Thống kê Bayes cho các nhà khoa học dữ liệu bối rối
Bayesian statistics for confused data scientists
Bài viết này làm rõ sự khác biệt cốt lõi giữa thống kê Bayesian và thống kê tần suất (frequentist): cách chúng xử lý sự bất định. Các phương pháp tần suất xem các tham số (parameters) là cố định nhưng chưa biết, coi dữ liệu là ngẫu nhiên và đưa ra các khoảng tin cậy (confidence intervals) mô tả hành vi dài hạn. Ngược lại, các phương pháp Bayesian mô hình hóa chính các tham số như các biến ngẫu nhiên (random variables) với các phân phối xác suất (probability distributions) đi kèm, trực tiếp định lượng sự bất định và cho ra các khoảng tin cậy (credible intervals) thể hiện xác suất một tham số nằm trong một phạm vi nhất định. Các developer nên hiểu rõ sự khác biệt này để tận dụng các phương pháp Bayesian, giúp định lượng sự bất định trong các mô hình của mình một cách trực quan hơn, đặc biệt khi làm việc với thông tin không đầy đủ.
Đây là lần thứ ba tôi rơi vào hố thỏ Bayesian. Mọi chuyện luôn diễn ra như thế này: Tôi tìm thấy một số bài viết hay về nó, cảm giác như có phép thuật, bất cứ ai viết về nó có lẽ hơi tự mãn về việc...
Đây là lần thứ ba tôi rơi vào hố thỏ Bayesian. Mọi chuyện luôn diễn ra như thế này: Tôi tìm thấy một số bài báo hay về nó, cảm giác như có phép thuật, bất cứ ai viết về nó có lẽ hơi tự mãn về việc nó hay hơn chủ nghĩa thường xuyên đến mức nào (và tôi không trách họ), nhưng tôi vẫn bối rối không biết chính xác chuyện gì đang xảy ra. Bài đăng này là một nỗ lực nhằm buộc bản thân phải hiểu mọi thứ tôi đã đọc cho đến nay và hy vọng nó cũng sẽ hữu ích cho nhóm ngoài kia, những người chắc chắn cũng cảm thấy giống như tôi.1
Bayesian vs. số liệu thống kê thường xuyên: câu chuyện về mối thù
Cách tiếp cận theo chủ nghĩa thường xuyên chiếm ưu thế đến mức khi bạn tìm hiểu số liệu thống kê, nó không được đặt tên như vậy mà chỉ là là số liệu thống kê. Mặt khác, cách tiếp cận Bayesian là một lĩnh vực kỳ lạ mà chỉ có một số ít người có vẻ thực sự quan tâm. Đó là Haskell của thống kê. Và cũng giống như đối tác lập trình của nó, bộ tộc Bayesian nhỏ bé này thực sự có lý khi yêu thích nó đến vậy.
Về cốt lõi, sự khác biệt giữa thống kê Bayesian và thống kê thường xuyên là ở vai trò triết học mà xác suất đóng trong khuôn khổ. Trong cả hai khung, bạn có thông số (thường là một số đại lượng không xác định xác định cách mọi thứ hoạt động) và bạn có dữ liệu (hoặc quan sát), là những thứ bạn đã đo lường.
Một ví dụ đơn giản là nếu bạn tung xúc xắc nhiều lần. Tham số ở đây là số lượng khuôn mặt nn (theo trực giác, tất cả chúng ta đều biết càng nhiều khuôn mặt thì khả năng một khuôn mặt nhất định sẽ xuất hiện càng ít), trong khi dữ liệu chỉ là những khuôn mặt được thu thập mà bạn nhìn thấy khi tung xúc xắc. Hãy để tôi nói cho bạn biết ngay rằng để ví dụ của tôi có thể hiểu được bất kỳ nào, bạn phải làm cho kịch bản trở nên phức tạp hơn một chút. Vì vậy, giả sử bạn đang chơi DnD hoặc một số trò chơi dựa trên xúc xắc, nhưng người quản lý trò chơi của bạn đang tung xúc xắc sau một bức màn. Vì vậy, bạn không biết con súc sắc có bao nhiêu mặt (có thể người điều khiển trò chơi đang nói dối bạn, có thể không), tất cả những gì bạn biết là đó là một con súc sắc và các giá trị được tung ra. Người thường xuyên trong tình huống này sẽ cho bạn biết tham số nn là cố định (mặc dù không xác định) và dữ liệu chỉ được lấy ngẫu nhiên từ phân bố đều X∼U(n)X \sim \mathcal{U}(n). Mặt khác, người theo trường phái Bayes sẽ nói rằng bản thân tham số nn là một biến ngẫu nhiên được rút ra từ phân phối một số khác PP, với độ không chắc chắn của chính nó và dữ liệu đó cho bạn biết phân bố đó thực sự là gì.
