Một giải pháp thay thế nhanh hơn cho Jq
A Faster Alternative to Jq
Một công cụ mới tên là `jsongrep` ra đời, hứa hẹn mang lại tốc độ vượt trội khi làm việc với dữ liệu JSON, lấy cảm hứng từ `ripgrep`. Điểm mấu chốt tạo nên tốc độ này là việc sử dụng một engine dựa trên Deterministic Finite Automaton (DFA), được "đọc" trực tiếp từ cấu trúc JSON và biên dịch từ các truy vấn của người dùng. Cách tiếp cận này, được trình bày chi tiết bằng lý thuyết automata và các bài kiểm tra hiệu năng (benchmark), cho thấy sự cải thiện đáng kể về hiệu suất so với các công cụ truy vấn JSON hiện tại. Các developer nên cân nhắc `jsongrep` cho các tác vụ xử lý JSON hiệu năng cao, đặc biệt hữu ích khi làm việc với tập dữ liệu lớn hoặc trong các ứng dụng yêu cầu tốc độ xử lý khắt khe.
Bài viết này vừa là phần giới thiệu về một công cụ mà tôi đang nghiên cứu có tên là jsongrep, vừa là phần giải thích kỹ thuật về công cụ tìm kiếm nội bộ mà nó sử dụng. Tôi cũng thảo luận về chiến lược đo điểm chuẩn được sử dụng...
Bài viết này vừa là phần giới thiệu về một công cụ mà tôi đang nghiên cứu có tên là jsongrep, vừa là phần giải thích kỹ thuật về công cụ tìm kiếm nội bộ mà nó sử dụng. Tôi cũng thảo luận về chiến lược đo điểm chuẩn được sử dụng để so sánh hiệu suất của jsongrep với các công cụ truy vấn và triển khai giống đường dẫn JSON khác.
Trong bài đăng này, trước tiên tôi sẽ cho bạn xem công cụ này, sau đó giải thích tại sao nó nhanh (về mặt khái niệm), sau đó làm thế nào nó nhanh (lý thuyết automata) và cuối cùng chứng minh nó (điểm chuẩn).
Trước hết, tôi muốn nói rằng bài viết này được lấy cảm hứng rất nhiều từ công cụ
ripgreptuyệt vời của Andrew Gallant và bài đăng trên blog liên quan của anh ấy "ripgrep nhanh hơn {grep, ag, git grep, ucg, pt, sift}".
Mục lục
Bạn có thể cài đặt jsongrep từ Crates.io:
cargo cài đặt jsongrepGiống như ripgrep, jsongrep là nền tảng chéo (các tệp nhị phân có sẵn tại đây) và được viết bằng Rust.
Chuyến tham quan vòng xoáy của jsongrep
jsongrep (nhị phân jg) thực hiện truy vấn và đầu vào JSON rồi in mọi giá trị có đường dẫn qua tài liệu khớp với truy vấn. Hãy xây dựng từng ngôn ngữ truy vấn bằng tài liệu mẫu này:
sample.json:
{
"tên": "Micah",
"favorite_drinks": ["cà phê", "Dr. Pepper", "Năng lượng quái vật"],
"bạn cùng phòng": [
{
"tên": "Alice",
" favorite_food": "pizza"
Đường dẫn chấm chọn các trường lồng nhau theo tên. Các dấu chấm (.) giữa các tên trường biểu thị sự ghép nối-- "khớp trường này, rồi đến trường kia":
$ cat sample.json | jg 'bạn cùng phòng[0].name'
bạn cùng phòng.[0].name:
"Alice"Ký tự đại diện khớp với bất kỳ khóa đơn nào (*) hoặc bất kỳ chỉ mục mảng nào ([*]):
$ cat sample.json | jg 'favorite_drinks[*]'
đồ uống yêu thích.[0]:
"cà phê"
đồ uống yêu thích.[1]:
"Dr. Hạt tiêu"
đồ uống yêu thích.[2]:
"Năng lượng quái vật"Alternation (|) khớp với một trong hai nhánh, chẳng hạn như thay thế biểu thức chính quy:
$ cat sample.json | jg 'name | bạn cùng phòng'
tên:
"Micah"
bạn cùng phòng:
[
{
"tên": "Alice",
"favorite_food": "pizza"
]Hạ cánh đệ quy sử dụng * và [*] bên trong một ngôi sao Kleene để đi sâu tùy ý vào trong cây. Ví dụ: để tìm mọi trường name ở bất kỳ độ sâu nào:
$ cat sample.json | jg '(* | [*])*.name'
tên:
"Micah"
bạn cùng phòng.[0].name:
"Alice" Mẫu (* | [*])* có nghĩa là "đi theo bất kỳ khóa hoặc bất kỳ chỉ mục nào, 0 hoặc nhiều lần", ví dụ: đi xuống qua mọi đường dẫn có thể. Sau đó, .name ở cuối sẽ chỉ lọc những đường dẫn kết thúc tại trường có tên là name.
Tương tự, jg hiển thị cờ -F ("chuỗi cố định") làm cách viết tắt cho các truy vấn gốc đệ quy này:
$ cat sample.json | jg -F tên
tên:
"Micah"
bạn cùng phòng.[0].name:
"Alice" Tùy chọn (?) khớp với 0 hoặc một lần xuất hiện:
$ cat sample.json | jg 'bạn cùng phòng[0].favorite_food?'
bạn cùng phòng.[0]:
{
"tên": "Alice",
"favorite_food": "pizza"
bạn cùng phòng.[0].favorite_food:
"pizza "Hãy chú ý xem chuỗi bên trong "pizza" khớp với ? như thế nào, ngoài trường hợp không xuất hiện gốc.
