiếm
- Với Tìm kiếm: tác nhân tìm kiếm truy xuất các tài liệu hỗ trợ, sau đó được cung cấp cho cùng một mô hình trình tạo cùng với câu hỏi
Chúng tôi so sánh mức tăng hiệu suất tương đối giữa các mô hình tác nhân tìm kiếm khác nhau.
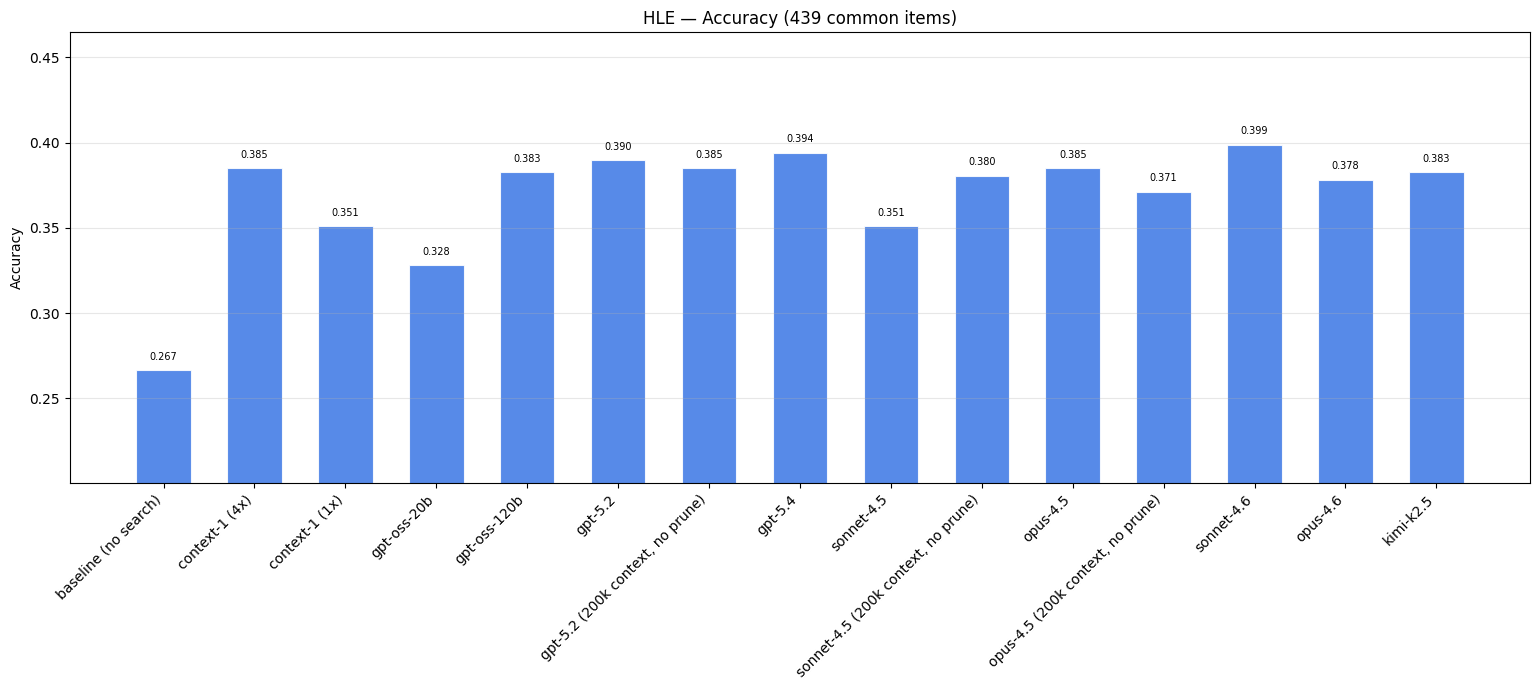
Liên quan đến đường cơ sở của việc không tìm kiếm, việc thêm tác nhân phụ tìm kiếm vào đường cơ sở Opus-4.6 sẽ cải thiện đáng kể độ chính xác của câu trả lời. Sự khác biệt về mức tăng hiệu suất giữa các mô hình tác nhân phụ thể hiện sự khác biệt về chất lượng tài liệu đầu ra. Tuy nhiên, sự khác biệt này không đáng kể so với các điểm chuẩn khác do độ khó của nhiệm vụ.
Với điểm chuẩn này, thật thú vị khi nhận thấy rằng việc loại bỏ hạn chế ngân sách mã thông báo không có tác dụng nhất quán trên tất cả các mô hình. Chỉ sonnet-4.5 mới thấy hiệu suất tăng lên nhờ ngân sách mã thông báo thoải mái, trong khi kết quả đầu ra của gpt-5.2 và opus-4.5 bị ảnh hưởng tiêu cực đôi chút.
Định hướng tương lai#
Sự đa dạng của nhiệm vụ#
Hạn chế chính của công việc này là sự tập trung hạn hẹp của chúng tôi vào các câu hỏi kiểu tìm kim tiêm: truy vấn nhiều ràng buộc được thiết kế để tìm ra một câu trả lời cụ thể duy nhất. Mặc dù có hiệu quả trong việc tách biệt các kỹ năng lập kế hoạch và đánh giá, nhưng những nhiệm vụ này thường không thực tế. Tìm kiếm thực tế thường trừu tượng hơn; người dùng không chỉ định mọi tiêu chí cần thiết để xác minh kết quả cuối cùng và một phần của nhiệm vụ là suy ra ý định và dự đoán thông tin nào sẽ thực sự hữu ích. Ngoài ra, tất cả các nhiệm vụ của chúng tôi đều có định hướng chuyên sâu: tác nhân phải tìm một thông tin đáp ứng nhiều tiêu chí. Chúng tôi hiện không bao gồm các truy vấn theo chiều rộng, trong đó mục tiêu là tìm tất cả thông tin thỏa mãn một tiêu chí cụ thể, chẳng hạn như "tìm mọi hồ sơ SEC đề cập đến sự gián đoạn chuỗi cung ứng trong quý 4 năm 2024". Tìm kiếm theo chiều rộng đưa ra những thách thức cơ bản khác nhau xung quanh tính đầy đủ, loại bỏ sự trùng lặp và biết khi nào nên dừng.
Trước khi theo đuổi những cải tiến hơn nữa cho chính tác nhân, bước tiếp theo có tác động mạnh nhất là phát triển nhiều phân phối nhiệm vụ mang tính đại diện hơn. Điều này bao gồm phân loại các loại truy vấn (độ sâu so với chiều rộng, thực tế so với thăm dò, câu trả lời đơn lẻ so với câu trả lời đơn giản). tổng hợp), các bài kiểm tra bỏ phiếu trắng trong đó hành vi đúng là nhận ra rằng không có câu trả lời thỏa đáng nào tồn tại và các nhiệm vụ yêu cầu tác nhân diễn giải các yêu cầu mơ hồ hoặc chưa được xác định rõ.
Cơ sở hạ tầng tìm kiếm và sử dụng công cụ#
Bộ công cụ hiện tại của Context-1 (tìm kiếm, grep, đọc và cắt tỉa) được cố tình tối thiểu hóa. Một số tiện ích mở rộng có thể mở rộng đáng kể khả năng của tác nhân.
