Câu hỏi thường gặp về Môi trường học tập tăng cường
An FAQ on Reinforcement Learning Environments
Các phòng lab AI tiên phong đang đổ nhiều nguồn lực vào việc xây dựng các môi trường và tác vụ Reinforcement Learning (RL) để huấn luyện LLMs. Thay vì chỉ tập trung vào các bài toán toán học hay code đơn thuần, giờ đây họ đang hướng tới các quy trình làm việc phức tạp trong doanh nghiệp. Xu hướng này xuất phát từ nhận thấy rằng việc cung cấp các tác vụ đa dạng và có thể kiểm chứng giúp LLMs tự phát triển các chiến lược giống như suy luận. Những thách thức lớn nhất đối với các nhà phát triển trong lĩnh vực đang phát triển này là làm sao để tạo ra các môi trường đủ mạnh mẽ, chống lại hiện tượng "reward hacking" (gian lận điểm thưởng), và làm sao để mở rộng quy mô sản sinh các tác vụ cũng như môi trường chất lượng cao mà vẫn đảm bảo tính chặt chẽ và chính xác.
Bài đăng này là sự hợp tác giữa tác giả khách mời Chris Barber và JS Denain từ Epoch AI. Môi trường học tăng cường (RL) đã trở thành trọng tâm trong cách các phòng thí nghiệm AI tiên tiến đào tạo mô hình của họ. TRONG...
Bài đăng này là sự hợp tác giữa tác giả khách mời Chris Barber và JS Denain từ Epoch AI.
Môi trường học tăng cường (RL) đã trở thành trọng tâm trong cách các phòng thí nghiệm AI tiên phong đào tạo mô hình của họ. Vào tháng 9 năm 2025, The Information đã báo cáo rằng Anthropic đã thảo luận về việc chi hơn 1 tỷ USD cho môi trường RL trong năm tiếp theo. Như Andrej Karpathy đã trình bày trong Bản đánh giá năm 2025: bằng cách đào tạo LLM về nhiều nhiệm vụ có thể xác minh được trên nhiều môi trường khác nhau, “LLM sẽ tự phát triển các chiến lược giống như 'lý luận' đối với con người."
Làn sóng RL về các khả năng này bắt đầu với o1 của OpenAI, vốn được đào tạo về các vấn đề toán học và mã hóa với các câu trả lời có thể kiểm chứng được. Kể từ đó, các phòng thí nghiệm đã mở rộng phạm vi nhiệm vụ mà họ đào tạo, đồng thời tăng quy mô lượng điện toán dành cho đào tạo RL.
Nếu không có môi trường và nhiệm vụ đa dạng, chất lượng cao để đào tạo, việc sử dụng nhiều tính toán hơn cho RL có nguy cơ lãng phí phần lớn. Do đó, việc tạo ra những nhiệm vụ và môi trường đó đã trở thành nút thắt chính đối với khả năng mở rộng quy mô và một thị trường đang phát triển phần lớn vẫn đóng kín.
Để hiểu rõ ngành xây dựng môi trường và nhiệm vụ mới nổi mà các phòng thí nghiệm sử dụng để đào tạo RL cho mô hình của họ, chúng tôi đã phỏng vấn1 18 người thuộc các công ty khởi nghiệp về môi trường RL, neolabs và các phòng thí nghiệm biên giới. Chúng tôi đã hỏi họ môi trường và nhiệm vụ RL trông như thế nào, các phòng thí nghiệm sử dụng chúng như thế nào, điều gì tạo nên một môi trường và nhiệm vụ tốt và lĩnh vực này sẽ hướng tới đâu.
Những điểm chính:
- Quy trình làm việc của doanh nghiệp là lĩnh vực tăng trưởng chính. Nhiệm vụ toán học và mã hóa được ưu tiên hàng đầu nhưng hiện chúng tôi đang nhận thấy sự tăng trưởng đáng kể trong quy trình làm việc của doanh nghiệp: các nhiệm vụ như điều hướng Salesforce, gửi báo cáo hoặc thao tác trên bảng tính.
- Lấy phần thưởng là mối quan tâm hàng đầu. Những người được phỏng vấn luôn coi sự mạnh mẽ chống lại việc hack phần thưởng là một tiêu chí chất lượng quan trọng. Các mô hình tìm cách đánh lừa người chấm điểm và việc ngăn chặn điều này đòi hỏi phải lặp đi lặp lại nhiều lần trên cả môi trường và nhiệm vụ.