Dưới đây là ảnh chụp màn hình hiển thị một số tính năng này đang hoạt động:
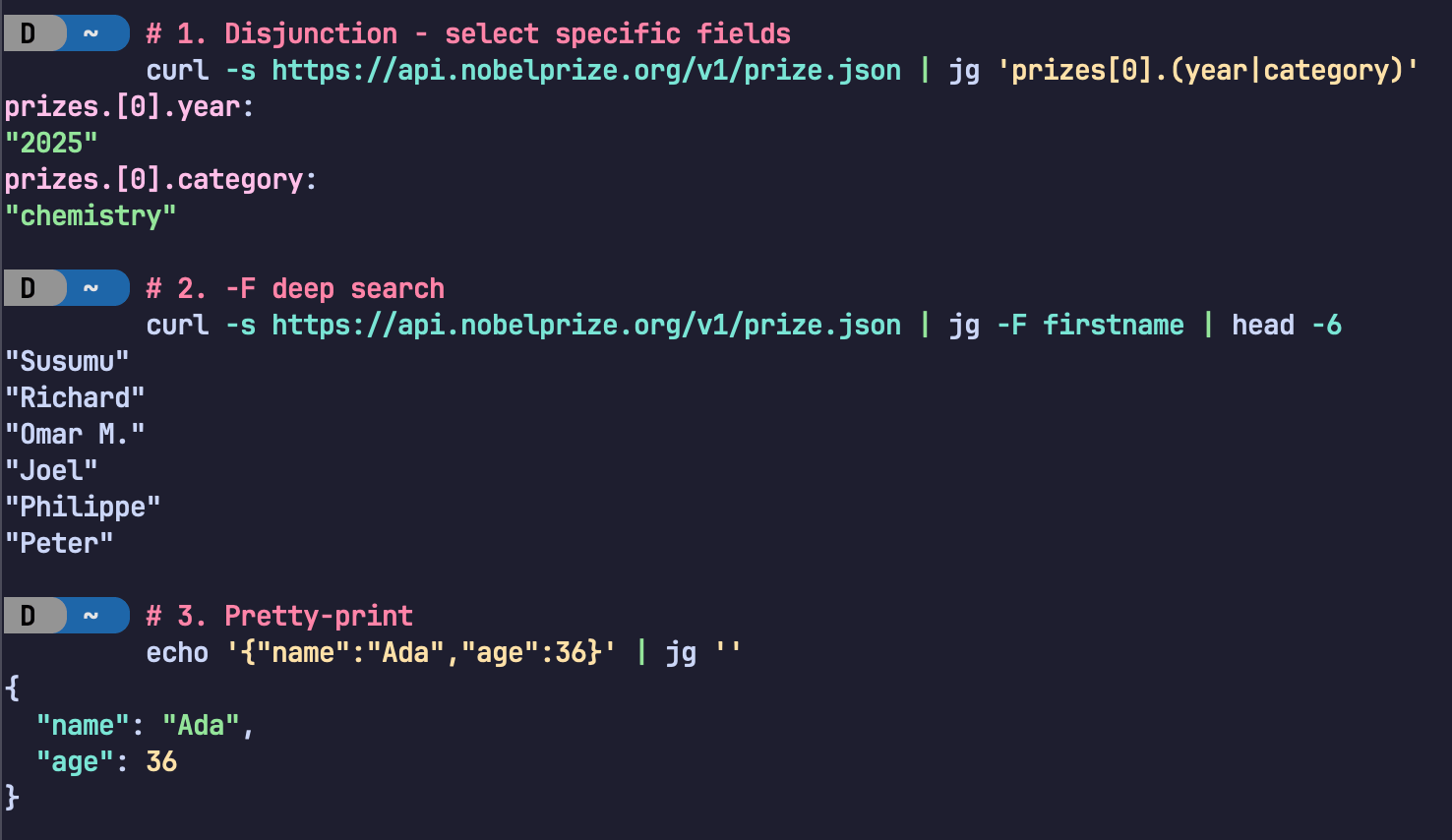
Ví dụ về một số tính năng truy vấn tìm kiếm của jsongrep trong thực tế.
LƯU Ý:
jsongreprất thông minh trong việc phát hiện xem bạn có đang chuyển sang một lệnh khác nhưlesshaysorthay không, trong trường hợp đó nó sẽ không hiển thị các đường dẫn JSON. Tuy nhiên, điều này có thể được ghi đè nếu muốn bằng tùy chọn--with-path.
jsongrep Pitch
Tài liệu JSON là cây: đối tượng và nhánh mảng, các đại lượng vô hướng là những chiếc lá, còn các khóa và chỉ số đánh dấu các cạnh. Truy vấn tài liệu JSON thực chất là mô tả đường dẫn xuyên qua cây này. jsongrep hiểu nhận xét này theo nghĩa đen: ngôn ngữ truy vấn của nó là ngôn ngữ thông thường dựa trên bảng chữ cái của các khóa và chỉ mục. Hãy nghĩ đến các biểu thức thông thường, nhưng thay vì khớp các ký tự trong một chuỗi, bạn đang khớp các cạnh trong một cây.
Tại sao "thông thường" lại quan trọng? Bởi vì các ngôn ngữ thông thường có một thuộc tính mạnh mẽ và nổi tiếng: chúng có thể được biên dịch thành máy tự động hữu hạn xác định (DFA). DFA xử lý đầu vào trong một lần truyền với $O(1)$ hoạt động trên mỗi ký hiệu đầu vào-- không quay lui, không ngăn xếp đệ quy, không tăng đột biến theo cấp số nhân đối với các truy vấn bệnh lý. Truy vấn được trả tiền một lần tại thời điểm biên dịch, sau đó việc tìm kiếm về cơ bản là miễn phí.
Đây là điểm khác biệt chính so với các công cụ như jq, jmespath hoặc jsonpath-rust. Các công cụ diễn giải biểu thức đường dẫn đó: tại mỗi nút trong cây JSON, chúng đánh giá truy vấn, kiểm tra các vị từ và đệ quy đi xuống các nhánh phù hợp. Nếu một truy vấn liên quan đến gốc đệ quy (.. hoặc $..), những công cụ này có thể truy cập lại cây con hoặc duy trì danh sách công việc. jsongrep thực hiện điều gì đó khác biệt về cơ bản-- nó biên dịch truy vấn thành DFA trước khi xem xét JSON, sau đó duyệt cây tài liệu chính xác một lần, thực hiện một chuyển đổi trạng thái $O(1)$ duy nhất ở mỗi cạnh. Không diễn giải, không quay lại, một lần vượt qua.
Do đó, jsongrep nhanh-- giống như rất nhanh:
So sánh hiệu suất tìm kiếm toàn diện trên tập dữ liệu xlarge (~190 MB).
jsongrep Anti-Pitch
Một lần nữa mượn từ bài đăng trên blog ripgrep, đây là "anti-pitch" dành cho jsongrep:
jsongrepkhông phổ biến (chưa) nhưjq.jqlà công cụ phù hợp để truy vấn, lọc JSON và chuyển đổi.Ngôn ngữ truy vấn có chủ ý ít biểu cảm hơn ngôn ngữ của
jq.jsongreplà công cụ tìm kiếm, không phải công cụ chuyển đổi-- nó tìm thấy các giá trị nhưng không tính toán các giá trị mới. Không có bộ lọc, không có số học, không có nội suy chuỗi.jsongreplà sản phẩm mới và chưa được thử nghiệm thực tế.
