Hướng dẫn về kỹ thuật ngữ cảnh cho LLM
A Guide to Context Engineering for LLMs
Bài viết này bàn về "context engineering" (kỹ thuật xây dựng ngữ cảnh) cho LLMs, nhấn mạnh thách thức khi tích hợp nhiều nguồn dữ liệu khác nhau để cung cấp cho LLMs thông tin liên quan, giúp chúng đưa ra quyết định tốt hơn. Việc xây dựng ngữ cảnh hiệu quả là chìa khóa để khai phá tối đa tiềm năng của LLMs, vượt xa việc chỉ dùng prompt đơn thuần, nhằm tạo ra các ứng dụng AI mạnh mẽ và nhận thức ngữ cảnh tốt hơn. Các developer nên tập trung xây dựng các data pipelines và chiến lược vững chắc để cung cấp ngữ cảnh phù hợp cho LLMs, vì đây sẽ là yếu tố tạo nên sự khác biệt quan trọng khi xây dựng các hệ thống AI tiên tiến.
Trong bài viết này, chúng ta sẽ xem xét cách LLM thực sự xử lý thông tin bạn cung cấp cho họ, kỹ thuật ngữ cảnh là gì và các chiến lược có thể giúp ích cho nó.
Việc cung cấp nhiều thông tin hơn cho LLM có thể làm nó kém thông minh đi. Một nghiên cứu năm 2025 của Chroma đã thử nghiệm 18 trong số các mô hình ngôn ngữ mạnh nhất hiện có, bao gồm GPT-4.1, Claude và Gemini, và phát hiện ra rằng mọi mô hình đều hoạt động kém hơn khi lượng đầu vào tăng lên.
Sự suy giảm này không hề nhỏ. Một số mô hình giữ vững độ chính xác 95% rồi lao dốc xuống 60% khi đầu vào vượt qua một ngưỡng nhất định.
Phát hiện này phá vỡ một trong những huyền thoại phổ biến nhất về việc làm việc với LLM rằng nhiều ngữ cảnh hơn luôn tốt hơn. Thực tế là LLM có những điểm mù kiến trúc khiến cho những gì bạn đưa vào và cách bạn cấu trúc nó quan trọng hơn nhiều so với số lượng bạn bao gồm.
Ngành khoa học kỹ thuật để làm đúng điều này được gọi là context engineering (kỹ thuật ngữ cảnh).
Trong bài viết này, chúng ta sẽ tìm hiểu cách LLM xử lý thông tin bạn cung cấp, context engineering là gì và các chiến lược có thể giúp ích cho nó.
Thuật ngữ chính
Trước khi đi xa hơn, có ba thuật ngữ thường xuyên xuất hiện khi nói về LLM. Làm rõ những điều này trước sẽ giúp mọi thứ theo sau dễ dàng hơn để suy luận.
Tokens: Đây là đơn vị mà LLM suy nghĩ. Chúng không phải là từ đầy đủ, mà là các đoạn văn bản trung bình khoảng ba phần tư một từ. Từ "context" là một token, trong khi từ "engineering" bị chia thành hai. Mọi phần văn bản mà mô hình xử lý, từ câu hỏi của bạn, hướng dẫn của nó, cho đến bất kỳ tài liệu nào bạn đã bao gồm, đều được đo bằng tokens.
Context Window: Đây là tổng số token mà mô hình có thể nhìn thấy cùng một lúc trong một tương tác duy nhất. Mọi thứ phải nằm gọn trong cửa sổ này: các hướng dẫn hệ thống xác định hành vi của mô hình, lịch sử hội thoại, bất kỳ tài liệu hoặc dữ liệu bên ngoài nào bạn đã đưa vào và câu hỏi thực tế của bạn. Các mô hình hiện đại quảng cáo cửa sổ ngữ cảnh dao động từ 128.000 đến hơn 2 triệu token. Con số đó nghe có vẻ khổng lồ, nhưng như chúng ta sẽ thấy, lớn hơn không nhất thiết tốt hơn một cách trực tiếp.
-
Chú ý: Đây là cơ chế mà mô hình sử dụng để xác định xem token nào quan trọng với token nào khác. Trước khi tạo mỗi token mới cho phản hồi của mình, mô hình sẽ so sánh nó với mọi token khác hiện có trong cửa sổ ngữ cảnh. Điều này mang lại cho LLM khả năng kết nối các ý tưởng qua các đoạn văn bản dài, nhưng nó cũng là nguồn gốc của những hạn chế quan trọng nhất của chúng.
LLM Xử Lý Ngữ Cảnh Như Thế Nào
Khi chúng ta gửi văn bản cho LLM, nó không đọc từ trên xuống dưới theo cách con người làm. Cơ chế attention so sánh mọi token với mọi token khác để tính toán mối quan hệ, có nghĩa là mô hình, về nguyên tắc, có thể kết nối một ý tưởng từ câu đầu tiên của đầu vào với một ý tưởng ở câu cuối cùng. Tuy nhiên, sức mạnh này đi kèm với hai cái giá phải trả.