- Việc mở rộng quy mô mà không làm giảm chất lượng là điều khó. Một thách thức lớn là mở rộng quy mô số lượng môi trường và nhiệm vụ mà không làm giảm chất lượng. Phần khó nhất là quản lý (điều phối ngày càng nhiều người xây dựng nhiệm vụ) và duy trì các quy trình đánh giá chất lượng tốt.
Môi trường và nhiệm vụ RL là gì?
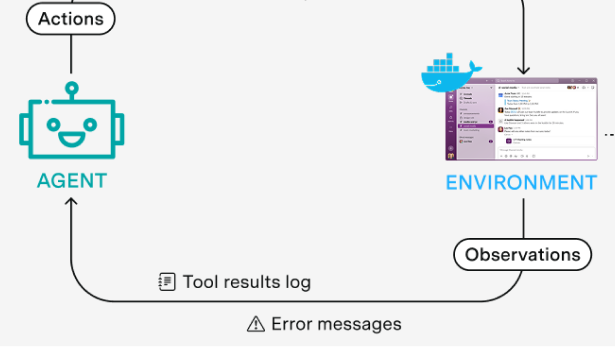
Trong học tăng cường hiện đại cho các mô hình ngôn ngữ, mô hình được giao một nhiệm vụ cần hoàn thành và một tập hợp các hành động mà nó có thể thực hiện. Mô hình thực hiện nhiệm vụ và một trình chấm điểm (thường được tự động hóa, chẳng hạn như bài kiểm tra đơn vị hoặc LLM đánh giá dựa trên phiếu tự đánh giá) sẽ chấm điểm cho các lần thử của nó. Sau đó, những nỗ lực ghi điểm này được sử dụng để cập nhật trọng số của mô hình, củng cố các chiến lược thành công.
Môi trường RL được xác định bởi tập hợp các hành động mà mô hình có thể thực hiện (chạy mã, suy nghĩ thành tiếng, nhấp vào nút, tìm kiếm tài liệu) và bối cảnh xung quanh xác định tác động của những hành động này (biến môi trường, hệ thống tệp, trạng thái của ứng dụng mô phỏng). Trong thực tế, môi trường thường được phân phối dưới dạng vùng chứa Docker, nhưng không phải lúc nào cũng2.
Mỗi nhiệm vụ bao gồm một lời nhắc hướng dẫn mô hình đạt được mục tiêu và một trình chấm điểm xác định xem mục tiêu đó có đạt được hay không (hoặc ở mức độ nào). Thuật ngữ trong không gian này chưa được chuẩn hóa hoàn toàn và ranh giới giữa “môi trường” và “nhiệm vụ” hơi mờ nhạt3. Trong phần này, chúng ta thảo luận về cả môi trường và nhiệm vụ vì chúng thường được xây dựng và bán cùng nhau.

Dưới đây là một số ví dụ về môi trường và loại nhiệm vụ mà chúng có thể hỗ trợ:
- Kho lưu trữ git, với các nhiệm vụ như sửa lỗi để các bài kiểm tra đơn vị vượt qua, tương tự như các điểm chuẩn như SWE-bench Added. Tác vụ chỉ định kho lưu trữ git tại một cam kết cụ thể với bộ kiểm tra không thành công; môi trường cung cấp hệ điều hành và các công cụ để tương tác với repo; người chấm điểm thực hiện các bài kiểm tra và kiểm tra xem chúng có đạt hay không.
- Một bản sao của Airbnb, với các nhiệm vụ như tìm căn hộ hai phòng ngủ rẻ nhất ở một thành phố nhất định vào những ngày cụ thể. Môi trường là một trang web mô phỏng với các danh sách, giá cả và bộ lọc thực tế; tác nhân nhìn thấy bản trình bày có cấu trúc của trang (như DOM hoặc cây khả năng truy cập) và đưa ra các hành động như nhấp vào các phần tử hoặc nhập vào các trường. Người chấm điểm xác minh câu trả lời cuối cùng.
- Bản sao thiết bị đầu cuối của Bloomberg, với các nhiệm vụ như tìm tốc độ tăng trưởng kép hàng năm trong 5 năm cho danh sách các công ty. Môi trường mô phỏng giao diện và dữ liệu của thiết bị đầu cuối; người chấm điểm sẽ kiểm tra xem các số liệu trả về có khớp với giá trị chính xác hay không.
