BIO: Bộ đồng xử lý I/O Bao
BIO: The Bao I/O Coprocessor
Bao I/O Coprocessor (BIO) là một bộ xử lý phụ I/O mới được thiết kế cho chip Baochip-1x SoC. Mục tiêu của nó là xử lý I/O một cách có thể dự đoán được (deterministic). Lấy cảm hứng từ PIO của Raspberry Pi, BIO đã rút kinh nghiệm từ việc PIO tốn nhiều tài nguyên FPGA và có hạn chế về thời gian, nên BIO chọn một kiến trúc đơn giản và hiệu quả hơn. Các developer có thể tận dụng BIO để giảm tải các tác vụ I/O khỏi CPU chính, đạt được thời gian thực thi có thể dự đoán được, điều này rất quan trọng cho các ứng dụng real-time. Các bạn có thể khám phá khả năng của BIO thông qua các ví dụ code assembly và C được cung cấp.
BIO là bộ đồng xử lý I/O trong Baochip-1x, một SoC 22nm mã nguồn mở mà tôi đã giúp thiết kế. Bạn có thể đọc thêm về nền tảng của Baochip-1x tại đây hoặc lấy bảng đánh giá tại Crowd Supply. Trong này...
BIO là bộ đồng xử lý I/O trong Baochip-1x, một SoC 22nm mã nguồn mở mà tôi đã giúp thiết kế. Bạn có thể đọc thêm về Nền tảng của Baochip-1x tại đây hoặc nhận bảng đánh giá tại Crowd Cung cấp.
Trong bài đăng này, tôi sẽ nói về nguồn gốc của BIO, bắt đầu bằng cách nghiên cứu chi tiết về Raspberry Pi PIO làm tài liệu tham khảo, trước khi đi sâu vào kiến trúc của BIO. Sau đó tôi sẽ làm việc qua ba ví dụ lập trình của BIO, hai ví dụ ở dạng hợp ngữ và một ở dạng C. Nếu tất cả những gì bạn quan tâm là cách sử dụng BIO, bạn có thể bỏ qua các chi tiết cơ bản và xem hết nửa bài để đến phần có tiêu đề “Thiết kế BIO” hoặc đi thẳng vào các ví dụ về mã.
Nền tảng
Bộ đồng xử lý I/O giảm tải các tác vụ I/O từ lõi CPU chính. Các CPU chính phải xử lý nhiều mức độ ưu tiên bằng cách sử dụng một số dạng đa tác vụ, dẫn đến thời gian phản hồi không thể đoán trước. Những phản ứng không thể đoán trước này biểu hiện dưới dạng sự bồn chồn không mong muốn hoặc sự chậm trễ trong các phản hồi quan trọng. Việc sử dụng bộ đồng xử lý cho tác vụ I/O sẽ đạt được tính xác định gần giống với máy trạng thái phần cứng chuyên dụng trong khi vẫn duy trì tính linh hoạt của CPU có mục đích chung.
Một ví dụ nổi tiếng về bộ đồng xử lý I/O là PIO của Raspberry Pi. Nó bao gồm một bộ gồm bốn “bộ xử lý”, mỗi bộ có chín lệnh, với bộ nhớ lệnh gồm 32 vị trí, được điều chỉnh cao để mang lại sự linh hoạt cao độ với thao tác GPIO chính xác theo chu kỳ dễ dàng. Ví dụ: triển khai SPI với đồng hồ, vào và ra bao gồm một công cụ sửa đổi cấu hình cộng với chỉ hai hướng dẫn được thực thi trong một "vòng lặp hiệu quả" do các tác dụng phụ có thể định cấu hình có sẵn trong cấu hình PIO, chẳng hạn như tự động bọc mã và quản lý FIFO:
".side_set 1",
"out pins, 1 side 0 [1]",
"in pins, 1 side 1 [1]",Tôi muốn có một số dạng bộ đồng xử lý I/O trong Baochip, vì vậy tôi đã nghiên cứu PIO theo cách tốt nhất mà tôi biết – bằng cách sao chép nó. Tôi đã phân nhánh fpga_pio của Lawrie Griffith làm điểm bắt đầu và thực hiện rất nhiều thử nghiệm hồi quy cũng như mô phỏng chi tiết để loại bỏ tất cả các trường hợp góc bị thiếu. Bạn có thể tìm thấy những gì tôi cho là khá gần với lõi PIO thế hệ RP2040 tuân thủ đầy đủ thông số kỹ thuật trong kho lưu trữ github này.
Bài học rút ra từ PIO
Sau khi xây dựng một bản sao PIO và biên dịch nó cho FPGA, tôi rất ngạc nhiên khi thấy rằng PIO tiêu tốn một lượng tài nguyên lớn đến mức đáng kinh ngạc. Nếu bạn đang nghĩ đến việc sử dụng nó trong FPGA, tốt hơn hết bạn nên bỏ qua PIO và chỉ triển khai bất kỳ thiết bị ngoại vi nào bạn muốn trực tiếp bằng RTL.
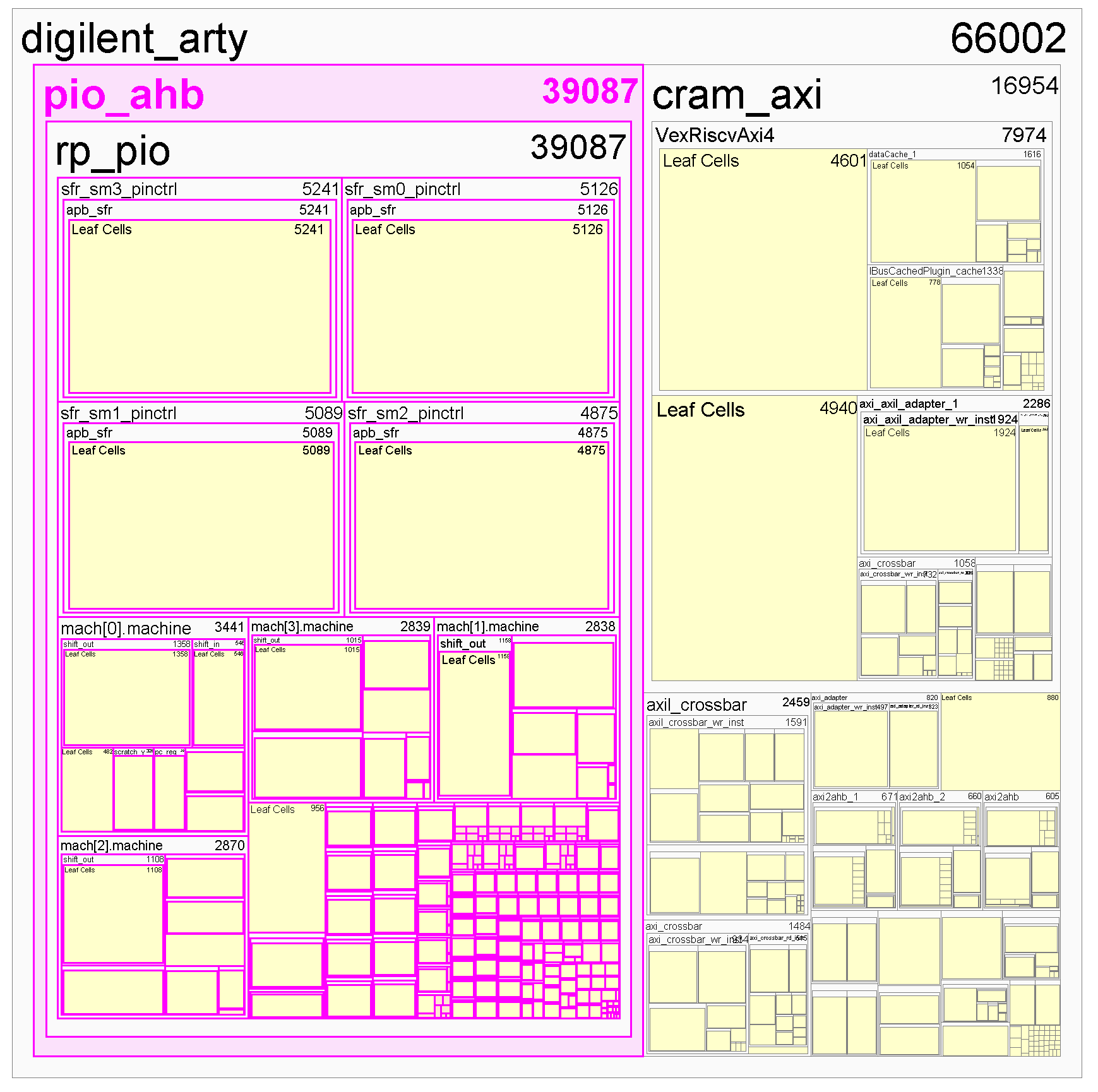
Trên đây là bản đồ tài nguyên phân cấp của lõi PIO được đặt và định tuyến nhắm mục tiêu XC7A100 FPGA. Tôi đã đánh dấu phần bị PIO chiếm giữ bằng màu đỏ tươi. Nó sử dụng hơn một nửa FPGA, thậm chí nhiều hơn cả lõi CPU RISC-V (khối “VexRiscAxi4” ở bên phải)! Mặc dù chỉ có thể chạy chín lệnh nhưng mỗi lõi PIO bao gồm khoảng 5.000 ô logic. So sánh điều này với CPU VexRiscv, nếu bạn không tính I-cache và D-cache thì chỉ tiêu thụ 4600 ô logic.