>Cái giá đầu tiên là về tính toán. Việc tăng gấp đôi số lượng token trong cửa sổ ngữ cảnh sẽ làm tăng gấp bốn lần lượng tính toán cần thiết. Ngữ cảnh dài hơn sẽ chậm hơn và tốn kém hơn theo tỷ lệ nghịch.
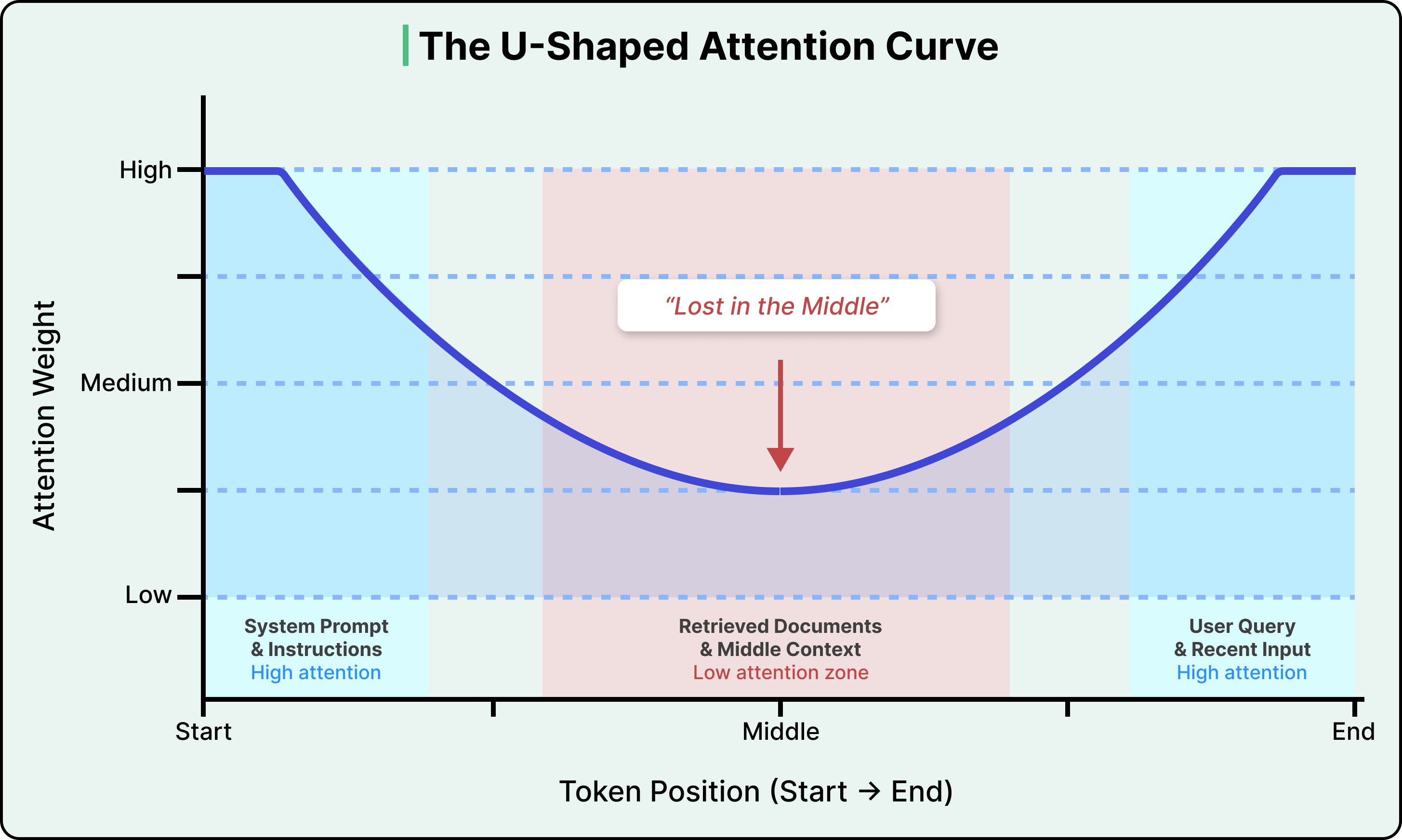
Cái giá thứ hai còn hệ trọng hơn. Attention không được phân bổ đều trên cửa sổ ngữ cảnh. Nghiên cứu đã chỉ ra một cách nhất quán rằng LLM tập trung nhiều nhất vào các token ở đầu và cuối của đầu vào, với sự sụt giảm đáng kể ở phần giữa. Điều này được gọi là vấn đề "lost in the middle" (lạc lõng ở giữa), và nghiên cứu đã phát hiện ra rằng độ chính xác có thể giảm hơn 30% khi thông tin liên quan được đặt ở giữa đầu vào so với đầu hoặc cuối.