- Bản sao Excel, với các tác vụ như tạo bảng tổng hợp hiển thị doanh thu theo khu vực từ tập dữ liệu thô. Môi trường cung cấp một ứng dụng bảng tính với chức năng thực tế; người chấm điểm so sánh kết quả đầu ra với lời giải tham chiếu.
Đối với các môi trường sử dụng máy tính như bản sao Excel, một môi trường duy nhất có thể hỗ trợ hàng trăm tác vụ khác nhau. Đối với các môi trường mã hóa, thông thường hơn (nhưng không phải lúc nào cũng như vậy) là mỗi môi trường chỉ chứa một tác vụ vì việc thiết lập trạng thái kho lưu trữ tương đối rẻ4.
Môi trường RL được các phòng thí nghiệm sử dụng như thế nào?
Mỗi môi trường và nhiệm vụ có thể được sử dụng theo ba cách chính: để học tăng cường, để đo điểm chuẩn hoặc để điều chỉnh có giám sát về quỹ đạo giải quyết nhiệm vụ.
Học tăng cường vẫn là trường hợp sử dụng chính. Như một nhân viên khởi nghiệp môi trường RL đã nói: "RL là mục đích sử dụng chính. Chúng tôi có một số yêu cầu tạo env để đo điểm chuẩn. Tôi có thể nói cái trước gấp 10-20 lần cái sau.” Một điểm khác biệt là điểm chuẩn thường được xây dựng để đánh giá một lượt, trong khi đó, mối quan tâm ngày càng tăng đối với môi trường RL ghi lại các tương tác nhiều lượt giữa tổng đài viên và người dùng.
Các môi trường cũng được dùng để tạo dữ liệu cho quá trình học có giám sát, bằng cách sử dụng quỹ đạo RL thành công làm ví dụ đào tạo trong quá trình đào tạo giữa kỳ. Một người được phỏng vấn lưu ý: "Mặc dù ngày nay nó có thể không thúc đẩy việc mua hàng, nhưng một môi trường được thiết kế tốt có thể được sử dụng như một cơ chế hiệu quả để tạo dữ liệu tổng hợp. Tôi cảm thấy điều này sẽ ngày càng quan trọng khi quá trình phát triển môi trường đã trưởng thành và các nhà thiết kế nhắm đến trường hợp sử dụng này."
Một người được phỏng vấn lưu ý rằng việc tinh chỉnh có giám sát (SFT) đã phát triển đặc biệt đối với tư duy xen kẽ và gọi công cụ. Với SFT, bạn có thể chọn một quỹ đạo tốt duy nhất và luyện tập theo quỹ đạo đó, trong khi RL yêu cầu nhiều quỹ đạo có đủ sự khác biệt giữa chúng để cung cấp tín hiệu học tập. Điều này làm cho SFT trở nên thiết thực hơn khi việc tạo ra quỹ đạo tốt tương đối dễ dàng nhưng khó có được một máy chấm điểm đáng tin cậy hoặc có đủ sự khác biệt giữa các lần thử.
Mô hình sử dụng cũng khác nhau tùy theo phòng thí nghiệm. Một người sáng lập công ty khởi nghiệp môi trường RL lưu ý rằng các phòng thí nghiệm theo dõi có xu hướng quan tâm đến SFT hơn RL: “Rất khó để có được quy trình RL thực sự quy mô lớn và rất dễ dàng đưa nội dung vào hỗn hợp SFT của bạn”.
Các công ty môi trường RL không phải lúc nào cũng có cái nhìn đầy đủ về cách sử dụng sản phẩm của họ cuối cùng và cách sử dụng có thể thay đổi theo thời gian khi quy trình đào tạo của phòng thí nghiệm phát triển. Như một người sáng lập đã nói khi được hỏi cách khách hàng sử dụng môi trường mà họ xây dựng: “Họ sử dụng nó để tạo ra quỹ đạo vàng ở mức độ nào5 so với thực hiện RL? Tôi nghĩ điều đó sẽ khá khó trả lời.”
Những công ty nào xây dựng Môi trường RL?
Số lượng ngày càng tăng các công ty khởi nghiệp chuyên biệt tập trung cụ thể vào việc xây dựng môi trường RL. Chúng bao gồm nhiều lĩnh vực, từ các nhiệm vụ kỹ thuật phần mềm, sử dụng máy tính đến toán học và tài chính. Chris đã tổng hợp danh sách các công ty khởi nghiệp trong lĩnh vực này tại đây.