Hơn nữa, đường tới hạn của lõi PIO kém hơn ít nhất gấp 2 lần so với VexRiscv. Thiết kế FPGA dễ dàng đóng thời gian ở mức 100 MHz chỉ với VexRiscv, nhưng với lõi PIO đã có sẵn, nó gặp khó khăn trong việc đóng thời gian ở mức 50 MHz.
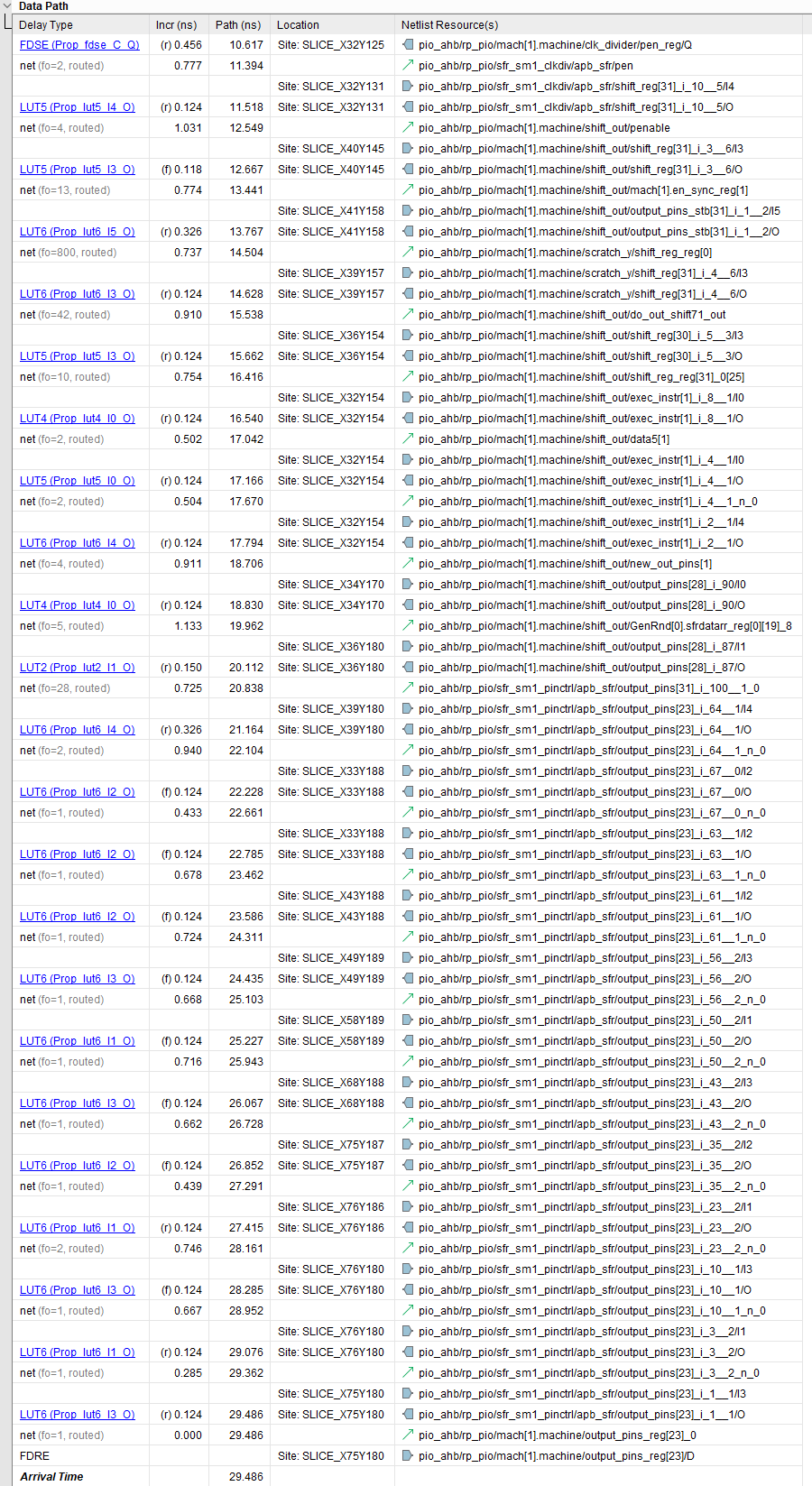
Việc xem nhanh kết quả phân tích thời gian trong Vivado sẽ cho chúng ta một số manh mối về điều gì đang diễn ra.

Bên trên là đường dẫn logic được tách biệt như một trong những đường dẫn kết hợp dài nhất trong thiết kế và bên dưới là báo cáo chi tiết về các ô.
Vấn đề tóm lại là một lập luận gần như lâu đời như chính kiến trúc máy tính: cuộc tranh luận giữa CISC và RISC. Mặc dù PIO “chỉ” có chín hướng dẫn nhưng mỗi hướng dẫn lại vô cùng phức tạp. Một lệnh có thể được điều chỉnh để thực hiện tất cả những điều sau trong một chu kỳ:
- Một số thao tác danh nghĩa (JMP, WAIT, IN, OUT, PUSH, PULL MOV, IRQ, SET)
- Tăng bộ đếm chương trình…nhưng cũng đưa nó trở lại vị trí đặt trước nếu đạt được một điều kiện nhất định
- Xoay dữ liệu thông qua bộ dịch chuyển thùng 32 bit đến/từ một nguồn/đích tiềm năng
- Kiểm tra ngưỡng và quyết định xem có nạp thêm FIFO đầu vào/đầu ra hay không, các FIFO này có thể được nối hoặc không
- Có khả năng đặt một mã pin khác ở bên cạnh
- Tính toán các cờ ngắt và có khả năng thay đổi bộ đếm chương trình dựa trên kết quả
- Giải quyết xung đột mức độ ưu tiên trong trường hợp nhiều máy cố gắng chạm vào tài nguyên dùng chung
Hóa ra, rất nhiều vùng logic được sử dụng bởi các bộ dịch chuyển cần thiết để xử lý tính linh hoạt của các tùy chọn ánh xạ chốt. Nhìn vào thanh ghi PINCTRL sẽ thấy bốn bộ chọn “cơ sở” ngụ ý bốn bộ chuyển đổi thùng 32 bit, cộng với một chiều dài chạy có thể định cấu hình được gắn vào phần cuối của bộ chuyển đổi. Về cơ bản, phần “xoay + mặt nạ” của PIO tiêu tốn nhiều diện tích logic hơn chính máy trạng thái và việc phải gộp một bộ mặt nạ xoay + phân chia đồng hồ và tính toán ngưỡng FIFO vào một chu kỳ duy nhất là khá tốn kém về mặt thời gian. Tính linh hoạt của các tùy chọn của PIO về cơ bản có nghĩa là bạn đang mô phỏng một mạng định tuyến giống như FPGA trên một FPGA – do đó sẽ kém hiệu quả.