Xem sơ đồ dưới đây cho thấy biểu đồ attention:
Đây không phải là lỗi của bất kỳ mô hình cụ thể nào, mà là một thuộc tính cấu trúc về cách các transformer (kiến trúc mạng nơ-ron cung cấp năng lượng cho hầu hết các LLM hiện đại) mã hóa vị trí của các token.
Phương pháp mã hóa vị trí được sử dụng trong hầu hết các LLM hiện đại (gọi là Rotary Position Embedding, hoặc RoPE) tạo ra hiệu ứng suy giảm khiến các token ở xa cả đầu và cuối chuỗi nằm trong vùng có attention thấp. Các mô hình mới hơn đã giảm mức độ nghiêm trọng, nhưng chưa có mô hình sản xuất nào loại bỏ hoàn toàn nó.
Ý nghĩa thực tế là vị trí của thông tin trong đầu vào quan trọng như chính thông tin đó. Nếu chúng ta dán một tài liệu dài vào LLM, mô hình có khả năng cao sẽ bỏ sót thông tin bị chôn vùi ở các trang giữa.
Tại Sao Ngữ Cảnh Lớn Hơn Có Thể Gây Hại
Sự phân bổ attention không đều là một vấn đề, nhưng có một mô hình rộng hơn làm trầm trọng thêm nó, được gọi là "context rot" (suy thoái ngữ cảnh).
Suy thoái ngữ cảnh (context rot) là sự suy giảm hiệu suất của LLM khi độ dài đầu vào tăng lên, ngay cả với các tác vụ đơn giản. Nghiên cứu năm 2025 của nhóm nghiên cứu Chroma đã kiểm tra 18 mô hình tiên tiến và phát hiện ra rằng sự suy giảm này không diễn ra từ từ. Các mô hình có thể duy trì độ chính xác gần như hoàn hảo cho đến một độ dài ngữ cảnh nhất định, sau đó hiệu suất giảm đột ngột một cách khó lường, thay đổi theo từng mô hình và từng tác vụ theo những cách khiến việc dự đoán đáng tin cậy khi nào bạn sẽ gặp điểm giới hạn là không thể.
Tại sao lại xảy ra điều này?
Mỗi token bạn thêm vào cửa sổ ngữ cảnh đều tiêu tốn một ngân sách chú ý hữu hạn. Thông tin không liên quan sẽ chôn vùi thông tin quan trọng trong các vùng có mức độ chú ý thấp, và nội dung nghe có vẻ liên quan nhưng thực tế không hữu ích sẽ làm nhầm lẫn khả năng xác định cái gì là quan trọng của mô hình. Mô hình không trở nên thông minh hơn với nhiều đầu vào hơn, mà dường như bị phân tâm.
Ngoài ra, LLM là mô hình không trạng thái. Chúng không có bộ nhớ giữa các lần gọi, và mỗi tương tác bắt đầu hoàn toàn mới. Khi có một cuộc trò chuyện đa lượt với LLM như ChatGPT, và nó dường như "nhớ" những gì chúng ta đã nói trước đó, đó là vì hệ thống đang đưa lại lịch sử trò chuyện vào cửa sổ ngữ cảnh mỗi lần. Bản thân mô hình không nhớ gì cả, có nghĩa là ai đó, hoặc một hệ thống nào đó, phải quyết định cho mỗi lần gọi thông tin nào cần đưa vào, thông tin nào cần bỏ qua và cách cấu trúc nó.
Ngoài ra còn có một khoảng cách đáng kể giữa quảng cáo và thực tế. Các mô hình quảng cáo cửa sổ ngữ cảnh hàng triệu token, và chúng vượt qua các bài kiểm tra tiêu chuẩn đơn giản ở các độ dài đó. Tuy nhiên, độ dài ngữ cảnh hiệu quả, nơi mô hình thực sự sử dụng thông tin một cách đáng tin cậy, thường nhỏ hơn nhiều. Vượt qua bài kiểm tra "kim trong đống rơm" (tìm một câu được cài cắm trong một tài liệu dài) rất khác với việc tổng hợp một cách đáng tin cậy thông tin trải rộng trên hàng trăm trang.
Định nghĩa Kỹ thuật Ngữ cảnh (Context Engineering)
Kỹ thuật ngữ cảnh là việc thiết kế, lắp ráp và quản lý toàn bộ môi trường thông tin mà LLM nhìn thấy trước khi nó tạo ra phản hồi. Nó vượt ra ngoài việc viết một hướng dẫn duy nhất tốt để điều phối mọi thứ lấp đầy cửa sổ ngữ cảnh, sao cho mô hình có chính xác những gì nó cần cho tác vụ hiện tại và không gì khác.