Hãy tiếp tục đọc nếu quan tâm đến nội dung bên trong của
jsongrep!
jsongrep Công cụ truy vấn dựa trên DFA của
Với tổng quan về công cụ và động lực đã có sẵn, hãy cùng đi sâu vào nội bộ. Phần này theo dõi một truy vấn duy nhất qua mọi giai đoạn của công cụ.
Tóm tắt về Quy trình
Cốt lõi của công cụ tìm kiếm là một quy trình gồm 5 giai đoạn:
- Phân tích tài liệu JSON thành một cây thông qua
serde_json_borrow(không sao chép). - Phân tích truy vấn của người dùng thành
Truy vấnAST. - Xây dựng NFA từ truy vấn thông qua thuật toán xây dựng của Glushkov 1.
- Xác định NFA thành DFA thông qua xây dựng tập hợp con2
- Đi theo JSON cây, thực hiện các chuyển đổi DFA ở mỗi cạnh và thu thập các kết quả khớp.
Để làm rõ điều này, chúng ta sẽ theo dõi truy vấn bạn cùng phòng[*].name qua từng giai đoạn. Dựa trên tài liệu mẫu của chúng tôi, truy vấn này phải khớp với "Alice" tại đường dẫn roommates[0].name.
Phân tích truy vấn
Chuỗi truy vấn roommates[*].name được phân tích cú pháp thành một AST. jsongrep sử dụng Ngữ pháp PEG (thông qua thư viện pest) ánh xạ DSL truy vấn tới cây Các biến thể enum truy vấn:
Đã dọn dẹp một chút Gỡ lỗi của đã biên dịch bạn cùng phòng[*].name Truy vấn:
Trình tự(
[
Trình tự(
[
Field("bạn cùng phòng"),
ArrayWildcard,
],
),
Trường ("tên"),
],
)Ngữ pháp rất đơn giản. Các dấu chấm biểu thị sự nối (trình tự), | biểu thị sự xen kẽ (phân tách), hậu tố * biểu thị ngôi sao Kleene (không lặp lại hoặc nhiều lần lặp lại) và hậu tố ? biểu thị tùy chọn (không hoặc một). Nhóm biểu thức con trong ngoặc đơn. Điều này ánh xạ trực tiếp đến định nghĩa của một ngôn ngữ thông thường-- và đó là toàn bộ vấn đề. Bởi vì ngôn ngữ truy vấn là ngôn ngữ thông thường nên mọi thứ sau đó (NFA, DFA, tìm kiếm một lần) đều có thể thực hiện được.
Truy vấn AST đầy đủ hỗ trợ các biến thể sau:
| Biến thể | Cú pháp | Ví dụ |
|---|---|---|
Trường | tên hoặc "tên được trích dẫn" | bạn cùng phòng |
Chỉ mục | [n] | [0] |
Phạm vi | [start:end] | [1:3] |
Ra ngeFrom | [n:] | [2:] |
FieldWildcard | * | * |
ArrayWildcard | [*] | [*] |
Tùy chọn | e? | name? |
KleeneStar | e* | (* | [*])* |
Phân tách | a | b | tên | tuổi |
Trình tự | a.b | foo.bar |
JSON dưới dạng cây
Các giá trị JSON tạo thành một cây. Khóa đối tượng và chỉ mục mảng là cạnh; các giá trị mà chúng trỏ đến là nút. Vô hướng (chuỗi, số, Boolean, null) là các lá.
Tài liệu mẫu của chúng tôi tạo thành cây này:
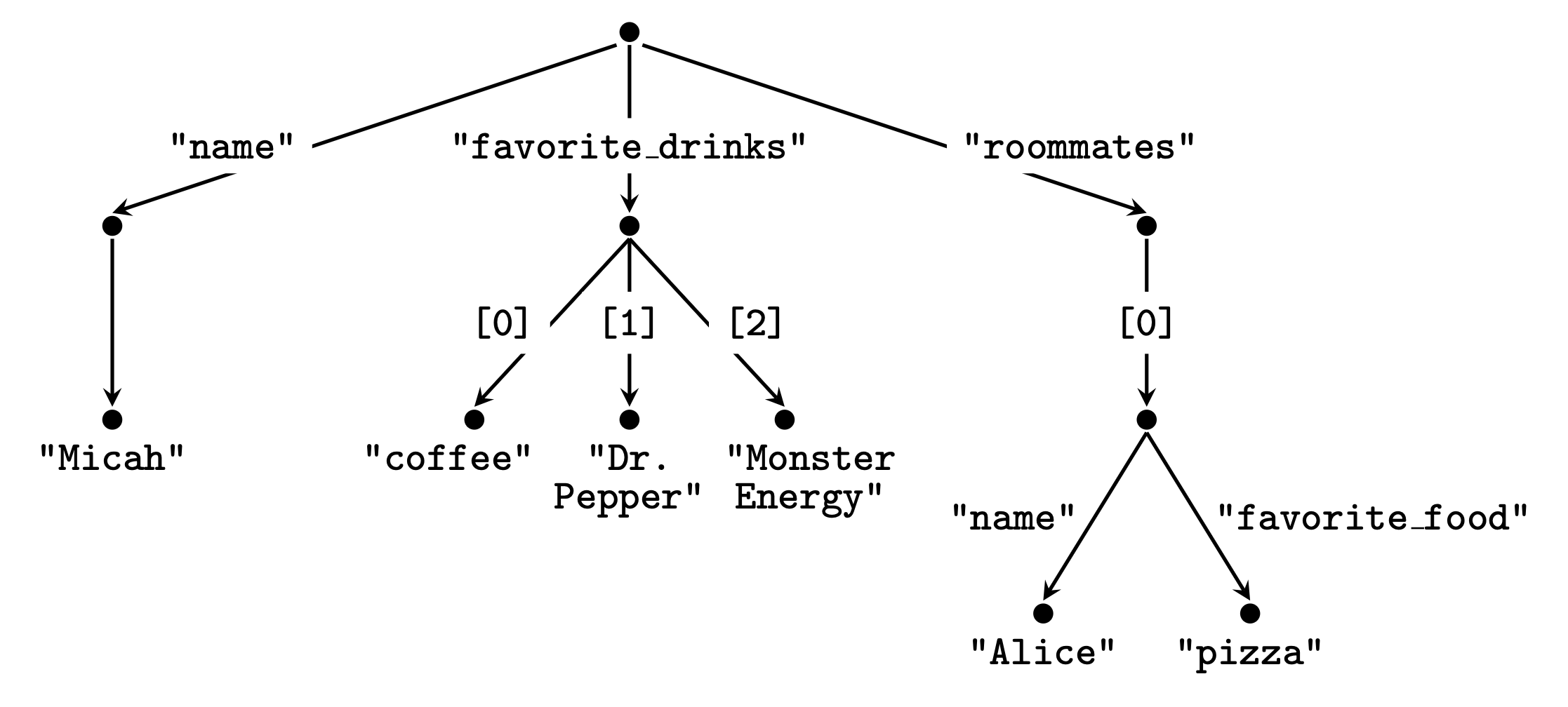
Tài liệu JSON mẫu dưới dạng cây.