Tôi sẽ tạm dừng ở đây để bạn hít thở và hét vào màn hình của mình rằng điều đó thật vô nghĩa. Tất nhiên, số mặt là cố định, là xúc xắc! Những gì thống kê Bayes định lượng bằng phân phối PP không phải là số lượng khuôn mặt ngẫu nhiên như thế nào mà là mức độ không chắc chắn của bạn về điều đó. Đây là sự khác biệt quan trọng và là toàn bộ lý do tại sao thống kê Bayesian lại có tác dụng mạnh mẽ đến vậy. Trong các cách tiếp cận theo chủ nghĩa thường xuyên, sự không chắc chắn thường là điều cần suy nghĩ lại, điều gì đó mà bạn chỉ cần sử dụng một số công thức lấy mẫu trên tổng thể sau khi thực tế xảy ra. Có lẽ nếu bạn cảm thấy thích thú, bạn có thể sử dụng một số phương pháp khởi động. Và bất kỳ khoảng thời gian nào bạn nhận được từ đây đều là khoảng tin cậy, nó không cho bạn biết khả năng tham số nằm trong đó như thế nào nhưng tần suất các khoảng được xây dựng theo cách này sẽ chứa tham số. Đây thường là một điểm khó hiểu khiến cho khoảng tin cậy trở thành một khái niệm rất dễ bị hiểu lầm. Mặt khác, trong thống kê Bayesian, tham số không phải là điểm mà là phân phối. Sự chênh lệch của phân phối đó đã giải thích cho sự không chắc chắn mà bạn có về tham số và khoảng tin cậy mà bạn nhận được từ nó thực sự cho bạn biết khả năng tham số nằm trong đó.
Một lưu ý mang tính toán học hơn, sự khác biệt giữa hai cách tiếp cận nằm ở định lý nổi tiếng của Bayes, cho bạn biết các xác suất có điều kiện có liên quan với nhau như thế nào:
P(A∣B)P(B)=P(B∣A)P(A) . P(A|B)P(B) = P(B|A)P(A)~.
Chính là nó! Nếu bạn lấy phương trình này và thêm các tham số θ\theta và dữ liệu XX vào đó, thì bạn sẽ nhận được P(θ∣X)=P(X∣θ)P(θ)P(X)P(\theta|X) = \frac{P(X|\theta)P(\theta)}{P(X), tức là nền tảng của suy luận Bayes. Điều này có vẻ không hữu ích ngay lập tức, nhưng nó thực sự hữu ích. Hãy nhớ rằng XX chỉ là một loạt các quan sát, trong khi θ\theta là thông số hóa mô hình của bạn. Vì vậy, P(X∣θ)P(X|\theta), khả năng, chỉ là khả năng xem dữ liệu bạn có để thực hiện các thông số nhất định. Trong khi đó, P(θ)P(\theta), trước, là trực giác mà bạn có về hình thức của các tham số. Tôi sẽ quay lại vấn đề này, nhưng đó thường là thứ bạn chọn. Cuối cùng, bạn có thể coi P(X)P(X) như một hằng số chuẩn hóa và một trong những điều chính mà mọi người làm trong suy luận Bayesian theo nghĩa đen là bất cứ điều gì họ có thể để họ không phải tính toán nó! Tất nhiên, mục tiêu là ước tính phân phối sau P(θ∣X)P(\theta|X) để cho bạn biết thông số này có phân phối như thế nào. Phân phối sau rất hữu ích vì
- nó cho bạn ý tưởng rõ ràng về sự không chắc chắn của bạn trong quá trình tham số hóa mô hình,
- bạn có thể sử dụng nó để xây dựng phân phối dự đoán sau P(Y∣X)=∫P(Y∣θ)P(θ∣X)dθ P(Y|X) = \int P(Y|\theta) P(\theta | X) \mathrm{d} \theta ~ trong đó YY là mới dữ liệu.
Hãy quay lại ví dụ lăn xúc xắc nhỏ của chúng ta và giả sử bạn quan sát các giá trị sau với tần số đã cho:
| Giá trị | Số | Tần suất |
|---|---|---|
| 1 | 2 | 0,250 |
| 2 | 1 | 0,125 |
| 3 | 2 | 0,250 |
| 4 | 3 | 0,375 |
Nếu bạn là người thường xuyên, bạn sẽ tìm kiếm ước tính khả năng tối đa của số lượng khuôn mặt, về cơ bản là sự tối đa hóa của thuật ngữ P(X∣θ)P(X|\theta) được giới thiệu ở trên. Hãy dành một giây để tìm hiểu điều này: nếu xúc xắc của bạn có nn mặt thì X∼U(n)X \sim \mathcal U(n) và xác suất quan sát được chính xác dữ liệu này là
P(X∣n)=P(X=1∣n)2P(X=2∣n)P(X=3∣n)2P(X=4∣n)3=(1n)8 .P(X|n) = P(X=1|n)^2 P(X=2|n) P(X=3|n)^2 P(X=4|n)^3 = \left(\frac{1}{n}\right)^8~.