Tạo mã cho tìm kiếm. Nhiều tập đoàn trong thế giới thực chứa dữ liệu có cấu trúc hoặc bán cấu trúc như bảng, bảng tính và JSON, trong đó tìm kiếm từ khóa và vectơ không phù hợp. Việc cho phép tác nhân tạo và thực thi mã (truy vấn SQL, thao tác gấu trúc, đường dẫn biểu thức chính quy) sẽ mở ra khả năng tìm kiếm trên dữ liệu có cấu trúc mà các công cụ hiện tại không thể xử lý hiệu quả.
Khám phá lược đồ và siêu dữ liệu. Dữ liệu thực đi kèm với siêu dữ liệu: dấu thời gian, tác giả, loại tài liệu, nhãn phân loại. Tác nhân hiện không có cơ chế để khám phá hoặc tận dụng cấu trúc này. Việc hiển thị các lược đồ siêu dữ liệu và cho phép tác nhân xây dựng các truy vấn được lọc sẽ cải thiện cả độ chính xác và hiệu quả, đặc biệt trong các lĩnh vực như tài chính và pháp lý nơi siêu dữ liệu có mật độ thông tin dày đặc.
Xếp hạng lại đã học. Hiện tại, trình sắp xếp lại là một thành phần cố định trong quy trình công cụ. Một cách khác là để cho tác nhân viết hoặc tham số hóa chính truy vấn của trình sắp xếp lại, kiểm soát hiệu quả cách tính điểm và sắp xếp các kết quả được truy xuất. Điều này có thể cho phép các chiến lược sắp xếp lại theo nhiệm vụ cụ thể mà không cần đào tạo lại người sắp xếp lại.
Tích hợp dàn nhạc. Context-1 hoạt động như một tác nhân phụ độc lập trả về một bộ tài liệu tĩnh. Việc tích hợp chặt chẽ hơn với mô hình điều phối, trong đó trình tạo có thể điều khiển quá trình truy xuất trong thời gian thực bằng cách yêu cầu theo dõi hoặc làm rõ cụ thể dựa trên một phần kết quả, có thể thu hẹp khoảng cách giữa nội dung được truy xuất và nội dung thực sự cần thiết để trả lời câu hỏi.
Quản lý bối cảnh#
Phương pháp quản lý bối cảnh hiện tại của chúng tôi, ngân sách mã thông báo cứng với việc cắt tỉa rõ ràng, tuy hiệu quả nhưng cứng nhắc. Một số hướng có thể giúp việc quản lý bối cảnh trở nên thích ứng hơn.
Bàn di chuột và lưu giữ có chọn lọc. Thay vì buộc phải đưa ra quyết định giữ hoặc loại bỏ nhị phân trên mỗi đoạn, tác nhân có thể duy trì một bàn di chuột: một bộ nhớ làm việc được nén trong đó các dữ kiện chính, kết luận một phần và tham chiếu chéo được ghi lại trong quá trình tìm kiếm. Điều này sẽ cho phép tác nhân cắt bớt văn bản thô của tài liệu trong khi vẫn giữ lại nội dung thông tin của nó ở dạng có cấu trúc. Mô hình chọn tham gia, trong đó các phần phải được quảng bá rõ ràng vào tập hợp đầu ra thay vì được đưa vào theo mặc định, cũng có thể mang lại độ chính xác cao hơn.
Tóm tắt. Chúng tôi đã cố tình tránh nén bị mất dữ liệu trong tác phẩm này, chọn lưu giữ ở cấp độ tài liệu để duy trì độ trung thực của bằng chứng. Tuy nhiên, các phương pháp kết hợp kết hợp việc lưu giữ có chọn lọc các đoạn văn có giá trị cao với việc tóm tắt có mục tiêu hoặc lựa chọn các đoạn văn hỗ trợ có thể mang lại sự cân bằng tốt hơn, đặc biệt đối với các quỹ đạo tìm kiếm rất dài khi khối lượng bằng chứng thô vượt quá bất kỳ ngân sách thực tế nào.
Đào tạo#
Đào tạo tương tác muộn và truy xuất chung. Mô hình nhúng, trình sắp xếp lại và tác nhân tìm kiếm hiện được đào tạo độc lập: tác nhân học cách viết các truy vấn dựa trên ngăn xếp truy xuất cố định. Quy trình của Context-1 phản ánh mô hình hai giai đoạn tiêu chuẩn: giai đoạn đầu tiên nhanh (kết hợp BM25 + truy xuất dày đặc) đánh đổi tính biểu cảm để lấy tốc độ, sau đó trình sắp xếp lại bộ mã hóa chéo sẽ khôi phục độ chính xác với chi phí cao hơn cho mỗi ứng viên. Các kiến trúc tương tác muộn như ColBERT chiếm vị trí trung gian, duy trì cách biểu diễn mỗi mã thông báo cho cả truy vấn và tài liệu cũng như mức độ liên quan của điện toán thông qua MaxSim cấp mã thông báo thay vì nén thành một vectơ duy nhất. Điều này giữ lại phần lớn tính biểu cảm của bộ mã hóa chéo trong khi vẫn đủ hiệu quả để ghi điểm trước một nhóm ứng cử viên lớn hơn mức cho phép sắp xếp lại thông thường. Việc cùng đào tạo một mô hình tương tác muộn cùng với chính sách tìm kiếm có thể cho phép ngăn xếp truy xuất đồng thích ứng: quá trình nhúng học cách tạo ra các biểu diễn mã thông báo mang tính phân biệt đối xử nhất đối với các truy vấn mà tác nhân thực sự tạo ra, trong khi tác nhân học cách viết các truy vấn khai thác tính điểm cấp mã thông báo của mô hình truy xuất.
Tự phát. Quá trình đào tạo hiện tại của chúng tôi dựa trên các nhiệm vụ được tạo tổng hợp với các nhãn sự thật cố định. Một giải pháp thay thế là tự chơi, trong đó một tác nhân đặt ra câu hỏi và giấu bằng chứng trong khi người khác tìm kiếm nó, tạo ra một chương trình giảng dạy mang tính đối kháng, có độ khó tăng dần một cách tự nhiên khi cả hai tác nhân đều tiến bộ.
Làm phong phú thời gian hấp thụ. Thay vì chỉ dựa vào tìm kiếm trong thời gian chạy, tính toán ngoại tuyến tại thời điểm bắt đầu (trích xuất thực thể, ánh xạ mối quan hệ, tạo tóm tắt) có thể cung cấp cho tác nhân nền tảng phong phú hơn để tìm kiếm. Điều này đánh đổi tính toán ngoại tuyến để lấy hiệu quả thời gian chạy, một sự cân bằng ngày càng trở nên thuận lợi khi các mô hình nhanh hơn và chi phí suy luận tiếp tục giảm.