Khi đó, một truy vấn sẽ mô tả một tập hợp các đường dẫn từ gốc đến các nút phù hợp. Truy vấn roommates[*].name mô tả đường dẫn: lấy cạnh bạn cùng phòng, sau đó là chỉ mục mảng bất kỳ, sau đó đến cạnh name.
Xây dựng NFA (Thuật toán Glushkov)
Với truy vấn được phân tích cú pháp thành AST, chúng ta cần chuyển đổi nó thành một máy tự động có thể khớp với các đường dẫn. Bước đầu tiên là xây dựng một máy tự động hữu hạn không xác định (NFA).
jsongrep sử dụng cách xây dựng của Glushkov, có lợi thế chính so với cách xây dựng của Thompson phổ biến hơn: nó tạo ra $\epsilon$-free NFA. Mọi chuyển đổi trong NFA kết quả đều sử dụng một ký hiệu-- không có chuyển đổi epsilon để đuổi theo, điều này giúp đơn giản hóa việc xác định xuôi dòng.
Thuật toán của Glushkov hoạt động theo bốn bước:
1. Tuyến tính hóa truy vấn. Mỗi ký hiệu (tên trường, ký tự đại diện, phạm vi chỉ mục) trong truy vấn có một số vị trí duy nhất. Truy vấn bạn cùng phòng[*].name của chúng tôi có ba ký hiệu:
| Vị trí | Biểu tượng |
|---|---|
| 1 | Field("bạn cùng phòng") |
| 2 | ArrayWildcard (bất kỳ chỉ mục) |
| 3 | Trường ("tên") |
2. Tính tập đầu tiên và tập cuối. Tập Đầu tiên chứa các vị trí có thể xuất hiện khi bắt đầu trận đấu; tập hợp Cuối cùng chứa các vị trí có thể xuất hiện ở cuối. Đối với một chuỗi đơn giản, Đầu tiên = {phần tử đầu tiên} và Cuối cùng = {phần tử cuối cùng}:
- $\textit{First} = \set{1}$ (
bạn cùng phòng) - $\textit{Last} = \set{3}$ (
name)
3. Tính tập hợp Số lượt theo dõi. Đối với mỗi vị trí i, Số lượt theo dõi(i) là tập hợp các vị trí có thể ngay lập tức theo sau i trong một trận đấu hợp lệ. Đối với một chuỗi đơn giản, mỗi vị trí theo sau vị trí trước nó:
- $\textit{Follows}(1) = \set{2}$
- $\textit{Follows}(2) = \set{3}$
- $\textit{Follows}(3) = \emptyset$
Đối với các truy vấn có dấu sao hoặc thay thế Kleene, bộ $\textit{Follows}$ trở nên thú vị hơn-- các vòng lặp và nhánh xuất hiện một cách tự nhiên.
4. Tập hợp NFA. NFA có các trạng thái $n + 1$ (một trạng thái bắt đầu cộng với một trạng thái cho mỗi vị trí). Các chuyển đổi được nối dây từ các tập hợp được tính toán:
- Từ trạng thái bắt đầu $q_0$, thêm các chuyển đổi vào mọi vị trí trong tập $First$
- Đối với mỗi vị trí $i$ và mỗi $j \in \textit{Follows}(i)$, hãy thêm một chuyển đổi từ trạng thái $i$ sang trạng thái $j$ trên ký hiệu $j$
- Các trạng thái tương ứng với các vị trí trong tập hợp $\textit{Last}$ được đánh dấu chấp nhận
Đối với truy vấn của chúng tôi, NFA thu được là:
Đã xây dựng NFA cho `bạn cùng phòng[*].name`:
Trạng thái NFA: 4
Trạng thái bắt đầu: 0
Các quốc gia chấp nhận: [3]
Bộ đầu tiên: ["[0] Field(bạn cùng phòng)"]
Bộ cuối cùng: ["[2] Trường(name)"]
Bộ yếu tố:
[0] Field(bạn cùng phòng) có thể được theo dõi bởi:
[1] Phạm vi (0, 18446744073709551615)
[1] Phạm vi (0, 18446744073709551615) có thể được theo sau bởi:
[2] Trường(tên)
[2] Không thể theo dõi trường (tên)
Chuyển đổi:
trạng thái 0:
trên [0] Field(bạn cùng phòng) -> [1]
trạng thái 1:
trên [1] Phạm vi (0, 18446744073709551615) -> [2]
trạng thái 2:
trên [2] Trường(tên) -> [3]
trạng thái 3:Giá trị
18446744073709551615là giá trị củausize::MAXtrên máy của tôi (không gian địa chỉ 64 bit, bằng2^64 - 1), là giá trị tối đa của 64 bit không dấu số nguyên.
Quá trình chuyển đổi NFA bảng:
| Tiểu bang | Trường ("bạn cùng phòng") | [*] | Field("name") | Chấp nhận? |
|---|---|---|---|---|
| $q_0$ | $q_1$ | — | — | Không |
| $q_1$ | — | $q_2$ | — | Không |
| $q_2$ | — | — | $q_3$ | Không |
| $q_3$ | — | — | — | Có |
Sơ đồ trạng thái NFA:
$$q_0 \xrightarrow{\texttt{roommates}} q_1 \xrightarrow{[\ast]} q_2 \xrightarrow{\texttt{name}} q_3$$
Đây là một chuỗi đơn giản dành cho truy vấn đơn giản của chúng ta, nhưng dành cho các truy vấn có * hoặc |, NFA sẽ có các cạnh phân nhánh và lặp. Ví dụ: (* | [*])*.name sẽ tạo ra một trạng thái có vòng lặp tự lặp trên cả FieldWildcard và ArrayWildcard, ghi lại hành vi "đi xuống thông qua mọi thứ".
Xác định: NFA đến DFA (Xây dựng tập hợp con)
NFA có thể ở nhiều trạng thái cùng lúc-- trên một đầu vào nhất định, nó có thể có một số chuyển đổi hợp lệ. Về mặt lý thuyết, điều này tốt nhưng lại không tốt cho hiệu suất: mô phỏng NFA có nghĩa là theo dõi một tập hợp trạng thái hoạt động ở mỗi bước. Ngược lại, DFA luôn ở một trạng thái chính xác, nghĩa là mỗi lần chuyển đổi là một lần tra cứu bảng O(1). Điều quan trọng là Rabin và Scott đã chỉ ra rằng mọi NFA đều có thể được chuyển thành một DFA tương đương2.