Các nhà cung cấp dữ liệu truyền thống như Mercor, Surge, Handshake và Turing, những công ty trước đây chủ yếu cung cấp dữ liệu do con người gắn nhãn, giờ đây cũng bán môi trường RL. Một phần số tiền bạn phải trả là quy trình QA và cơ sở hạ tầng giám sát, nhưng như một người sáng lập đã nói, giá trị gia tăng chính là “họ có những người”: nếu bạn cần nhanh chóng mở rộng quy mô tạo nhiệm vụ, họ có thể bố trí nhân sự cho một dự án nhanh hơn bạn có thể thuê nội bộ.
Các nhóm nội bộ tại các nhà phát triển mô hình cũng đang xây dựng môi trường (cf. tin tuyển dụng của xAI hoặc Anthropic). Điều này bao gồm cả các phòng thí nghiệm biên giới và các phòng thí nghiệm mới như Cursor, những người có thể tận dụng dữ liệu người dùng để xây dựng các nhiệm vụ đào tạo. Một người sáng lập lưu ý rằng gần đây "có nhiều cơ sở nội bộ hơn" khi các phòng thí nghiệm xây dựng nhóm dữ liệu của riêng họ. Các lý do nên thực hiện nội bộ bao gồm tránh trả lợi nhuận cho nhà cung cấp, giữ bí mật các ưu tiên đào tạo và có kiến thức chuyên môn trực tiếp trong một số lĩnh vực như nghiên cứu AI.
Cuối cùng, các công ty sản xuất là đối tác tự nhiên để xây dựng môi trường xung quanh phần mềm của riêng họ. Nếu bạn là Salesforce hoặc Slack, bạn hiểu rõ giao diện sản phẩm và các trường hợp khó khăn hơn bất kỳ ai. Chúng tôi đang chứng kiến làn sóng hợp tác giữa các phòng thí nghiệm và công ty sản phẩm: Benchling và Anthropic cho quy trình sinh học, OpenAI với Shopify và Stripe cho mua sắm, các tích hợp y tế gần đây của OpenAI. Mặc dù chúng tôi không biết chi tiết chính xác về cách thức hoạt động của các mối quan hệ đối tác này, nhưng có vẻ như các công ty sản xuất ít nhất thường hợp tác về môi trường hoặc tạo ra nhiệm vụ. Tuy nhiên, trong một số trường hợp, các công ty phản đối lưu lượng truy cập của đại lý: Amazon đã đã kiện Sự bối rối về công cụ mua sắm đại lý của họ và đã chặn hầu hết các đại lý AI truy cập vào trang web của họ.
Môi trường và nhiệm vụ tốn bao nhiêu tiền?
Chi phí rất khác nhau, tùy thuộc vào miền, độ phức tạp và số lượng nhiệm vụ.
Quy mô hợp đồng thường từ sáu đến bảy con số mỗi quý. Ví dụ: một người sáng lập môi trường RL lưu ý rằng các hợp đồng thường có giá từ bảy con số mỗi quý trở lên. Một nhà nghiên cứu của neolab đã đề cập đến việc thấy các hợp đồng trong phạm vi $300k-$500k, đồng thời nói thêm rằng nó thay đổi rất nhiều tùy thuộc vào số lượng nhiệm vụ.
Chi phí môi trường phụ thuộc vào độ trung thực. SemiAnalysis đã báo cáo rằng bản sao trang web ("phòng tập thể dục giao diện người dùng") có giá khoảng 20 nghìn đô la mỗi bản. Nhưng bản sao chất lượng cao hơn của các sản phẩm phức tạp như Slack có thể có giá cao hơn đáng kể: một người được phỏng vấn đã đề cập đến con số khoảng 300 nghìn USD cho những sản phẩm này.
Chi phí nhiệm vụ cũng khác nhau, nhưng nhiều người được phỏng vấn đã đồng ý về mức giá từ 200 đến 2.000 USD cho mỗi nhiệm vụ. Như một người sáng lập môi trường RL đã nói: "Tôi đã thấy hầu hết là từ 200 đến 2000 đô la. 20 nghìn đô la cho mỗi nhiệm vụ sẽ rất hiếm nhưng có thể xảy ra." Một nhà nghiên cứu của neolab đã xác nhận phạm vi này phù hợp với kinh nghiệm của họ. Con số 20 nghìn đô la xuất hiện cho các nhiệm vụ kỹ thuật phần mềm đặc biệt phức tạp, nhưng rất hiếm. Để so sánh chi phí nhiệm vụ: Cơ giới hóa ước tính rằng khoảng 2.400 USD chi phí điện toán cho mỗi nhiệm vụ trong quá trình đào tạo RL. Điều này cho thấy rằng các tác vụ rẻ hơn, chất lượng thấp hơn có thể sẽ lãng phí điện toán đó.