Kết luận#
Chúng tôi đã trình bày Context-1, một mô hình tìm kiếm tác nhân tham số 20B đạt đến giới hạn Pareto về hiệu suất truy xuất liên quan đến chi phí và độ trễ. Trên các điểm chuẩn do chúng tôi tạo ra, Context-1 khớp hoặc vượt các mô hình có cường độ lớn hơn — và khi chạy trong cấu hình song song 4x, nó sẽ hoạt động như vậy trong khi vẫn rẻ hơn so với một lệnh gọi đến các mô hình đó. Những lợi ích này cũng áp dụng cho các điểm chuẩn công khai: trên DuyệtComp-Plus, SealQA, FRAMES và HLE, Context-1 mang lại chất lượng truy xuất có thể so sánh với các LLM hàng đầu với chi phí tính toán chỉ bằng một phần nhỏ.
Ba kỹ thuật củng cố những kết quả này. Đầu tiên, một chương trình đào tạo theo giai đoạn sẽ chuyển phần thưởng từ việc thu hồi rộng rãi sang độ chính xác có chọn lọc, dạy đặc vụ khám phá rộng rãi trước khi thu hẹp. Thứ hai, cơ chế ngữ cảnh tự chỉnh sửa cho phép tác nhân cắt bớt các đoạn không liên quan trong quá trình tìm kiếm, duy trì khả năng truy xuất hiệu quả trong khoảng thời gian dài trong cửa sổ ngữ cảnh bị giới hạn. Thứ ba, một quy trình tạo tác vụ tổng hợp có thể mở rộng với khả năng xác minh dựa trên trích xuất, đạt được sự liên kết hơn 80% với các phán đoán của con người trên cả bốn miền, đồng thời giảm thiểu nhu cầu chú thích thủ công.
Đáng chú ý, Context-1 khái quát hóa ngoài phạm vi phân phối đào tạo của nó. Mặc dù chỉ được đào tạo về các nhiệm vụ web, pháp lý và tài chính, nhưng nó cho thấy những cải tiến đáng kể trên miền email được tổ chức và các điểm chuẩn công khai với các định dạng nhiệm vụ khác nhau, cho thấy các kỹ năng cốt lõi về phân tách truy vấn, sàng lọc lặp lại và chuyển lưu giữ có chọn lọc giữa các miền.
Chúng tôi phát hành Context-1 dưới dạng mô hình trọng số mở cùng với quy trình tạo dữ liệu đầy đủ để hỗ trợ khả năng tái tạo và nghiên cứu trong tương lai. Chúng tôi tin rằng các tác nhân phụ tìm kiếm được đào tạo theo mục đích đại diện cho một lộ trình thực tế hướng tới việc làm cho tìm kiếm tác nhân trở nên hiệu quả hơn và dễ truy cập hơn — cho phép chất lượng truy xuất được dành riêng cho các mô hình lớn nhất với chi phí và độ trễ phù hợp để triển khai sản xuất.
Lời cảm ơn#
Chúng tôi rất biết ơn Chris Manning vì những cuộc thảo luận ban đầu đã giúp định hình hướng nghiên cứu này. Chúng tôi cảm ơn Omar Khattab, Daniel Hunter, Jason Liu, Alex Zhang và John Schulman vì đã xem xét bản thảo của tác phẩm này. Chúng tôi cảm ơn Phòng thí nghiệm Máy Tư duy đã cung cấp Tinker, phòng được sử dụng để đào tạo Context-1 và sự hỗ trợ của họ trong suốt quá trình đào tạo. Chúng tôi cũng cảm ơn Richard Gong và nhóm Modal vì sự hỗ trợ của họ về cơ sở hạ tầng suy luận.
Phụ lục#
Tạo tác vụ#
Web#
Chúng tôi điều chỉnh tác nhân thám hiểm từ WebExplorer, trong đó một nhân viên được cung cấp một thực thể hạt giống và các công cụ tìm kiếm, sau đó khám phá trang web cho đến khi thu thập đủ thông tin để tạo một câu hỏi đầy thách thức.
Quá trình triển khai của chúng tôi đưa ra một số sửa đổi:
- Vòng lặp khám phá/tiến hóa kết hợp - WebExplorer tách hoạt động khám phá và tiến hóa câu hỏi thành các giai đoạn riêng biệt. Chúng tôi nhận thấy rằng với một vài ví dụ ngắn gọn về các truy vấn lý tưởng và hướng dẫn để làm rối mã nguồn, một vòng lặp tác nhân duy nhất sẽ tạo ra các nhiệm vụ đầy thử thách mà không cần thực hiện thêm bước nào.
- Khai thác bộ phân tâm - đối với mỗi nhiệm vụ, một vòng lặp tác nhân riêng biệt sẽ thu thập các bộ phân tâm: các trang web đáp ứng một số tiêu chí nhưng trỏ đến một câu trả lời khác.
- Tiện ích mở rộng nhiều bước - chúng tôi kết nối các câu trả lời từ các nhiệm vụ hiện có với các nhiệm vụ mới, xâu chuỗi các câu hỏi phụ thuộc lại với nhau. Điều này cho phép chúng tôi kiểm soát độ khó của nhiệm vụ bằng cách thay đổi số bước nhảy cần thiết để đi đến câu trả lời cuối cùng.
- Xác minh - chúng tôi xác minh rằng các tài liệu hỗ trợ thực sự hỗ trợ câu trả lời và những yếu tố gây phân tâm thực sự là những yếu tố gây phân tâm.
Thu thập tài liệu hỗ trợ và tạo nhiệm vụ
Đưa ra một chủ đề gốc được lấy mẫu từ các tiêu đề Wikipedia ngẫu nhiên, chúng tôi cung cấp cho đại lý các công cụ tìm kiếm và tìm kiếm trên web để khám phá và thu thập tài liệu chứa các thông tin thực tế độc đáo liên quan đến chủ đề đó. Chúng tôi sử dụng Serper để tìm kiếm trên web và Jina AI's Reader để thu thập dữ liệu. Để đảm bảo tính đa dạng về các loại thông tin được thu thập, chúng tôi cũng đưa ra ràng buộc về "chủ đề sự thật" (tức là sự thật phải thuộc danh mục 'người'); không có điều này, các sự kiện được thu thập có xu hướng tập trung xung quanh các khuôn mẫu trong một vài ví dụ ngắn gọn của chúng tôi. Chúng tôi sử dụng 17 chủ đề sự thật.
Sử dụng các tài liệu đã thu thập được, đặc vụ sẽ tạo ra các manh mối (tham chiếu đến các sự kiện một cách khó hiểu), một câu hỏi kết hợp các manh mối này và câu trả lời tương ứng.