Có lẽ việc triển khai PIO của tôi thiếu một số tối ưu hóa giúp nó hiệu quả hơn. Tuy nhiên, tôi khá cẩn thận để duy trì độ chính xác theo chu kỳ và khi làm như vậy, tôi phải tránh những hoạt động tối ưu hóa có thể ảnh hưởng đến độ chân thực, ngay cả khi điều đó có thể cải thiện việc đóng thời gian.
Các bài học rút ra từ nghiên cứu FPGA cũng được chuyển sang quy trình ASIC. Sau khi đẩy cơ sở mã thông qua cùng một chuỗi công cụ được sử dụng để tạo Baochip-1x, số lượng cổng và độ trễ cũng lớn và “chậm” tương tự. Tôi sử dụng “chậm” trong dấu ngoặc kép vì nó vẫn còn rất nhanh cho những gì nó cần làm – hơi nhanh so với GPIO – nó chỉ chậm so với những gì bạn có thể làm trong ASIC.
Lời cảnh báo dành cho người dùng PIO
Dường như có ít nhất một bằng sáng chế đang cản trở PIO. Về mặt chính sách, tôi không đọc các bằng sáng chế, do đó tôi không thể phản đối liệu việc triển khai lại có vi phạm bất kỳ bằng sáng chế nào hay không. Tuy nhiên, đây là tín hiệu từ nền tảng Raspberry Pi rằng họ không hoan nghênh việc triển khai lại khối của họ bằng nguồn mở. Họ không buộc tôi phải gỡ bỏ mã nguồn của khối, nhưng bất kỳ ai cố gắng sử dụng mã tham chiếu mà tôi đã chia sẻ cũng nên lưu ý đến vấn đề này và xem xét các rủi ro khi kết hợp nó vào sản phẩm.
Một cách tiếp cận thay thế
Quá trình đào tạo chuyên môn và ảnh hưởng nghề nghiệp của tôi đã đưa tôi vững chắc vào nhóm kiến trúc máy tính RISC. Cố vấn tiến sĩ của tôi, Tom Knight, sẽ nhắc nhở chúng tôi rằng "đó là do dây điện, đồ ngốc!" khi nghĩ về kiến trúc phần cứng; rằng sự phức tạp ngày nay là trách nhiệm pháp lý trong tương lai (còn được gọi là “thiết kế đơn giản dễ chuyển sang quy trình mới hơn”) và tính mới của phần cứng sẽ vô giá trị nếu không có công cụ phần mềm tốt.
Kết quả là, PIO, mặc dù khá gọn gàng như một khái niệm tinh thần trừu tượng, nhưng thực sự khiến tôi khó chịu với tư cách là người thực hiện. Bộ chuyển số thùng có phần cứng đắt tiền. Có rất nhiều dây trong bộ chuyển thùng và tôi đã được huấn luyện cách sử dụng dây một cách có chủ ý. Hơn nữa, tập lệnh tùy chỉnh khó mã hóa, đặc biệt với tất cả các cài đặt ngoài phạm vi có thể ảnh hưởng đến việc thực thi lệnh. Ngay cả sau khi dành vài tháng để viết rất nhiều mã PIO, tôi vẫn gặp khó khăn để mọi thứ hoạt động trong lần thử đầu tiên và tôi chủ yếu dựa vào mô phỏng Verilator để gỡ lỗi bất kỳ mã PIO tùy chỉnh nào (Tôi không biết các lập trình viên khác của PIO làm gì để gỡ lỗi nội dung của họ. Tuy nhiên, có lẽ một trong những tiện ích lớn nhất của việc triển khai lại PIO là bạn thực sự có thể gỡ lỗi mã PIO của mình trong mô phỏng bằng trình xác minh!).
Điểm mấu chốt là sau khi làm tất cả công việc này, tôi cảm thấy kiệt sức hơn là được tiếp thêm sức mạnh: PIO không thú vị như tôi mong muốn.
Rồi tôi nảy ra một suy nghĩ. Tại sao không thử tưởng tượng một thế giới nơi chúng ta có phiên bản PIO hoàn toàn RISC? Vì vậy, “BIO” đã ra đời.
RISC có sự thay đổi
Hóa ra lõi RISC-V 32-bit có thể khá nhỏ gọn. PicoRV32 của Claire Xenia Wolf là một ví dụ tuyệt vời về điều này: lõi có thể ánh xạ xuống mức nhỏ tới 761 lát LUT và đạt tốc độ >200 MHz trên FPGA Xilinx 7 dòng điển hình. Mặc dù vậy, nó có thể chạy bộ hướng dẫn RV32I đầy đủ, nghĩa là bạn có thể tận dụng công cụ phần mềm tuyệt vời có sẵn cho hệ sinh thái RISC-V.
Tất nhiên là có những nhược điểm. Một là bạn hiện đang ở trong tình trạng khó khăn khi đếm chu kỳ nếu bạn muốn I/O của mình lật vào một thời điểm xác định rõ ràng. Một vấn đề khác là chỉ cần nối các lõi với các thanh ghi I/O với hướng dẫn tải/lưu trữ có nghĩa là bạn có bốn lõi cạnh tranh cho một dãy các thanh ghi GPIO, điều này có thể dẫn đến nhiều tính chất không xác định, trạng thái chờ và các vấn đề phức tạp khác. Do đó, người ta không thể chỉ gắn bốn lõi PicoRV32 lên bus AXI và GPIO bit-bang rồi mong đợi kết quả giống như PIO.
May mắn thay, tôi có một mẹo nhỏ trong tay. Nhiều thập kỷ trước, tôi đã thiết kế kiến trúc CPU có tên “ADAM” cho luận án Tiến sĩ của mình. Hầu hết các chi tiết đều không liên quan ngoại trừ một thủ thuật: thay vì chỉ đặt các thanh ghi vào tệp đăng ký, tôi ánh xạ một phần trong số chúng vào hàng đợi, khiến chúng tiếp nhận ngữ nghĩa chặn toàn bộ/trống ở cấp độ kiến trúc. Thủ thuật này cho phép thực hiện nhiều thứ, từ tính song song ở cấp độ lệnh nhẹ cho đến khả năng giao tiếp nhanh, độ trễ thấp giữa bộ xử lý và tài nguyên I/O. Đây là thuộc tính thứ hai mà chúng tôi sử dụng ở đây.
Thiết kế BIO
Thiết kế BIO bắt đầu với PicoRV32 được định cấu hình là RV32E. Ở chế độ này, thay vì có đầy đủ 32 thanh ghi (bao gồm cả thanh ghi 0), bạn nhận được 16: chỉ r0 – r15 chính thức là một phần của đặc tả RV32E. Sau đó, tôi lạm dụng r16 – r31 để ánh xạ vào một tập hợp “hàng đợi đăng ký” cũng như các nguyên hàm truy cập và đồng bộ hóa GPIO. Dưới đây là sơ đồ của bộ thanh ghi cuối cùng được hiển thị trên mỗi lõi trong số bốn lõi RV32E.