Điều này rõ ràng là tối đa khi nn là giá trị nhỏ nhất có thể, ở đây là 4 (vì không thể rút được số 4 bằng xúc xắc 3 mặt). Cho đến nay điều này khá dễ dàng, nhưng khoảng tin cậy lại là một vấn đề khác và minh họa khá rõ ý tưởng về “tiện ích bổ sung”. Một cách để tìm nó là tìm tất cả các giá trị của nn sao cho P(Xmax≤4∣n) ≥α/2P(X_{\mathrm{max}} \leq 4 | n) \geq \alpha/2, trong đó α\alpha là mức độ tin cậy (thường được chọn là 5%). Đối với một nn nhất định, xác suất này bằng (4n)8\left(\frac{4}{n}\right)^8 mang lại CI có dạng [4,6][4,6], vậy là chúng ta đã có nó!2
Bây giờ hãy đặt giới hạn Bayesian và xem chúng ta có thể làm gì. Trước hết, chúng ta đã thấy điều đó qua các quan sát kk, P(X∣n)=1nkP(X|n) = \frac{1}{n^k (k=8k=8 tại đây), vì vậy chúng ta đã xác định được khả năng xảy ra. trước, như tôi đã đề cập trước đây, là thứ bạn chọn. Về cơ bản, bạn phải quyết định một số phân phối mà bạn cho rằng tham số đó có khả năng tuân theo. Nhưng hãy nghe tôi: nó không cần phải hoàn hảo miễn là nó hợp lý! Những gì phần trước làm về cơ bản là cung cấp một số thông tin ban đầu, chẳng hạn như sự thúc đẩy, cho mô hình Bayesian của bạn. Điều duy nhất bạn nên đảm bảo là cung cấp hỗ trợ cho bất kỳ giá trị nào bạn nghĩ có thể phù hợp (vì vậy hãy luôn chọn mức phân bổ tương đối rộng). Ví dụ: ở đây, tôi sẽ chọn một giá trị tiên nghiệm siêu thiếu thông tin: phân phối đồng đều P(n)=1/N P(n) = 1/N~ với n∈[4,N+3]n \in [4, N+3] cho một số NN rất lớn (giả sử là 100). Khi đó, sử dụng định lý Bayes, phân bố sau là P(n∣X)∝1nkP(n | X) \propto \frac{1}{n^k. Ký hiệu ∝\propto có nghĩa là nó đúng với hằng số chuẩn hóa, vì vậy chúng ta có thể viết lại toàn bộ phân phối dưới dạng
P(n∣X)=n−k∑m ≥4m−k=n−kζ(k,4) ,P(n | X) = \frac{n^{-k}}{\sum_{m \geq 4} m^{-k}} = \frac{n^{-k}}{\zeta(k, 4)}~,
trong đó mẫu số được gọi là hàm Hurwitz zeta, một chuỗi hội tụ nhanh. Ở giai đoạn này, nhà thống kê Bayes sẽ tính toán ước tính hậu nghiệm tối đa (MAP) được đưa ra bởi mức phân bổ tối đa (là n=4n = 4) hoặc giá trị trung bình nˉ=∑n ≥4n1−k∑m ≥4m−k=ζ(k−1,4)ζ(k,4)≃4.26\bar{n} = \frac{\sum_{n \geq 4} n^{1-k}}{\sum_{m \geq 4} m^{-k}} = \frac{\zeta(k-1, 4)}{\zeta(k, 4)} \simeq 4.26. Hiện tại, bạn có thể thu được khoảng đáng tin cậy bằng cách chỉ cần xem xét hàm phân phối tích lũy cho phân phối sau F(N)=∑s=4NP(n=s∣X)F(N) = \sum_{s=4}^N P(n = s | X) và tìm các giá trị [4,nR][4, n_R] mà nó chiếm 95% khối lượng xác suất. Đối với vấn đề này, chúng ta chỉ có thể thực hiện với một vài giá trị và xem nó dừng ở đâu, dẫn đến khoảng [4,5]:
| n | F(n) |
|---|---|
| 4 | 0,816 |
| 5 | 0,953 |
| 6 | 0,985 |
Vì vậy, kết quả này khá phù hợp với cách tiếp cận thường xuyên và sự không chắc chắn ở đây có thể được hiểu là hệ quả của
- sử dụng rất không có thông tin trước P(θ)∝1P(\theta) \propto 1,
- có ít dữ liệu để quan sát.