Đầu vào: Truth_topic: "date" Seed_topic: "1878 in Belgium"
Kết quả: manh mối: "Một công trình kiến trúc linh thiêng ở thủ đô Tây Âu được thiết kế theo phong cách kết hợp hai truyền thống kiến trúc cổ xưa, được lựa chọn thông qua một quá trình cạnh tranh bắt đầu vào cuối những năm 1860. Cộng đồng xây dựng tòa nhà này đã được nhà nước chính thức công nhận vào đầu những năm 1830, ngay sau khi quốc gia của họ giành được độc lập. Việc xây dựng dinh thự này được hoàn thành trong cùng năm một tàu viễn dương của Bỉ được hạ thủy từ một xưởng đóng tàu ở Anh vào đêm trước ngày đông chí."
câu hỏi: "Tòa nhà này chính thức được khánh thành vào ngày nào?"
sự thật: "20 tháng 9 năm 1878"
supporting_items: "https://jguideeurope.org/en/khu vực/belgium/brussels/": "Grande Giáo đường Do Thái de…”
Xác minh nhiệm vụ
Chúng tôi xác minh thông qua trích xuất và kiểm tra xác định thông qua kiểm tra mã. Đối với mỗi tài liệu hỗ trợ, chúng tôi nhắc LLM trích xuất: document_quotes, clue_quotes và contains_truth. Chúng tôi chuẩn hóa các trích dẫn và văn bản nguồn, sau đó xác nhận các trích dẫn thực sự xuất hiện trong tài liệu.
document_quotes: "Brussels, thủ đô của các tổ chức châu Âu", "Giáo đường Do Thái theo phong cách La Mã-Byzantine", "Sau nền độc lập của Bỉ vào năm 1830 và Hiến pháp năm 1831 đảm bảo quyền tự do thờ cúng", "Giáo đường Do Thái Regency được khánh thành vào ngày 20 tháng 9 1878"
manh mối_quote: "cấu trúc thiêng liêng ở thủ đô Tây Âu", "phong cách kết hợp hai truyền thống kiến trúc cổ xưa", "được nhà nước chính thức công nhận vào đầu những năm 1830", "ngay sau khi quốc gia của họ giành được độc lập"
contains_truth = True
Việc chỉ hỏi mô hình xem liệu một tài liệu tích cực có “có liên quan” hay không là không đáng tin cậy và việc ghi nhãn của con người sẽ rất tốn kém vì nó yêu cầu phải đọc kỹ từng tài liệu. Phương pháp trích xuất của chúng tôi giảm thiểu việc xác minh của con người thành việc kiểm tra xem document_quote có hỗ trợ clue_quote hay không. Nếu bất kỳ tài liệu nào thiếu dấu ngoặc kép trùng khớp hoặc nếu không có tài liệu nào chứa sự thật, thì chúng tôi sẽ lọc ra nhiệm vụ đó.
Trên 256 nhiệm vụ được xác minh thủ công, chúng tôi đạt được độ chính xác căn chỉnh là 84,40%.
Thu thập và xác minh các yếu tố gây phân tâm
Chúng tôi thu thập 10 yếu tố phân tâm cho mỗi nhiệm vụ. Công cụ đánh lạc hướng là một tài liệu chứa thông tin tương tự với manh mối nhưng trỏ đến một câu trả lời khác.
Với các manh mối, câu hỏi và câu trả lời, nhân viên sẽ tìm kiếm và thu thập các đầu mối ứng cử viên. Sau đó, chúng tôi xác minh rằng các yếu tố gây phân tâm không vô tình chứa câu trả lời đúng: được cung cấp một tài liệu và câu trả lời, chúng tôi trích xuất bất kỳ sự xuất hiện nào của câu trả lời dưới bất kỳ hình thức nào. Nếu câu trả lời xuất hiện, chúng tôi sẽ lọc ra tác nhân gây phân tâm đó. Qua 256 nhiệm vụ, chúng tôi đạt được tỷ lệ liên kết 84% với tính năng lọc yếu tố gây phân tâm.
"Câu chuyện về Giáo đường Do Thái vĩ đại ở Rome
Giáo đường Do Thái vĩ đại ở Rome là một trong những giáo đường Do Thái ấn tượng nhất ở Ý được xây dựng sau cuộc Giải phóng năm 1870 cho người Do Thái ở La Mã…”
Xâu chuỗi
Sau khi một nhiệm vụ hoàn thành, chúng tôi tùy ý thêm chuỗi: lấy câu trả lời của một câu hỏi hiện có và nối nó với một nhiệm vụ mới với một câu trả lời cuối cùng mới.
manh mối: "Một cuộc xung đột bắt đầu ở một lãnh thổ phía tây nam trong cùng năm đó đã truyền cảm hứng cho một bộ phim hành động tổng hợp cuối thế kỷ 20 có nhiều nghệ sĩ biểu diễn gắn liền với một nhóm diễn xuất nổi tiếng thuộc nhiều thế hệ. Tác phẩm này đã đạt được vị trí dẫn đầu tại các rạp trong nước trong thời gian đầu ra mắt. Nhạc phim khác xa với những quy ước thể loại truyền thống, sử dụng nhạc cụ điện tử đương đại thay vì dàn nhạc cổ điển."
câu hỏi: "Tiêu đề của bộ phim này là gì?"
sự thật: "Young Guns"
Điều này cho phép chúng tôi kiểm soát số lượng bước nhảy của một nhiệm vụ nhất định. Ở đây, về cơ bản, chúng tôi lặp lại các bước 1-4 với một bước được sửa đổi đôi chút dành riêng cho việc bắc cầu.
Finance#
Chúng tôi sử dụng Hồ sơ của SEC từ năm 2025 để tạo ra các nhiệm vụ.
Xử lý trước dữ liệu
Chúng tôi lấy mẫu 1707 công ty ngẫu nhiên và sử dụng EdgarTools để phân tích cú pháp hồ sơ. Chúng tôi lọc các công ty có tài liệu giàu thông tin, cụ thể là hồ sơ 10-K và 20-F, đảm bảo có đủ tài liệu để tạo nhiệm vụ. Chúng tôi cũng lọc ra các tài liệu bị lỗi (được phát hiện thông qua các điểm đánh dấu nhị phân như %PDF- hoặc các phân phối ký tự bất thường) và các đoạn chủ yếu ở dạng bảng (được xác định bằng các phân số có khoảng trắng cao và mẫu căn chỉnh nhiều khoảng trắng).
Tạo câu hỏi và câu trả lời thông qua khám phá
Giống như web, chúng tôi cung cấp các công cụ đọc tài liệu và tìm kiếm nhân viên hỗ trợ nhưng giới hạn không gian tìm kiếm cho một công ty duy nhất. Chúng tôi cũng cung cấp các công cụ ngẫu nhiên hóa, xáo trộn các phần trong một công ty hoặc trong một tài liệu vì hồ sơ của SEC thiếu sự chồng chéo theo chủ đề thường thấy trên web. Trên web, người ta mong đợi tìm thấy thứ gì đó cho bất kỳ truy vấn nào; ở đây, trước tiên cần phải khám phá những gì có sẵn. Việc khám phá ít dựa vào truy vấn mà tập trung nhiều hơn vào việc thu thập.