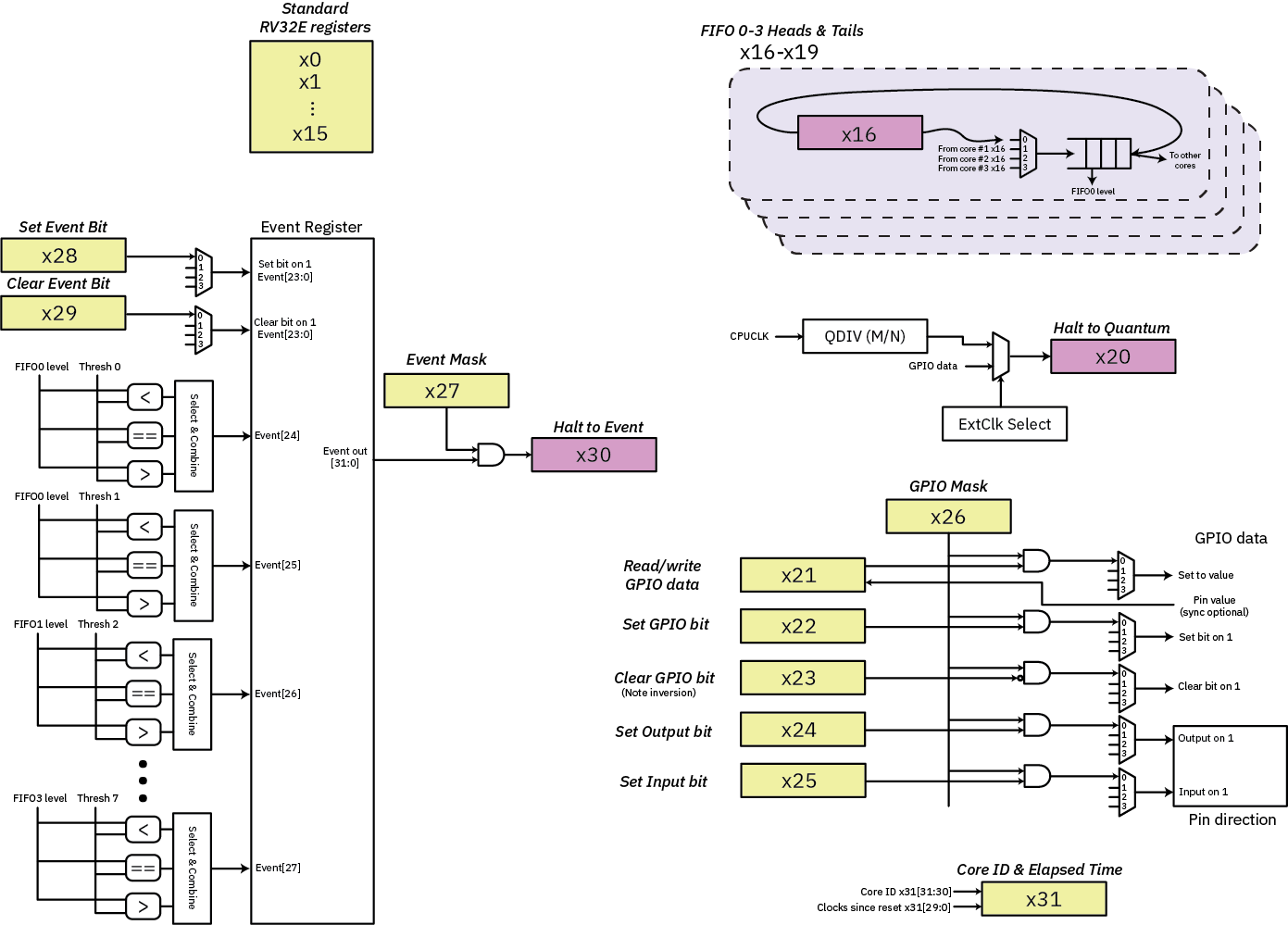
Các hình chữ nhật màu buff là các thanh ghi có ngữ nghĩa đọc/ghi thông thường, trong khi các hình chữ nhật màu hoa oải hương là các thanh ghi có thể chặn việc thực thi CPU dựa trên các điều kiện khác nhau. Dưới đây là mô tả về sổ đăng ký "ngân hàng cao" trong văn bản:
FIFO - Truy cập đầu/đuôi fifo sâu 8. Lõi dừng khi tràn/tràn.
- x16 r/w fifo[0]
- x17 r/w fifo[1]
- x18 r/w fifo[2]
- x19 r/w fifo[3]
Lượng tử - lõi sẽ dừng cho đến khi xảy ra xung chia xung nhịp do máy chủ định cấu hình,
hoặc một sự kiện bên ngoài xảy ra trên chân GPIO do máy chủ chỉ định.
- x20 -/w dừng ở mức lượng tử
GPIO - lưu ý ngữ nghĩa rõ ràng trên 0 để xóa bit cho các chân dữ liệu!
Điều này được thực hiện để chúng ta có thể thực hiện dịch chuyển và di chuyển mà không cần đảo ngược
bitbang một pin dữ liệu. Hướng vẫn giữ một ý nghĩa "thông thường" hơn
trong đó việc viết `1` để xóa hoặc đặt sẽ gây ra hành động,
vì việc chuyển đổi hướng của chốt ít có khả năng nằm trong vòng lặp bên trong chặt chẽ.
- x21 r/w ghi: (x26 & x21) -> chân gpio; đọc: chân gpio -> x21
- x22 -/w (x26 & x22) -> a `1` trong x22 sẽ đặt mã pin tương ứng trên gpio
- x23 -/w (x26 & ~x23) -> a `0` trong x23 sẽ xóa mã pin tương ứng trên gpio
- x24 -/w (x26 & x24) -> a `1` trong x24 sẽ tạo đầu ra cho mã pin gpio tương ứng
- x25 -/w (x26 & x25) -> a `1` trong x25 sẽ biến mã gpio tương ứng thành đầu vào
- x26 r/w mặt nạ đầu ra hành động GPIO
Sự kiện - hoạt động trên sổ đăng ký sự kiện được chia sẻ. Các bit [31:24] được nối cứng với FIFO
cờ cấp độ, được cấu hình bởi máy chủ; ghi vào bit [31:24] bị bỏ qua.
- x27 -/w che dấu các bit nhạy cảm sự kiện
- x28 -/w `1` sẽ đặt bit sự kiện tương ứng. Chỉ [23:0] mới có dây.
- x29 -/w `1` sẽ xóa bit sự kiện tương ứng. Chỉ [23:0] mới được nối dây.
- x30 r/- tạm dừng cho đến khi ((x27 & sự kiện) != 0) và trả về giá trị `events` không được che dấu
ID lõi & gỡ lỗi:
- x31 r/- [31:30] -> ID lõi; [29:0] -> đồng hồ cpu kể từ khi đặt lại
Khía cạnh thú vị nhất của bộ thanh ghi mở rộng là các thanh ghi chặn. Đây là những thanh ghi mà lệnh hiện tại đang được thực thi có thể không ngừng hoạt động cho đến khi đáp ứng được một số điều kiện liên quan đến FIFO. Ví dụ: đọc bất kỳ x16-x19 nào đều cố gắng loại bỏ một giá trị khỏi một trong các FIFO được chia sẻ. Nếu FIFO đích trống thì quá trình thực thi CPU sẽ dừng lại cho đến khi một giá trị xuất hiện trong FIFO. Tương tự, việc ghi vào x16-x19 chỉ hoàn thành nếu FIFO có khoảng trống. Sau khi FIFO đầy, quá trình thực thi sẽ tạm dừng cho đến khi có ít nhất một mục nhập bị người tiêu dùng khác sử dụng hết.
Mục tiêu quan trọng đối với bất kỳ bộ xử lý I/O nào là đáp ứng các đảm bảo cứng rắn về thời gian thực. Một ví dụ đơn giản là đảm bảo trình tự kịp thời của các sự kiện đều đặn. Để hỗ trợ việc này, các thanh ghi x20 và x30 được nối dây theo cách có thể dừng việc thực thi CPU cho đến khi đáp ứng điều kiện không đồng bộ.

Trên: minh họa cách sử dụng quyền truy cập vào x20 để tự động lên lịch hoạt động của CPU theo các khoảng thời gian định lượng.
Trong trường hợp x20, CPU sẽ dừng cho đến khi một lượng tử thời gian trôi qua (được xác định bằng bộ chia xung nhịp phân đoạn bên trong hoặc nguồn xung nhịp bên ngoài từ chân GPIO). Trong trường hợp x30, CPU sẽ tạm dừng cho đến khi đáp ứng một điều kiện “sự kiện” (chẳng hạn như FIFO đạt đến mức đầy nhất định).
Thanh ghi "dừng lượng tử" có thể loại bỏ nhu cầu đếm chu kỳ trong mã khi lượng tử được đảm bảo dài hơn đường dẫn mã dài nhất giữa các lần ghi vào thanh ghi lượng tử. Điều này thường xảy ra với các giao thức hoạt động ở tốc độ đơn MHz trở xuống.