Để hiểu điều này bao gồm những gì, bạn nên xem những gì thực sự cạnh tranh cho không gian bên trong cửa sổ ngữ cảnh. Có sáu loại ngữ cảnh trong một lần gọi LLM điển hình:
Chỉ dẫn hệ thống (các quy tắc hành vi, vai trò và hướng dẫn mà mô hình tuân theo)
Đầu vào của người dùng (câu hỏi hoặc lệnh thực tế của bạn)
Lịch sử trò chuyện (bộ nhớ ngắn hạn của phiên hiện tại)
Kiến thức đã truy xuất (tài liệu, kết quả cơ sở dữ liệu hoặc phản hồi API được lấy từ các nguồn bên ngoài)
Mô tả công cụ (định nghĩa các công cụ mà mô hình có thể gọi và cách sử dụng chúng)
Kết quả công cụ (kết quả trả về từ các lệnh gọi công cụ trước đó)
Câu hỏi thực tế của người dùng thường chỉ là một phần nhỏ trong tổng số token.
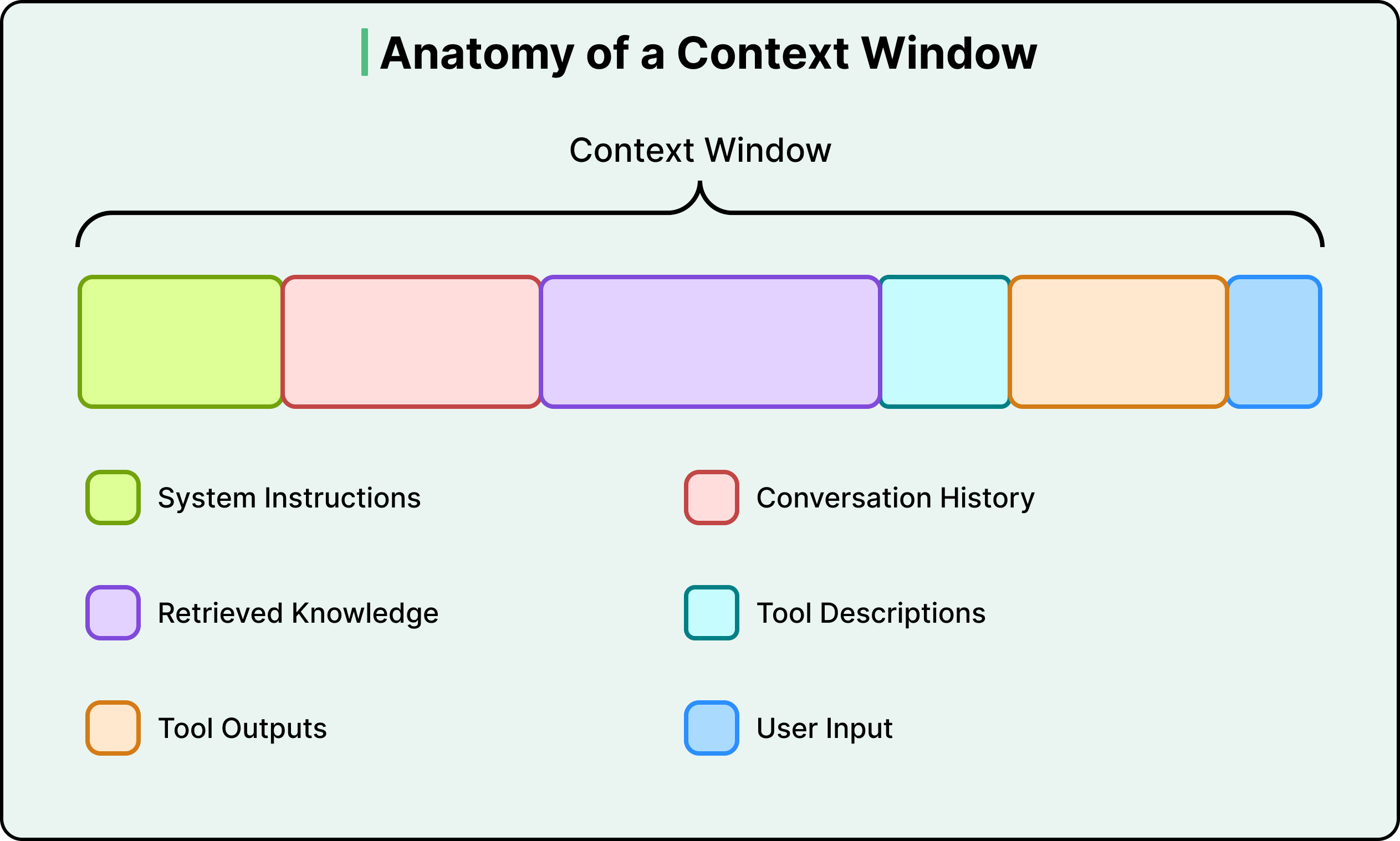
Phần còn lại là cơ sở hạ tầng, và cơ sở hạ tầng đó là thứ mà context engineering thiết kế.