Nếu cả khả năng xảy ra và thông tin trước đều mang ít thông tin thì thông tin sau sẽ rất không chắc chắn. Đây là một ví dụ hoàn hảo mà chúng ta có thể thấy việc sử dụng một cái trước khác, một cái bao gồm một số kiến thức về vấn đề, có thể hữu ích như thế nào. Vì nn là một số nguyên có thể gần bằng 4 nên tôi sẽ sử dụng phân bố hình học như trước n∼3+Geom(q)n \sim 3 + \mathrm{Geom}(q), với q=0.5q = 0,5. Trong đoạn mã bên dưới, tôi sử dụng pymc để thực hiện việc này bằng số và tôi tìm thấy nˉ=4.10\bar n = 4.10 với khoảng tin cậy [4,5][4, 5]. Mặc dù khoảng thời gian là như nhau nhưng điều quan trọng là mức phân phối đang tiến gần đến 4 (xem giá trị trung bình), cho thấy sự không chắc chắn của chúng tôi đang giảm dần.
nhập pymc as chiều
import numpy as np
import arviz as az
nhập matplotlib.pyplot as plt
# Quan sát
quan sát = np.array([1, 1, 2, 3, 3, 4, 4, 4])
k = len(observations)
x_max = int(observations.max())
với pm.Model() như mô hình:
# Hình học trước trên các mặt thừa ngoài x_max
thừa = pm.Geometric("excess", p=0,5) - 1 # 0, 1, 2, ...
n = pm.Deterministic("n", vượt quá + x_max)
# Khả năng: (1/n)^k, hợp lệ theo cách xây dựng vì n >= x_max
pm.Potential("likelihood", -k * pm.math.log(n))
# Sử dụng bộ lấy mẫu NUTS với target_accept=0.9 cho các biến rời rạc
trace = pm.sample(10000, tune=2000, chuỗi=4)
posterior_n = trace.posterior["n"].values.flatten()
hdi = az.hdi(trace, var_names=[ "n"], hdi_prob=0,95)
print(f" Nghĩa sau: {posterior_n.mean():.2f>")
print(f"95% HDI: {hdi['n' .giá trị")
Nhưng trước đó bạn đã nói điều trước đó không quan trọng. Rõ ràng là có!
Đúng vậy, đây là một khía cạnh quan trọng của thống kê Bayes. Vì phần sau trực tiếp phụ thuộc vào phần trước nên tất nhiên nó có tác dụng nhất định. Tuy nhiên, bạn càng có nhiều dữ liệu thì phần sau của bạn sẽ càng được xác định bởi thuật ngữ khả năng. Điều này đặc biệt đúng nếu bạn lấy giá trị trước “rộng” (Gaussian rộng, đồng nhất, v.v.). Lý do cho điều này là bạn càng có nhiều dữ liệu thì khả năng bạn sẽ có càng nhiều cấu trúc (tức là các đỉnh cục bộ). Khi nhân với phần trước, những phần này sẽ hầu như không bị xáo trộn bởi các phần phẳng của phần trước và sẽ vẫn giữ nguyên các đặc điểm của phần sau. Nhưng khi bạn có ít dữ liệu, điều ngược lại sẽ xảy ra và dữ liệu trước của bạn được phản ánh nhiều hơn trong dữ liệu sau. Đây là một trong những điểm mạnh của thống kê Bayes. Cái trước có ở đây để bù đắp cho việc thiếu dữ liệu và khi có đủ dữ liệu, nó sẽ ngừng hoạt động.3
TL; DR: Trong khi thống kê thường xuyên coi các tham số là cố định và dữ liệu là ngẫu nhiên thì thống kê Bayes lại làm ngược lại. Đây chủ yếu là sự khác biệt trong cách giải thích, nhưng nó có một số tác động đến chính khuôn khổ đó. Thống kê Bayes đặc biệt phù hợp để mô hình hóa tính không chắc chắn vốn có của dữ liệu được lấy mẫu.
Thống kê Bayes trong thực tế
Nếu phần trước bạn cảm thấy hơi tẻ nhạt thì đó là điều bình thường. Thông thường với các ví dụ đơn giản như ví dụ trên, số liệu thống kê Bayesian không có vẻ đặc biệt hữu ích và sự phức tạp của việc thay đổi các khuôn khổ dường như khó có giá trị. Tuy nhiên, những tình huống như vậy hiếm khi xảy ra trong đời thực. Gần đây tôi đã phát hiện ra một trường hợp sử dụng thú vị hơn nhiều, trong đó sự cân bằng giữa mô hình hóa trước và khả năng xảy ra theo một cách rất thú vị.