BIO cũng có khả năng thực hiện DMA thông qua tiện ích mở rộng “BDMA”. Tiện ích mở rộng này cho phép các đơn vị tải/lưu trữ của lõi PicoRV32 truy cập vào bus của SoC, với trình phân giải ưu tiên “ngu ngốc” trong trường hợp có các quyền truy cập cạnh tranh (lõi được đánh số thấp nhất luôn thắng; các lõi khác dừng lại). Việc bổ sung khả năng này cho phép BIO cũng hoạt động như một công cụ DMA thông minh để truyền dữ liệu đến và đi từ bộ nhớ chính, nhưng nó tăng thêm khoảng 50% kích thước của lõi BIO cơ sở. Nó không nhanh bằng các công cụ DMA nhanh nhất nhưng có thể thực hiện các chuyển đổi truy cập dữ liệu khá phức tạp, chẳng hạn như thu thập phân tán, xoay và xáo trộn/xen kẽ với một số tính năng thông minh để xử lý các trường hợp ngoại lệ và trường hợp đặc biệt.
Xin lưu ý thêm, quyền truy cập vào bộ nhớ chính bị chặn bởi danh sách trắng, theo mặc định là trống. Vì vậy, trước khi thử sử dụng tính năng BDMA, trước tiên người ta phải khai báo vùng bộ nhớ nào mà BIO được phép truy cập. Điều này cũng giúp ngăn chặn việc lạm dụng BDMA như một phương pháp để vượt qua các tính năng bảo mật của CPU chủ.
Ví dụ về mã BIO đơn giản
Để giúp minh họa ý chính về cách sử dụng các thanh ghi FIFO trong BIO, chúng ta hãy xem một ví dụ về hoạt động DMA; chúng tôi cũng sẽ giả định rằng danh sách trắng đã được thiết lập bởi lõi Vexriscv. Trong ví dụ này, chúng tôi phân tách hoạt động DMA thành hai phần: một lõi BIO được sử dụng để tìm nạp và lưu trữ bộ nhớ, còn lõi BIO khác được sử dụng để tạo địa chỉ.
Mã lõi BIO tìm nạp/lưu trữ khá đơn giản: chỉ là một chuỗi tải (lw) và lưu trữ (sw) với địa chỉ offset có nguồn gốc từ x16 hoặc x17 (tương ứng là FIFO0 và FIFO1):
bio_code!(dma_mc_copy_code, DMA_MC_COPY_START, DMA_MC_COPY_END,
"20:",
"lw a0, 0(x16)", // chưa được kiểm soát để có hiệu suất cao hơn
"sw a0, 0(x17)",
"lw a0, 0(x16)",
"sw a0, 0(x17)",
"lw a0, 0(x16)",
"sw a0, 0(x17)",
"lw a0, 0(x16)",
"sw a0, 0(x17)",
"j 20b"
);Đoạn mã này được gói trong macro Rust. Vì BIO chủ yếu sử dụng RV32E có sẵn nên chúng tôi có thể tận dụng các công cụ RISC-V hiện có. Trong trường hợp này, macro bio_code! chú thích mã lắp ráp Rust với các mã định danh “DMA_MC_COPY_START” và “DMA_MC_COPY_END”. Những mã nhận dạng này cho phép một trình tải mã riêng biệt xác định cơ sở và phạm vi của khối nhị phân đã được tập hợp để có thể sao chép nó vào bộ nhớ BIO trong thời gian chạy.
Trong ví dụ trên, CPU sẽ dừng ở lệnh đầu tiên vì x16 trống, chờ địa chỉ được tạo cho nó.
Trong khi đó, lõi CPU thứ hai chạy đoạn mã sau:
Mã này khiến CPU phải đợi cho đến khi các tham số của DMA được máy chủ đưa ra, trong trường hợp này, bằng cách ghi địa chỉ nguồn vào hàng đợi FIFO2 (xuất hiện theo thứ tự thành x18), theo sau là # byte để sao chép. Khi những phần dữ liệu này được cung cấp, lõi sẽ tạo ra nhiều địa chỉ nhất có thể, lấp đầy x16 bằng địa chỉ nguồn, cho đến khi x16 đầy và khối trình tạo hoặc số byte cần sao chép đã được đáp ứng.
CPU thứ ba được sử dụng để chạy một khối mã rất giống, đọc địa chỉ đích từ FIFO3 và tạo địa chỉ ghi vào x17.
Ví dụ đơn giản này cho thấy cách chúng ta có thể sử dụng ba lõi CPU đơn giản và khiến chúng thực thi song song một cách hiệu quả, dẫn đến băng thông DMA cao hơn mức mà một lõi đơn có thể đạt được.
Chi tiết về FIFO và GPIO
Mỗi FIFO có khả năng nhận dữ liệu từ một trong năm nguồn bất kỳ: máy chủ, cộng với bốn lõi. Phía enqueue của FIFO có trình phân giải ưu tiên với các quy tắc sau:
- Máy chủ luôn được ưu tiên
- Lõi được đánh số thấp hơn có mức độ ưu tiên hơn lõi được đánh số cao hơn
- Việc ghi tranh chấp tạm dừng cho đến khi đến lượt lõi
Không có cơ chế nào khác đảm bảo tính “công bằng” khi truy cập vào FIFO.
Phía dequeue của FIFO chỉ cần sao chép đầu ra của FIFO tới nhiều người nghe nếu có nhiều yêu cầu dequeue đến trong cùng một chu kỳ. Không có cơ chế nào đảm bảo đồng bộ hóa giữa các lõi một cách rõ ràng, nhưng lập trình viên có thể sử dụng quyền truy cập đăng ký “tạm dừng sự kiện” hoặc “tạm dừng lượng tử” trước khi đọc từ FIFO để đảm bảo rằng nhiều lõi đọc từ một nguồn FIFO duy nhất trong cùng một chu kỳ.
Các chân GPIO có một trình phân giải mức độ ưu tiên tương tự để thiết lập các bit của nó, với điểm khác biệt là lõi “mất” mức độ ưu tiên khi ghi chỉ đơn giản là yêu cầu của nó bị loại bỏ, vì lõi có mức ưu tiên cao hơn được coi là ghi đè ngay lập tức yêu cầu GPIO của lõi có mức ưu tiên thấp hơn.
Ngữ nghĩa truy cập GPIO được tối ưu hóa để chuyển nhanh dữ liệu thô sang mã pin tùy ý. Cụ thể, việc xóa một bit liên quan đến việc ghi “0” vào một bit, đây là một ngoại lệ đáng chú ý đối với mọi trường hợp khác khi một hành động được biểu thị bằng cách viết “1” vào một bit. Lý do ngoại lệ này được đưa ra là vì nó cho phép chúng ta loại bỏ tính năng đảo ngược bit khỏi vòng lặp lõi của giao thức bit-bang song song với nối tiếp, có lẽ là ứng dụng nhạy cảm nhất về hiệu năng đối với khối BIO.
Chụp theo lượng tử: Một ví dụ về SPI
Nói về SPI, chúng ta hãy xem một ví dụ về triển khai SPI bitbang. Trong trường hợp này, hai lõi chạy song song, một lõi xử lý shift-out + clock, còn lõi kia xử lý shift-in. Ánh xạ của các chân được đặt ở nơi khác trong mã để nhận trên GPIO 7, truyền trên GPIO 8, đồng hồ trên GPIO 9 và chọn chip trên GPIO 10.
Snap-to-quantum được sử dụng để đảm bảo các cạnh thẳng hàng. Để triển khai điều này, lượng tử cần chạy ở tốc độ xung nhịp SPI gấp đôi (vì vậy, 50 MHz cho xung nhịp SPI 25 MHz, có thể đạt được nếu lõi BIO chạy ở tốc độ 700 MHz; lưu ý rằng trên PicoRV32, một lệnh thông thường cần khoảng ba chu kỳ để thực thi vì không có đường dẫn).