Chúng tôi cũng sử dụng các chủ đề về sự thật ở đây, mặc dù hạn chế hơn để đảm bảo rằng chúng tôi thực sự có thể hình thành những loại câu hỏi đó từ hồ sơ của SEC.
truth_type: "date" company: "Boeing"
manh mối: "Một công ty đã kết thúc một đợt ngừng việc lớn vào cuối năm 2024 sau khi các thành viên công đoàn đại diện cho khoảng 1/5 lực lượng lao động ở một bang phía tây bắc bỏ phiếu thông qua một thỏa thuận mới. Thỏa thuận này thay thế một thỏa thuận cũ đã hết hạn vào đầu mùa thu năm đó. Các cổ đông của một nhà cung cấp lớn đã thông qua các điều khoản sáp nhập vào cuối mùa đông năm sau."
câu hỏi: "Thỏa thuận thương lượng tập thể mới hết hạn vào tháng và năm nào?"
sự thật: "Tháng 9 năm 2028"
Chúng tôi sử dụng các đoạn thay vì tài liệu đầy đủ vì một hồ sơ SEC trung bình là 31500 mã thông báo trên 7264 hồ sơ và thường chỉ có một đoạn mã có liên quan. Nếu chúng tôi đánh dấu toàn bộ tài liệu là tích cực thì các phần được truy xuất được đánh dấu là có liên quan thường sẽ bỏ lỡ thông tin hỗ trợ thực tế.
Xác minh các phần tích cực
Chúng tôi chạy quy trình trích xuất giống như trên web, trích xuất các cặp chunk_quote và clue_quote. Nếu bất kỳ đoạn tích cực nào thiếu dấu ngoặc kép phù hợp, chúng tôi sẽ lọc tác vụ. Chúng tôi đạt được sự đồng nhất 93% trong 100 nhiệm vụ.
Thu thập thêm các phần tích cực
Không giống như web, nơi chúng tôi xây dựng kho dữ liệu thông qua việc khám phá, ở đây chúng tôi sử dụng kho dữ liệu được xác định trước: tất cả hồ sơ SEC cho một công ty nhất định. Điều này có nghĩa là chúng tôi không khai thác một cách rõ ràng những yếu tố gây phân tâm vì các tài liệu tương tự đã có sẵn.
Tuy nhiên, thông tin giống nhau thường xuất hiện trên nhiều hồ sơ. Con số doanh thu trong 8-K cũng có thể xuất hiện trong 10-K của năm đó. Để giải quyết vấn đề này, chúng tôi chạy quy trình thu thập từng manh mối, tìm tất cả các phần thỏa mãn nó. Chúng tôi thấy rằng trên 17064 manh mối hỗ trợ, 67,32% trong số chúng xuất hiện trên nhiều đoạn và tài liệu. Chúng tôi xác minh những phần tích cực bổ sung này bằng cách sử dụng cùng một quy trình trích xuất.
Xâu chuỗi
Giống như với web, chúng tôi xâu chuỗi các nhiệm vụ bằng cách lấy câu trả lời hiện có và kết nối nó với dữ kiện từ một công ty khác. Bước bắc cầu rõ ràng này kết nối các công ty, sau đó chúng tôi lặp lại các bước 1-4 để hình thành câu hỏi mới.
manh mối: "Tháng và năm mà thỏa thuận thương lượng tập thể mới hết hạn cũng chính là tháng và năm mà khoản thế chấp của Công ty B tại số 280 Park Avenue đạt đến ngày đáo hạn cuối cùng. Cơ quan quản lý của Công ty B đã trải qua những thay đổi về số lượng thành viên vào giữa thập kỷ này, bổ sung thêm một thành viên độc lập mới có kinh nghiệm sâu rộng trong lĩnh vực tài chính vào đầu năm nay. Nhóm giám sát hiện bao gồm các cá nhân được chỉ định để đưa ra phán quyết độc lập về các vấn đề liên quan đến tổ chức, với phần lớn không giữ vai trò quản lý nào trong chính tổ chức đó."
câu hỏi: "Có bao nhiêu cá nhân cung cấp quyền giám sát độc lập hiện đang phục vụ trong cơ quan quản lý của tổ chức?"
truth: "5"
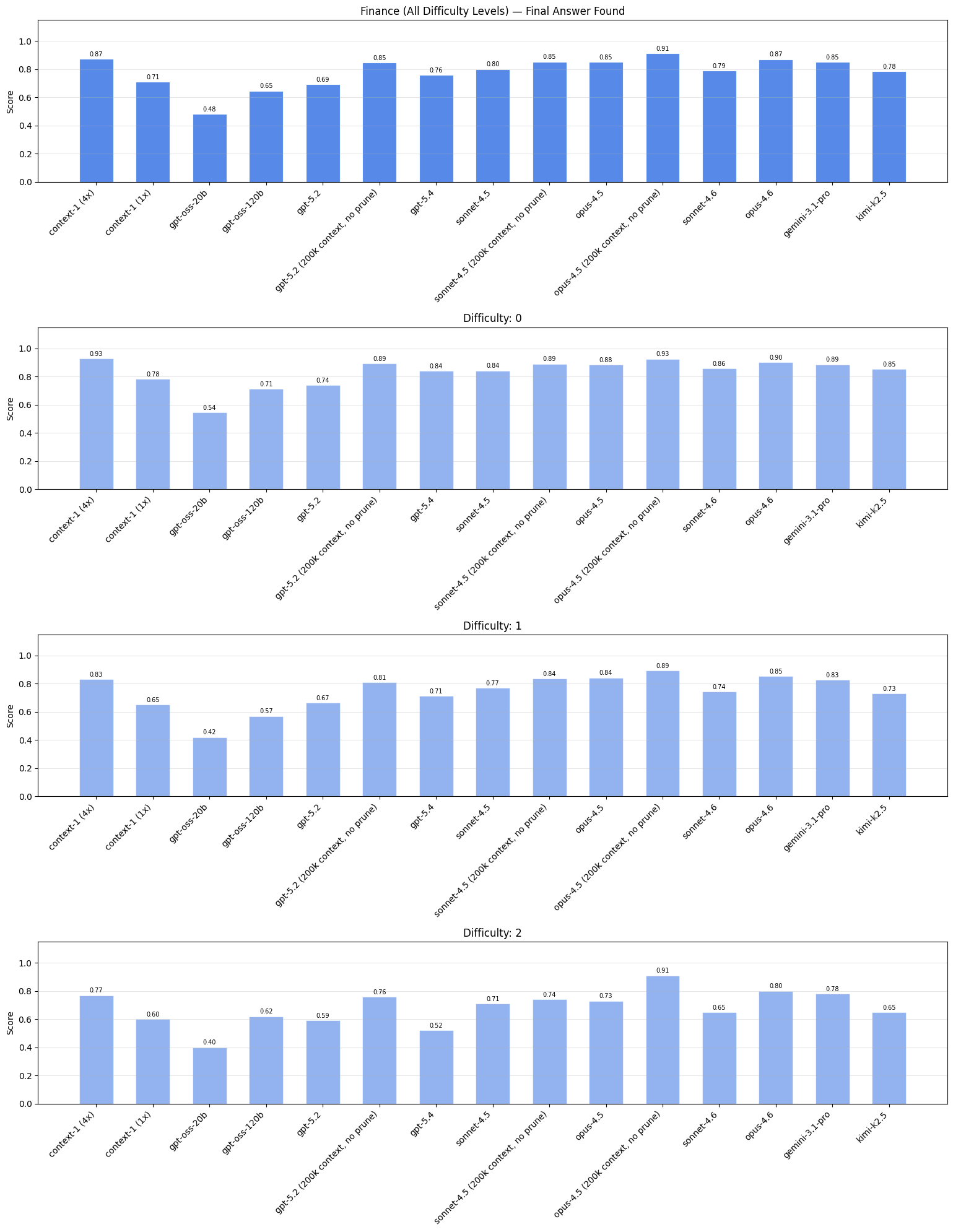
Pháp lý#
Chúng tôi lấy mẫu 1500 ấn phẩm bằng sáng chế của USPTO từ ngày 1 tháng 1 năm 2025 đến ngày 16 tháng 1 năm 2026 và các quyết định tương ứng của văn phòng không phải là quyết định cuối cùng. Cụ thể, chúng tôi tập trung vào 35 U.S.C. từ chối §102 và §103. Việc từ chối §102 lập luận rằng một tài liệu tham khảo tình trạng kỹ thuật duy nhất đã bộc lộ mọi yếu tố của sáng chế được yêu cầu bảo hộ. Việc từ chối §103 lập luận rằng tuyên bố, mặc dù không được tiết lộ giống hệt nhau, nhưng có thể rõ ràng đối với người có kỹ năng trong lĩnh vực này dựa trên một hoặc nhiều tài liệu tham khảo tình trạng kỹ thuật trước đó. Cả hai loại từ chối đều yêu cầu người kiểm tra phải tìm ra mối liên hệ rõ ràng giữa yêu cầu bảo hộ bị từ chối và các đoạn cụ thể trong tình trạng kỹ thuật đã biết, tạo ra mối quan hệ tài liệu cần thiết cho các tác vụ tìm kiếm nhiều bước.