Hãy tưởng tượng bạn là một công ty bán lẻ và bạn muốn tạo dữ liệu tổng hợp thể hiện các đơn đặt hàng của mình, dựa trên dữ liệu lịch sử. Một khía cạnh khá khó khăn của việc này là làm thế nào để phân phối dữ liệu tổng hợp về mặt địa lý. Cách tiếp cận đơn giản nhất chỉ là lấy mẫu một vị trí ngẫu nhiên (chẳng hạn như mã bưu chính) cho mỗi đơn hàng, dựa trên tần suất các đơn hàng tương tự trong quá khứ. Hiện tại, điều tương tự có thể chỉ có nghĩa là cùng một danh mục hoặc được bán trong cùng một kênh (tại cửa hàng, trực tuyến, v.v.). Cách tiếp cận thường xuyên đối với vấn đề này thường bắt đầu bằng cách phân cụm dữ liệu lịch sử dựa trên nhóm bạn đã chọn và ước tính mức phân bổ mã bưu chính cho từng cụm bằng cách sử dụng số lượng bán hàng trong dữ liệu. Nếu chuẩn hóa số lượng theo danh mục, bạn sẽ nhận được phân bố xác suất có điều kiện P(postal code∣category)P(\text{postal code} | \text{category}) mà sau đó bạn có thể lấy mẫu.
Mặc dù đây là một cách tiếp cận hoàn toàn hợp lý nhưng không phải là không có vấn đề. Ví dụ: nó không hiệu quả lắm đối với các danh mục mới hoặc mã bưu chính mới. Tương tự, nếu dữ liệu của bạn thưa thớt thì phân phối ước tính có thể khá nhiễu. Trong khoa học dữ liệu, loại tình huống này thường yêu cầu các phương pháp chính quy hóa cụ thể. Theo cách tiếp cận Bayesian, việc phân phối lịch sử của mã bưu chính sẽ kiểm soát khả năng xảy ra (tôi dựa trên phân phối Dirichlet-Đa thức), nhưng bạn vẫn phải cung cấp trước. Như tôi đã đề cập ở trên, phần trước sẽ tiếp quản bất cứ nơi nào dữ liệu của bạn không đủ chính xác để mang lại khả năng cao. Tất nhiên, không giống như ví dụ trước, bạn không muốn sử dụng phần trước không có thông tin mà muốn tận dụng một số kiến thức về miền. Nếu không, bạn cũng có thể sử dụng phương pháp tiếp cận thường xuyên. Ưu tiên tốt nhất cho vấn đề này sẽ là bất kỳ sự phân phối dựa trên dân số nào (hoặc bất kỳ điều gì có liên quan đến doanh số bán hàng). Điểm mấu chốt ở đây là không giống như dữ liệu của chúng tôi, sự phân bố dân cư không thưa thớt nên mọi mã bưu chính đều có cơ hội được lấy mẫu, điều này dẫn đến một mô hình mạnh mẽ hơn. Khi thực hiện việc này, bạn sẽ có được một mô hình tận dụng tối đa dữ liệu đồng thời xử lý khéo léo các khu vực mới bằng cách sử dụng khu vực trước đó làm loại dự phòng.
Các phương pháp số trong thống kê Bayesian
Tôi hy vọng bây giờ bạn có thể thấy số liệu thống kê Bayesian hữu ích như thế nào. Nhưng đồng thời, bạn cũng có thể nhận thấy rằng việc tính toán có thể hơi khó khăn. Trước đây chúng ta đã gặp may vì mọi thứ đều có thể được biểu diễn bằng một chuỗi toán học nổi tiếng. Nói chung, đây không phải là trường hợp. Rất may, có một số thuật toán số hiệu quả có thể giúp bạn tìm phân bố sau mà không cần phải thực hiện bất kỳ công việc nào trong số này và tôi thực sự đã cho bạn xem một ví dụ ở trên dựa trên gói Python pymc.
Ý tưởng này bắt nguồn từ phương pháp Markov Chain Monte Carlo (MCMC):
- ‘Chuỗi Markov’ về cơ bản là các bước đi ngẫu nhiên trong không gian tham số không có bộ nhớ (vì vậy mỗi bước chỉ phụ thuộc vào trạng thái hiện tại),
- 'Monte Carlo' đề cập đến các thuật toán sử dụng lấy mẫu ngẫu nhiên để ước tính một số lượng (trong trường hợp này là phân phối sau).