Đoạn mã đầu tiên này là đoạn mã chạy trên lõi quản lý đồng hồ TX +. Một số hướng dẫn đầu tiên thiết lập mặt nạ bit và khoảng thời gian tạm thời, sau đó quy trình thay đổi các bit thực tế sẽ không được kiểm soát, do đó bạn không phải trả tiền phạt nhánh/vòng lặp giữa các bit. Việc hủy cuộn vòng lặp rất phổ biến trong mã BIO vì bạn có không gian mã rộng 4 kiB cho mỗi PicoRV32.
"82:", // máy 2 - tx trên bit 8, đồng hồ trên bit 9, chọn chip trên bit 10
"li x1, 0x700", // thiết lập các bit mặt nạ đầu ra
"mv x26, x1", // mặt nạ
"mv x24, x1", // hướng (1 = đầu ra)
"li x2, 0x100", // bitmask cho dữ liệu đầu ra
"không phải x3, x2",
"li x4, 0x200", // bitmask cho đồng hồ
"không phải x5, x4",
"li x6, 0x400", // bitmask để chọn chip
"không phải x7, x6",
"mv x21, x6", // thiết lập GPIO với CS cao, xung nhịp thấp, dữ liệu thấp
"mv x20, x0", // dừng ở lượng tử, đảm bảo điều này có hiệu lực
"20:", // vòng lặp chính
"mv x15, x16", // tải dữ liệu để truyền từ fifo 0 - tạm dừng cho đến khi có dữ liệu
"mv x23, x7", // bỏ CS
"slli x15, x15, 8", // dịch chuyển để LSB ở bit 8
"mv x20, x0", // chờ lượng tử cho thời gian giữ CS
// bit 0
"và x22, x15, x2", // đặt bit dữ liệu, nếu là 1
"hoặc x23, x15, x3", // xóa bit dữ liệu nếu là 0
"mv x20, x0", // đợi lượng tử để thiết lập dữ liệu
"mv x22, x4", // đồng hồ tăng
"srli x15, x15, 1",
"mv x20, x0", // chờ lượng tử để giữ dữ liệu
// bit 1
"và x22, x15, x2", // đặt bit dữ liệu, nếu là 1
"hoặc x23, x15, x3", // xóa bit dữ liệu nếu là 0
"mv x23, x5", // đồng hồ rơi
"mv x20, x0", // đợi lượng tử để thiết lập dữ liệu
"mv x22, x4", // đồng hồ tăng
"srli x15, x15, 1",
"mv x20, x0", // chờ lượng tử để giữ dữ liệuMã tiếp tục đi tiếp cho từng bit nhưng bị cắt bớt sau bit 1 để cho ngắn gọn. Bạn có thể xem mã đầy đủ github của chúng tôi kho lưu trữ.
Đoạn mã thứ hai này chạy song song trên lõi quản lý RX.
//đợi CS rớt
"31:",
"và x8, x6, x21",
"bnez x8, 31b",
// bit 0
"srli x14, x14, 1", // dịch chuyển bit vào vị trí
//đợi đồng hồ lên
"mv x20, zero", // dừng cho đến khi cạnh tăng ở bit 9 (được cấu hình bởi máy chủ)
"và x9, x2, x21", // che dấu bit
"slli x9, x9, 7", // chuyển sang MSB
"hoặc x14, x9, x14", // OR vào kết quả
// bit 1
"srli x14, x14, 1", // dịch chuyển bit vào vị trí
// đợi đến đồng hồ tăng lên
"mv x20, zero", // dừng cho đến khi cạnh tăng ở bit 9 (được cấu hình bởi máy chủ)
"và x9, x2, x21", // che dấu bit
"slli x9, x9, 7", // chuyển sang MSB
"hoặc x14, x9, x14", // HOẶC vào kết quảMã này tiếp tục tương tự với các bit còn lại và được cắt bớt để ngắn gọn.
Lưu ý ở đây rằng nguồn “snap to Quantum” cho x20 chỉ đơn giản là tín hiệu đồng hồ do TX tạo ra, do đó RX được tự động kích hoạt theo cách đồng bộ với tín hiệu đồng hồ SPI.
Sự đánh đổi ở mọi nơi: Diện tích, tốc độ đồng hồ và không gian mã
Nếu bạn chỉ đang tìm mã ví dụ về cách sử dụng BIO, bạn có thể bỏ qua hai phần tiếp theo và chuyển thẳng đến phần về cách chạy mã C trên BIO. Tuy nhiên, đối với những người quan tâm đến thiết kế và kiến trúc cơ bản của khối, nên so sánh việc triển khai PIO và BIO song song để thấy tác động của những quyết định kiến trúc này đến việc triển khai thực tế.
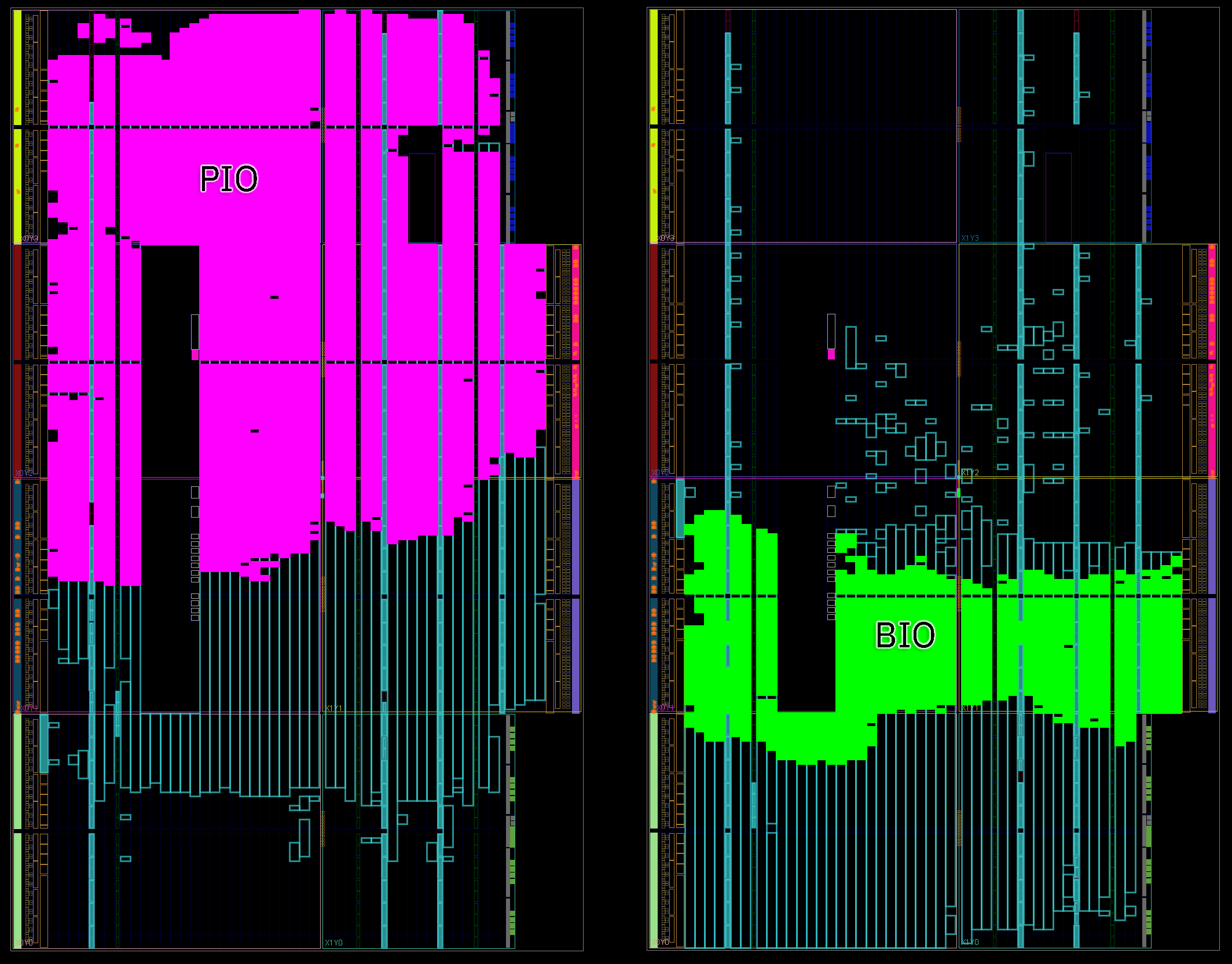
Trên đây là bản so sánh sơ đồ tầng song song của PIO và BIO được biên dịch trên cùng một FPGA 7-series Artix. Điểm đáng chú ý là mặc dù có bộ hướng dẫn RV32E phong phú hơn 9 hướng dẫn của PIO, BIO (hiển thị bằng màu xanh lá cây) chỉ tiêu thụ một phần diện tích của PIO (hiển thị bằng màu đỏ tươi).