Thuật toán tiêu chuẩn để chuyển đổi NFA thành DFA là xây dựng tập hợp con (còn gọi là cấu trúc tập hợp lũy thừa). Ý tưởng rất đơn giản: mỗi trạng thái DFA tương ứng với một tập hợp trạng thái NFA. Thuật toán khám phá tất cả các tập hợp có thể truy cập thông qua tìm kiếm theo chiều rộng:
- Bắt đầu với trạng thái DFA tương ứng với $q_0$ (chỉ trạng thái bắt đầu NFA).
- Đối với mỗi trạng thái DFA và mỗi ký hiệu trong bảng chữ cái, hãy tính tập hợp các trạng thái NFA có thể truy cập bằng cách thực hiện quá trình chuyển đổi đó từ bất kỳ trạng thái NFA nào trong tập hợp hiện tại.
- Nếu tập kết quả này là mới, hãy tạo trạng thái DFA mới cho nó.
- Trạng thái DFA sẽ chấp nhận nếu bất kỳ trong số các trạng thái NFA cấu thành của nó đang chấp nhận.
- Lặp lại cho đến khi không phát hiện được trạng thái DFA mới nào.
Đối với truy vấn ví dụ của chúng tôi roommates[*].name, NFA đã mang tính xác định (một chuỗi đơn giản không có phân nhánh), do đó việc xây dựng tập hợp con tạo ra một DFA có hình dạng giống nhau:
DFA được xây dựng cho truy vấn: `roommates[*].name`
Trạng thái DFA: 4
Trạng thái bắt đầu: 0
Các quốc gia chấp nhận: [3]
Bảng chữ cái (4 ký hiệu):
0: Khác
1: Field("bạn cùng phòng")
2: Trường ("tên")
3: Phạm vi(0, 18446744073709551615)
Chuyển đổi:
trạng thái 0:
trên [Khác] -> (đã chết)
trên [Field("bạn cùng phòng")] -> 1
trên [Field("name")] -> (đã chết)
trên [Phạm vi(0, 18446744073709551615)] -> (đã chết)
trạng thái 1:
trên [Khác] -> (đã chết)
trên [Field("bạn cùng phòng")] -> (đã chết)
trên [Field("name")] -> (đã chết)
trên [Phạm vi (0, 18446744073709551615)] -> 2
trạng thái 2:
trên [Khác] -> (đã chết)
trên [Field("bạn cùng phòng")] -> (đã chết)
trên [Field("name")] -> 3
trên [Phạm vi(0, 18446744073709551615)] -> (đã chết)
trạng thái 3:
trên [Khác] -> (đã chết)
trên [Field("bạn cùng phòng")] -> (đã chết)
trên [Field("name")] -> (đã chết)
trên [Range(0, 18446744073709551615)] -> (đã chết) | Trạng thái DFA | NFA Các tiểu bang | Chấp nhận? |
|---|---|---|
| 0 | $\set{q_0}$ | Không | 1 | $\set{q_1}$ | Không |
| 2 | $\set{q_2}$ | Không |
| 3 | $\set{q_3}$ | Có |
Bảng chuyển đổi:
| Trạng thái | Field("bạn cùng phòng") | Field("name") | Range(0, MAX) | Khác | Chấp nhận? |
|---|---|---|---|---|---|
| 0 | 1 | Không | |||
| 1 | 2 | Không | |||
| 2 | 3 | Không | |||
| 3 | Có |
Vì vậy, sơ đồ trạng thái của DFA trông giống như cái này:
$$q_0 \xrightarrow{\texttt{roommates}} q_1 \xrightarrow{[\ast]} q_2 \xrightarrow{\texttt{name}} q_3$$
Trong quá trình triển khai, bảng chữ cái không chỉ là các ký hiệu chữ trong truy vấn-- jsongrep cũng thêm biểu tượng Other để xử lý các khóa JSON không xuất hiện trong truy vấn. Bất kỳ chuyển đổi nào trên Other đều dẫn đến trạng thái chết (hoặc vẫn ở trạng thái mà khóa đó không liên quan), đảm bảo chúng tôi bỏ qua các nhánh không khớp một cách hiệu quả.
Đối với các truy vấn phức tạp hơn, việc xây dựng tập hợp con có thể tạo ra các trạng thái DFA kết hợp nhiều trạng thái NFA. Ví dụ: (* | [*])*.name sẽ tạo ra các trạng thái DFA đại diện cho các tập hợp như $\set{q_0, q_1}$ (cả "ở đầu" và "ở giữa quá trình giảm dần"), điều này cho phép hành vi chuyển một lần.
Tìm kiếm: DFS với Chuyển đổi DFA
Đây là phần thưởng. Với DFA được xây dựng, việc tìm kiếm tài liệu JSON là một quá trình duyệt cây theo chiều sâu đơn giản, mang theo trạng thái DFA:
- Bắt đầu từ gốc của cây JSON ở trạng thái DFA $q_0$.
- Tại mỗi nút, lặp qua các nút con của nó (khóa đối tượng hoặc chỉ mục mảng).
- Đối với mỗi cạnh con, hãy tra cứu quá trình chuyển đổi DFA: với trạng thái hiện tại và nhãn cạnh (tên khóa hoặc chỉ mục), tiếp theo là gì bang?
- Nếu không có quá trình chuyển đổi nào tồn tại cho cạnh này, bỏ qua toàn bộ cây con.
- Nếu trạng thái mới chấp nhận, ghi lại kết quả trùng khớp (đường dẫn + giá trị).
- Đệ quy vào thành phần con với trạng thái DFA mới.
Hãy theo dõi truy vấn bạn cùng phòng[*].name của chúng ta dựa trên tài liệu mẫu:
1. Bắt đầu từ đối tượng gốc ở trạng thái DFA $q_0$. Lặp lại ba khóa của nó:
- Edge
"name": $\delta(q_0, \texttt{Field("name")}) \to \text{dead}$. Cắt tỉa cây con này. - Cạnh
"favorite_drinks": $\delta(q_0, \texttt{Other}) \to \text{dead}$. Prune. - Edge
"bạn cùng phòng": $\delta(q_0, \texttt{Field("roommates")}) \to q_1$. Đi xuống.
2. Tại mảng bạn cùng phòng ở trạng thái $q_1$. Lặp lại các chỉ mục của nó:
- Edge
[0]: $\delta(q_1, \texttt{Range(0, MAX)}) \to q_2$. Đi xuống.