Để lấy mẫu phân phối sau, có một số thuật toán MCMC (pyMC sử dụng thuật toán NUTS), nhưng ở đây tôi sẽ tập trung vào thuật toán Metropolis mà tôi đã sử dụng trước đó để giải mô hình spin Ising. Thuật toán bắt đầu từ một điểm nào đó trong không gian tham số θ0\theta_0. Sau đó, tại mỗi bước thời gian tt, thuật toán đề xuất một điểm mới θt+1\theta_{t+1} được chấp nhận với xác suất min(1,P(θt+1∣X)P(θt∣X))\min\left(1, \frac{P(\theta_{t+1}|X)}{P(\theta_t|X)}\right). Bởi vì xác suất này chỉ phụ thuộc vào tỷ lệ phân phối sau, nên nó độc lập với thuật ngữ chuẩn hóa P(X)P(X) và thay vào đó chỉ phụ thuộc vào khả năng và phân phối trước đó. Đây là một lợi thế rất lớn vì cả hai đều nổi tiếng và dễ tính toán. Thuật toán tiếp tục trong một thời gian cho đến khi chuỗi hội tụ về phân bố sau và các điểm dữ liệu được quan sát hiển thị hình dạng của phân bố sau.
Trong pymc, cách để thực hiện việc này là xác định mô hình bằng cách sử dụng pm.Model(). Bạn có thể xác định một số phân phối cho các ưu tiên của mình bằng cách sử dụng pm.Uniform, pm.Normal, pm.Binomial, v.v. Để chỉ định khả năng của mình, bạn có thể chỉ định nó trực tiếp bằng cách sử dụng pm.Potential (như tôi đã làm ở trên) nếu bạn có biểu mẫu đóng, nếu không, bạn có thể chỉ định mô hình dựa trên tham số của mình bằng bất kỳ phương pháp phân phối nào, cung cấp dữ liệu được quan sát bằng đối số được quan sát. Cuối cùng, bạn có thể gọi pm.sample() để chạy thuật toán MCMC và lấy mẫu từ phân phối sau. Sau đó, bạn có thể sử dụng arviz để phân tích kết quả và nhận được những thứ như khoảng tin cậy, phương tiện hậu nghiệm, v.v.
Ví dụ: giả sử bạn muốn điều chỉnh mô hình hồi quy tuyến tính y=ax+by = a x + b cho một số dữ liệu (xi,yi)(x_i, y_i). Theo cách tiếp cận Bayesian, trước tiên chúng tôi xác định mức ưu tiên cho các tham số aa, bb. Vì tất cả các tham số đều là số thực liên tục nên phân phối chuẩn trước rộng là một lựa chọn tốt. Để có khả năng xảy ra, chúng ta có thể tập trung vào phần dư ri=yi−(axi+b)r_i = y_i - (a x_i + b) mà chúng ta lập mô hình thông qua phân phối chuẩn ri∼N(0,σ2)r_i \sim \mathcal{N}(0, \sigma^2) (chúng tôi cũng cung cấp các giá trị tiên nghiệm cho σ\sigma). Trong pymc, điều này có thể được triển khai như sau:
nhập pymc như chiều
với pm.Model() dưới dạng mô hình:
# Ưu tiên
a = pm.Normal("a", mu=0, sigma=10)
b = pm.Normal("b", mu=0, sigma=10)
sigma = pm.HalfNormal("sigma", sigma=10)
# Khả năng
y_obs = pm.Normal("y_obs", mu=a * x + b, sigma =sigma, được quan sát=y)
# Mẫu từ phía sau
dấu vết = pm.sample(1000, điều chỉnh=1000, chuỗi=4)
Sau khi các chuỗi đã hội tụ, chúng ta có thể trích xuất các phân phối sau cho aa, bb và σ\sigma (để lấy phương tiện hoặc CI) bằng cách sử dụng arviz:
nhập arviz as az
a_mean = trace.posterior[ "a"].values.mean()
b_mean = trace.posterior["b"].values.mean()
sigma_mean = trace.posterior["sigma"].values.mean()
Một lợi ích thú vị của phương pháp này là nó cũng hoạt động rất tốt nếu dữ liệu của bạn có các giá trị ngoại lệ. Trong trường hợp này, bạn có thể thêm một tham số phiền toái gi∈[0,1]g_i \in [0,1] cho mỗi điểm dữ liệu để nội suy giữa khả năng Gaussian của chúng tôi và một phân phối Gaussian khác có phương sai rộng hơn nhiều, lập mô hình nhiễu nền. Điều này phần lớn làm tăng số lượng tham số chưa biết, nhưng đổi lại mọi tham số đều được cân nhắc và mô hình có thể dễ dàng xác định các giá trị ngoại lệ. Trong pymc, việc này sẽ được thực hiện như thế này:
với pm.Model() như mô hình:
# Priors
a = pm.Normal("a", mu=0, sigma= 10)
b = pm.Normal("b", mu=0, sigma=10)
# Phương sai của hai hỗn hợp Gauss
sigma = pm.HalfNormal("sigma", sigma=10)
delta = pm.HalfNormal("delta", sigma=5)
sigma_bgd = pm.Deterministic( "sigma_bgd", sigma + delta)