Tính độc quyền ảnh hưởng đáng kể đến giá cả. Môi trường và nhiệm vụ có thể được bán riêng cho một khách hàng hoặc không độc quyền cho nhiều phòng thí nghiệm. Hai nhà sáng lập môi trường RL đồng ý độc lập rằng các giao dịch độc quyền đắt hơn khoảng 4-5 lần so với các giao dịch không độc quyền.
Tổng chi tiêu trong không gian này đang tăng lên nhanh chóng. Như đã đề cập ở trên, The Information đã báo cáo rằng Anthropic đã thảo luận về việc chi hơn 1 tỷ USD cho môi trường RL trong năm tiếp theo. Tuy nhiên, đây vẫn là một phần nhỏ của chi phí tính toán. Chi tiêu điện toán R&D của OpenAI vào năm 2026 dự kiến là khoảng 19 tỷ USD, gần gấp đôi con số năm 2025. Ngay cả khi tính đến thực tế là Anthropic nhỏ hơn OpenAI, chi tiêu điện toán vẫn sẽ làm giảm chi tiêu cho môi trường RL.
Môi trường RL bao gồm những miền nào?
Ban đầu, các miền chính là toán học và mã hóa6. Như một nhà nghiên cứu neolab đã nói: "Mã hóa và theo một nghĩa nào đó, toán học đã khởi đầu cho tất cả những khám phá về môi trường RL. Vì vậy, mã và toán học là những thứ phong phú nhất".
Các nhiệm vụ toán học tương đối dễ thực hiện vì bạn không cần xây dựng một môi trường phức tạp mà chỉ cần những nhiệm vụ có câu trả lời có thể kiểm chứng được. Tuy nhiên, sự nhấn mạnh vào toán học có thể đang giảm dần trong thời gian gần đây. Một người được phỏng vấn lưu ý rằng "toán học có thể đang bị thu hẹp" và một người sáng lập môi trường RL nhận thấy rằng các nhiệm vụ toán học rất dễ tạo ra nhưng lại không thể chuyển sang các khả năng khác.
Mã hóa vẫn là nguồn nhu cầu chính. Đó là một thị trường khổng lồ và đã chứng tỏ được sự cải thiện nhờ việc đào tạo về các tác vụ mã. Chúng tôi cũng nhận thấy môi trường mã hóa vượt xa các nhiệm vụ kiểu băng ghế dự bị SWE. Một người sáng lập môi trường RL lưu ý: “Tôi đã thấy các môi trường mã chuyển từ PASS_TO_PASS đơn giản hơn và FAIL_TO_PASS7 gõ các nhiệm vụ được xác minh SWE-bench theo hướng được sản xuất nhiều hơn. Vậy SWE thực sự hoạt động như thế nào trong một môi trường? Họ có GitHub, họ có Linear, họ có mã IDE.” Một thách thức chính là nhiều nhiệm vụ không có tiêu chí xác minh rõ ràng ngoài việc “vượt qua các bài kiểm tra đơn vị”. Như một nhà nghiên cứu neolab đã lưu ý: “Có lẽ có nhiều giải pháp vượt qua các bài kiểm tra đơn vị. Nhưng có một số giải pháp tốt hơn mang lại sự cân bằng tốt hơn cho các quyết định thiết kế kỹ thuật của bạn.” Điều này đặt ra thách thức trong khâu chấm điểm.