3. Tại đối tượng bạn cùng phòng[0] ở trạng thái $q_2$. Lặp lại các khóa của nó:
- Edge
"name": $\delta(q_2, \texttt{Field("name")}) \to q_3$. Trạng thái $q_3$ chấp nhận-- ghi lại kết quả trùng khớp:bạn cùng phòng.[0].name→"Alice". - Edge
"favorite_food": $\delta(q_2, \texttt{Other}) \to \text{dead}$. Prune.
4. Tìm kiếm hoàn tất. Đã tìm thấy một kết quả phù hợp:
bạn cùng phòng.[0].name:
"Alice"Lưu ý cách DFA cho phép chúng tôi bỏ qua các cây con "name" và "favorite_drinks" ở gốc trong bước 1-- chúng tôi thậm chí chưa bao giờ xem xét giá trị của chúng. Trên một tài liệu lớn, việc cắt tỉa này giúp cho việc tìm kiếm trở nên nhanh chóng: toàn bộ các nhánh của cây JSON bị loại bỏ trong $O(1)$ mà không đệ quy vào chúng.
Mỗi nút được truy cập nhiều nhất một lần và mỗi lần chuyển đổi là một lần tra cứu bảng $O(1)$. Tổng thời gian tìm kiếm là O(n) trong đó n là số nút trong cây JSON. Không cần quay lui, không cần phí thông dịch.
Là một phần thưởng triển khai, jsongrep sử dụng serde_json_borrow để phân tích cú pháp JSON không sao chép. Cây được phân tích cú pháp giữ các tham chiếu mượn (&str) vào bộ đệm đầu vào ban đầu thay vì phân bổ các chuỗi mới, giúp giảm đáng kể chi phí bộ nhớ trên các tài liệu lớn.
Phương pháp đo điểm chuẩn
Ngoài ra còn có thêm thông tin về đo điểm chuẩn, bao gồm cả cách tái tạo kết quả, trong thư mục benches/ của kho lưu trữ jsongrep.
Tất cả các điểm chuẩn đều sử dụng Tiêu chí.rs , một khung đo điểm chuẩn Rust dựa trên thống kê cung cấp khoảng tin cậy, khả năng phát hiện ngoại lệ và phát hiện thay đổi trong các lần chạy.
Bộ dữ liệu
Bốn bộ dữ liệu về việc tăng tỷ lệ kiểm tra kích thước hành vi:
| Tên | Tệp | Kích thước | Mô tả |
|---|---|---|---|
| nhỏ | simple.json | 106 B | Tối thiểu được làm thủ công tài liệu |
| trung bình | kubernetes-def định.json | ~992 KB | Định nghĩa lược đồ API Kubernetes |
| large | kestra-0.19.0.json | ~7.6 MB | Thông số OpenAPI cho Kestra |
| xlarge | citylots.json | ~190 MB | San Francisco GeoJSON bưu kiện |
Công cụ so sánh
Năm công cụ truy vấn JSON đã được so sánh:
| Công cụ | Thùng | Ghi chú |
|---|---|---|
jsongrep | (thùng này, jsongrep) | Dựa trên DFA, serde_json_borrow (không sao chép) |
jsonpath-rust | jsonpath-rust | serde_json::Value (phân bổ) |
jmespath | jmespath | jmespath::Loại tùy chỉnh |
jaq | jaq-core + jaq-std | jq-tương thích, jaq_json::Val |
jql | jql-parser + jql-runner | serde_json::Value (phân bổ) |
Nhóm điểm chuẩn
Điểm chuẩn được chia thành bốn nhóm để phân biệt thời gian sử dụng:
document_parse-- chỉ chi phí phân tích cú pháp JSON. Đo lườngserde_json_borrow(không sao chép) so vớiserde_json::Value(phân bổ) so vớijmespath::Variable. Điều này tách biệt lợi thế phân tích cú pháp không sao chép của jsongrep.query_compile-- Chỉ chi phí biên dịch truy vấn. jsongrep phải xây dựng AST và xây dựng DFA trả trước; các công cụ khác có thể có các bước biên dịch rẻ hơn (hoặc không có). Đây là cái giá mà jsongrep phải trả cho việc tìm kiếm nhanh.query_search-- Truy vấn được biên dịch trước, tài liệu được phân tích trước, chỉ tìm kiếm. Tách biệt chi phí truyền tải/so khớp mà không cần phân tích cú pháp hoặc chi phí biên dịch.end_to_end-- Quy trình đầy đủ: phân tích cú pháp JSON + biên dịch truy vấn + tìm kiếm. Đây là kịch bản sử dụng CLI thực tế.
Truy vấn tương đương
Mỗi công cụ sử dụng cú pháp truy vấn riêng nhưng điểm chuẩn đảm bảo hoạt động tương đương trên các công cụ. Ví dụ:
| Khái niệm | jsongrep | JSONPath | jq |
|---|---|---|---|
| Trường đơn giản | tên | $.name | .name |
| Lồng nhau đường dẫn | name.first | $.name.first | .name.first |
| Chỉ mục mảng | sở thích[0] | $.hobbies[0] | .hobbies[0] |
| Đệ quy gốc | (* | [*])*.description | $..description | .. | .Sự miêu tả? // trống |
Cân nhắc về tính công bằng
- Lợi thế phân tích cú pháp không sao chép được tách biệt rõ ràng trong nhóm
document_parsechứ không phải ẩn. jsongrepChi phí biên dịch DFA trả trước của được tính riêng trongquery_compileđể người đọc có thể thấy sự cân bằng.- Các công cụ thiếu một số tính năng truy vấn nhất định (ví dụ:
jmespathkhông có gốc đệ quy) sẽ bị bỏ qua đối với các điểm chuẩn đó thay vì bị phạt. - Các công cụ yêu cầu quyền sở hữu JSON được phân tích cú pháp (
jaq,jmespath) sử dụngiter_batchedcủa Tiêu chí để sao chép khá riêng biệt chi phí từ chi phí tìm kiếm.
Kết quả điểm chuẩn
Hãy cùng xem kết quả từ điểm chuẩn. Chúng tôi sẽ sử dụng tập dữ liệu xlarge trừ khi có ghi chú khác vì tập dữ liệu này thể hiện rõ nhất tác động của hiệu suất nhưng bạn có thể xem kết quả đầy đủ tại đây.