Trên đây là bản đồ sử dụng theo thứ bậc mà bạn có thể so sánh với bản đồ PIO được hiển thị trước đó trong bài đăng này. BIO sử dụng 14597 ô, trong khi PIO sử dụng 39087 ô. Theo các con số, BIO có diện tích bằng khoảng một nửa PIO. Hơn nữa, khi được chuyển sang luồng ASIC, tốc độ xung nhịp mà BIO đạt được cao hơn gấp 4 lần tốc độ xung nhịp của PIO được triển khai trong cùng một nút quy trình.
Trước khi chúng ta quá say mê với tốc độ xung nhịp, hãy nhớ rằng lõi PicoRV32 cho phép chúng ta đạt tốc độ xung nhịp trên mỗi lõi cao hơn, nhưng mỗi lõi thực hiện ít hơn với mỗi chu kỳ xung nhịp và lệnh. Đây là sự đánh đổi cổ điển giữa CISC và RISC. PicoRV32 được thiết kế để thu gọn chứ không phải hiệu suất và do đó, phải mất khoảng ba chu kỳ cho mỗi lệnh và sẽ cần một số lệnh để thực hiện những gì PIO có thể thực hiện trong một lệnh. Điều này có nghĩa là trên mạng, BIO sẽ không đạt được tốc độ tối đa như PIO có thể đạt được đối với những thứ rất đơn giản như SPI, nhưng do tập lệnh phong phú hơn và bộ nhớ lệnh lớn hơn, người ta có thể triển khai nhiều chức năng hơn, chẳng hạn như xử lý tín hiệu điểm cố định hoặc nhồi bit để đóng khung dữ liệu vào các giao thức khác nhau. Do đó, nếu tất cả những gì bạn muốn là một công cụ tăng tốc bit có thể dịch chuyển các bit nhanh nhất có thể từ luồng DMA từ RAM, thì PIO là phù hợp hơn; nhưng nếu bạn muốn có bộ đồng xử lý I/O đầy đủ tính năng hơn thì BIO sẽ phù hợp hơn.
Điều đó có nghĩa là, nếu sẵn sàng sử dụng nhiều cổng hơn, bạn có thể hoán đổi lõi PicoRV32 bằng lõi có đường dẫn, hiệu suất cao hơn giúp đưa các hướng dẫn trên mỗi chu kỳ của bạn gần hơn với sự thống nhất. BIO là mã nguồn mở, vì vậy bạn có thể tự do tối ưu hóa sự cân bằng giữa diện tích và hiệu suất! Tin vui là cơ chế “snap to Quantum”, khi được sử dụng đúng cách, sẽ cho phép cùng một mã chạy trên các hoạt động triển khai BIO khác nhau, đồng thời đạt được cùng một kết quả chính xác theo chu kỳ.
Một điểm khác biệt giữa PIO và BIO là PIO không có bộ nhớ lệnh chỉ chứa 32 lệnh. Tuy nhiên, tôi đã chọn cung cấp cho mỗi lõi BIO một RAM 4 kiB rộng rãi để sử dụng. Một lần nữa, có những sự đánh đổi làm nền tảng cho điều này.
Về sự đánh đổi bộ nhớ
PIO chia sẻ bộ nhớ lệnh 32 mục nhập duy nhất với bốn lõi. Mỗi lõi trong số bốn lõi có khả năng truy cập độc lập vào bộ nhớ lệnh này một lần trong mỗi chu kỳ. Có lẽ, bộ nhớ 32 mục này được triển khai bằng cách sử dụng một biển flip flop, vì macro cứng bốn cổng dành cho RAM không quá phổ biến và nó có thể sẽ điều chỉnh hiệu suất sai cho ứng dụng của PIO. Do đó, mặc dù PIO hoạt động hiệu quả theo một nghĩa nào đó khi sử dụng lại 32 lệnh giống nhau trên cả bốn lõi, nhưng nó có thể phải chịu một số hình phạt nếu chuyển tiếp bản sao của các hướng dẫn đó qua bốn lõi được phân bổ theo không gian.
Mặt khác, ngay cả khi người ta có thể tận dụng macro cứng cho RAM thì vẫn có một kích thước tối thiểu nhất định mà theo đó chi phí dành cho macro sẽ chiếm ưu thế trong khu vực. Macro RAM rộng 32 từ x 32 bit sẽ có chi phí cực kỳ cao trong quy trình ASIC – có thể hơn 80% diện tích sẽ là trình điều khiển hàng/cột và bộ khuếch đại cảm biến, vì vậy cuối cùng có thể sẽ tốn khoảng cùng một diện tích để tạo ra nó từ dép xỏ ngón.
Tuy nhiên, chi phí hoạt động của RAM có quy mô tốt, gần như tỷ lệ với căn bậc hai của dung lượng bit. Điểm hấp dẫn phụ thuộc vào nút quy trình; Khi xem xét một số ảnh vi mô từ Baochip-1x, chúng tôi có thể xác định bằng thực nghiệm rằng các macro RAM một cổng bị chi phối bởi chi phí hoạt động cho đến khi kích thước mảng vượt quá kích thước hình học khoảng 512×32 bit.

Phía trên bên trái: ảnh vi mô của macro SRAM 256×27 từ quy trình 22 nm; phía trên bên phải: cùng một hình ảnh, nhưng với mảng lưu trữ được đánh dấu màu xanh mòng két và ranh giới của macro SRAM tổng thể được đánh dấu màu đỏ. Vùng trên cao của macro chứa các mạch như trình điều khiển đường truyền, bộ giải mã địa chỉ và bộ khuếch đại cảm biến.
Do chi phí chung, tôi quyết định sử dụng macro RAM nhanh một cổng 4 kiB, 1024×32 làm bộ nhớ chuyên dụng cho mỗi CPU PicoRV32. 4 kiB cũng chính xác bằng kích thước của một trang bộ nhớ ảo trên CPU RV32 của chúng tôi. Vì hầu hết các quy trình I/O bit-bang tiêu thụ ít hơn vài trăm byte nên có rất nhiều không gian mã trong BIO để giảm tải cho một số quy trình xử lý cấp cao hơn.
Mã hóa BIO bằng C
Mặc dù việc viết mã thủ công các quy trình lắp ráp bit-bang rất thú vị nhưng việc triển khai các tính năng cấp cao hơn như toán điểm cố định và ngăn xếp giao thức lại tẻ nhạt hơn và dễ xảy ra lỗi hơn trong quá trình lắp ráp. Để tạo điều kiện cho mã phức tạp hơn, tôi đã phát triển chuỗi công cụ C cho các chương trình BIO. Các chương trình này được biên dịch thành các macro tập hợp Rust, do đó quá trình biên dịch và liên kết Xous OS cuối cùng được thực hiện bằng Rust thuần túy, không có đốm màu.
Việc phát triển phương pháp C bên trong Xous rất khó, vì một trong những lợi ích chính của hệ sinh thái Xous là Rust thuần túy là chúng tôi không phải duy trì bất kỳ công cụ nào. Chúng tôi muốn giữ nó để công cụ duy nhất cần có để xây dựng hình ảnh Xous là Rust ổn định. Thời điểm trình biên dịch C được đưa vào quá trình xây dựng, chúng ta phải vượt qua một loạt các chuỗi công cụ C dành riêng cho phân phối, làm tăng đáng kể gánh nặng bảo trì và cản trở của nhà phát triển.