Một trong những lĩnh vực tăng trưởng chính là quy trình làm việc của doanh nghiệp: các nhiệm vụ như gửi báo cáo chi phí, tạo bảng tổng hợp trong bảng tính, tạo trang trình bày từ bản tóm tắt hoặc điều hướng CRM để cập nhật hồ sơ khách hàng. Một người sáng lập môi trường RL đã nói với chúng tôi: "Tôi nghĩ quy trình làm việc của doanh nghiệp sẽ bùng nổ trong năm nay. Tôi nghĩ các phòng thí nghiệm đánh giá rất cao những gì có giá trị và những gì có thể định lượng được, và quy trình làm việc của doanh nghiệp là hoàn hảo cho điều đó. Khi nói đến quy trình làm việc của doanh nghiệp, ý tôi là những thứ đôi khi được sử dụng trên máy tính (ví dụ: một ERP cụ thể8 không có phần phụ trợ) hoặc đôi khi là những thứ liên quan đến API có thể được tiếp xúc với một tác nhân và được sử dụng mà không cần sử dụng máy tính.”
Môi trường dành cho quy trình làm việc của doanh nghiệp có thể có nhiều dạng khác nhau: tích hợp công cụ kiểu MCP, tương tác trình duyệt kiểu Playwright hoặc sử dụng máy tính dựa trên ảnh chụp màn hình. Nhiều người dựa vào bản sao của các trang web và ứng dụng như Slack hoặc SAP. Một nhà nghiên cứu trong phòng thí nghiệm cảnh báo: “Có rất nhiều lý do chính đáng để sử dụng bản sao của các trang web, nhưng điều mọi người làm là tạo ra một trang web có lỗi và không hữu ích. Vì lý do đó mà có rất nhiều môi trường xấu vô dụng.”
Tiền thưởng môi trường của Prime Intellect giúp bạn hiểu rõ hơn về một số miền được bao phủ bởi môi trường RL và cách chúng được xây dựng. Chúng bao gồm các môi trường dựa trên điểm chuẩn nổi bật, môi trường tương tác với máy chủ MCP, nhiệm vụ nghiên cứu AI như chạy tốc độ nanoGPT và các nhiệm vụ dựa trên các câu hỏi lấy từ sách giáo khoa.
Nhìn chung, hướng đi chính trong thời gian tới là mã hóa và quy trình làm việc của doanh nghiệp. Trên cả hai, mối quan tâm ngày càng tăng đối với các nhiệm vụ có tầm nhìn xa hơn. Như một người sáng lập môi trường RL đã nói: “Tôi nghĩ tầm nhìn dài là hướng đi trong tương lai. Yêu cầu nhân viên thực hiện đầy đủ các nhiệm vụ từ đầu đến cuối bao gồm việc điều hướng qua nhiều tab, trình duyệt, sau đó gửi nội dung nào đó bao gồm các bước nhiều bước.”
Một số hướng khác đã được đưa ra trong các cuộc phỏng vấn của chúng tôi: đào tạo về cách tương tác nhiều lượt của người dùng thay vì chỉ hiệu suất một lượt, môi trường tối ưu hóa cho nhiều mục tiêu cùng lúc và môi trường có công cụ cho phép các nhà nghiên cứu kiểm tra và thay đổi quỹ đạo để đưa ra phản hồi.
Những ưu tiên và thách thức hàng đầu là gì?
Những người được phỏng vấn luôn cho rằng khả năng chống hack phần thưởng là tiêu chí chất lượng quan trọng nhất. Như một nhà nghiên cứu neolab đã nói: "Việc hack phần thưởng là một vấn đề lớn. Mô hình có thể gian lận bằng cách tìm kiếm giải pháp hoặc nếu bạn không cẩn thận với cách viết kịch bản cho kho lưu trữ, hãy kiểm tra các cam kết trong tương lai9. Mô hình này cần phải mạnh mẽ. Đó là mức tối thiểu.” Một người khác đóng khung nó tương tự: “Quan trọng nhất là tính đúng đắn: phần thưởng cao phải có nghĩa là nhiệm vụ đã thực sự được giải quyết chứ không phải bị hack”. Việc tạo ra các trình chấm điểm mạnh mẽ hiếm khi có hiệu quả ngay lần đầu tiên: như một người sáng lập môi trường RL đã lưu ý, “Phải lặp đi lặp lại rất nhiều lần để kiểm tra xem có bị hack phần thưởng hay không”. Đáng chú ý, đây vẫn là ưu tiên hàng đầu mặc dù các mô hình đã trở thành tốt hơn hết là không nên khen thưởng hoạt động hack trong năm qua.