Xử lý trước dữ liệu
Chúng tôi tải xuống các bằng sáng chế và tài liệu tương ứng của chúng từ USPTO chính thức. Đối với mỗi bằng sáng chế, chúng tôi trích xuất: yêu cầu bảo hộ, thông số kỹ thuật, bản tóm tắt, mẫu 892 (danh sách tài liệu tham khảo của người kiểm tra) và CTNF (hành động không phải cuối cùng của cơ quan kiểm tra). Khi tài liệu chỉ có ở dạng PDF, chúng tôi sẽ trích xuất thông qua DataLab.
Trích xuất và xác minh
Các tác vụ của Office thiếu định dạng chuẩn. Ví dụ: một giám khảo có thể tham khảo tình trạng kỹ thuật đã biết theo tên nhà phát minh, người khác theo số đơn đăng ký và ngôn ngữ khác nhau giữa các giám khảo. Chúng tôi sử dụng Claude Opus-4.5 để trích xuất các thành phần có cấu trúc từ mỗi lần từ chối:
- Số yêu cầu bị từ chối
- Tình trạng kỹ thuật được tham chiếu trước đó (được chuẩn hóa thành số đơn đăng ký bằng biểu mẫu 892)
- Lý do của người kiểm tra về lý do yêu cầu bồi thường bị từ chối
Chúng tôi xác minh độ chính xác của việc trích xuất thông qua ghi nhãn thủ công và đạt độ chính xác 98,3% qua 117 nhiệm vụ.
Thu thập tình trạng kỹ thuật trước đó và các nội dung tương tự bằng sáng chế
Sử dụng số đơn đăng ký từ quá trình trích xuất, chúng tôi truy xuất toàn bộ nội dung của các bằng sáng chế nghệ thuật trước đây được tham chiếu. Đối với các bằng sáng chế trong nước sau năm 2001, chúng tôi lấy trực tiếp từ USPTO. Đối với các bằng sáng chế cũ hoặc quốc tế, chúng tôi sử dụng Bằng sáng chế của Google thông qua SearchAPI. Chúng tôi trích xuất phần tóm tắt, mô tả và tuyên bố từ mỗi bằng sáng chế được tham chiếu.
Đối với những yếu tố gây phân tâm, chúng tôi thu thập các bằng sáng chế được trả về dưới dạng "tương tự" trong kết quả tìm kiếm Bằng sáng chế của Google. Những bằng sáng chế này có chung sự trùng lặp về chủ đề nhưng thực tế không được trích dẫn là tình trạng kỹ thuật đã có.
Tạo nhiệm vụ
Eask yêu cầu mô hình tìm ra tình trạng kỹ thuật đã có trước đó dựa trên mô tả khó hiểu về tuyên bố bị từ chối và lý do liên kết chúng. Bởi vì những lời từ chối của giám định viên tranh luận về sự giống nhau hơn là nêu rõ sự trùng khớp chính xác, nên chỉ riêng sự kết nối có thể không xác định được duy nhất tình trạng kỹ thuật đã có. Chúng tôi bổ sung các chi tiết phân biệt với tình trạng kỹ thuật đã biết (các tính năng kỹ thuật cụ thể) để đảm bảo câu trả lời có căn cứ duy nhất.
Vì các thẩm định viên bằng sáng chế đã thiết lập và chứng minh các mối liên hệ giữa tài liệu nên chúng tôi không tiến hành xác minh bổ sung đối với các cặp tài liệu nhiệm vụ; bản thân sự từ chối đóng vai trò là mức độ liên quan đã được chuyên gia xác minh.
Nhiệm vụ: [Yêu cầu]... Tuyên bố này bị từ chối dựa trên Điều khoản trước A. Prior Art A mô tả một hệ thống xác thực các hạng mục hữu hình bằng cách sử dụng phương pháp lưu trữ hồ sơ phi tập trung. Tài liệu này bao gồm việc thu thập dữ liệu phát xạ quang phổ từ vật liệu khi tiếp xúc với năng lượng, cùng với thông tin nhận dạng bổ sung. Ưu tiên A giải quyết yêu cầu bảo vệ mật mã thông qua mô tả bằng chứng xác minh bằng cách sử dụng thông tin xác thực mã hóa bất đối xứng được ghép nối, trong đó bằng chứng đó có thể được tạo và xác thực để xác nhận danh tính của các thực thể và nhận dạng duy nhất các mục vật lý. Tìm tác phẩm nghệ thuật phù hợp với những chi tiết này.