Phân tích tài liệu Thời gian
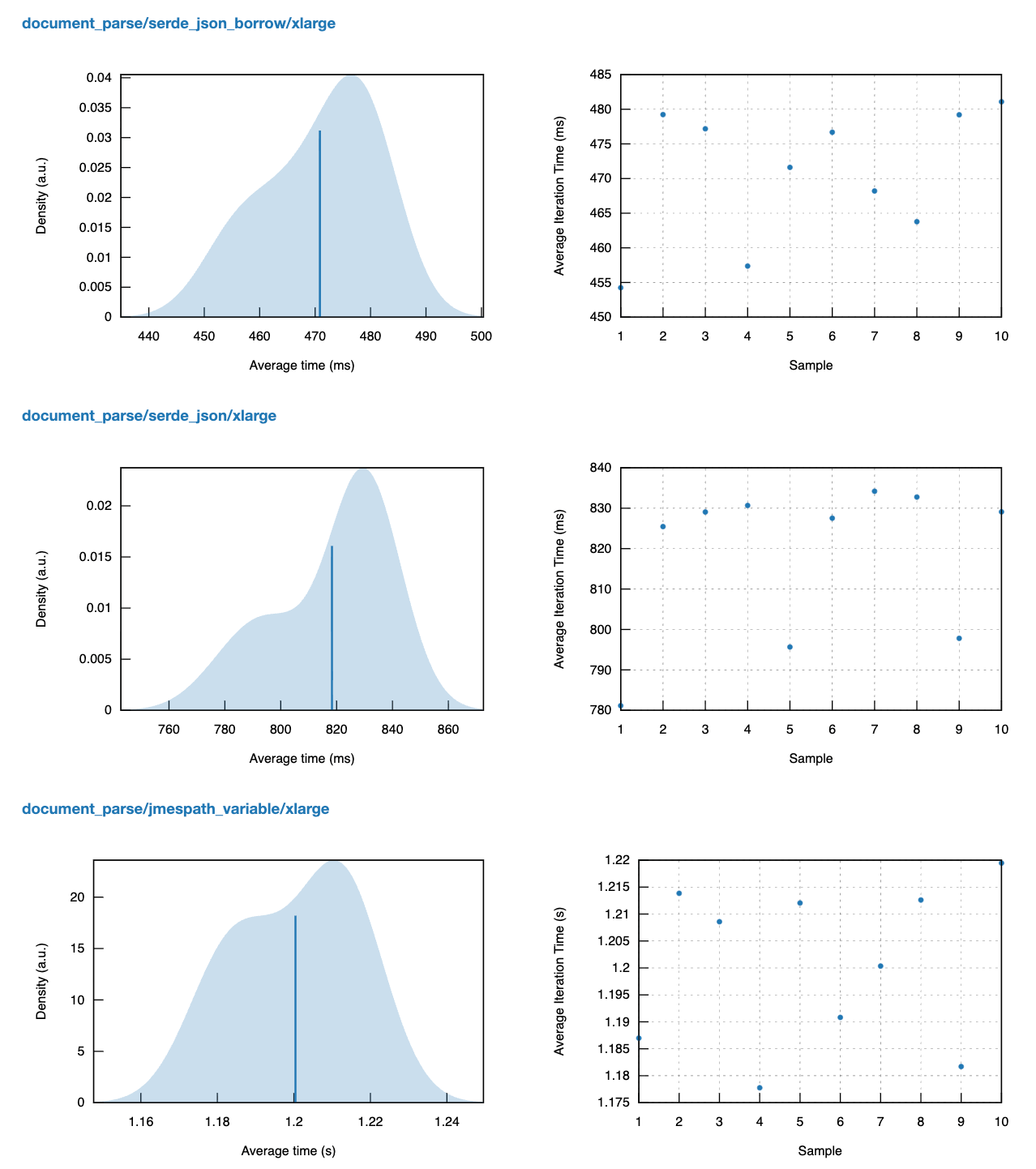
Thời gian phân tích tài liệu trên tập dữ liệu xlarge trên tất cả các công cụ.
Không có gì ngạc nhiên ở đây: serde_json_borrow là nhanh nhất, tiếp theo là serde_json::Value và jmespath::Biến.
Thời gian biên dịch truy vấn
Như mong đợi, jsongrep cần có thời gian để biên soạn các truy vấn khác nhau và đây là chi phí lớn nhất:
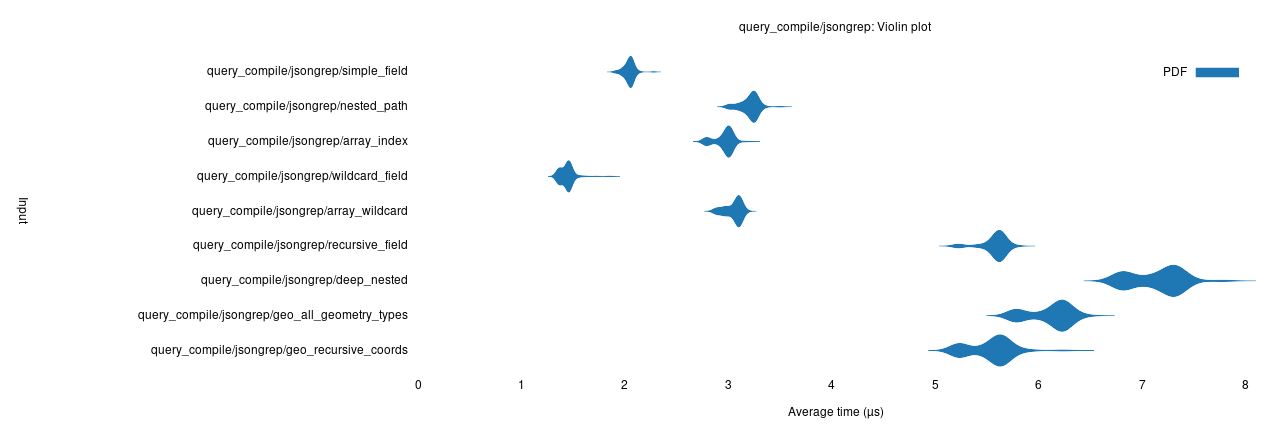
thời gian biên dịch truy vấn jsongrep.