Giải pháp của chúng tôi cho vấn đề này, ít nhất là ở thời điểm hiện tại, là mượn trình biên dịch clang C của hệ sinh thái Zig. Zig phân phối chuỗi công cụ của mình dưới dạng gói Python, được xây dựng dựa trên giả định rằng hầu như tất cả các máy tính đều đã có bản phân phối Python nào đó. Do đó, để xây dựng mã C cho BIO, người ta sử dụng Python để cài đặt chuỗi công cụ Zig, sau đó sử dụng trình biên dịch C được tích hợp trong chuỗi công cụ Zig để xây dựng mã C:
- Đầu tiên, người dùng cài đặt Zig bằng
python3 -m pip install ziglang. Chỉ chuỗi công cụ 0,15 mới tương thích với tập lệnh BIO. - Sau đó, người dùng biên dịch các chương trình BIO C thành các macro tập hợp Rust bằng cách sử dụng
python3 -m ziglang build -Dmodule=bên trong thư mụclibs/bio-lib/src/c.
Tập lệnh xây dựng biên dịch mã C thành clang tập hợp trung gian, sau đó được chuyển sang tập lệnh Python để dịch nó thành macro Rust, được kiểm tra vào Xous dưới dạng một tạo phẩm có thể xây dựng bằng cách sử dụng chuỗi công cụ Rust thuần túy của nó. Tập lệnh Python cũng kiểm tra mã lắp ráp để tìm một số họa tiết nhất định có thể kích hoạt lỗi trong lõi BIO và tự động vá chúng. Do đó, trường hợp duy nhất cần có chuỗi công cụ C là khi nhà phát triển cần thay đổi mã C; việc sử dụng lại chương trình C hiện có chỉ yêu cầu Rust. Là một tác dụng phụ, điều này cũng mở đường cho các nhà phát triển Zig viết mã BIO.
Dưới đây là ví dụ cho thấy C-for-BIO trông như thế nào:
// pin được cung cấp dưới dạng số GPIO để điều khiển
// dải là một mảng u32 chứa dữ liệu Gbps
// len là chiều dài của dải
void ws2812c(uint32_t pin, uint32_t *strip, uint32_t len) {
uint32_t dẫn;
// tỉnh táo kiểm tra giá trị pin
nếu (pin > 31) {
trở lại;
}
mặt nạ uint32_t = 1 << pin;
uint32_t antimask = ~mask;
set_gpio_mask(mặt nạ);
set_output_pins(mặt nạ);void main(void) {
uint32_t pin;
uint32_t actual_leds;
uint32_t rate; // blocks until these are configured
pin = pop_fifo1();
actual_leds = pop_fifo1();
tỷ lệ = pop_fifo1();
while (1) {
ws2812c(pin, led_buf, real_leds);
Rainbow_update(actual_leds, rate);
for (uint32_t i = 0; i < 100000; i++) {
wait_quantum();
}
}
Đây là ví dụ về giao thức LED WS2812C. Mã nguồn được phân chia giữa main và tiêu đề. Ở đây, chúng tôi tận dụng tính năng “lượng tử” để có được thời gian xung chính xác mà không cần dùng đến tính năng đếm chu kỳ. “Lượng tử” được đặt ở khoảng thời gian 150 ns, chia đều tất cả các mẫu thời gian cao/thấp cần thiết. Miễn là tất cả tính toán trong vòng lặp kết thúc trước lượng tử tiếp theo thì các yêu cầu về thời gian của WS2812C đều được đáp ứng.
Thư viện C mới ra đời cũng bao gồm thư viện toán điểm cố định, do đó, bản demo có thể tính toán các hiệu ứng màu sắc ngoài việc điều khiển chuỗi đèn LED. Toàn bộ chương trình demo, bao gồm thư viện toán điểm cố định, chỉ sử dụng khoảng 25% bộ nhớ BIO: 1062 byte trong số 4096 byte có sẵn. Hãy xem bản trình diễn “colorwheel” cho mã hoặc README trong bio-lib để biết lời nhắc về cách sử dụng chuỗi công cụ C.
Ánh xạ
PIO và BIO là những nghiên cứu điển hình về các triết lý kiến trúc khác nhau đối với việc triển khai bộ đồng xử lý I/O. Tóm lại:
PIO:
- Cấu trúc CISC
- Tập hợp phong phú các tùy chọn có thể định cấu hình với mỗi lệnh
- Việc đếm chu kỳ thật dễ dàng, cho phép tạo ra các dạng sóng bit-bang thủ công và thời gian phản hồi xác định
- Bộ nhớ lệnh nhỏ, được chia sẻ bởi cả bốn lõi
- Được tối ưu hóa cho mỗi lõi triển khai một chức năng khác nhau
- Vùng logic lớn hơn
- Tốc độ xung nhịp thấp hơn nhưng IPC được đảm bảo là 1
- Công cụ tùy chỉnh, không có trình biên dịch (afaik)
- Nguồn đóng, có thể bị cản trở bởi ít nhất một bằng sáng chế
BIO:
- Cấu trúc RISC
- Các thao tác cơ bản trong mỗi lệnh: yêu cầu một số lệnh để khớp với một lệnh PIO
- Việc đếm chu kỳ khó hơn nhưng hiệu suất xác định theo thời gian thực được hỗ trợ nhờ các thanh ghi ổn định
- Các tiện ích mở rộng ISA để liên lạc trực tiếp giữa các lõi với FIFO
- Bộ nhớ lệnh lớn hơn, riêng tư cho từng lõi
- Được tối ưu hóa cho nhiều lõi cộng tác nhằm cải thiện hiệu suất; hoặc mỗi lõi thực hiện một chức năng khác nhau nhưng ở tốc độ thấp hơn
- Vùng logic nhỏ hơn
- Tốc độ xung nhịp cao hơn nhưng IPC nằm trong khoảng 0,2-0,33 (có thể được cải thiện bằng cách sử dụng nhiều vùng logic hơn)
- Tận dụng công cụ tiêu chuẩn cho RV32E, bao gồm trình biên dịch, trình biên dịch mã, macro, trình gỡ lỗi, v.v.
- Mã nguồn mở, không có bằng sáng chế
Việc triển khai BIO hiện tại ưu tiên diện tích hơn hiệu suất, cho phép nó được tích hợp hợp lý dưới dạng thiết bị ngoại vi trên FPGA có kích thước khiêm tốn. Lựa chọn triển khai này có nghĩa là BIO không thể bitbang DVI như PIO có thể, nhưng nó có đủ chỗ trống trên bo mạch Arty A7-100T. Tuy nhiên, tôi cảm thấy BIO thực sự tỏa sáng ở chỗ giảm tải các tác vụ như quản lý ngăn xếp giao thức khỏi CPU. Bất chấp những đánh đổi, việc triển khai Baochip-1x chạy ở tốc độ 700 MHz có thể mô phỏng thoải mái bus SPI ở tốc độ 25 MHz, đủ nhanh cho một loạt ứng dụng nhúng.
Tài nguyên
Để giúp bạn bắt đầu, các tài nguyên sau có sẵn trên GitHub.
- Dành cho nhà phát triển BIO: Thư viện mẫu Xous-native. Bắt đầu bằng cách sao chép một trong các thư viện này làm mẫu và mở rộng nó!
- Dành cho kỹ sư phần cứng: RTL cho BIO. Nó được viết bằng SystemVerilog và tích hợp vào hệ thống máy chủ bằng AHB (và AXI cho DMA nếu được bật).
- Dành cho kỹ sư xác minh: Kiểm tra đơn vị cho phần cứng BIO
Cuối cùng, nếu bạn quan tâm đến việc sử dụng phần cứng BIO thực tế trong một con chip, hãy xem chiến dịch của ban phát triển “Dabao” trên Crowd Supply.
Tôi hy vọng bạn có được nhiều niềm vui khi sử dụng nó như tôi đã tạo ra nó!
Mục nhập này được đăng vào Thứ Bảy, ngày 21 tháng 3 năm 2026 lúc 12:39 sáng và được gửi trong baochip, Hacking, nguồn mở . Bạn có thể theo dõi mọi phản hồi cho mục này thông qua nguồn cấp dữ liệu RSS 2.0. Bạn có thể để lại phản hồi hoặc theo dõi từ trang web của riêng bạn.
Tác giả: zdw