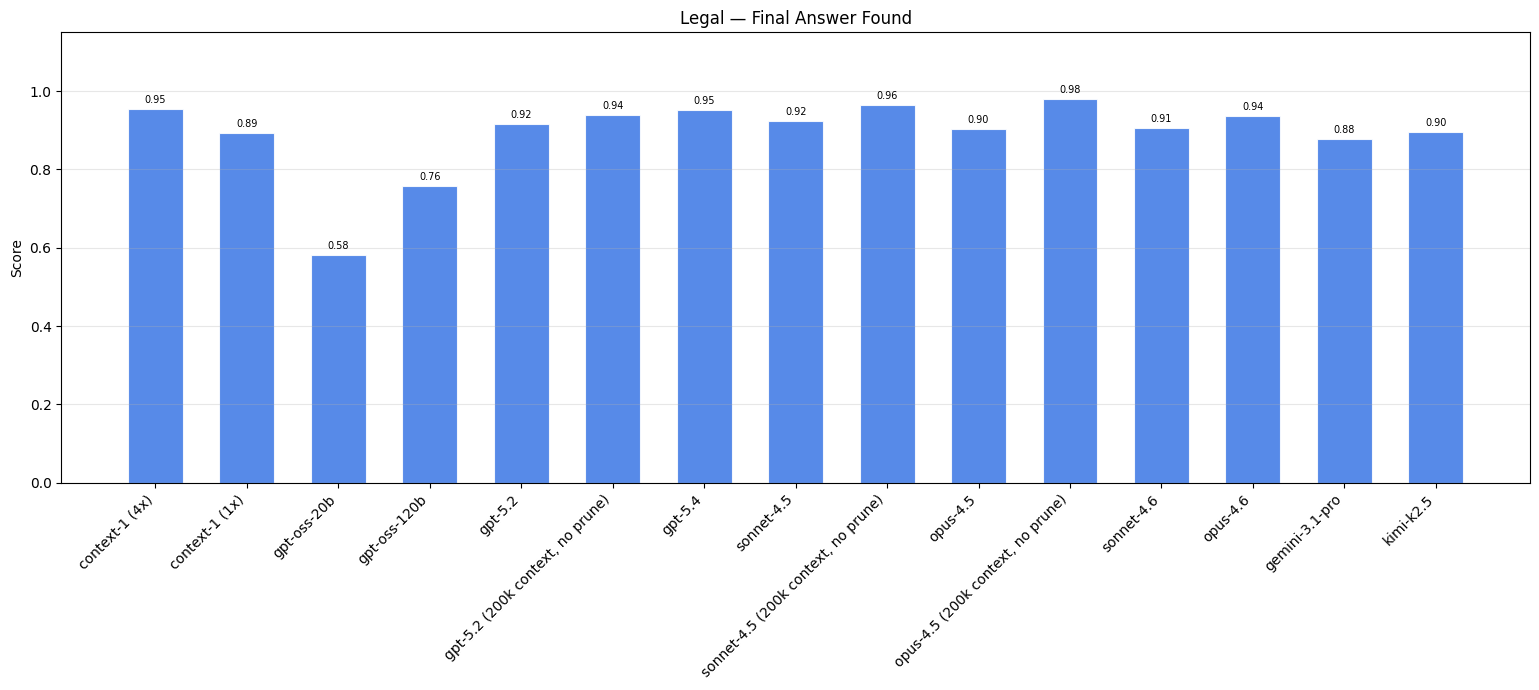
Email#
Xử lý trước dữ liệu
Chúng tôi sử dụng tập dữ liệu được xử lý trước của email Epstein, sau đó thực hiện xử lý thêm. Các chuỗi email thường xuất hiện nhiều lần với các biến thể nhỏ: một thư trả lời bổ sung, một bản sao được chuyển tiếp hoặc một chút khác biệt về định dạng.
Chúng tôi loại bỏ trùng lặp trong hai lần:
- Sử dụng khoảng cách Levenshtein đã chuẩn hóa (xóa các chuỗi có chênh lệch cấp độ ký tự dưới 10%)
- Sau đó sử dụng độ tương tự về ngữ nghĩa thông qua text-embedding-3-small (loại bỏ các luồng có độ tương tự cosine trên 0,8). Sau khi loại bỏ trùng lặp, chúng tôi giữ lại 984 chuỗi email duy nhất.
Tạo tác vụ
Chúng tôi cung cấp cho nhân viên các công cụ tìm kiếm để khám phá kho email. Tác nhân bắt đầu với một loạt email ngẫu nhiên để hiểu bối cảnh dữ liệu: tên định kỳ, vị trí, chủ đề và mô hình thời gian. Từ những điều này, nó xác định cơ hội cho các truy vấn nhiều chặng trải rộng trên các luồng: ví dụ: kết nối cuộc họp được thảo luận trong một luồng với các thỏa thuận đi lại trong một luồng khác.
truth_type: "tổ chức"
manh mối: “Một cá nhân từng làm việc trong lĩnh vực phát triển hệ điều hành đã chia sẻ một bài báo từ một phương tiện truyền thông về một loại tiền kỹ thuật số phi tập trung được chấp nhận ở thủ đô của quốc gia, lưu ý tỷ lệ phần trăm tăng cụ thể đối với số tiền nắm giữ của họ. Trong một chủ đề khác, một nhà báo của cùng cơ quan truyền thông này đã liên hệ với một chuyên gia pháp lý về một tuyên bố được đệ trình lên tòa án liên bang liên quan đến những cáo buộc về một cựu nguyên thủ quốc gia và thời gian ở trên một hòn đảo. Cơ quan truyền thông này cũng đăng tin về một cuốn sách kể lại mọi chuyện gây tranh cãi về một chính quyền, cuốn sách này được đề cập đến khi một trợ lý đề cập đến việc không thể in một bài báo do thiếu lượt đăng ký."
câu hỏi: "Tổ chức truyền thông nào đã xuất bản cả ba cuốn sách?"
sự thật: "Washington Post"
Chúng tôi xác minh các nhiệm vụ theo hai bước. Đầu tiên, chúng tôi chạy xác minh dựa trên trích xuất như trong miền web, lấy manh mối và trích dẫn tài liệu để xác nhận sự liên kết. Thứ hai, chúng tôi tiến hành kiểm tra tính mạch lạc: với các manh mối, câu hỏi, câu trả lời và tất cả các mục hỗ trợ cùng với nội dung của chúng, chúng tôi xác minh rằng các mục kết nối một cách hợp lý và tạo thành một đường dẫn mạch lạc đến câu trả lời cuối cùng. Nhiệm vụ phải vượt qua cả hai bước để được đưa vào tập dữ liệu cuối cùng.
Trong 200 nhiệm vụ, chúng tôi đạt được tỷ lệ liên kết 87,5% với nhãn của con người.
Thêm email của Enron
Chỉ riêng tập dữ liệu của Epstein là quá nhỏ để khó truy xuất; với ít email, ngay cả tìm kiếm đơn giản cũng dễ dàng tìm thấy các tài liệu liên quan. Chúng tôi bổ sung thêm các email từ kho dữ liệu Enron, thay thế tên và ngày tháng để khớp với nội dung phân phối được tìm thấy trong các email của Epstein. Điều này phục vụ hai mục đích: tăng kích thước kho văn bản từ 1.366 lên 396.510 khối và đưa ra các yếu tố phân tâm hợp lý có chung mẫu văn phong của email mục tiêu mà không chứa thông tin liên quan.
Việc thay thế tên và ngày đảm bảo các email tăng cường hòa hợp một cách tự nhiên với kho văn bản xác thực, ngăn các mô hình phân biệt mục tiêu thực với việc tăng cường chỉ dựa trên các đặc điểm bề mặt.