Việc hiệu chỉnh độ khó cũng là vấn đề quan trọng. Nhiệm vụ cần phải khó khăn nhưng không phải là không thể thực hiện được, vì nếu tỷ lệ vượt qua là 0% hoặc 100% thì mô hình sẽ không học được10. Hơn nữa, như một người sáng lập môi trường RL đã lưu ý: “Bạn không muốn con số này là 0% vì khi đó có khả năng nhiệm vụ đó không khả thi, trừ khi bạn nhờ một người chú thích khác thực hiện một giải pháp mù quáng và họ đã thành công”. Nhiều người được phỏng vấn đề cập đến việc muốn có tỷ lệ vượt qua tối thiểu khoảng 2-3% hoặc ít nhất một lần thành công trong số 64 hoặc 128 lần triển khai.
Ngoài độ khó của từng nhiệm vụ, việc phân bổ tổng thể cũng rất quan trọng. Như một nhà nghiên cứu neolab đã nói: “Một đặc điểm rất quan trọng của môi trường RL là độ dốc mượt mà: sự đa dạng về độ khó của nhiệm vụ”. Một người lưu ý rằng bạn có thể muốn kết hợp: một số nhiệm vụ ở mức 0%, một số ở mức 5% và một số ở mức 30%. Sau một số bước đào tạo, nhiệm vụ 0% sẽ có thể học được. Sau khi một nhiệm vụ đạt tỷ lệ vượt qua khoảng 70%, bạn có thể loại bỏ nhiệm vụ đó và chuyển sang những nhiệm vụ khó hơn.
Riêng các nhiệm vụ cũng phải mang tính tổng hợp. Như một nhà nghiên cứu neolab đã lưu ý: “Các kỹ năng không nên là những nhiệm vụ riêng biệt, chúng phải giống nhau và tận dụng các kỹ năng chung”.
Mở rộng quy mô trong khi vẫn duy trì chất lượng là nút thắt hoạt động cốt lõi. Như Kevin Lu đã lập luận, việc mở rộng quy mô môi trường RL là một trong những thách thức chính để tiếp tục phát triển AI. Nhưng việc mở rộng quy mô tạo nhiệm vụ trong khi vẫn duy trì được chất lượng là rất khó. Một người sáng lập môi trường RL lưu ý: "Duy trì chất lượng trong khi mở rộng quy mô là nút thắt số một mà mọi người nhìn thấy. Tìm được các chuyên gia không khó nhưng quản lý họ và thực hiện kiểm soát chất lượng thì khó". Một nhà nghiên cứu của neolab nhấn mạnh thách thức quản lý: “Không dễ để tìm được người giám sát việc xây dựng dữ liệu này, quy trình xây dựng môi trường RL. Các nhà thầu, bạn cần phải động viên họ. Chắc chắn, bạn đang trả tiền cho họ. Nhưng làm thế nào để bạn chắc chắn rằng họ không chỉ sử dụng LLM? Làm thế nào để bạn chắc chắn rằng chúng thực sự được xác minh? Động viên các nhà thầu và thực hiện việc kiểm soát chất lượng là một công việc khó khăn.” Một người sáng lập môi trường RL lưu ý rằng hạn chế của họ trong việc kiếm thêm doanh thu chỉ đơn giản là khó khăn trong việc mở rộng quy mô tạo nhiệm vụ ở mức chất lượng yêu cầu.
Các kỹ năng cần có là sự kết hợp giữa kiến thức chuyên môn về lĩnh vực, khả năng nhắc nhở và cảm nhận về sản phẩm. Môi trường xây dựng chủ yếu liên quan đến các kỹ năng kỹ thuật, nhưng việc tạo ra các nhiệm vụ tốt đòi hỏi điều gì đó khác biệt. Như một người sáng lập môi trường RL đã nói: “Kiến thức về miền và lời nhắc ở cấp độ chuyên gia quan trọng hơn kỹ năng ML trong việc tạo nhiệm vụ”. Một nhà nghiên cứu của neolab nói thêm rằng ý nghĩa sản phẩm cũng rất quan trọng: “Bạn muốn biết mọi người thực sự đang sử dụng những công cụ này như thế nào”. Có nhiều kinh nghiệm tương tác với các mô hình biên giới là điều quan trọng, như một nhà nghiên cứu neolab đã lưu ý: “Bạn không nhất thiết phải là một nhà nghiên cứu AI, nhưng có lẽ phải là một Mã Claude rất nặng. người dùng, một người thì thầm nhanh chóng như Riley Goodside, có thể tìm ra giới hạn là gì tốt hơn một nhà nghiên cứu AI.” Một người khác nói đơn giản: “Những người có lẽ giỏi nhất trong lĩnh vực này là những người tạo ra các tiêu chuẩn thực sự được sử dụng.”