Điều này cũng làm rõ sự khác biệt giữa context engineering và prompt engineering. Prompt engineering đặt câu hỏi: "Làm thế nào để diễn đạt hướng dẫn của tôi để đạt được kết quả tốt nhất?" Mặt khác, Context engineering đặt câu hỏi: "Mô hình cần thấy gì ngay bây giờ, và làm thế nào để tôi tổng hợp tất cả chúng một cách linh hoạt?"
Prompt engineering là một thành phần trong context engineering, tập trung vào lớp hướng dẫn, trong khi context engineering bao gồm toàn bộ hệ thống thông tin xung quanh mô hình. Như Andrej Karpathy đã nói trong một bài đăng được tham khảo rộng rãi, context engineering là "nghệ thuật và khoa học tinh tế của việc lấp đầy cửa sổ ngữ cảnh với thông tin phù hợp cho bước tiếp theo."
Hai người sử dụng cùng một mô hình có thể nhận được kết quả hoàn toàn khác nhau. Mô hình là giống nhau, nhưng ngữ cảnh khác nhau, và context engineering là yếu tố quyết định mọi thứ.
Các Chiến Lược Cốt Lõi
Các nhà phát triển đã hội tụ về bốn chiến lược rộng để quản lý ngữ cảnh, được phân loại là write, select, compress và isolate. Mỗi chiến lược là một phản ứng trực tiếp với một ràng buộc cụ thể mà chúng ta đã đề cập.
Write: Lưu Ngữ Cảnh Bên Ngoài
Ràng buộc mà nó giải quyết là cửa sổ ngữ cảnh có hạn và tính trạng thái có nghĩa là thông tin bị mất giữa các lần gọi.
Thay vì cố gắng giữ mọi thứ bên trong cửa sổ ngữ cảnh, hãy lưu thông tin quan trọng vào bộ nhớ ngoài và lấy lại khi cần. Điều này có hai hình thức chính.
Hình thức đầu tiên là scratchpads, nơi một agent lưu trữ các kế hoạch trung gian, ghi chú hoặc các bước suy luận vào bộ nhớ ngoài trong một tác vụ kéo dài. Hệ thống nghiên cứu multi-agent của Anthropic thực hiện đúng điều này. Agent nghiên cứu chính ghi kế hoạch của mình vào bộ nhớ ngoài khi bắt đầu một tác vụ, vì nếu cửa sổ ngữ cảnh vượt quá 200.000 token, nó sẽ bị cắt bớt và kế hoạch sẽ bị mất.
Hình thức thứ hai là bộ nhớ dài hạn, bao gồm việc lưu giữ thông tin qua các phiên làm việc. ChatGPT tự động tạo ra các tùy chọn của người dùng từ các cuộc trò chuyện, Cursor và Windsurf học các mẫu mã hóa và ngữ cảnh dự án, và Claude Code sử dụng các tệp CLAUDE.md làm bộ nhớ hướng dẫn lâu dài. Tất cả các hệ thống này coi bộ nhớ ngoài là lớp bộ nhớ thực tế, với cửa sổ ngữ cảnh đóng vai trò là không gian làm việc tạm thời.
Select: Chỉ Lấy Những Gì Liên Quan
Ràng buộc mà nó giải quyết là nhiều ngữ cảnh hơn không tốt hơn, và mô hình cần thông tin phù hợp thay vì tất cả thông tin có sẵn.
Kỹ thuật quan trọng nhất ở đây là Retrieval-Augmented Generation, hay RAG. Thay vì nhồi nhét tất cả kiến thức của bạn vào cửa sổ ngữ cảnh, chúng tôi lưu trữ nó bên ngoài trong một cơ sở dữ liệu có thể tìm kiếm. Tại thời điểm truy vấn, chỉ truy xuất các đoạn có liên quan nhất đến câu hỏi hiện tại và chèn chúng vào ngữ cảnh, cung cấp cho mô hình kiến thức mục tiêu mà không bị nhiễu từ mọi thứ khác.