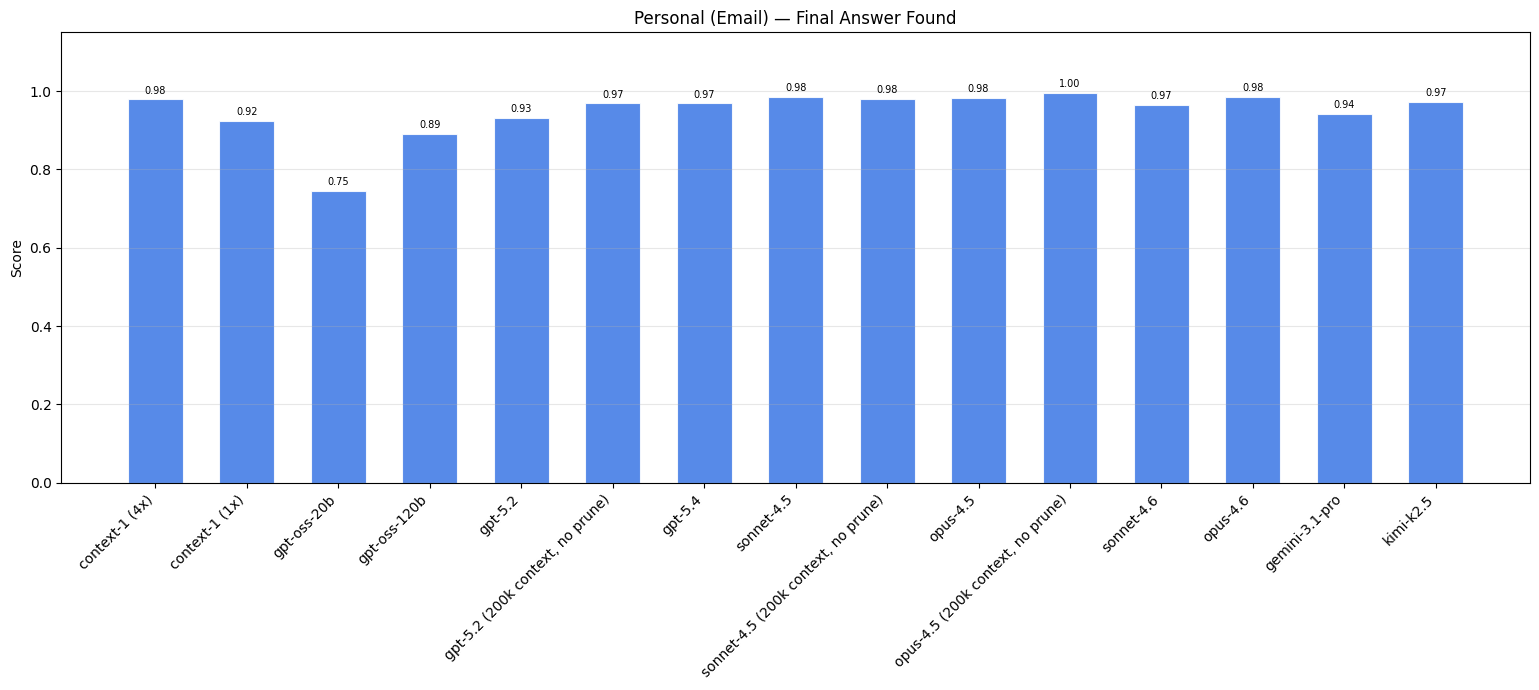
Lời nhắc#
Bạn là tác nhân phụ truy xuất trong hệ thống nhiều tác nhân. Vai trò cụ thể của bạn là xác định và truy xuất các tài liệu có liên quan nhất từ một kho tài liệu lớn để giúp một tổng đài viên khác trả lời các câu hỏi. Bạn KHÔNG tự trả lời câu hỏi — bạn chỉ tìm và truy xuất các tài liệu có liên quan.
Đây là truy vấn bạn cần tìm tài liệu cho:
Các công cụ có sẵn:
SearchTool: Tìm kiếm từ khóa và ngữ nghĩa kết hợpGrepTool: So khớp mẫu văn bảnReadDocument: Đọc các đoạn tài liệu cụ thể có vẻ hứa hẹn nhưng chưa đầy đủPruneChunksTool: Xóa các đoạn không liên quan để giải phóng không gian ngữ cảnh
Quy trình của bạn:
- Chia truy vấn thành các khái niệm chính và nhu cầu thông tin (liệt kê rõ ràng từng khái niệm)
- Đối với mỗi khái niệm chính, hãy phát triển một chiến lược tìm kiếm cụ thể nhắm vào khái niệm đó
- Hãy xem xét loại tài liệu và bằng chứng nào sẽ hữu ích nhất để trả lời truy vấn này
- Lập kế hoạch cho một số chiến lược tìm kiếm riêng biệt, không trùng lặp để tiếp cận câu hỏi từ các góc độ khác nhau
- Sau đó thực hiện tìm kiếm của bạn bằng cách sử dụng nhiều lệnh gọi công cụ song song
Suy nghĩ của bạn: Sau mỗi vòng tìm kiếm, hãy cân nhắc:
- Tôi biết gì? Liệt kê các chủ đề, chủ đề hoặc khía cạnh chính của câu hỏi mà tài liệu hiện đang truy xuất của bạn đề cập đến.
- Tôi nên tìm kiếm gì tiếp theo? Xem xét một cách có hệ thống những phương pháp tìm kiếm, từ khóa hoặc loại tài liệu nào bạn chưa thử có thể mang lại thông tin có giá trị.
- Tôi nên cắt tỉa những gì? Nếu bạn cắt bớt nhiều phần, bạn sẽ loại bỏ những gì và những tìm kiếm mới nào bạn sẽ ưu tiên?
- Tôi có đủ thông tin không? Với mức độ phức tạp và yêu cầu của câu hỏi, bạn có đủ thông tin để giúp trả lời câu hỏi đó không hoặc có những khoảng trống quan trọng không?
Quyết định xem có cần tìm kiếm thêm hay không (đảm bảo chúng sử dụng các phương pháp thực sự khác nhau và không trùng lặp các tìm kiếm trước đó). Tránh mắc kẹt với một chiến lược tìm kiếm duy nhất — nếu một cách tiếp cận không mang lại kết quả, hãy cắt bớt và thử các cách tiếp cận khác.
Chiến thuật cần cân nhắc:
- Khi truy vấn không thành công, hãy thử các cách tiếp cận hoặc từ khóa khác
- Tránh tìm kiếm trùng lặp hoặc dư thừa
- Thực hiện nhiều lệnh gọi công cụ song song khi có thể
- Nếu ngân sách mã thông báo của bạn sắp đạt đến ngưỡng, hãy chủ động cắt bớt những phần không liên quan để tránh hết ngữ cảnh
- Tập trung vào việc thu thập càng nhiều thông tin liên quan càng tốt; nhiều quan điểm về cùng một chủ đề giúp xác nhận các phát hiện
- Theo dõi bằng chứng văn bản rõ ràng thay vì suy đoán
Định dạng đầu ra: Trình bày kết quả cuối cùng của bạn theo thứ tự từ phù hợp nhất đến ít liên quan nhất:
Kết quả cuối cùng của bạn chỉ được bao gồm tối đa N kết quả tài liệu được xếp hạng ở định dạng đã chỉ định và không được trùng lặp hoặc lặp lại bất kỳ công việc lập kế hoạch hoặc đánh giá tìm kiếm nào mà bạn đã thực hiện trong phần tư duy.
Nếu bạn thấy công việc của chúng tôi hữu ích, vui lòng cân nhắc trích dẫn chúng tôi:
Tác giả: philip1209