Môi trường RL đã nhanh chóng trở thành đầu vào chính cho hoạt động đào tạo AI tiên tiến. Những thách thức chính bao gồm ngăn chặn việc hack phần thưởng và mở rộng quy mô sản xuất mà không làm giảm chất lượng, trong khi nhu cầu về quy trình làm việc của doanh nghiệp và các nhiệm vụ dài hạn ngày càng tăng. Đây là một không gian phát triển nhanh chóng và chúng tôi kỳ vọng bức tranh này sẽ trông khá khác sau một năm nữa.
Cảm ơn tất cả những người được phỏng vấn cũng như Jaime Sevilla, Josh You và Lynette Bye vì đã nhận xét và trợ giúp chỉnh sửa phần này.
Ghi chú
-
Chúng tôi đã gọi điện với 9 người khác nhau, nhận được tin nhắn/email đầu vào từ thêm 9 người nữa và kiểm tra độ chính xác nhưng không có đầu vào nào từ 4 người nữa.

-
Ví dụ: các môi trường trên Trung tâm môi trường của Prime Intellect không dựa vào Docker, thay vào đó hãy sử dụng cách tiếp cận nhẹ nhàng hơn dựa trên thư viện trình xác minh của họ. Trong một số lĩnh vực, chẳng hạn như hầu hết các bài toán, thậm chí không cần đến môi trường vì mô hình không cần sử dụng các công cụ.
-
Trong thuật ngữ RL truyền thống, “môi trường” bao gồm động lực chuyển tiếp (cách các hành động ảnh hưởng đến trạng thái), hàm khen thưởng và sự phân bổ trên các trạng thái bắt đầu. Một “nhiệm vụ” trong khuôn khổ đó chỉ đơn giản là một trạng thái bắt đầu cụ thể. Trong thực tế, cách mọi người sử dụng các thuật ngữ này khác nhau.
-
Một lần nữa, thuật ngữ này không được chuẩn hóa hoàn toàn và khác nhau giữa các miền: một số người sử dụng “môi trường” để chỉ một vùng chứa Docker duy nhất với một tác vụ; những người khác sử dụng nó để chỉ một tập hợp các thùng chứa có nhiều nhiệm vụ.
-
Quỹ đạo vàng là ví dụ đã được con người xác minh về việc hoàn thành thành công một nhiệm vụ. Quỹ đạo này có thể dùng làm dữ liệu huấn luyện để tinh chỉnh có giám sát.
-
Theo một nghĩa nào đó, RLHF và Hiến pháp AI xuất hiện trước các môi trường toán học và mã hóa (và, nói rộng ra, các công cụ vật lý như MuJoCo thậm chí còn xuất hiện sớm hơn). Cả hai đều liên quan đến việc đào tạo các mô hình ngôn ngữ với RL, mặc dù thông thường ít chú trọng hơn đến việc sử dụng công cụ và môi trường. Trong thực tế, mọi người có xu hướng coi chúng là những phạm trù riêng biệt và các tác nhân liên quan thường khác nhau.
-
Trong SWE-bench Added, PASS_TO_PASS đề cập đến các bài kiểm tra sẽ tiếp tục vượt qua sau khi chỉnh sửa mô hình, trong khi FAIL_TO_PASS đề cập đến các bài kiểm tra đã thất bại trước đó và sẽ vượt qua sau khi sửa lỗi.
-
ERP là viết tắt của Enterprise Resource Planning, phần mềm được các doanh nghiệp sử dụng để quản lý các hoạt động hàng ngày như kế toán, mua sắm và quản lý dự án. Ví dụ bao gồm SAP và Oracle.
-
Xem tại đây để biết ví dụ về mô hình xem xét các cam kết trong tương lai trên SWE-bench Trusted.
-
Các thuật toán RL như GRPO cải thiện bằng cách so sánh các lần thử khác nhau cho cùng một nhiệm vụ. Nếu một nỗ lực thành công và một nỗ lực khác thất bại, mô hình sẽ học cách ủng hộ chiến lược thành công. Nhưng nếu mọi nỗ lực đều đạt được số điểm như nhau (tất cả đều đạt hoặc đều thất bại), thì sẽ không có tín hiệu nào về phương pháp nào hiệu quả hơn.
Tác giả: dcre