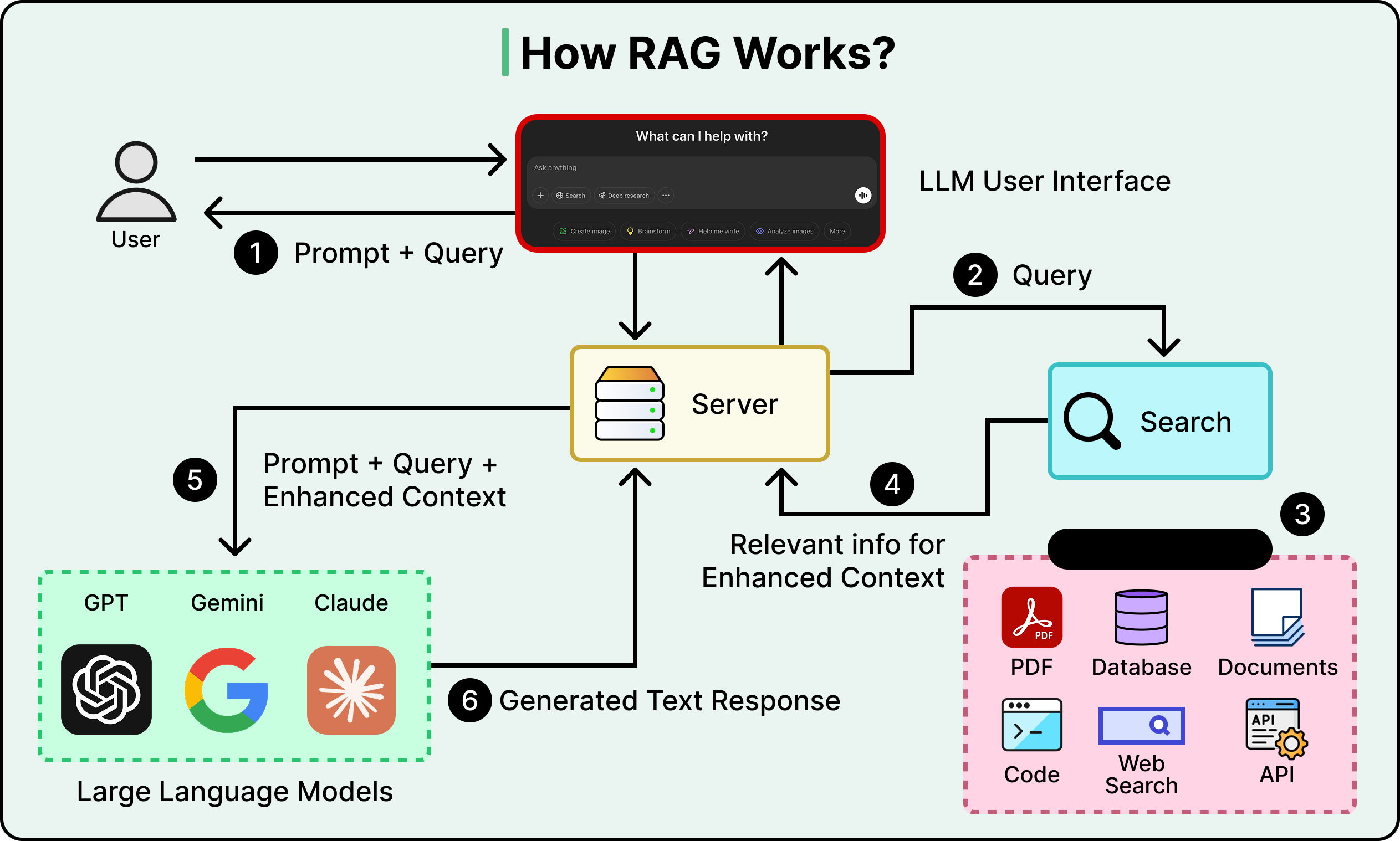
Việc lựa chọn cũng áp dụng cho các công cụ. Khi một agent có hàng tá công cụ khả dụng, việc liệt kê mô tả của mọi công cụ trong mỗi prompt sẽ lãng phí token và làm mô hình bối rối. Một cách tiếp cận tốt hơn là chỉ truy xuất các mô tả công cụ có liên quan đến tác vụ hiện tại.
Sự đánh đổi quan trọng với việc lựa chọn là độ chính xác. Nếu việc truy xuất mang lại các tài liệu gần đúng nhưng không hoàn toàn phù hợp, chúng sẽ trở thành những yếu tố gây xao nhãng, làm tăng số lượng token và đẩy ngữ cảnh quan trọng vào các vùng có ít sự chú ý. Bản thân bước truy xuất phải tốt, nếu không toàn bộ chiến lược sẽ phản tác dụng.
Nén: Chỉ Giữ Những Gì Bạn Cần
Hạn chế mà nó giải quyết là sự suy giảm ngữ cảnh và chi phí ngày càng tăng của sự chú ý trên nhiều token hơn.
Khi quy trình làm việc của agent trải dài hàng chục hoặc hàng trăm bước, cửa sổ ngữ cảnh sẽ đầy với lịch sử cuộc trò chuyện và đầu ra công cụ đã tích lũy. Các chiến lược nén giảm tải trọng này trong khi cố gắng bảo tồn thông tin thiết yếu.