# Đối với phương sai nền, hãy đảm bảo phương sai nền lớn hơn
# so với phương sai nội bộ bằng cách thêm một delta dương.
# Điều này giúp phá vỡ tính đối xứng giữa
# hai thành phần và cho phép mô hình xác định các ngoại lệ tốt hơn.
# Trọng số hỗn hợp
gs = pm.Beta("gs", alpha=2, beta=2, hình dạng=len (x))
# Khả năng là một hỗn hợp có trọng số
mu = a * x + b
w = pm.math.stack([gs, 1 - gs], axis= 1)
pm.Mixture(
"likelihood",
w=w,
comp_dists=[
pm.Normal.dist(mu =mu, sigma=v),
pm.Normal.dist(mu=mu, sigma=sigma_bgd),
],
được quan sát=y,
)
# Mẫu từ phía sau
trace = pm.sample(1000, điều chỉnh=1000, chuỗi=4)
Vậy khi gig_i gần bằng 1, khả năng bị chi phối bởi Gaussian hồi quy trong khi khi gig_i gần bằng 0, hỗn hợp có xu hướng hướng về Gaussian nền. Trong hình bên dưới, bạn có thể thấy phương pháp này so với hồi quy tuyến tính bình phương nhỏ nhất như thế nào.
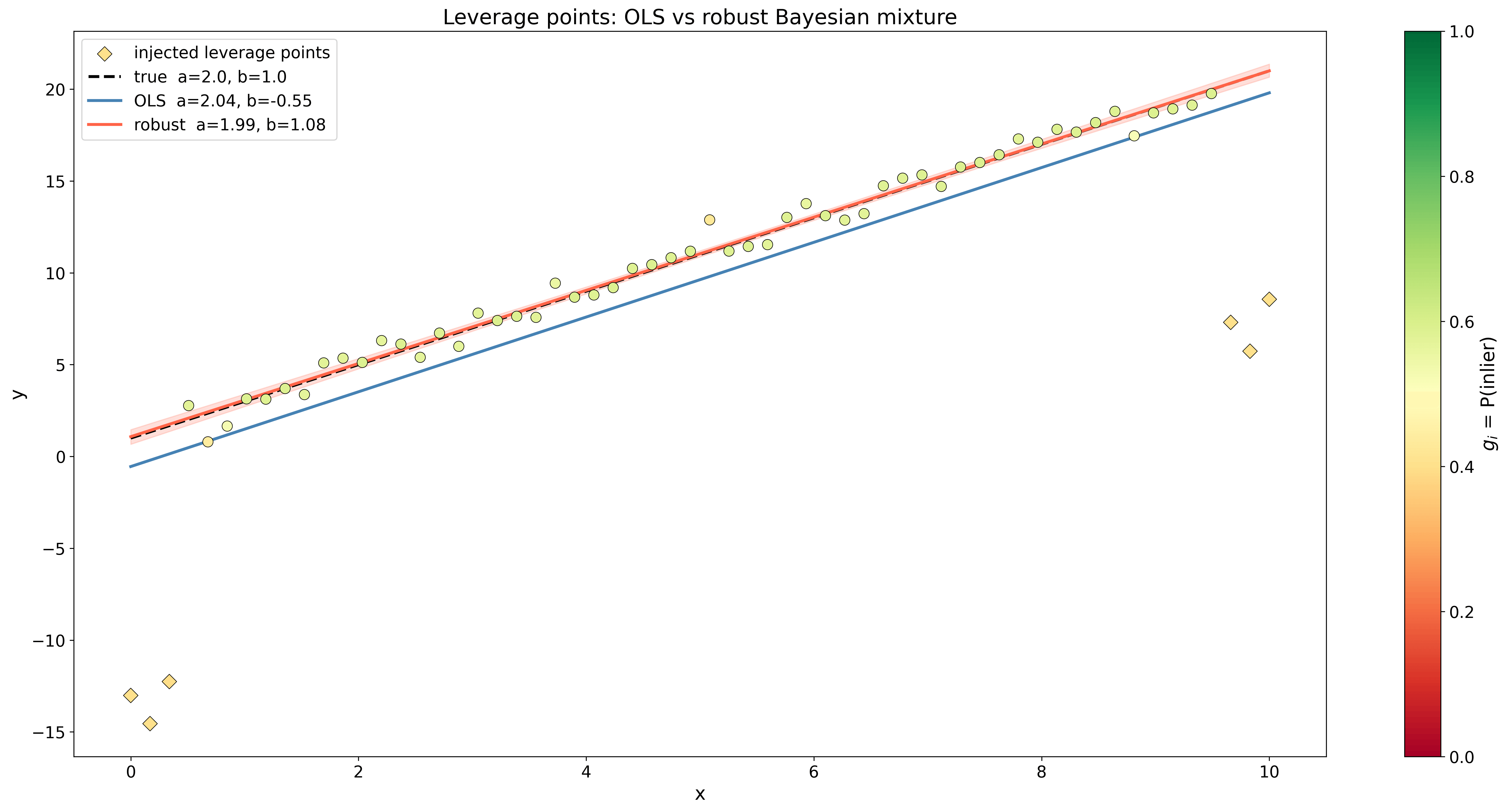
Là một nhà khoa học dữ liệu, bạn có thể đã quen với việc giải quyết các vấn đề như thế này bằng cách sử dụng các hồi quy tuyến tính chính quy như hồi quy Lasso (L1) hoặc Ridge (L2). Về cơ bản, điều này tương đương với việc tìm MAP của tham số dựa trên Laplace hoặc Gaussian trước đó. Nếu bạn sử dụng phiên bản log của định lý Bayes với khả năng hồi quy thì việc tối đa hóa phân phối sau sẽ trở thành tối thiểu hóa
θMAP=minθ(−logP(θ∣X))=minθ∑i(yi−θ0−θ1xi)2σ2+F(θ) . \theta_{\mathrm{MAP}} = \min_\theta (-\log P(\theta | X)) = \min_\theta \sum_i \frac{(y_i - \theta_0 - \theta_1 x_i )^2}{\sigma^2} + F(\theta)~.