So sánh thời gian này với thời gian biên dịch của jmespath (nhanh hơn rất nhiều):
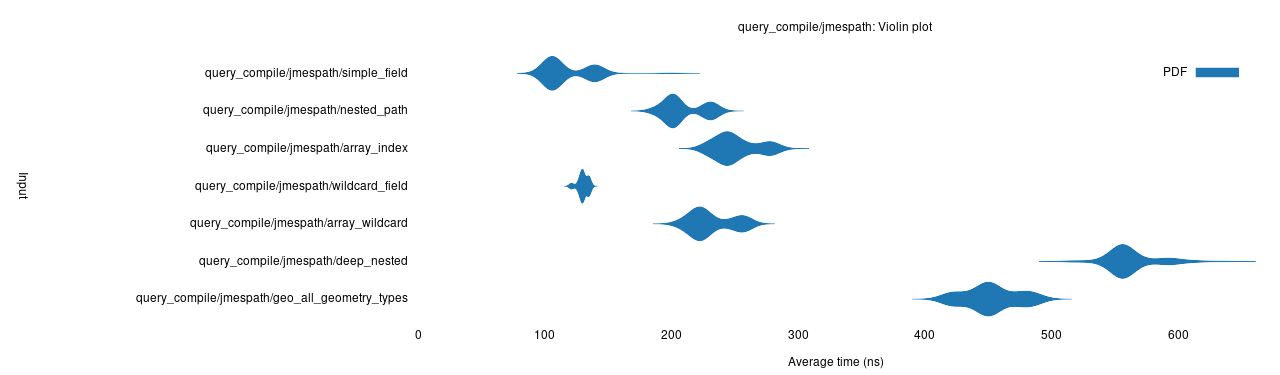
thời gian biên dịch truy vấn jmespath.
Thời gian tìm kiếm

Tìm kiếm thời gian trên tập dữ liệu xlarge trên tất cả các công cụ.
Tất cả query_search xlarge kết quả
Thời gian tìm kiếm từ đầu đến cuối
Như đã trình bày ở đầu bài đăng, so với tập dữ liệu xlarge (~190 MB) trên điểm chuẩn toàn diện, nó thậm chí còn chưa bằng:
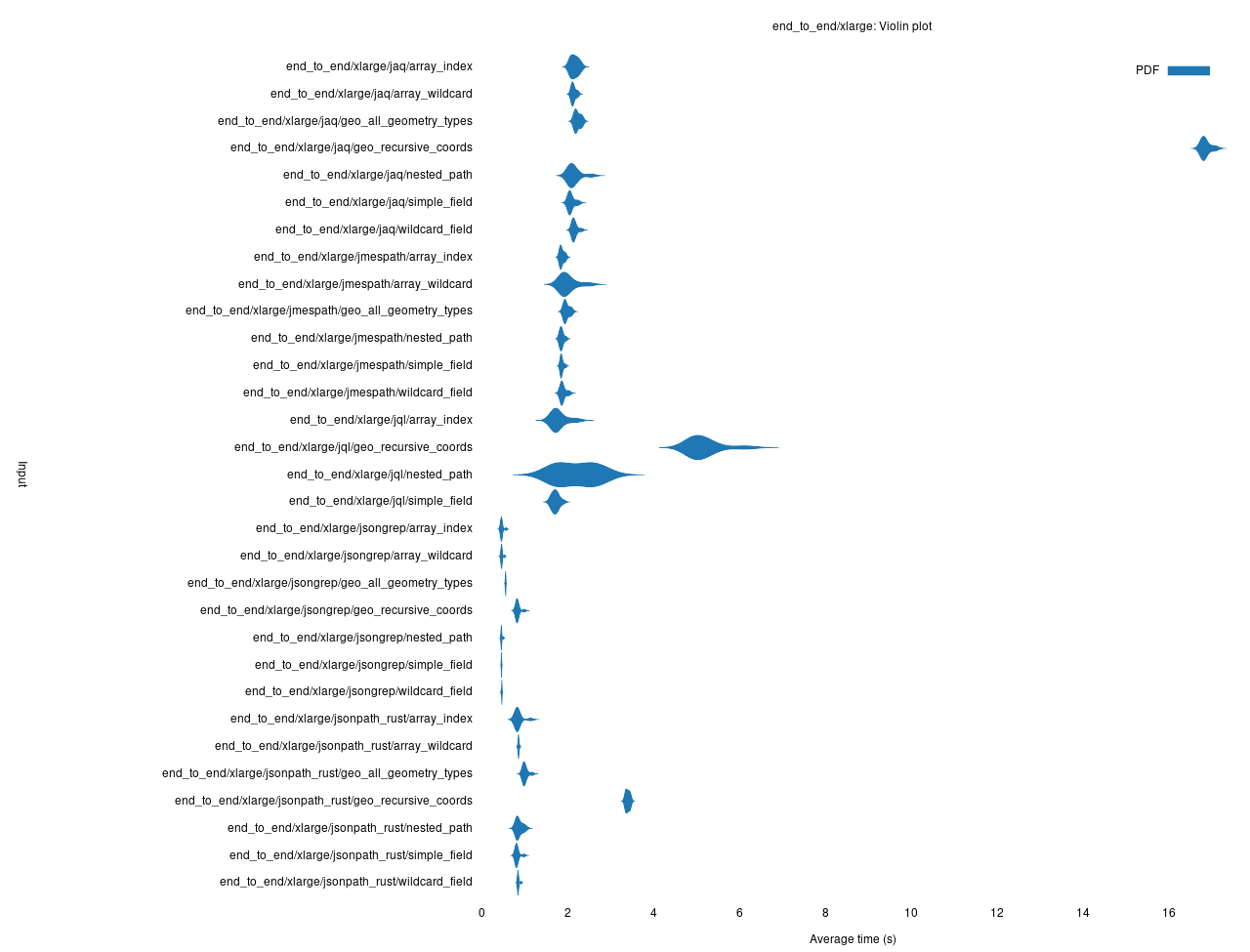
So sánh hiệu suất tìm kiếm toàn diện trên tập dữ liệu xlarge (~190 MB).
Báo cáo Tiêu chí tương tác đầy đủ hiện có tại trang web đo điểm chuẩn trực tiếp.
Liên kết
jsongrep hoàn toàn là phần mềm nguồn mở, được MIT cấp phép.
- GitHub: liên kết
- Crates.io: liên kết
- Kết quả đo điểm chuẩn: trang web trực tiếp | Đầu ra tiêu chí
- Docs.rs: liên kết
jsongrep cũng hiển thị công cụ truy vấn dựa trên DFA của nó dưới dạng một thùng thư viện, do đó bạn có thể nhúng tìm kiếm JSON nhanh trực tiếp vào các dự án Rust của riêng bạn.
Tài liệu tham khảo
Glushkov, V. M. “Lý thuyết trừu tượng của AUTOMATA.” Khảo sát toán học Nga 16, không. 5 (1961): 1–53. https://doi.org/10.1070/RM1961v016n05ABEH004112. ↩
Rabin, M. O. và D. Scott. “Automata hữu hạn và các vấn đề về quyết định của chúng.” Tạp chí Nghiên cứu và Phát triển của IBM, tập. 3, không. 2, tháng 4 1959, trang 114–25. ACM.org, https://dl.acm.org/doi/10.1147/rd.32.0114. ↩ ↩2
Tác giả: pistolario