Tóm tắt cuộc trò chuyện là phương pháp phổ biến nhất. Ví dụ, Claude Code sẽ kích hoạt quy trình "tự động nén" khi ngữ cảnh đạt 95% dung lượng, tóm tắt toàn bộ lịch sử tương tác thành một dạng ngắn hơn. Cognition, công ty đứng sau agent mã hóa Devin, đã huấn luyện một mô hình riêng biệt, chuyên dụng dành riêng cho việc tóm tắt tại các ranh giới agent-to-agent. Việc họ xây dựng một mô hình riêng chỉ cho bước này cho thấy việc nén kém có thể nghiêm trọng như thế nào, vì một quyết định hoặc chi tiết cụ thể bị tóm tắt đi sẽ biến mất vĩnh viễn.
Các dạng nén đơn giản hơn bao gồm cắt bớt (loại bỏ các tin nhắn cũ khỏi lịch sử) và nén đầu ra công cụ (giảm các kết quả tìm kiếm hoặc đầu ra mã dài dòng về những điểm thiết yếu trước khi chúng đi vào ngữ cảnh).
Phân lập: Chia Ngữ Cảnh Giữa Các Agent
Hạn chế mà nó giải quyết là sự pha loãng sự chú ý và sự đầu độc ngữ cảnh khi có quá nhiều loại thông tin cạnh tranh trong một cửa sổ.
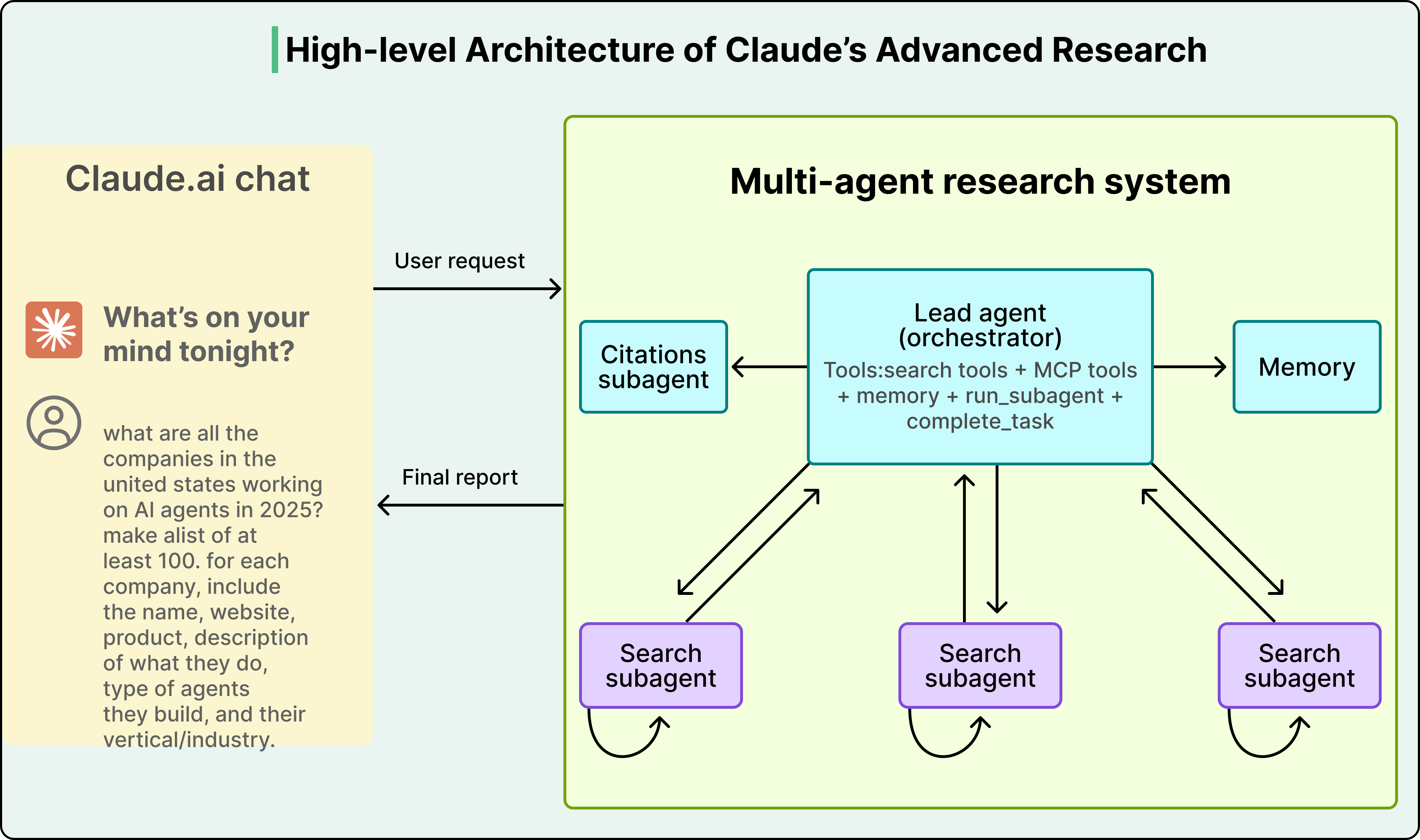
Thay vì một agent cố gắng xử lý mọi thứ trong một cửa sổ ngữ cảnh duy nhất bị phình to, chiến lược này chia công việc cho nhiều agent chuyên biệt, mỗi agent có ngữ cảnh riêng, sạch sẽ và tập trung. Một agent "nghiên cứu" nhận được ngữ cảnh chứa đầy các công cụ tìm kiếm và tài liệu được truy xuất, trong khi một agent "viết" nhận được ngữ cảnh chứa đầy hướng dẫn phong cách và quy tắc định dạng, vì vậy không ai bị phân tâm bởi thông tin của người kia.