Đối với một Gaussian tiên nghiệm P(θ)∼N(0,τ)P(\theta) \sim \mathcal N(0, \tau) nên F(θ)=1τ2∑iθi2F(\theta) = \frac{1}{\tau^2} \sum_i \theta_i^2 trong khi đối với Laplace trước P(θ)∼Laplace(0,τ)P(\theta) \sim \mathrm{Laplace}(0, \tau), thì F(θ)=1τ∑i∣θi∣F(\theta) = \frac{1}{\tau} \sum_i |\theta_i|. Vì vậy, từ trước đến nay, hai kỹ thuật chính quy hóa này chỉ là những lựa chọn khác nhau của các chuyên gia Bayesian!
Kết luận
Tôi hy vọng bài đăng này đã cung cấp cho bạn một số ý tưởng tốt hơn về cách thức hoạt động của thống kê Bayes và điểm chúng tỏa sáng. Nói chung, tôi thấy đây là một khuôn khổ tốt hơn để điều chỉnh dữ liệu không chắc chắn và mặc dù nó nghe có vẻ phức tạp hơn một chút, nhưng bạn có thể thấy từ các ví dụ mã rằng phương pháp MCMC giúp việc tạo các mô hình phức tạp từ dữ liệu và dữ liệu trước đó trở nên rất dễ dàng.
Tài liệu tham khảo
- Chủ nghĩa thường xuyên và chủ nghĩa Bayes: Giới thiệu thực tế
- Giới thiệu hiện đại về lập trình xác suất với PyMC
- Trang chủ thư viện PyMC
Chú thích cuối trang
-
Phải không? Xin hãy nói với tôi rằng tôi không phải là người duy nhất. ↩
-
Thực sự có một số chi tiết khó chịu ở đây vì sự phân bổ rời rạc nhưng CI kết thúc trong khoảng từ 6 đến 7, do đó tùy thuộc vào cách bạn làm tròn, bạn có thể gặp một số vấn đề về phạm vi bao phủ trên CI 95%. Nhưng tôi sẽ giấu cái này dưới tấm thảm. ↩
-
Đối với những người quan tâm, hậu trường của tuyên bố này là Bernstein-von Mises định lý về cơ bản phát biểu rằng trong một giới hạn nào đó, phần sau hội tụ về một phân bố chuẩn tắc xoay quanh ước tính khả năng xảy ra tối đa (câu trả lời thường xuyên) với độ rộng thu hẹp lại. Trong cùng giới hạn này, khả năng chi phối phần trước và kiểm soát hoàn toàn phần sau, do đó các phương pháp tiếp cận theo chủ nghĩa Bayes và người theo chủ nghĩa thường xuyên đều đồng ý. ↩
Tác giả: speckx