Anthropic đã chứng minh điều này với hệ thống nghiên cứu đa agent của họ, nơi một agent Opus 4 chính đã ủy nhiệm các nhiệm vụ phụ cho các agent phụ Sonnet 4. Hệ thống đạt được 90,2% cải thiện so với một agent Opus 4 duy nhất trong các tác vụ nghiên cứu, mặc dù sử dụng cùng một họ mô hình cơ bản. Toàn bộ sự gia tăng hiệu suất đến từ cách quản lý ngữ cảnh, không phải từ một mô hình mạnh mẽ hơn.
Xem sơ đồ bên dưới:
Tradeoffs
Những chiến lược này rất mạnh mẽ, nhưng chúng đi kèm với những đánh đổi mà không có câu trả lời nào là đúng cho tất cả:
Nén thông tin so với mất mát thông tin: Mỗi khi bạn tóm tắt, bạn có nguy cơ mất một chi tiết quan trọng sau này. Bạn nén càng mạnh, bạn càng tiết kiệm token, nhưng khả năng phá hủy vĩnh viễn một thứ gì đó quan trọng càng cao.
Một agent so với nhiều agent: Kết quả của nhiều agent từ Anthropic rất ấn tượng, nhưng những người khác, đặc biệt là Cognition, đã lập luận rằng một agent duy nhất với khả năng nén tốt mang lại sự ổn định hơn và chi phí thấp hơn. Cả hai bên đều đang tranh luận về câu hỏi cốt lõi về cách quản lý ngữ cảnh hiệu quả, và câu trả lời phụ thuộc vào độ phức tạp của tác vụ, khả năng chấp nhận chi phí và yêu cầu về độ tin cậy.
Độ chính xác của truy xuất so với nhiễu: RAG bổ sung kiến thức, nhưng việc truy xuất không chính xác lại thêm các yếu tố gây xao nhãng. Nếu các tài liệu bạn truy xuất không thực sự liên quan, chúng sẽ tốn token và đẩy nội dung quan trọng vào các vị trí có mức độ chú ý thấp, do đó hệ thống truy xuất tự nó phải được thiết kế tốt, hoặc RAG sẽ làm mọi thứ tệ hơn.
Chi phí so với sự phong phú: Mỗi token đều tốn tiền và thời gian xử lý. Sự mở rộng không tương xứng của cơ chế attention khiến ngữ cảnh dài trở nên tốn kém nhanh chóng, và việc kỹ thuật ngữ cảnh phần nào là một bài toán kinh tế để tìm ra điểm mà lợi tức từ các token bổ sung không còn xứng đáng với chi phí.
Kết luận
Ý chính rút ra là mô hình chỉ tốt bằng ngữ cảnh mà nó nhận được. Làm việc hiệu quả với LLM đòi hỏi phải suy nghĩ về toàn bộ hệ thống xung quanh mô hình, không chỉ riêng mô hình.
Khi các mô hình trở nên mạnh mẽ hơn, kỹ thuật ngữ cảnh càng trở nên quan trọng. Khi mô hình đủ mạnh, hầu hết các lỗi sẽ không còn là lỗi về trí tuệ mà trở thành lỗi về ngữ cảnh, nơi mà mô hình có thể đã làm đúng nhưng không có đủ những gì cần thiết hoặc có quá nhiều những gì không cần thiết.
Các chiến lược đang phát triển và các phương pháp tốt nhất đang được sửa đổi khi các mô hình mới được phát hành. Tuy nhiên, các ràng buộc cơ bản về attention hữu hạn, thiên vị vị trí và tính không trạng thái là những ràng buộc về kiến trúc.
Tài liệu tham khảo
Tác giả: ByteByteGo